字数 4466,阅读大约需 23 分钟

这一转变意味着什么
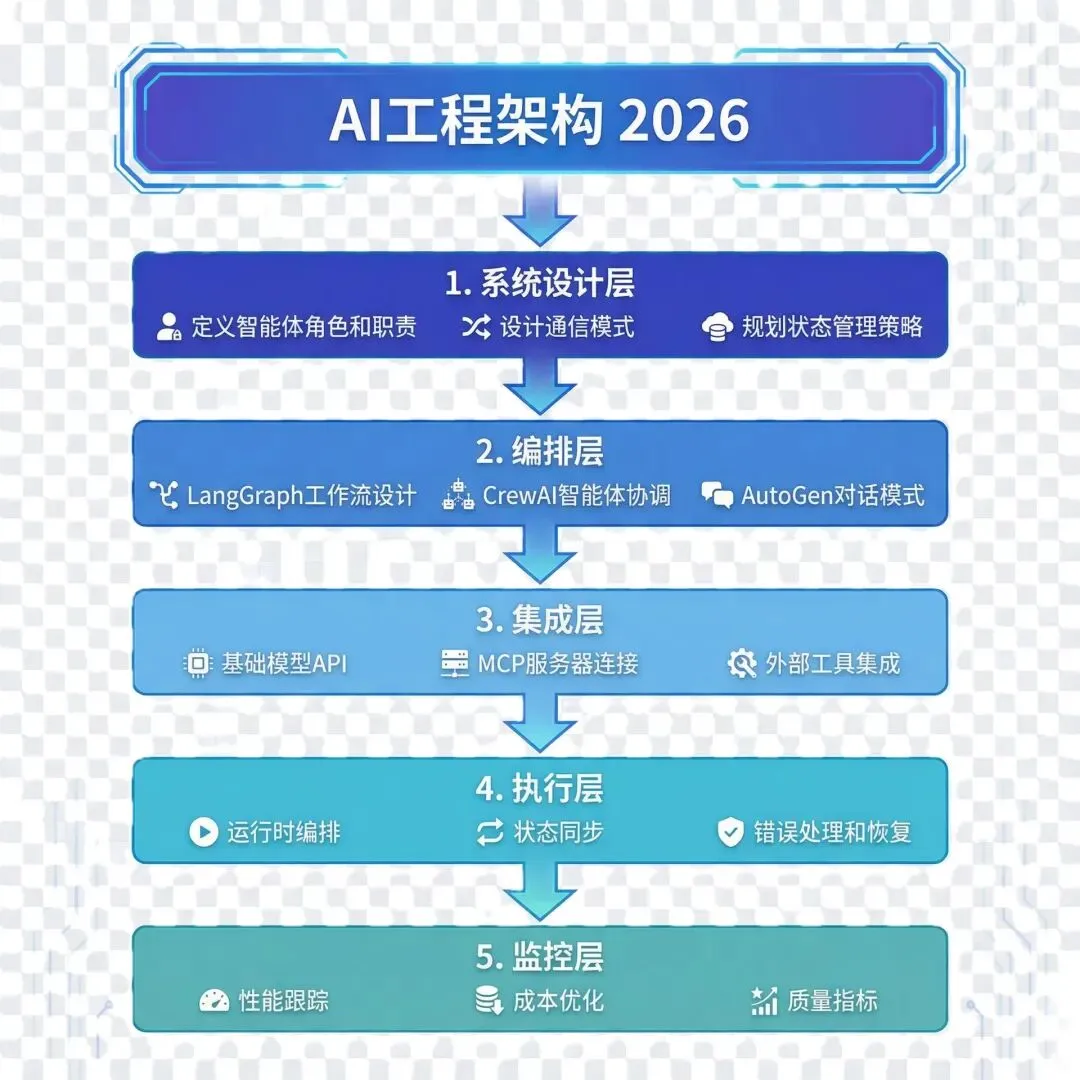
AI工程领域正在经历根本性的变革。现代AI工程师越来越多地关注系统设计、协调编排和集成,而不是从零开始实现算法。从头编写反向传播或推导优化函数的时代已经让位于使用预构建组件来组合复杂的AI系统。
关键转变:
这一变化为何正在发生
1. 抽象层成熟化
现代框架如LangChain、LangGraph、CrewAI和AutoGen抽象掉了数学复杂性。构建生产级RAG系统不需要理解Transformer数学原理。
2. 基础模型经济
预训练模型(GPT-4、Claude、Gemini)承担了繁重的工作。价值在于如何组合和编排这些模型,而不是从头训练它们。
3. 现实世界的商业问题
公司需要能够构建多智能体系统、集成MCP服务器、设计智能体工作流、创建生产级AI应用的工程师——而不是能够推导损失函数的研究人员。
4. 工具激增
AI工具、API和框架的爆发意味着成功取决于知道使用哪些工具以及如何连接它们,而不是它们内部如何工作。
如何实施这种架构优先的方法
2026年的核心能力
而非: 线性代数、微积分、概率论
重点关注: 系统设计模式、API编排、状态管理、智能体通信协议
而非: 实现注意力机制
重点关注: 设计多智能体架构、工作流编排、工具集成
而非: 反向传播算法
重点关注: 提示词工程、上下文窗口优化、检索策略
实用实施框架
# 旧方法(2023年):从头实现class CustomTransformer: def __init__(self, d_model, nhead, num_layers): self.attention = MultiHeadAttention(d_model, nhead) self.feedforward = FeedForward(d_model) # 复杂的数学实现...
