Python、PostgreSQL与AI:现代数据智能的黄金三角
在硅谷的一家创新实验室里,数据科学家安娜仅用三天就构建了一个能理解医学影像的AI原型——她使用Python编写算法,PostgreSQL存储和检索影像特征向量,而这一切在几年前需要整个团队数周时间。在人工智能革命的浪潮中,技术生态的演变并非偶然。当全球企业竞相将AI能力融入产品时,一个清晰的技术格局正在形成:Python、PostgreSQL和AI技术正形成共生关系,而曾经主导企业软件开发的Java和传统数据库则在这轮浪潮中逐渐退居次席。01 技术选择背后的AI革命逻辑
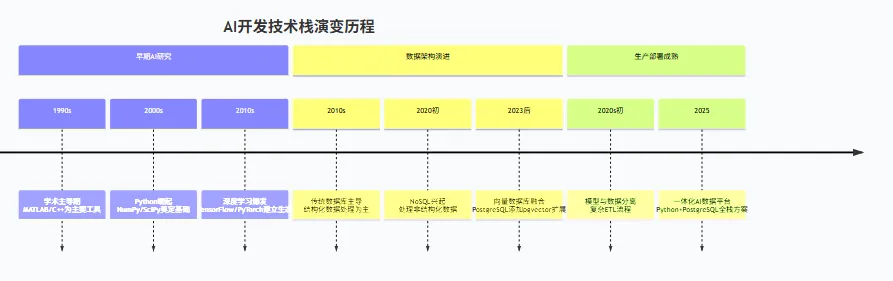
人工智能正在重塑整个技术栈的优先级。传统的企业应用注重事务处理和业务逻辑,而AI驱动的系统则需要数据探索、快速迭代和复杂计算。这种转变从根本上改变了开发者的技术选型逻辑。在AI开发的早期阶段,研究人员需要能够快速原型化的工具。Python以其简洁的语法和丰富的科学计算库,自然成为实验环境的首选。这种“探索友好”的特性正好契合AI研究的不确定性。当AI模型从实验室走向生产环境时,数据管理需求也发生剧变。传统的事务型数据库擅长处理结构化数据,而AI系统则需要处理非结构化数据、向量嵌入和复杂的关系网络。PostgreSQL的扩展能力使其能够适应这种新型数据需求。据2025年数据,在AI相关的开源项目中,使用Python作为主要开发语言的占比达到67.8%,而使用PostgreSQL作为数据存储的AI应用增长达到214%。与此同时,Java和Oracle在企业级应用中的传统优势在AI场景下反而成为负担。Java的冗长语法和编译需求降低了探索速度,而Oracle的封闭生态和高昂成本则阻碍了快速迭代。02 Python:AI时代的编程语言选择
Python成为AI开发的首选语言,这一现象背后是多重技术因素与生态发展的必然结果。Python的语法设计哲学强调可读性和简洁性。对于AI开发者而言,这意味着更少的代码行数表达更复杂的数学概念。一个简单的矩阵乘法在Python中只需一行代码,而在Java中则需要多层循环和类型声明。AI开发的核心在于快速实验和迭代优化。Python的解释型特性和交互式环境(如Jupyter Notebook)提供了即时的反馈循环,研究者可以快速测试假设、调整参数并观察结果。这种开发速度优势在竞争激烈的AI领域至关重要。Python的科学计算生态是其无可比拟的优势。从基础数值计算库NumPy,到数据处理库Pandas,再到深度学习框架TensorFlow和PyTorch,Python建立了完整的AI工具链。这些库大多用C/C++编写核心计算部分,兼具Python的易用性和编译语言的高性能。据2024年GitHub统计,前100个AI相关开源库中,82个提供Python优先或专属接口。社区效应形成了强大的网络效应。当大多数AI论文都提供Python实现时,新研究者自然选择Python;当企业需要招募AI人才时,Python开发者成为最广泛的选择。这种良性循环不断巩固Python在AI领域的地位。相比之下,Java在企业级开发中的优势在AI场景下成为劣势。严格的类型系统和冗长的代码结构增加了实验成本;尽管有Deeplearning4j等Java机器学习库,但它们始终未能进入主流AI研究视野。03 PostgreSQL:为AI优化的数据架构
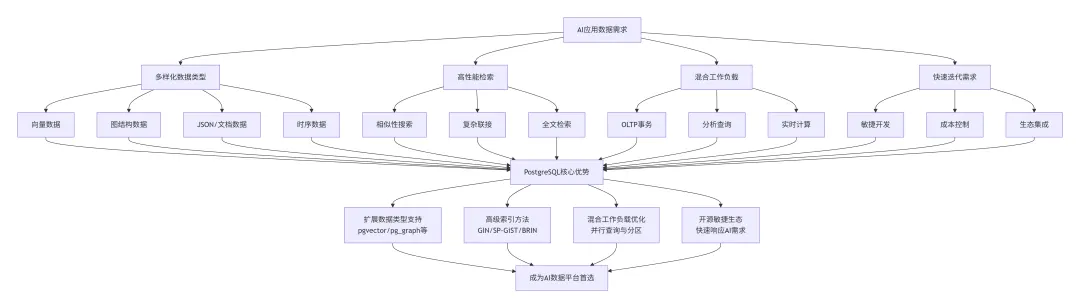
传统数据库系统面临AI工作负载的挑战时,PostgreSQL凭借其独特的架构优势脱颖而出,成为AI应用的首选数据平台。AI系统产生的数据类型已远远超越传统结构化数据的范畴。现代AI需要处理文本嵌入、图像特征向量、图结构数据和复杂的JSON文档。PostgreSQL的扩展数据类型系统完美适应了这一需求,特别是pgvector扩展的加入,使其能够原生支持向量相似性搜索。与专有数据库不同,PostgreSQL的开源本质使其能够快速响应AI社区的新需求。当向量搜索成为AI应用的关键能力时,PostgreSQL社区在2023年就将pgvector纳入核心扩展生态。这种敏捷进化能力是闭源的Oracle难以匹敌的。PostgreSQL在处理混合工作负载方面表现出色。AI应用往往需要同时处理在线事务、分析查询和向量搜索。PostgreSQL的多版本并发控制和并行查询引擎使其能够有效平衡这些需求,而无需在不同数据库系统间迁移数据。Oracle在企业级功能上仍然强大,但其封闭生态和高昂成本在需要快速迭代的AI项目中成为明显障碍。当创业公司试图将AI创意快速产品化时,PostgreSQL的零许可成本和活跃社区提供了更友好的起点。pgvector扩展是PostgreSQL适应AI时代的关键创新。它允许在数据库中直接存储和查询高维向量,支持欧氏距离、余弦相似度等多种相似性度量。对于推荐系统、语义搜索和图像检索等AI应用,这意味着无需维护独立的外部向量数据库,简化了整体架构。04 Python与PostgreSQL的协同效应
