Python学习
一、学前花絮
AI大模型(Large AI Models),尤其是大语言模型(LLMs),是近年来人工智能领域最具革命性的技术突破之一。它们不仅重塑了人机交互方式,也正在深刻改变科研、产业与社会的运行逻辑。
我们一直在说学习python是为了解决实际问题,那么在AI大模型时代,如何以python入局深入了解AI大模型,本文将进行详细介绍。
二、AI大模型是什么?并以python入局了解大模型
2.1 什么是AI大模型?
AI大模型是指参数量巨大(通常在十亿至万亿级别)的深度神经网络模型,通过在海量无标注数据上进行预训练,获得强大的通用理解与生成能力。
典型代表:GPT系列(OpenAI)、PaLM(Google)、LLaMA(Meta)、通义千问Qwen(阿里)、DeepSeek(深度求索)。
核心特征:
l规模效应:参数越多,能力越强(遵循“Scaling Law”)。
l涌现能力(Emergent Abilities):当模型超过某一临界规模后,会自发产生未显式训练的能力(如推理、代码生成)。
l多模态融合:不仅能处理文本,还能理解图像、音频、视频(如GPT-4V、Gemini)。
简单比喻:大模型就像一个“数字大脑”,通过阅读互联网上的几乎所有公开文本,学会了人类的语言模式、知识结构甚至创作风格。
核心技术支柱:

2.2 如何以python入局大模型并示例
Python 是构建、训练、部署和应用 AI 大模型的“通用语言”和核心工具链。
2.2.1 Python 成为大模型的“首选语言”

