Python操作Excel|Part 10: 内容一键映射修正
- 2026-07-02 17:50:24
Python操作Excel|Part 10: 内容一键映射修正*这篇文章其实是对Part3第一、二部分的一个简化,当时写python还非常的C语言,写的非常繁冗,现在这个方法感觉就很“轻巧”
目录 1. 内容完整替换 2. 内容部分替换 3. 补充:.items/.replace/数组和series
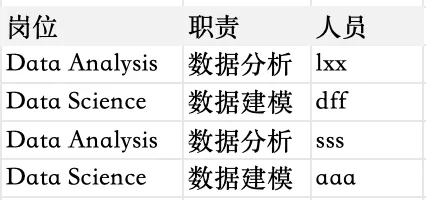
列名一键映射(完整字段映射) 我们经常会遇到取下来的列明和目标列明不一样的情况,而且不想手动一个个修改,就可以使用字典进行映射 读取excel,得到原来的数据样子:
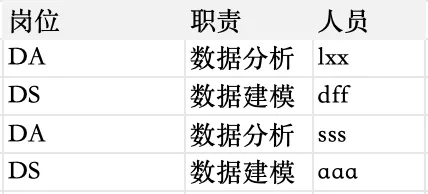
import pandas as pd # 导入必要库# 读取我们的表格df = pd.read_excel("/Users/Documents/月报/人力数据.xlsx")# 假设我们想要修改“岗位”这一列,把里面所有的全称替换成缩写# 根据需求创建字典mapping = { # 冒号前面是原来的内容,冒号后面是想要修改成的内容"Data Analysis": "DA", # 两个对应关系之间一定要加逗号!"Data Science": "DS"}# 为了确保数据不存在格式问题,先统一变成字符串df["岗位"] = df["岗位"].astype(str)# 现在就可以一键替换了# 对着列中的每一个内容(单元格),进行map行为,依据上面的mapping字典df["岗位"] = df["岗位"].map(lambda x: mapping.get(x, x))
处理后的数据:
列名一键映射(部分字段映射) 此时如果这一列中除了岗位信息还有别的信息,例如负责人名字,而我们只想对岗位进行缩写,就不能简单用.map进行一键操作 例如数据修正前样子为: 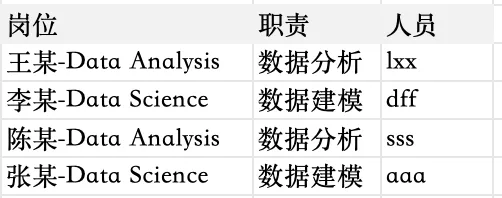
这时候,如果用字典.map一键匹配,他是无法识别的,例如第一行是“王某-Data Analysis”而不是“Data Analysis”,所以电脑并不认为这对应mapping字典的键(冒号前的内容),从而导致.map失效。
# 前半部分和上面一样import pandas as pddf = pd.read_excel("/Users/Documents/月报/人力数据.xlsx")mapping = {"Data Analysis": "DA", # 每个对应关系之间一定要加逗号!"Data Science": "DS" # 可以继续添加对应关系,记得加逗号!