# 新方法(2026年):架构和编排from langgraph.graph import StateGraph, ENDfrom langchain_anthropic import ChatAnthropicclass TradingAgentArchitecture: """多智能体交易系统 - 关注设计,而非数学""" def __init__(self): self.workflow = StateGraph(TradingState) self._build_architecture() def _build_architecture(self): # 设计智能体角色和通信 self.workflow.add_node("market_analyzer", self.analyze_market) self.workflow.add_node("risk_manager", self.assess_risk) self.workflow.add_node("executor", self.execute_trade) # 定义编排流程 self.workflow.add_edge("market_analyzer", "risk_manager") self.workflow.add_conditional_edges( "risk_manager", self.should_execute, {"execute": "executor", "abort": END} )
必备架构模式
1. 智能体编排模式
from crewai import Agent, Task, Crewfrom langchain_openai import ChatOpenAI
# 模式:层级化智能体协调class MultiAgentSystem: def __init__(self): self.researcher = Agent( role='市场研究员', goal='分析市场趋势', backstory='金融分析专家', llm=ChatOpenAI(model="gpt-4"), tools=[market_data_tool, news_tool] ) self.trader = Agent( role='交易策略师', goal='制定交易策略', backstory='量化交易专家', llm=ChatOpenAI(model="gpt-4"), tools=[strategy_tool, backtest_tool] ) self.risk_manager = Agent( role='风险管理师', goal='确保风险合规', backstory='风险管理专家', llm=ChatOpenAI(model="gpt-4"), tools=[risk_assessment_tool] )
2. 状态管理架构
from typing import TypedDict, Annotatedfrom langgraph.graph import add_messages
class AgentState(TypedDict): """集中式状态管理 - 架构层面的关注点""" messages: Annotated[list, add_messages] market_data: dict analysis_results: dict risk_assessment: dict trade_decisions: list execution_status: str
3. 工具集成模式
from langchain.tools import BaseToolfrom pydantic import BaseModel, Field
class MarketDataInput(BaseModel): symbol: str = Field(description="股票代码") timeframe: str = Field(description="数据时间范围")class MarketDataTool(BaseTool): """关注集成,而非实现""" name = "market_data" description = "获取实时市场数据" args_schema = MarketDataInput def _run(self, symbol: str, timeframe: str) -> dict: # 集成逻辑,而非数学计算 return self.api_client.get_data(symbol, timeframe)
4. MCP服务器架构
from mcp.server import Serverfrom mcp.types import Tool, TextContent
# 现代架构:构建MCP服务器class TradingMCPServer: def __init__(self): self.server = Server("trading-analytics") self._register_capabilities() def _register_capabilities(self): """能力的架构设计""" @self.server.list_tools() async def list_tools() -> list[Tool]: return [\ Tool(\ name="analyze_portfolio",\ description="分析投资组合表现",\ inputSchema={\ "type": "object",\ "properties": {\ "portfolio_id": {"type": "string"}\ }\ }\ )\ ]
完整架构流程图
综合实施示例
from langgraph.graph import StateGraph, ENDfrom langgraph.prebuilt import ToolExecutorfrom langchain_anthropic import ChatAnthropicfrom typing import TypedDict, Annotated, Sequenceimport operator
# 架构优先:定义系统结构class TradingSystemState(TypedDict): messages: Annotated[Sequence[dict], operator.add] market_context: dict risk_metrics: dict trade_signals: list execution_plan: dict next_action: strclass AutonomousTradingSystem: """ 架构优先的AI系统设计 零自定义数学,全部是组合和编排 """ def __init__(self): # 初始化基础模型(无需数学知识) self.llm = ChatAnthropic( model="claude-sonnet-4-20250514", temperature=0 ) # 设计智能体架构 self.agents = { 'analyzer': self._create_analyzer_agent(), 'strategist': self._create_strategy_agent(), 'risk_manager': self._create_risk_agent(), 'executor': self._create_execution_agent() } # 构建编排工作流 self.workflow = self._build_workflow() def _create_analyzer_agent(self): """智能体设计模式 - 架构决策""" return { 'role': '市场分析师', 'capabilities': ['技术分析', '情绪分析'], 'tools': [market_data_tool, news_sentiment_tool], 'prompt': """分析市场状况并识别交易机会。 