「Python 深度学习」时间序列预测经典可视化——多模型预测效果对比(附完整代码)
今天为大家带来 Python 数据分析及可视化学习群的分享(近期会推出视频课程)——时间序列多模型预测效果对比图。
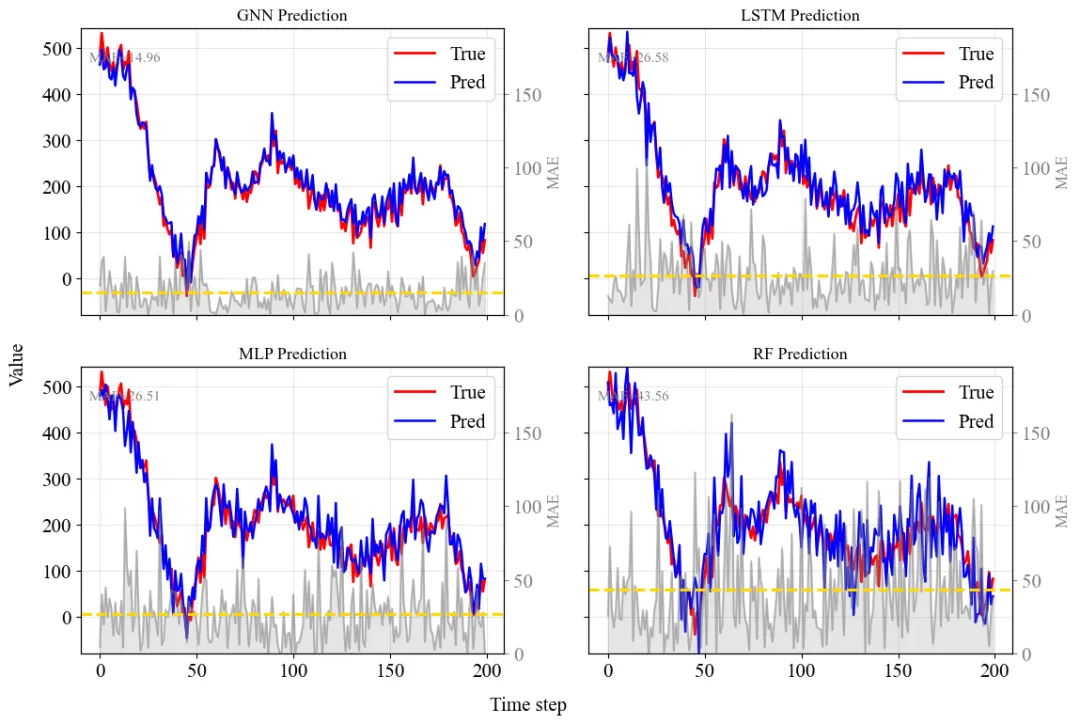
Case:“预测曲线 + 误差曲线(MAE)”,并做成 2×2 对比面板
这一节我们用一个完整案例,把两件事同时解决:
- 同一个子图的右轴:画 MAE(逐时刻绝对误差),并用阴影填充、再加一条 Mean MAE 的水平虚线
1)输入数据长什么样?我们需要哪些字段?
首先,分享给大家的数据是从 pickle 里读出来的:
df = pd.read_pickle(r"...\time_series.pickle")
对于这份可视化,我们实际只用到两列(外加索引):
df.index:时间索引(DatetimeIndex 或者其他索引都可以,但最好是时间)df["Pred_2"]:某一个模型的预测(这里作为基准:GNN 的预测)
也就是说,这张图的输入结构可以理解为:
请注意:后面为了演示“多模型对比”,没有真的训练 LSTM/MLP/RF,而是用“在 GNN 预测基础上加噪声”的方式模拟不同误差水平。
2)数据准备:真实值、预测值、多模型模拟
这一段是核心:把数据变成“画图可以直接用的一维数组”。
true = df['Site_2'].values
gnn_pred = df['Pred_2'].values
这里 .values 会拿到 numpy 数组,后面做误差和绘图更方便。
2.1 为什么要算 noise_scale?
