诸位,你是否曾经遇到过需要从Google Drive下载文件或文件夹的情况?特别是当文件太大无法直接下载时?今天我们来深入解析 gdown 这个神器是如何工作的!
gdown 是一个Python库,专门用于从Google Drive下载文件和文件夹。它绕过了Google Drive的一些限制,让你能够用简单的代码下载大文件。
我们可以在使用前先更新一下gdown,使用以下代码即可:
pip install --upgrade gdown
很多人第一次用 gdown,都会误以为它是Google Drive 官方下载工具,但其实它更像一个聪明的网页扒手。
gdown 的核心价值只有一件事:
不用登录、不用 API、不用 OAuth,就能在 Python 里直接把 Google Drive 上的文件或文件夹拉到本地。
它是怎么做到的?
答案很简单粗暴:解析 Google Drive 的网页结构,然后模拟浏览器逐个下载文件。
诸位,我们来看一段最典型的文件夹下载场景。
你给 gdown 一个 Google Drive 文件夹链接,它首先会访问这个文件夹的网页页面,而不是调用什么官方接口。
在这个页面里,Google 已经把该文件夹下所有文件和子文件夹的信息“嵌”在网页源码中。
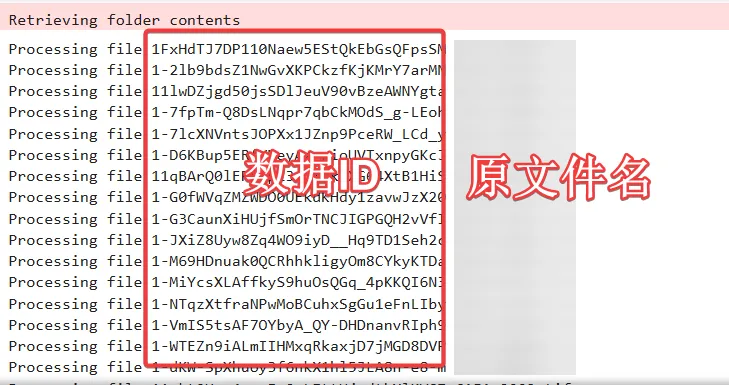
gdown 会解析这些信息,提取出每一个文件的 file_id,然后开始一个文件一个文件地下载。这就是为什么它叫 download_folder,但实际上并不存在“整体打包下载”这件事。
再看接下来我们能要在干什么。
先把下载和本地路径这两件事分开:一个工具管拉数据,一个工具管落地,这是为什么 gdown 和 os 总是成对出现,也就是我们首先导入这两个python包:
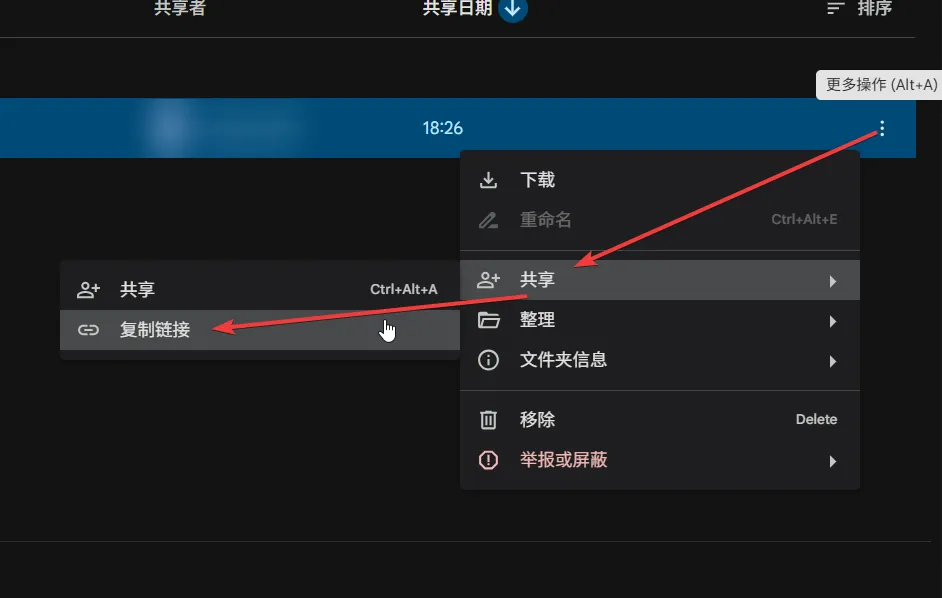
它给 gdown 的不是分享页,而是一个干净的文件夹入口。它只认文件夹 ID 或标准 folders 链接,其他参数一概无视。我们可以直接在 Google Drive里获取文件或者文件夹链接,如下图所示:
而后我们将该链接赋值给folder_url,即:
folder_url = "https://drive.google.com/drive/folders/………………"
由于此处我个人数据隐私的原因,就不将这部分数据公开了。
接下来便是指定本地数据存放路径,真正的文件夹结构,会在下载过程中按 Drive 里的样子自动生成。我们可以使用如下代码提前把目录建好:
download_path = "I:/GoogleDriveDownload"os.makedirs(download_path, exist_ok=True)
接下来是最关键的步骤,也就是说真正干活的是 download_folder,它明确知道这是个文件夹,于是放弃任何打包处理的繁琐,选择最稳妥的方式,即进页面 → 找文件 → 一个一个下 → 在本地复刻结构。
