01 性能优化的“救火”时刻:当告警变成噩梦
“服务器又卡了!”业务团队在群里疯狂@运维。你急忙登录机器,面对一系列复杂问题:系统负载居高不下,但top命令显示CPU空闲率还有40%;磁盘I/O似乎正常,但应用日志不断报超时错误;内存显示充足,却频繁触发OOM Killer。
这种场景下,盲目重启服务可能暂时缓解症状,但问题根源依然存在,随时可能再次爆发。真正的解决方案需要系统性方法和精准工具。
02 性能分析黄金法则:找到真正瓶颈
性能优化首要原则:先测量,后优化。错误的优化方向比不优化更糟糕。
Linux性能大师Brendan Gregg提出的USE方法论(Utilization、Saturation、Errors)是排查性能问题的黄金标准:
使用率:资源忙于工作的百分比
饱和度:资源排队工作的程度
错误:错误事件的数量
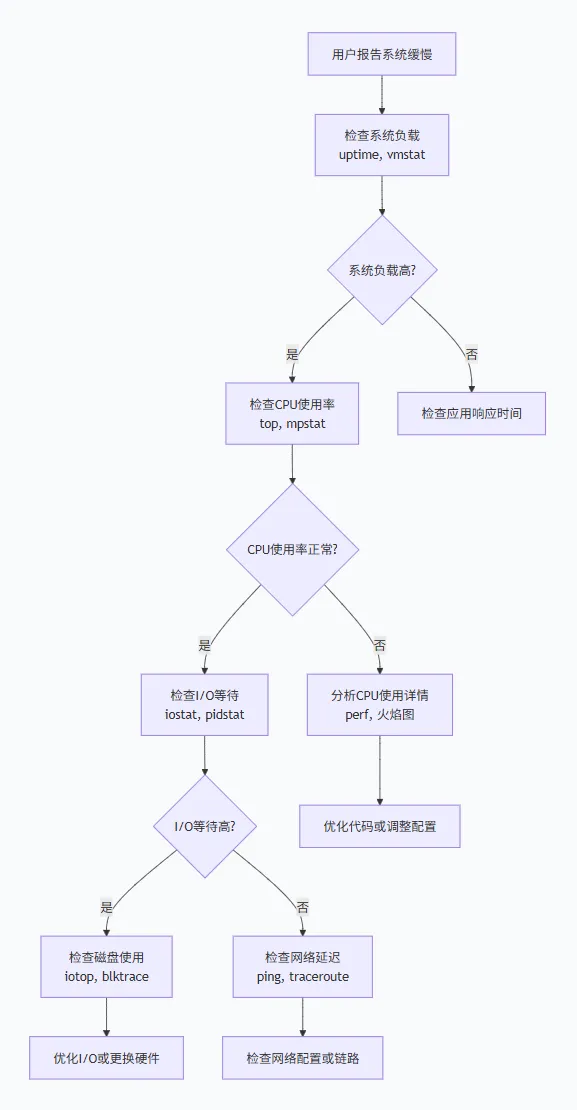
下面是性能问题排查路线图:
03 CPU性能优化:找出隐藏的“吃资源怪兽”
CPU性能问题常常表现为系统响应缓慢,但top命令可能显示CPU使用率并不高。这时候需要深入分析:
识别CPU瓶颈的关键命令:
CPU性能优化实战案例:
某电商网站在大促期间,虽然CPU总体使用率只有60%,但业务响应时间却大幅增加。通过perf工具生成火焰图分析,发现一个商品推荐算法存在大量不必要的序列化操作:
优化措施:
减少不必要的JSON序列化
缓存频繁计算的商品推荐结果
将同步调用改为异步处理
优化后,CPU使用率降低15%,P99响应时间从800ms降至200ms。
04 内存优化:告别OOM Killer的随机杀戮
内存问题往往比CPU问题更隐蔽,常见的现象是应用运行一段时间后突然崩溃,系统日志中出现Out of memory: Kill process。
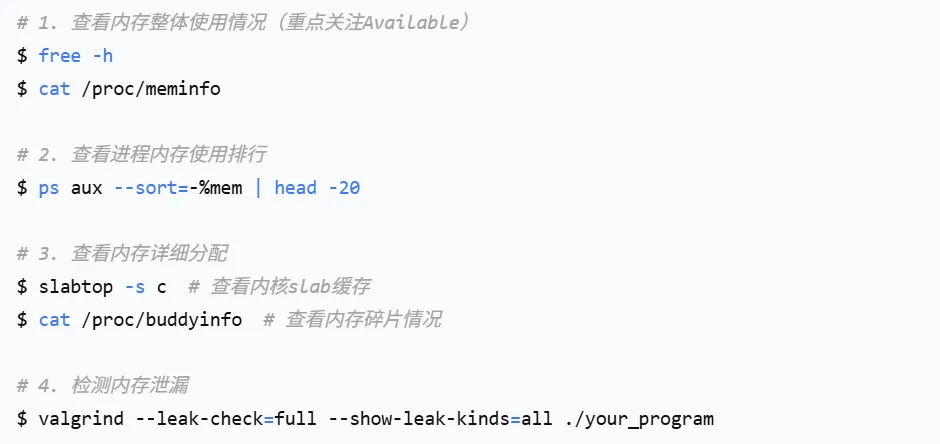
内存分析命令集:
内存优化实战:Java应用内存泄漏排查
某Java应用每隔一周就会因OOM崩溃一次。排查步骤:
1.开启GC日志分析:
2.使用jmap分析堆内存:
3.使用MAT或VisualVM分析堆转储文件,发现一个静态Map不断增长未清理,修复后应用稳定运行超过30天。
05 磁盘I/O优化:解决“存储瓶颈”
磁盘I/O问题通常表现为应用响应时间不稳定,尤其是数据库操作和文件读写密集型应用。
I/O性能分析工具箱:
SSD优化实战配置:
针对NVMe SSD的优化配置:
06 网络优化:减少“网络延迟”的隐形消耗