noise_scale = np.std(true - gnn_pred)
true - gnn_pred 是“GNN 的误差序列”,它的标准差 std 表示“误差波动的典型尺度”。
- 如果
noise_scale 很小,说明 GNN 很准 - 如果
noise_scale 很大,说明误差整体比较大
这里主要是为了后面用不同倍数的 noise_scale 去生成其它模型的“假预测”,本质上就是:让 LSTM 比 GNN 稍差一点,MLP 再差一点,RF 最差。
mlp_pred = gnn_pred + np.random.normal(0, 1.5 * noise_scale, size=len(gnn_pred))
lstm_pred = gnn_pred + np.random.normal(0, 1.2 * noise_scale, size=len(gnn_pred))
rf_pred = gnn_pred + np.random.normal(0, 2.5 * noise_scale, size=len(gnn_pred))
你这里 np.random.seed(42) 是为了可复现——每次运行出来的曲线形状一致。
3)截取一段时间
n_points = 200
x = np.arange(n_points)
true_seg = true[:n_points]
在时序任务里,完整序列可能很长(几千甚至几万点),直接画全长会有两个问题:
所以通常会**截取一段“窗口”**来展示局部预测效果。取前 200 个点,就是一个典型的“展示窗口”。同时用 x = np.arange(n_points) 做横轴,这样横轴就是 0~199 的时间步编号,简单直观。
如果你后面想把横轴换成真实时间,也可以用:
plt_time = df.index[:n_points]
然后把 ax.plot(x, ...) 改成 ax.plot(plt_time, ...),并配合 matplotlib.dates 去格式化日期显示。
4)关键细节:统一四张子图的 y 轴范围(非常重要)
如果四张子图各自自动缩放 y 轴,会出现一种“视觉陷阱”:
- 某个模型误差很大,但它的 y 轴范围也被拉大了,看起来反而“没那么差”
- 某个模型误差很小,但 y 轴范围很窄,看起来“波动很剧烈”
所以这里做了两件事:
4.1 统一主轴(值)的 y 范围
y_min = min(true_seg.min(), *(p.min() for p in preds.values()))
y_max = max(true_seg.max(), *(p.max() for p in preds.values()))
这行代码的含义是:把 True 和四个 Pred 的最小/最大值都扫一遍,找全局 min/max,然后所有子图都用同一个范围。
4.2 统一右轴(MAE)的 y 范围
global_mae_max = max(np.abs(true_seg - p).max() for p in preds.values())
同样逻辑:先把所有模型在该窗口内的 MAE 最大值找出来,让所有 MAE 轴保持同一尺度。这样一眼就能比较“哪个模型误差整体更大”。
5)绘图布局:2×2 子图 + sharex/sharey
fig, axes = plt.subplots(2, 2, figsize=(12, 8), sharex=True, sharey=True)
axes = axes.flatten()
sharex/sharey=True:四张图共享同一横轴/左纵轴刻度(对比时更整齐)flatten():把 2×2 的 axes 变成一维数组,方便 for 循环配对模型
6)每个子图的绘制逻辑(重点)
你在循环里做了三层信息叠加:
6.1 主曲线:True(红)+ Pred(蓝)
ax.plot(x, true_seg, color='red', label='True', linewidth=2)
ax.plot(x, pred, color='blue', label='Pred', linewidth=1.8)
ax.set_ylim(y_min, y_max)
这里 True 线更粗一点,是为了强调“真实值是参照”。
6.2 同一子图的右轴:MAE 曲线 + 阴影 + Mean MAE 水平线
mae = np.abs(true_seg - pred)
mean_mae = mae.mean()
ax2 = ax.twinx()
ax2.plot(x, mae, color='gray', alpha=0.5, linewidth=1.5)
ax2.fill_between(x, 0, mae, color='gray', alpha=0.2)
ax2.axhline(mean_mae, color='gold', linestyle='--', linewidth=2.2, label='Mean MAE')
ax2.set_ylim(0, global_mae_max * 1.2)
这里的设计非常值得在课上讲清楚:
np.abs(true_seg - pred):逐点绝对误差(MAE 的“序列形式”)ax.twinx():创建一个共享 x 轴、但右侧有自己 y 轴的坐标系
这能解决一个经典问题:Pred/True 的数值范围和MAE 的范围往往不同,硬塞在一个 y 轴上会很难看。fill_between:把误差面积填充出来,你的读者会立刻理解“误差像一层灰色阴影覆盖在上面”axhline(mean_mae):一条平均误差水平线,读者不用计算,也能一眼比较四个模型的平均表现
这里还做了细节的美化:
ax2.set_ylabel("MAE", color='gray', fontsize=12)
ax2.tick_params(axis='y', colors='gray')
ax2.yaxis.label.set_color('gray')
右轴统一灰色系,让它“辅助信息”的视觉权重低于主曲线。
6.3 平均 MAE 数字标注
ax.text(0.02, 0.92, f"MAE={mean_mae:.2f}", transform=ax.transAxes,
fontsize=11, color='gray', ha='left', va='top')
这里 transform=ax.transAxes 是关键:
(0.02, 0.92) 永远表示“靠左上角一点点”
7)字体与中英混排:Times New Roman + SimSun
设置全局 rcParams:
plt.rcParams.update({
'font.size': 15,
'font.family': ['Times New Roman', 'SimSun']
})
这在中文技术文章/学术作图里很实用:
- 中文自动 fallback 到 宋体 SimSun
8)全局标签、tight_layout 与保存高清图
没有在每个子图单独写 x/y label,而是用全局标签(更整洁):