关注技术形态和情绪指标。""" } def _build_workflow(self) -> StateGraph: """ 系统架构定义 这是2026年的核心技能——而非实现算法 """ workflow = StateGraph(TradingSystemState) # 添加处理节点 workflow.add_node("analyze", self.analyze_market) workflow.add_node("strategize", self.develop_strategy) workflow.add_node("assess_risk", self.evaluate_risk) workflow.add_node("execute", self.execute_trades) workflow.add_node("monitor", self.monitor_performance) # 定义编排流程(架构决策) workflow.set_entry_point("analyze") workflow.add_edge("analyze", "strategize") workflow.add_edge("strategize", "assess_risk") # 条件路由(设计模式) workflow.add_conditional_edges( "assess_risk", self.risk_decision, { "proceed": "execute", "reject": END, "review": "strategize" } ) workflow.add_edge("execute", "monitor") workflow.add_conditional_edges( "monitor", self.continuation_decision, { "continue": "analyze", "stop": END } ) return workflow.compile() async def analyze_market(self, state: TradingSystemState): """集成和编排——而非数学""" response = await self.llm.ainvoke([\ {"role": "system", "content": self.agents['analyzer']['prompt']},\ {"role": "user", "content": f"分析当前市场:{state['market_context']}"}\ ]) return { "messages": [{"role": "analyzer", "content": response.content}], "trade_signals": self._extract_signals(response.content) } def risk_decision(self, state: TradingSystemState) -> str: """业务逻辑路由——架构模式""" risk_score = state['risk_metrics'].get('score', 0) if risk_score < 0.3: return "proceed" elif risk_score < 0.7: return "review" else: return "reject"
架构优先方法的主要优势
更快的开发
更好的可扩展性
更易于维护
业务对齐
团队协作
2026年的实用学习路径
第1-2月:基础
- • 掌握LangChain/LangGraph基础
第3-4月:架构
第5-6月:生产环境
持续进行:
现实世界的用例
企业AI助手
自主交易系统
内容生成管道
客户服务自动化
AI工程的未来在于组合智能系统,而非推导方程式。你的竞争优势在于理解如何架构设计、编排和集成AI组件来解决实际业务问题——这比记忆微积分公式要有价值得多。
智能体模式的兴起取代模型训练
自演进智能体架构
现代AI系统需要自主改进循环——智能体能够从执行历史中学习并适应其行为,而无需重新训练模型。
from langgraph.graph import StateGraphfrom langgraph.checkpoint.memory import MemorySaverfrom datetime import datetime
class SelfEvolvingAgent: """ 架构模式:通过执行反馈改进的智能体 无需梯度下降——只需智能状态管理 """ def __init__(self): self.memory = MemorySaver() # 跨运行持久化状态 self.performance_history = [] self.strategy_variants = {} def execution_loop(self, state): """自主循环——新的核心能力""" # 1. 执行当前策略 result = self.execute_strategy(state) # 2. 评估性能 performance_metrics = self.evaluate_outcome(result) # 3. 根据结果更新策略(而非反向传播!) self.adapt_strategy(performance_metrics) # 4. 持久化学习成果 self.memory.put( namespace=("agent_memory", "strategies"), key=datetime.now().isoformat(), value={ "strategy": state['current_strategy'], "performance": performance_metrics, "context": state['market_context'] } ) return self.select_next_strategy() def adapt_strategy(self, metrics): """ 架构模式:基于规则的适应 这取代了神经网络微调 """ if metrics['success_rate'] > 0.8: # 放大成功的模式 self.increase_confidence(metrics['strategy_id']) elif metrics['success_rate'] < 0.4: # 生成变体策略 self.create_strategy_variant(metrics['strategy_id']) # 通过组合而非训练实现模式演进 self.strategy_variants = self.compose_hybrid_strategies()
反思和元认知模式
class ReflectiveAgent: """ 模式:思考自己思考的智能体 对2026年至关重要——实现无需人工干预的自我修正 """ async def execute_with_reflection(self, task): # 初始执行 initial_response = await self.llm.ainvoke(task) # 自我反思循环(架构模式) reflection_prompt = f""" 回顾你之前的回复:{initial_response} 分析: 1. 你错过了任何关键信息吗? 2. 有逻辑不一致之处吗? 3. 方法可以改进吗? 4. 有什么风险/局限性? 如需要,提供改进后的回复。 """ reflected_response = await self.llm.ainvoke(reflection_prompt) # 元认知:决定是否进一步迭代 if self.needs_another_iteration(reflected_response): return await self.execute_with_reflection(reflected_response) return reflected_response
