全局解释器锁,简称 GIL,发音为 gill,是 Python 社区中一个颇有争议的话题。简而言之,GIL 阻止一个 Python 进程在任何给定时间执行多个 Python 字节码指令。这意味着,即使我们在多核机器上有多个线程,一个 Python 进程一次只能有一个线程运行 Python 代码。在我们拥有多核 CPU 的世界里,这对希望利用多线程来提高应用程序性能的 Python 开发人员来说可能是一个重大挑战。
注意 多进程可以并发运行多个字节码指令,因为每个 Python 进程都有自己的 GIL。
那么为什么 GIL 存在呢?答案在于 CPython 中内存的管理方式。在 CPython 中,内存主要通过一个称为引用计数的过程来管理。引用计数的工作原理是跟踪谁当前需要访问特定的 Python 对象,如整数、字典或列表。引用计数是一个整数,跟踪有多少地方引用该特定对象。当有人不再需要该引用对象时,引用计数减少;当其他人需要它时,它增加。当引用计数达到零时,没有人在引用该对象,可以将其从内存中删除。
CPython 是 Python 的参考实现。所谓参考实现,我们指的是它是语言的标准实现,并作为语言正确行为的参考。还有其他 Python 实现,如 Jython,它设计用于 Java 虚拟机;以及 IronPython,它设计用于 .NET 框架。
线程的冲突在于 CPython 中的实现不是线程安全的。当我们说 CPython 不是线程安全时,我们的意思是如果两个或更多线程修改一个共享变量,该变量可能最终处于意外状态。这种意外状态取决于线程访问变量的顺序,通常称为竞态条件。当两个线程需要同时引用一个 Python 对象时,可能会出现竞态条件。
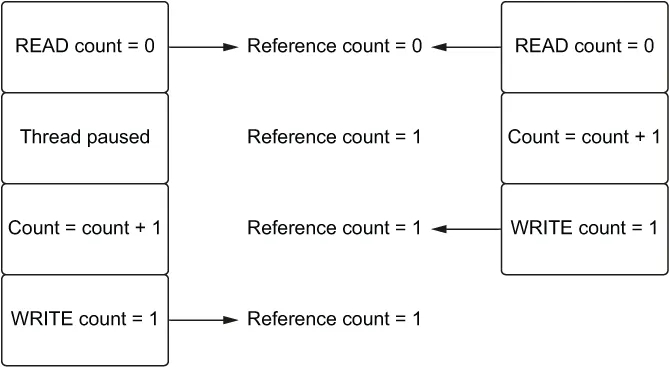
如图 1.6 所示,如果两个线程同时增加引用计数,我们可能会面临这样一种情况:一个线程导致引用计数为零,而该对象仍在被另一个线程使用。这可能导致的结果是,当我们尝试读取可能已删除的内存时,应用程序崩溃。
图 1.6 一个竞态条件,两个线程试图同时递增引用计数。得到的计数是 1,而不是预期的 2。
为了演示 GIL 对多线程编程的影响,让我们检查计算斐波那契数列中第 n 个数字的 CPU 密集型任务。我们将使用该算法的一个相当慢的实现来演示一个耗时的操作。正确的解决方案将使用记忆化或数学技术来提高性能。
import timedef print_fib(number: int) -> None: def fib(n: int) -> int: if n == 1: return 0 elif n == 2: return 1 else: return fib(n - 1) + fib(n - 2) print(f'fib({number}) is {fib(number)}')def fibs_no_threading(): print_fib(40) print_fib(41)start = time.time()fibs_no_threading()end = time.time()print(f'Completed in {end - start:.4f} seconds.')
这个实现使用递归,总体上是一个相对较慢的算法,需要指数级 O(2^N) 时间来完成。如果我们需要打印两个斐波那契数,很容易像我们前面的列表那样同步调用它们并计时结果。
根据运行代码的 CPU 速度,我们会看到不同的计时,但运行清单 1.5 的代码将产生类似以下的输出:
fib(40) is 63245986fib(41) is 102334155Completed in 65.1516 seconds.
这是一个相当长的计算,但我们对 print_fibs 的函数调用彼此独立。这意味着它们可以被放入多个线程中,我们的 CPU 理论上可以在多个核心上并发运行,从而加速我们的应用程序。
import threadingimport timedef print_fib(number: int) -> None: def fib(n: int) -> int: if n == 1: return 0 elif n == 2: return 1 else: return fib(n - 1) + fib(n - 2)def fibs_with_threads(): fortieth_thread = threading.Thread(target=print_fib, args=(40,)) forty_first_thread = threading.Thread(target=print_fib, args=(41,)) fortieth_thread.start() forty_first_thread.start() fortieth_thread.join() forty_first_thread.join()start_threads = time.time()fibs_with_threads()end_threads = time.time()print(f'Threads took {end_threads - start_threads:.4f} seconds.')