即使像 Meta 的 LLaMA、Google 的 Gemma 这类闭源模型,其推理、微调、评估接口也优先提供 Python SDK(Python软件开发工具包)。
阶段 1:使用现有大模型 API(零门槛)
目标:快速体验大模型能力,构建应用原型
示例:用 OpenAI API 写一个智能问答机器人
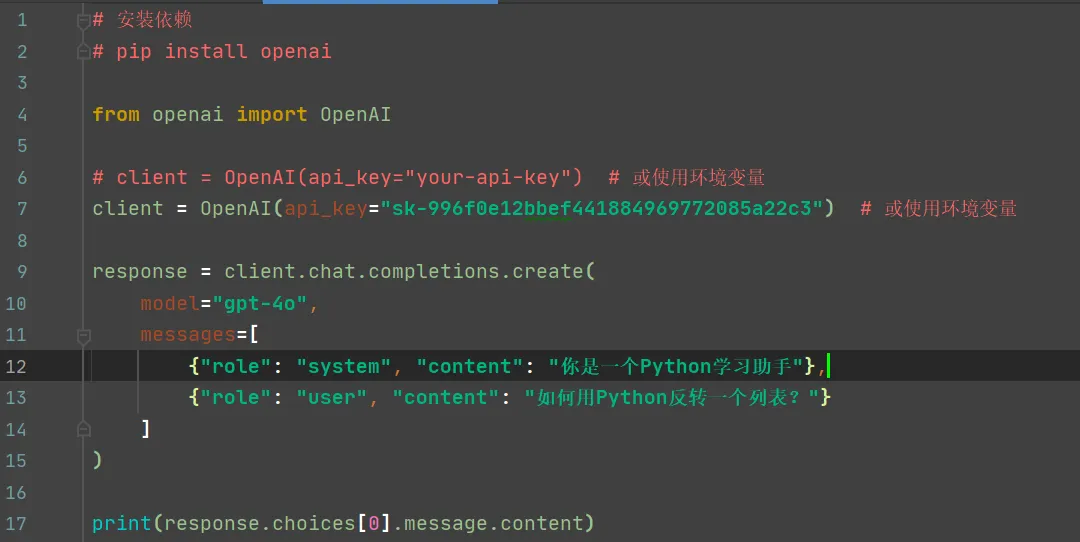
关键技能:
l理解 prompt 工程
l处理 API 返回结构
l错误重试与限流处理
阶段 2:本地运行开源大模型(低成本)
示例:用 transformers + llama.cpp 运行 Qwen/Qwen2
# 安装 Hugging Face 库 pip install transformers accelerate torch # 可选:安装 llama-cpp-python(用于 GGUF 量化模型) pip install llama-cpp-python |
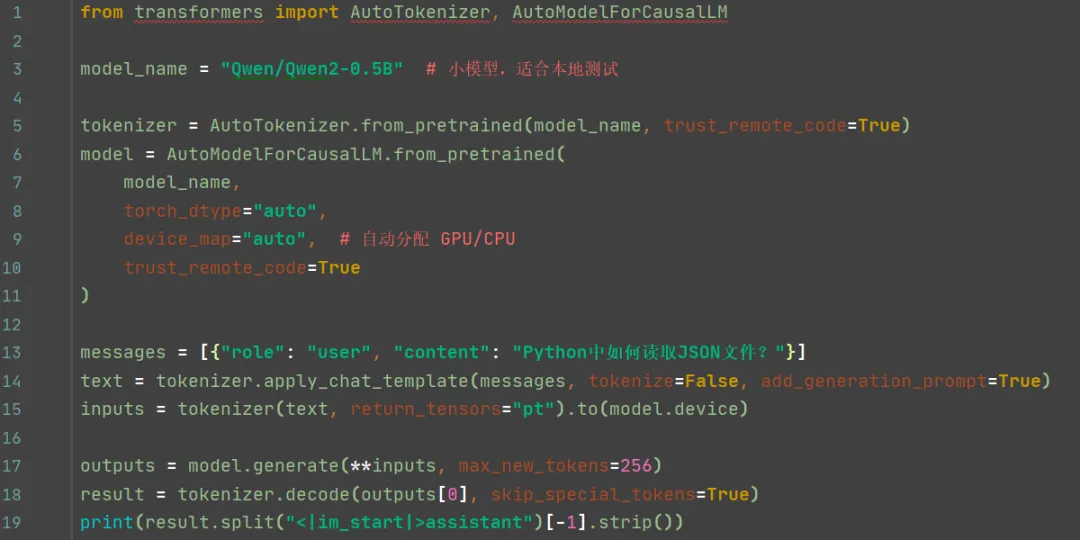
提示:
l小模型推荐:Qwen/Qwen2-0.5B、google/gemma-2b、meta-llama/Llama-3.2-1B
l显存不足?用 GGUF 格式 + llama.cpp(4-bit 量化,8GB 内存可跑 7B 模型)
2.3 Python 入局大模型的完整技术栈

2.4 给初学者的建议路线图
1.先会用:用 OpenAI / 通义千问 API 做一个小项目(如智能笔记、代码解释器)
2.再本地跑:在 Colab 或本地用 transformers 跑通 Qwen2-0.5B
3.学微调:用 LoRA 在自定义数据上微调小模型
4.做整合:结合 Flask + 模型 + 前端,做一个完整应用
5.深入优化:学习 vLLM 部署、RAG 架构、Agent 设计
你的 Python 学习网站,完全可以升级为:
lAI 辅导员:用户提问,模型自动解答
l智能导航:根据用户水平推荐学习路径
l代码陪练:输入需求,生成示例代码并解释
2.5 以上知识总结:
Python 不是大模型的“附属品”,而是它的“操作系统”。
l掌握 Python,你就拿到了进入大模型世界的万能钥匙。
l从调用 API 到训练千亿参数模型,每一步都离不开 Python 的简洁与强大。
三、小结
通过学习AI大模型,并以python入局示例。应该说,大模型包括的知识点还是很多的,而我们的优势是用python完成大模型的很多功能。从最基础做起,逐渐深入。
让我们保持学习热情,多做练习。我们下期再见!