打开日志,是为了确认数据的存在,关掉 cookies,是为了让公开资源少点变量。所以当你看到文件慢慢往磁盘里掉,那不是效率问题,而是 gdown 在模拟一次人类手动下载整个文件夹的全过程。不优雅,不官方,但极其可靠。
在能跑通这件事上,gdown 一直很诚实。
下面便看看完整的流程:
import gdownimport osfolder_url = "https://drive.google.com/drive/folders/……………………"download_path = "I:/BaiduNetdiskDownload"os.makedirs(download_path, exist_ok=True)gdown.download_folder( url=folder_url, output=download_path, quiet=False, use_cookies=False)
可以看到,只需要十行左右的代码,就能把整个 Google Drive 文件夹直接拉到本地。不必等待Google Drive 先打包、再压缩、再下载,也不再被它看心情的下载流程牵着走。众所周知,Google Drive 的整包下载对网络环境极其敏感,一旦连接不稳,压缩过程可能中断,下载任务直接失败,只能重来。而 gdown 选择了一条更朴素、也更稳定的路径,跳过压缩步骤,直接按文件逐个拉取。即使网络偶尔波动,也只是影响单个文件,而不是推翻整个下载过程。PS:在使用gdown下载GoogleDrive文件时需保持科学上网。运行上述代码,我们可以看到运行代码后程序会自动将文件数据解析出来并编号,具体如下图所示:
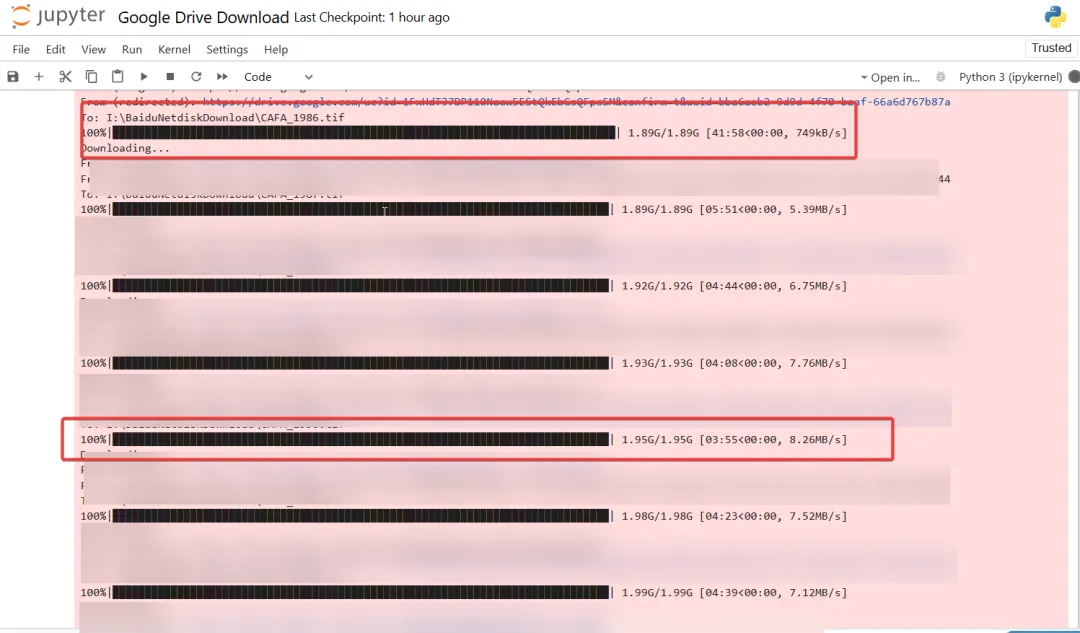
紧接着便会开始整个下载流程,可以看到整体下载速度取决于个人网络,刚开始由于我个人网络问题,故而下载速度较为缓慢,后续网络通畅的情况下对于较大的文件也下载相对较快,实测瞬时下载速度超过20mb/s:
如果你觉得 "原来 Python 还能把这些事做得这么顺手" ,那么请点个关注,后续会持续分享一些偏实用、偏脚本、偏解决具体问题的小工具和用法,比如:
用 Python 快速接管各类网盘与数据源的自动下载把零散脚本整理成可复用的小工具,而不是一次性代码在不引入重型框架的前提下,提升批量处理的稳定性让脚本在不同环境下少踩坑、多跑通的实践经验那些看起来不起眼,但每天都能省时间的 Python 习惯
很多脚本的起点,其实都来自一句话:这一步,真的还要手动做吗?如果你也遇到过类似的场景,欢迎留言或邮件交流:📧 shenzhijun2024@hotmail.com
你的困扰,很可能就是下一段实用脚本的灵感来源。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