在前面的列表中,我们创建了两个线程,一个用于计算 fib(40),一个用于计算 fib(41),并通过在每个线程上调用 start() 同时启动它们。然后我们调用 join(),这将导致我们的主程序等待线程完成。考虑到我们同时开始计算 fib(40) 和 fib(41) 并并发运行它们,你会认为我们可以看到合理的加速;然而,即使在多核机器上,我们也会看到类似以下的输出:
fib(40) is 63245986fib(41) is 102334155Threads took 66.1059 seconds.
我们的线程版本几乎花了相同的时间。事实上,它甚至稍微慢了一点!这几乎完全归因于 GIL 以及创建和管理线程的开销。虽然线程确实是并发运行的,但由于锁的原因,一次只允许其中一个运行 Python 代码。这使另一个线程处于等待状态,直到第一个线程完成,这完全否定了多线程的价值。
基于前面的例子,您可能想知道,既然 GIL 阻止同时运行两行 Python 代码,那么 Python 中的并发是否永远无法通过线程发生。然而,GIL 并非永远持有,我们无法利用多线程发挥优势。
全局解释器锁在 I/O 操作发生时被释放。这使我们能够在涉及 I/O 时使用线程进行并发工作,但不适用于 CPU 密集型的 Python 代码本身(在某些情况下,有一些值得注意的例外会为 CPU 密集型工作释放 GIL,我们将在后面的章节中介绍这些情况)。为了说明这一点,让我们用一个读取网页状态码的例子。
import timeimport requestsdef read_example() -> None: response = requests.get('https:/ / www .example .com') print(response.status_code)sync_start = time.time()read_example()read_example()sync_end = time.time()print(f'Running synchronously took {sync_end - sync_start:.4f} seconds.')
在前面的列表中,我们检索 example.com 的内容并打印两次状态码。根据我们的网络连接速度和位置,运行此代码时我们将看到类似以下的输出:
200200Running synchronously took 0.2306 seconds.
现在我们有了同步版本的基准,我们可以编写一个多线程版本进行比较。在我们的多线程版本中,为了尝试并发运行它们,我们将为每个对 example.com 的请求创建一个线程。
import timeimport threadingimport requestsdef read_example() -> None: response = requests.get('https:/ / www .example .com') print(response.status_code)thread_1 = threading.Thread(target=read_example)thread_2 = threading.Thread(target=read_example)thread_start = time.time()thread_1.start()thread_2.start()print('All threads running!')thread_1.join()thread_2.join()thread_end = time.time()print(f'Running with threads took {thread_end - thread_start:.4f} seconds.')
当我们执行前面的列表时,将看到类似以下的输出,同样取决于我们的网络连接和位置:
All threads running!200200Running with threads took 0.0977 seconds.
这大约是我们原始未使用线程版本的两倍快,因为我们大致同时运行了两个请求!当然,根据您的互联网连接和机器规格,您会看到不同的结果,但数字应该方向相似。
那么,为什么我们可以在 I/O 时释放 GIL 而不能在 CPU 密集型操作时释放呢?答案在于后台进行的系统调用。在 I/O 的情况下,低级系统调用在 Python 运行时之外。这允许释放 GIL,因为它不直接与 Python 对象交互。在这种情况下,只有当接收到的数据被转换回 Python 对象时,GIL 才会被重新获取。然后,在操作系统层面,I/O 操作并发执行。这个模型给了我们并发性,但没有并行性。在其他语言中,如 Java 或 C++,我们将在多核机器上获得真正的并行性,因为我们没有 GIL,可以同时执行。然而,在 Python 中,由于 GIL,我们最多只能获得 I/O 操作的并发性,并且在给定时间只有一段 Python 代码在执行。
asyncio 利用 I/O 操作释放 GIL 这一事实,即使在只有一个线程的情况下也给我们提供了并发性。当我们利用 asyncio 时,我们创建称为协程的对象。协程可以被认为是执行一个轻量级线程。就像我们可以有多个线程同时运行,每个线程都有自己的并发 I/O 操作一样,我们可以有很多协程同时运行。在我们等待 I/O 密集型协程完成的同时,我们仍然可以执行其他 Python 代码,从而给我们并发性。重要的是要注意 asyncio 并没有绕过 GIL,我们仍然受其约束。如果我们有一个 CPU 密集型任务,我们仍然需要使用多个进程来并发执行它(这可以通过 asyncio 本身完成);否则,我们将导致应用程序出现性能问题。现在我们知道单线程实现 I/O 并发是可能的,让我们深入了解这是如何通过非阻塞套接字实现的。