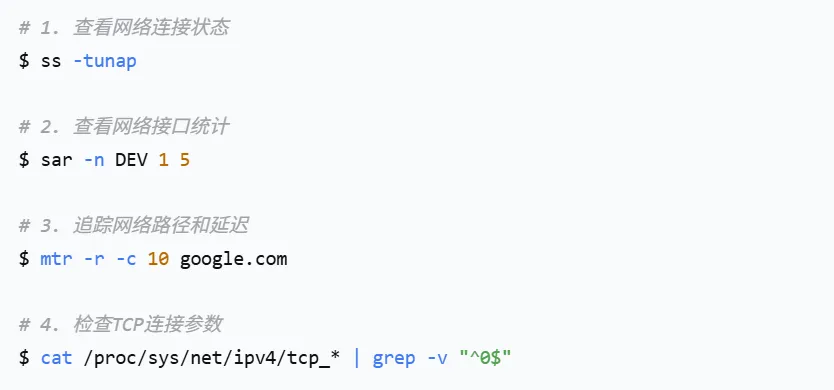
网络问题常常被误判为应用或数据库问题,特别是在微服务架构中。
网络性能诊断命令:
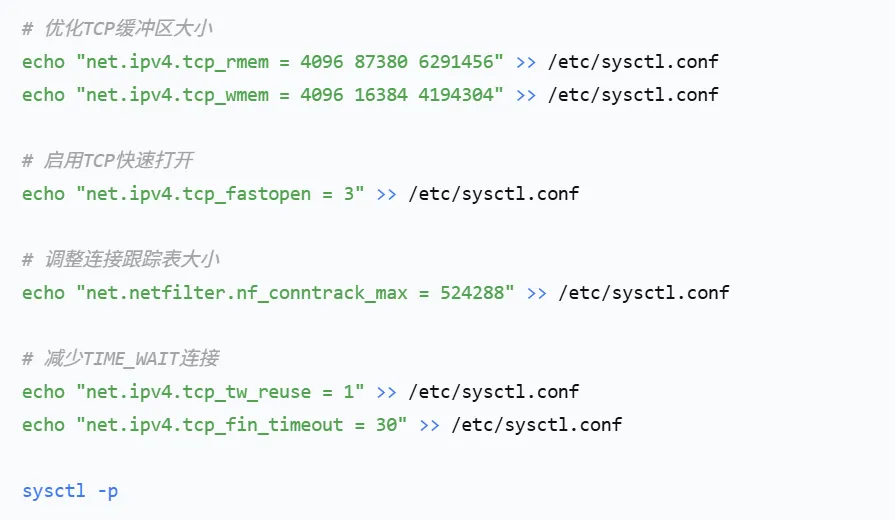
TCP优化实战配置:
针对高并发Web服务的TCP优化:
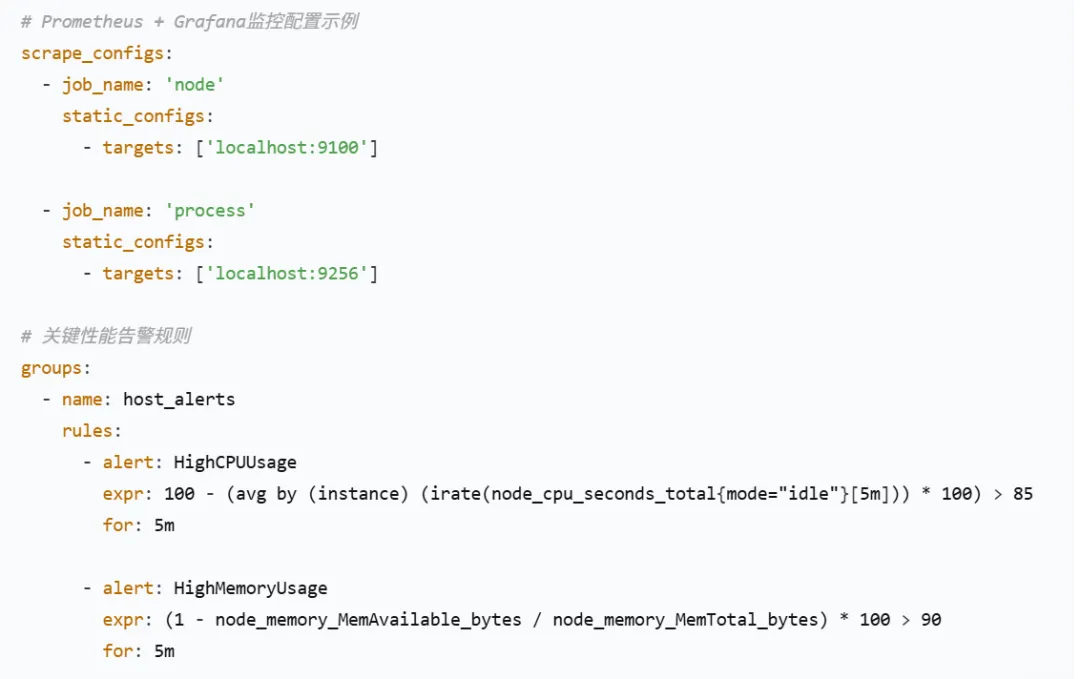
07 高级工具与自动化:构建性能监控体系
性能监控平台建设:
自动化性能巡检脚本:
08 性能优化文化:从救火到防火的转变
建立性能基线:
记录正常业务时段的性能指标作为基准
建立性能测试环境,每次发布前进行压测
制定性能验收标准,不达标不允许上线
性能优化流程化:
监控发现:通过监控系统自动发现性能异常
问题分类:确定是CPU、内存、I/O还是网络问题
根因分析:使用对应工具深入分析
解决方案:制定并实施优化方案
效果验证:验证优化效果,更新性能基线
持续优化文化:
定期进行性能复盘会议
建立性能知识库,积累优化经验
将性能指标纳入团队KPI考核
性能优化不是一次性的任务,而是需要持续投入的工程实践。当你的团队能够从被动“救火”转向主动“防火”时,才能真正掌控系统的性能命脉。