高维气象数据处理中,我们通常面对一个问题,比如集合成员数量不统一、不同来源数据的维度不相同、数据集没有按照升序排列……
这些问题虽然解决起来不麻烦,但是却非常关键,尤其是当我们提取数据进行深度学习或者统计建模的时候,我们通常会使用数组进行运算,这就对坐标对齐有非常严格的要求,本期我们就来看看一些常见的基本操作。
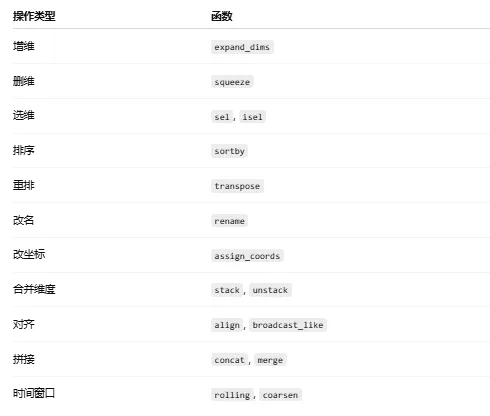
xarray 在「维度变换」这块设计得非常优雅,基本可以概括为 增 / 删 / 换 / 并 / 拆 / 叠 / 展 / 对齐 八大类。
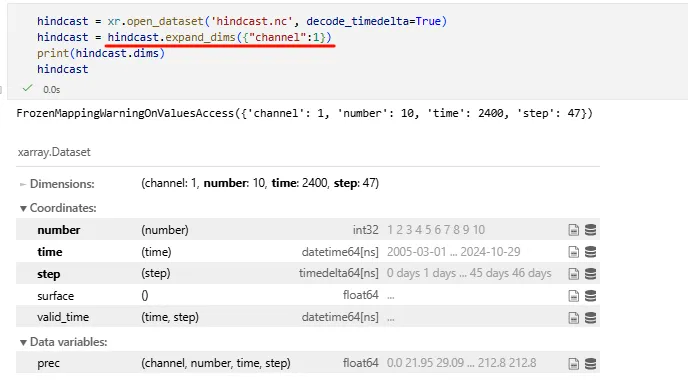
作用:给 Dataset / DataArray 增加一个长度为 1 的新维度
da2 = da.expand_dims('time')
或指定位置 / 坐标:
da2 = da.expand_dims(time=[pd.Timestamp("2020-01-01")])
常见用途:
构造 batch / ensemble 维度
单时次样本 → 时间序列
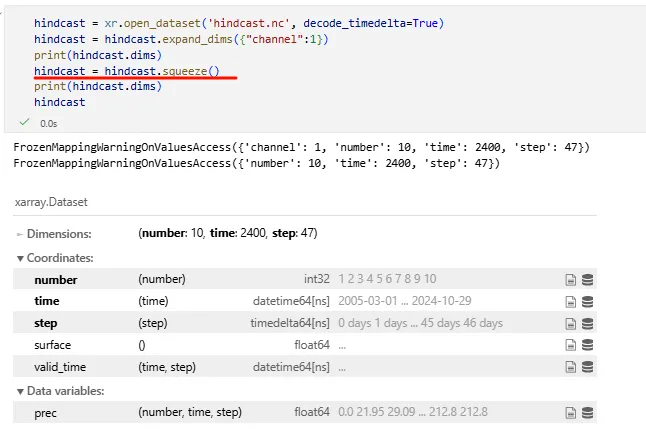
2️⃣ squeeze —— 删除长度为 1 的维度
作用:去掉 size=1 的维度
3️⃣ sel —— 按坐标值选
da_sel = da.sel(time="2020-06-01")da_sel = da.sel(time=slice("2020-06", "2020-08"))
支持条件:
da_sel = da.sel(time=da.time.dt.month.isin([6,7,8]))
最常用函数,没有之一
4️⃣ isel —— 按索引位置选
da_isel = da.isel(time=0)da_isel = da.isel(step=slice(0,10))
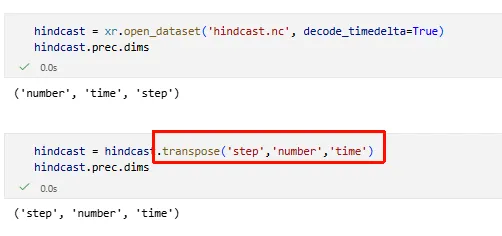
5️⃣ transpose —— 改变维度顺序
da2 = da.transpose('time', 'lat', 'lon')
DL / torch 前常用(通道顺序)
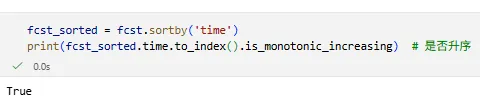
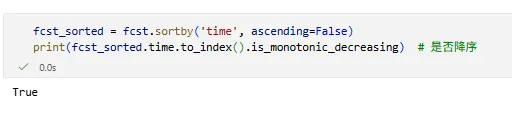
6️⃣ sortby —— 按坐标排序
da_sorted = da.sortby('time')da_sorted = da.sortby('time', ascending=False)
时间维度强烈建议 concat 后排序
7️⃣ rename —— 重命名维度 / 变量
da2 = da.rename({'latitude': 'lat', 'longitude': 'lon'})
8️⃣ assign_coords —— 替换 / 新增坐标
da2 = da.assign_coords(time=new_time)
9️⃣ stack —— 多维 → 一维
da_stack = da.stack(sample=('time', 'step'))
DL 样本构建神器:
(time, step, lat, lon) → (sample, lat, lon)
10 unstack —— 一维 → 多维
da_unstack = da_stack.unstack('sample')
与 stack 成对使用
11 broadcast_like —— 广播对齐
da2 = da1.broadcast_like(da_ref)
12 align —— 多对象对齐
da1a, da2a = xr.align(da1, da2, join='inner')
join 可选:
'inner'
'outer'
'left'
'right'
多模式、多数据源必用
13 concat —— 沿维度拼接
ds = xr.concat([ds1, ds2], dim='time')
hindcast + forecast 标配操作
14 merge —— 按变量合并
ds = xr.merge([ds1, ds2])
多物理量合并(降水 + 温度)
15 rolling —— 滑动窗口
da_roll = da.rolling(time=7).sum()
16 coarsen —— 降采样
da_week = da.coarsen(time=7).sum()
日 → 周 / 月非常好用
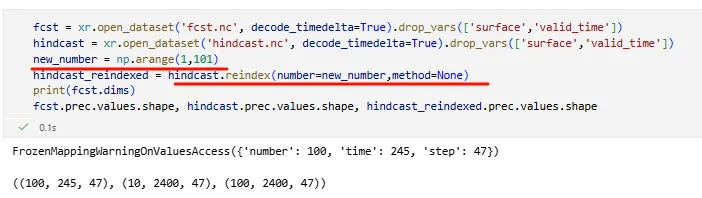
假设你有两个集合预报数据,但是它们的成员数量不相同,你需要统一到最大成员数量。已知fcst成员数量更多,为100个,后者为10个,目的就是把10扩充到100.
检查是不是相同的number维度上数据依然相等
np.all(np.isclose(hindcast.prec.values,hindcast_reindexed.prec.values[:10,:,:]))
True,说明扩充前后相同成员数据依然是相等的
对于深度学习来说,该操作比较常用