AI系统的事件驱动架构
响应式智能体网络
import asynciofrom typing import Callable, Dictfrom dataclasses import dataclass
@dataclassclass AgentEvent: event_type: str payload: dict timestamp: datetime source_agent: strclass EventDrivenAgentSystem: """ 现代模式:事件驱动的智能体协调 取代单体AI管道 """ def __init__(self): self.event_bus = asyncio.Queue() self.subscribers: Dict[str, list[Callable]] = {} self.agents = {} def subscribe(self, event_type: str, handler: Callable): """用于智能体协调的发布-订阅模式""" if event_type not in self.subscribers: self.subscribers[event_type] = [] self.subscribers[event_type].append(handler) async def publish(self, event: AgentEvent): """跨智能体网络的事件传播""" await self.event_bus.put(event) async def event_loop(self): """ 核心编排循环 这种架构模式实现了松耦合 """ while True: event = await self.event_bus.get() # 并行事件处理 handlers = self.subscribers.get(event.event_type, []) tasks = [handler(event) for handler in handlers] await asyncio.gather(*tasks)# 使用示例class TradingEventSystem(EventDrivenAgentSystem): def setup(self): # 连接响应式行为 self.subscribe("market_signal", self.analyzer_agent.process) self.subscribe("analysis_complete", self.strategy_agent.evaluate) self.subscribe("strategy_proposed", self.risk_agent.assess) self.subscribe("risk_approved", self.execution_agent.execute) # 反馈循环 self.subscribe("trade_executed", self.performance_monitor.track) self.subscribe("performance_degraded", self.strategy_agent.adapt)
上下文窗口管理架构
动态上下文优化
class ContextWindowOptimizer: """ 2026年关键技能:管理有限的上下文窗口 比理解注意力机制更重要 """ def __init__(self, max_tokens=200000): self.max_tokens = max_tokens self.context_priorities = { 'critical': 1.0, 'high': 0.7, 'medium': 0.4, 'low': 0.1 } def optimize_context(self, context_items: list) -> list: """ 架构决策:上下文包含什么 取代嵌入相似度计算 """ # 按业务价值对每个项目评分 scored_items = [] for item in context_items: score = self._calculate_relevance_score(item) scored_items.append((score, item)) # 按分数排序 scored_items.sort(reverse=True, key=lambda x: x[0]) # 打包直到达到token限制 selected = [] token_count = 0 for score, item in scored_items: item_tokens = self.count_tokens(item) if token_count + item_tokens <= self.max_tokens: selected.append(item) token_count += item_tokens else: # 总结剩余的关键项目 if score > 0.8: # 关键信息 summary = self.summarize(item) selected.append(summary) return selected def _calculate_relevance_score(self, item) -> float: """ 上下文相关性的业务逻辑 不是ML——只是智能启发式 """ score = 0.0 # 最近性提升 age_hours = (datetime.now() - item['timestamp']).hours score += max(0, 1 - (age_hours / 24)) # 来自元数据的优先级 score += self.context_priorities.get(item.get('priority'), 0.5) # 领域特定相关性 if item.get('category') in ['risk_alert', 'execution_status']: score += 0.5 return score
向量数据库架构(无需数学)
智能检索模式
from qdrant_client import QdrantClientfrom qdrant_client.models import Distance, VectorParams, PointStruct
class ProductionRAGArchitecture: """ 模式:无需理解嵌入数学的生产级RAG 关注架构,而非算法 """ def __init__(self): self.client = QdrantClient(url="http://localhost:6333") self.setup_collections() def setup_collections(self): """架构设计:如何组织向量空间""" # 按域分离集合(设计决策) self.client.create_collection( collection_name="market_analysis", vectors_config=VectorParams(size=1536, distance=Distance.COSINE) ) self.client.create_collection( collection_name="trade_history", vectors_config=VectorParams(size=1536, distance=Distance.COSINE) ) # 有效负载索引用于混合搜索(架构模式) self.client.create_payload_index( collection_name="market_analysis", field_name="timestamp", field_schema="datetime" ) def