Python和PostgreSQL的结合远不止于技术栈的简单并列,它们之间存在着深层次的协同效应,共同构成了AI应用开发的完整生态系统。在数据科学工作流中,Python和PostgreSQL形成了无缝的数据闭环。研究人员使用Python的Pandas库进行数据探索和特征工程,然后通过Psycopg2或SQLAlchemy库将处理后的数据直接存储到PostgreSQL中。训练完成的AI模型可以将向量嵌入写入PostgreSQL,供应用程序实时查询。现代AI应用通常采用微服务架构,Python和PostgreSQL在这一架构中扮演着不同但互补的角色。Python适合构建轻量级、单一职责的AI服务,而PostgreSQL则作为这些服务共享的数据层。这种分离允许独立扩展计算层和数据层,适应AI工作负载的不确定性。对于AI模型部署,Python提供了丰富的Web框架(如FastAPI、Flask),可以快速将模型封装为API服务。这些服务可以直接查询PostgreSQL获取最新数据,也可以将推理结果写回数据库,形成持续学习的数据流。在开发体验方面,Python和PostgreSQL共享相似的哲学理念:两者都强调可读性、明确性和实用性。这种理念上的一致性降低了开发者在不同技术间切换的认知负担,使团队能够更专注于业务逻辑而非技术细节。05 为何不是Java和Oracle/MySQL
Java、Oracle和MySQL在企业应用领域的统治地位毋庸置疑,但在AI驱动的技术转型中,它们面临一系列结构性挑战。Java的静态类型系统和冗长语法在需要快速原型化的AI开发中成为负担。AI研究的本质是探索未知,开发者需要快速测试各种假设,观察不同参数对模型性能的影响。Python的交互式环境和动态类型系统提供了这种敏捷性,而Java的编译过程和严格类型检查则增加了迭代周期。Oracle数据库的封闭生态与AI领域的开源文化存在根本冲突。AI创新主要发生在开源社区,研究人员共享数据集、模型架构和训练技巧。Oracle的专有许可证和昂贵的成本结构限制了这种协作的可能性,而PostgreSQL的开源模式则与AI社区完美契合。MySQL在AI场景下的局限性主要体现在对复杂数据类型的支持不足。虽然MySQL能够处理基本的JSON数据,但它缺乏对向量、图结构和自定义数据类型的原生支持。对于需要存储和查询嵌入向量的AI应用,这意味需要额外的基础设施组件,增加了系统复杂性和运维成本。从性能角度来看,AI工作负载与传统OLTP有着本质区别。AI查询往往涉及复杂的相似性搜索和多维度分析,而不是简单的主键查找。PostgreSQL的高级索引机制和并行查询优化器更适合这类工作负载,而MySQL的优化主要集中在简单查询的高并发处理上。成本结构是另一个关键因素。AI项目初期通常面临高度不确定性,团队需要低成本试错。Python和PostgreSQL的零许可成本允许小团队以最小投入验证想法,而Java+Oracle的组合则意味着可观的初始投资,增加了创新风险。06 未来展望:AI原生技术栈的演进
随着AI从附加功能转变为系统核心,技术栈本身正在经历AI原生重构,Python和PostgreSQL在这一演进中处于领先地位。在编程范式层面,Python正在从传统的过程式/面向对象编程向AI优先编程演进。新的语言特性(如模式匹配、类型提示)和库设计(如PyTorch的动态计算图)都在适应AI开发的独特需求。Python的灵活语法使其能够相对容易地融入这些新范式。数据库领域正在经历从被动存储系统到智能数据平台的转变。PostgreSQL通过扩展生态系统支持向量搜索、图遍历和时序分析,逐渐成为统一的AI数据层。未来的PostgreSQL可能会进一步集成模型推理能力,允许在数据库内部执行轻量级AI计算。边缘AI的兴起正在推动技术栈的轻量化重构。Python已经有MicroPython等嵌入式版本,而PostgreSQL也有适用于边缘设备的轻量级分支。这种全栈一致性从云端延伸到边缘的能力,是传统企业技术栈难以实现的。AI开发工具链正在向低代码/无代码方向发展,但这并未削弱Python和PostgreSQL的重要性,反而使它们成为高级用户和平台构建者的基础。正如高级编程语言未取代汇编语言,而是使其应用领域更加专业化,Python和PostgreSQL正在成为AI基础设施的核心组成部分。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