}# ————————这里开始和上面不一样了————————for k, v in mapping.items(): # 这时候k和v会依次循环mapping中的键和值# 第一个循环里,k = "Data Analysis" ; v = "DA"# 第二个循环里,k = "Data Science" ; v = "DS"# 我们的mapping只有两组数据,所以只有两个循环# 可以添加下面三行代码自行查看每一轮k和v都是什么(选中下面三行,按command+/)# print(k)# print(v)# print("_____") # 用来分隔一下每一轮的输出df["岗位"] = df["岗位"].str.replace(k, v, regex=False)# 这里 df["岗位"]是一个series类型,不能直接使用.replace# 只有字符串可以直接使用.replace# 所以.str是告诉电脑,这个series是含有多个字符串的,对其中每一个字符串进行操作# 这样就可以用.replace了(操作对象变成了字符串)
.replace(k, v)就是把字符串里的k部分替换成v部分,regex = False是避免前面的k或者v被识别成正则表达式(这里先不说正则表达式是什么了,如果想了解的话,随便一搜就有),总之是确保,我们就是把k替换成v 那么这样一来,就会得到: 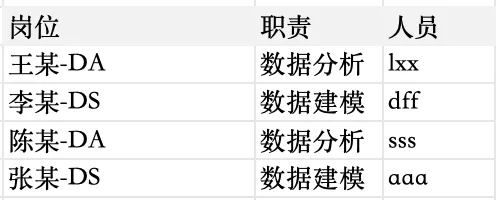
补充 关于.items()
因为我们的字典是“键”:“值”的形式,只有两部分,所以.items()之后,会变成二元组,每一个二元组有2个元素 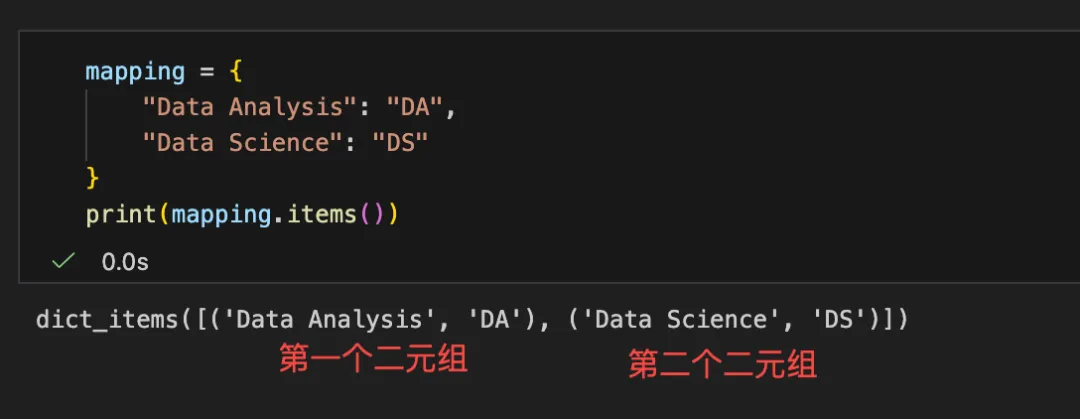
然后我们去循环输出每一个二元组 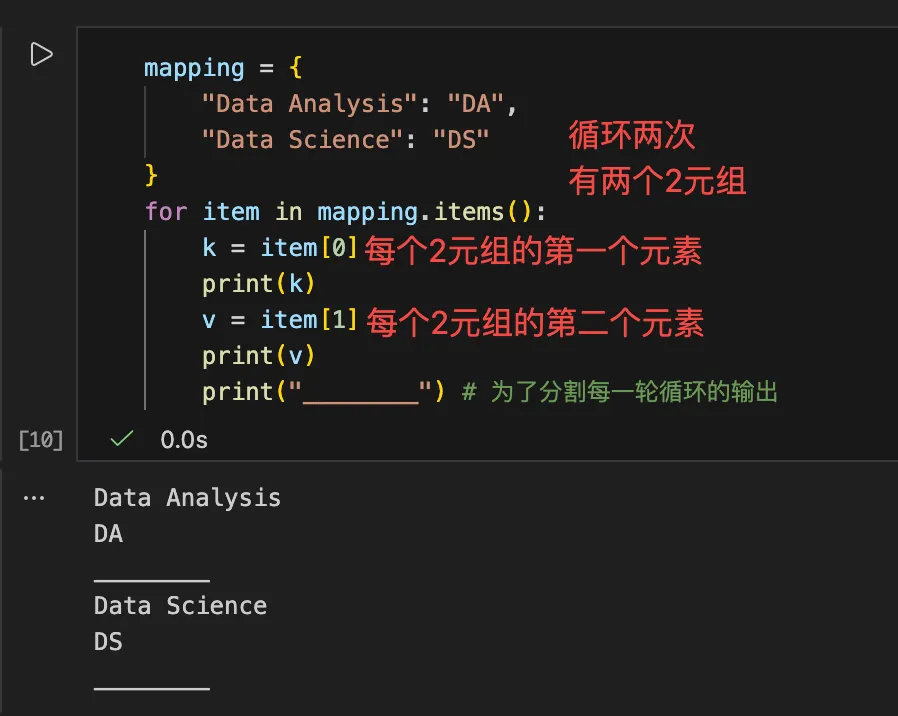
关于.replace的实验 如果我们想要对a进行替换,需要给他赋值给另一个变量,否则a本身不会变的 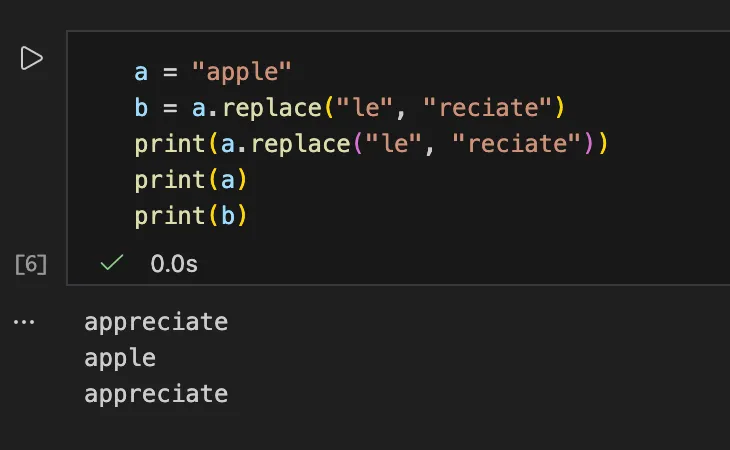
这里a是字符串(str),而我们通常操作的是excel的某一列,是series,所以需要.str,表示:要操作这一列的每一个元素,并且把每一个元素都当成字符串str。也就是把这一列当成了一个每一个元素都是字符串的数组(array)。
关于数组和series 本质上只是python中的两种数据类型,可以用type(a),查看数据类型 【个人理解】series已经有了一定的表结构,可以设置索引,可以按照“列”去处理;array数组就还是一堆个体放在了一起,所以只能对里面的个体进行某种处理 现在AI非常发达,其实从应用层面已经不需要非常的了解他们之间的区别,只是在快速想要完成某种实践任务的时候,能够注意到他们是不同的从而使用对应方法进行应用就可以了。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