hybrid_retrieval(self, query: str, filters: dict): """ 架构模式:向量 + 元数据过滤的组合 无需理解余弦相似度数学 """ # 向量搜索(由客户端抽象) vector_results = self.client.search( collection_name="market_analysis", query_vector=self.embed(query), # API调用,而非数学 limit=50 ) # 重新排序通过业务逻辑 reranked = self.business_logic_rerank( vector_results, filters=filters ) return reranked[:10] def business_logic_rerank(self, results, filters): """ 这是真正的技能:领域感知排序 不是ML——只是好的工程 """ scored_results = [] for result in results: score = result.score # 提升最近项目 if result.payload['timestamp'] > filters.get('after_date'): score *= 1.5 # 按来源可信度提升 if result.payload['source'] in ['bloomberg', 'reuters']: score *= 1.3 # 如果缺少必填字段则惩罚 if not all(k in result.payload for k in filters.get('required_fields', [])): score *= 0.5 scored_results.append((score, result)) return sorted(scored_results, reverse=True, key=lambda x: x[0])
人在回路架构
审批工作流和升级模式
from enum import Enumfrom typing import Optional
class ApprovalStatus(Enum): PENDING = "pending" APPROVED = "approved" REJECTED = "rejected" ESCALATED = "escalated"class HumanInLoopWorkflow: """ 关键模式:知道何时需要人工介入 比自主准确性更有价值 """ def __init__(self): self.confidence_threshold = 0.85 self.risk_threshold = 0.3 async def execute_with_oversight(self, action, state): """ 架构决策:自动化 vs 手动执行 """ # 评估操作置信度和风险 confidence = self.evaluate_confidence(action, state) risk_level = self.evaluate_risk(action, state) # 决策树(不是ML——业务逻辑) if confidence > self.confidence_threshold and risk_level < self.risk_threshold: # 自主执行 return await self.execute_autonomous(action) elif risk_level > 0.7: # 高风险:升级到高级审批 return await self.request_approval( action, approver_level="senior", reason="检测到高风险" ) else: # 中等置信度/风险:标准审批 return await self.request_approval( action, approver_level="standard", reason="置信度低于阈值" ) async def request_approval( self, action, approver_level: str, reason: str) -> dict: """ 集成模式:外部审批系统 """ approval_request = { "action": action, "reason": reason, "context": self.generate_context_summary(action), "recommended_decision": self.ai_recommendation(action), "risk_analysis": self.generate_risk_report(action) } # 发送到审批队列(集成,而非实现) response = await self.approval_service.submit( request=approval_request, approver_level=approver_level ) return response
可观测性和监控架构
追踪智能体决策链
from opentelemetry import tracefrom opentelemetry.trace import Status, StatusCodeimport structlog
class ObservableAgentSystem: """ 生产需求:对智能体行为有完全的可见性 比模型性能指标更重要 """ def __init__(self): self.tracer = trace.get_tracer(__name__) self.logger = structlog.get_logger() async def traced_agent_execution(self, agent_name: str, task: dict): """ 模式:全面执行追踪 对调试生产智能体系统至关重要 """ with self.tracer.start_as_current_span( f"agent.{agent_name}", attributes={ "agent.name": agent_name, "task.type": task['type'], "task.priority": task.get('priority', 'medium') } ) as span: try: # 记录输入 self.logger.info( "agent_execution_started", agent=agent_name, task_id=task['id'], context=task.get('context', {}) ) # 执行并追踪token start_tokens = self.get_token_count() result = await self.execute_agent(agent_name, task) end_tokens = self.get_token_count() # 记录指标 span.set_attribute("tokens.used", end_tokens - start_tokens) span.set_attribute("execution.duration_ms", span.elapsed_time) span.set_attribute("result.status", result['status']) # 成本追踪 cost = self.calculate_cost(end_tokens - start_tokens) span.set_attribute("execution.cost_usd", cost) # 记录输出 self.logger.info( "agent_execution_completed", agent=agent_name, task_id=task['id'], tokens_used=end_tokens - start_tokens, cost_usd=cost, result_summary=result.get('summary') ) span.set_status(Status(StatusCode.OK)) return result except Exception as e: # 详细错误追踪 span.set_status(Status(StatusCode.ERROR)) span.record_exception(e) self.logger.error( "agent_execution_failed", agent=agent_name, task_id=task['id'], error=str(e), traceback=traceback.format_exc() ) # 对关键失败发出警报 if task.get('critical', False): await self.send_alert(agent_name, task, e) raise