fig.text(0.5, 0.04, "Time step", ha='center', fontsize=15)
fig.text(0.04, 0.5, "Value", va='center', rotation='vertical', fontsize=15)
再用:
plt.tight_layout(rect=[0.05, 0.05, 1, 1])
plt.savefig('save.png', dpi=300, bbox_inches='tight')
这里有两个关键点:
tight_layout:防止子图标题、刻度、图例挤在一起bbox_inches='tight':保存时自动裁掉多余空白边缘
9)最终整理版代码
👇扫码关注Python深度学习&图神经网络&物理信息神经网络专项学习群👇
👇免费加群,每周都有【Python深度学习】免费公开课程👇
| 微信(ILoveHF2016) | QQ(1061241906) |
| |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# --------------------------
# 0) 全局字体设置(中英混排)
# --------------------------
plt.rcParams.update({
'font.size': 15,
'font.family': ['Times New Roman', 'SimSun']
})
# --------------------------
# 1) 数据准备:真实值 + 基准预测(GNN)
# --------------------------
true = df['Site_2'].values
gnn_pred = df['Pred_2'].values
# 用 GNN 的误差尺度来模拟其它模型的预测误差(教学用)
np.random.seed(42)
noise_scale = np.std(true - gnn_pred)
mlp_pred = gnn_pred + np.random.normal(0, 1.5 * noise_scale, size=len(gnn_pred))
lstm_pred = gnn_pred + np.random.normal(0, 1.2 * noise_scale, size=len(gnn_pred))
rf_pred = gnn_pred + np.random.normal(0, 2.5 * noise_scale, size=len(gnn_pred))
# --------------------------
# 2) 截取一个窗口(避免全序列太密)
# --------------------------
n_points = 200
x = np.arange(n_points)
true_seg = true[:n_points]
preds = {
"GNN": gnn_pred[:n_points],
"LSTM": lstm_pred[:n_points],
"MLP": mlp_pred[:n_points],
"RF": rf_pred[:n_points],
}
# --------------------------
# 3) 统一四张图的范围(对比才公平)
# --------------------------
y_min = min(true_seg.min(), *(p.min() for p in preds.values()))
y_max = max(true_seg.max(), *(p.max() for p in preds.values()))
global_mae_max = max(np.abs(true_seg - p).max() for p in preds.values())
# --------------------------
# 4) 2×2 面板绘图
# --------------------------
fig, axes = plt.subplots(2, 2, figsize=(12, 8), sharex=True, sharey=True)
axes = axes.flatten()
for ax, (model_name, pred) in zip(axes, preds.items()):
# 4.1 主轴:True vs Pred
ax.plot(x, true_seg, color='red', label='True', linewidth=2)
ax.plot(x, pred, color='blue', label='Pred', linewidth=1.8)
ax.set_ylim(y_min, y_max)
# 4.2 右轴:MAE 序列 + 阴影 + Mean MAE
mae = np.abs(true_seg - pred)
mean_mae = mae.mean()
ax2 = ax.twinx()
ax2.plot(x, mae, color='gray', alpha=0.5, linewidth=1.5)
ax2.fill_between(x, 0, mae, color='gray', alpha=0.2)
ax2.axhline(mean_mae, color='gold', linestyle='--', linewidth=2.2)
ax2.set_ylim(0, global_mae_max * 1.2)
ax2.set_ylabel("MAE", color='gray', fontsize=12)
ax2.tick_params(axis='y', colors='gray')
# 4.3 子图标注:平均 MAE 数值(轴坐标系比例定位,不会跑)
ax.text(0.02, 0.92, f"MAE={mean_mae:.2f}",
transform=ax.transAxes, fontsize=11,
color='gray', ha='left', va='top')
# 4.4 标题、图例、网格
ax.set_title(f"{model_name} Prediction", fontsize=13)
ax.legend(loc='upper right')
ax.grid(alpha=0.3)
# --------------------------
# 5) 全局标签 + 保存高清图
# --------------------------
fig.text(0.5, 0.04, "Time step", ha='center', fontsize=15)
fig.text(0.04, 0.5, "Value", va='center', rotation='vertical', fontsize=15)
plt.tight_layout(rect=[0.05, 0.05, 1, 1])
plt.savefig("save.png", dpi=300, bbox_inches='tight')