成本优化架构
Token感知系统设计
class CostOptimizedAgentSystem: """ 2026年关键技能:构建成本高效的AI系统 架构决策直接影响运营成本 """ def __init__(self): self.model_costs = { 'gpt-4': {'input': 0.03, 'output': 0.06}, # 每1k tokens 'claude-sonnet-4': {'input': 0.003, 'output': 0.015}, 'claude-haiku': {'input': 0.00025, 'output': 0.00125} } self.daily_budget = 100.00 # 美元 self.current_spend = 0.0 def select_optimal_model(self, task: dict) -> str: """ 架构模式:按成本/性能进行模型路由 不是ML——业务优化 """ complexity = self.estimate_task_complexity(task) latency_requirement = task.get('max_latency_ms', 5000) # 路由逻辑(架构决策) if complexity < 0.3: # 简单任务:使用最便宜的模型 return 'claude-haiku' elif complexity < 0.7 and latency_requirement > 3000: # 中等复杂度:平衡成本/性能 return 'claude-sonnet-4' else: # 复杂或时间敏感:使用最佳模型 return 'gpt-4' async def execute_with_budget_control(self, task: dict): """ 模式:预算感知执行 """ # 执行前估算成本 estimated_cost = self.estimate_task_cost(task) # 预算检查 if self.current_spend + estimated_cost > self.daily_budget: # 优雅降级 return await self.execute_reduced_quality(task) # 执行并追踪成本 result = await self.execute_task(task) actual_cost = self.calculate_actual_cost(result) self.current_spend += actual_cost # 自适应节流 if self.current_spend > 0.8 * self.daily_budget: await self.enable_aggressive_caching() return result def optimize_prompt_tokens(self, prompt: str, context: list) -> str: """ 模式:提示词压缩 对成本控制至关重要 """ # 去除冗余 compressed_context = self.deduplicate_context(context) # 总结冗长部分 if self.count_tokens(prompt) > 2000: prompt = self.compress_prompt(prompt) # 使用结构化格式(更少的token) structured = self.convert_to_structured_format(prompt, compressed_context) return structured
多模态架构模式
class MultiModalAgentSystem: """ 2026年模式:无缝处理文本、图像、音频、视频 关注编排,而非理解视觉Transformer """ def __init__(self): self.text_model = ChatAnthropic(model="claude-sonnet-4") self.vision_model = ChatAnthropic(model="claude-sonnet-4") async def process_multi_modal_input(self, inputs: list): """ 架构模式:模态特定路由和融合 """ results = {} # 按模态并行处理 tasks = [] for input_item in inputs: if input_item['type'] == 'image': tasks.append(self.process_image(input_item)) elif input_item['type'] == 'text': tasks.append(self.process_text(input_item)) elif input_item['type'] == 'document': tasks.append(self.process_document(input_item)) modality_results = await asyncio.gather(*tasks) # 融合层(架构决策) fused_understanding = await self.fuse_modality_results( modality_results ) return fused_understanding async def process_image(self, image_data): """与视觉模型集成""" response = await self.vision_model.ainvoke([\ {\ "role": "user",\ "content": [\ {"type": "image", "source": image_data['source']},\ {"type": "text", "text": "从该图表中提取所有交易信号"}\ ]\ }\ ]) return { 'modality': 'vision', 'extracted_info': response.content, 'confidence': self.estimate_confidence(response) }
关键要点
架构胜于算法——系统设计技能比数学知识更重要
集成胜于实现——组合现有工具而非从零构建
业务逻辑是核心——领域知识和决策规则创造价值
可观测性是必需的——生产系统需要全面监控
成本意识很重要——运营成本是一等一的架构关注点
人工监督模式——知道何时升级比完美自主更重要
这些附加模式完整描绘了2026年AI工程的样子。重点已明确从理解模型内部工作原理转向有效编排它们的架构设计。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
