Cursor 于 2026 年 1 月 30 日发布了 Agent Trace[1]协议,以下内容由 GPT5 根据原文生成,我人工核查,并使用 Gemini 3 Pro 做了事实核对。
我先用一句话总结一下:
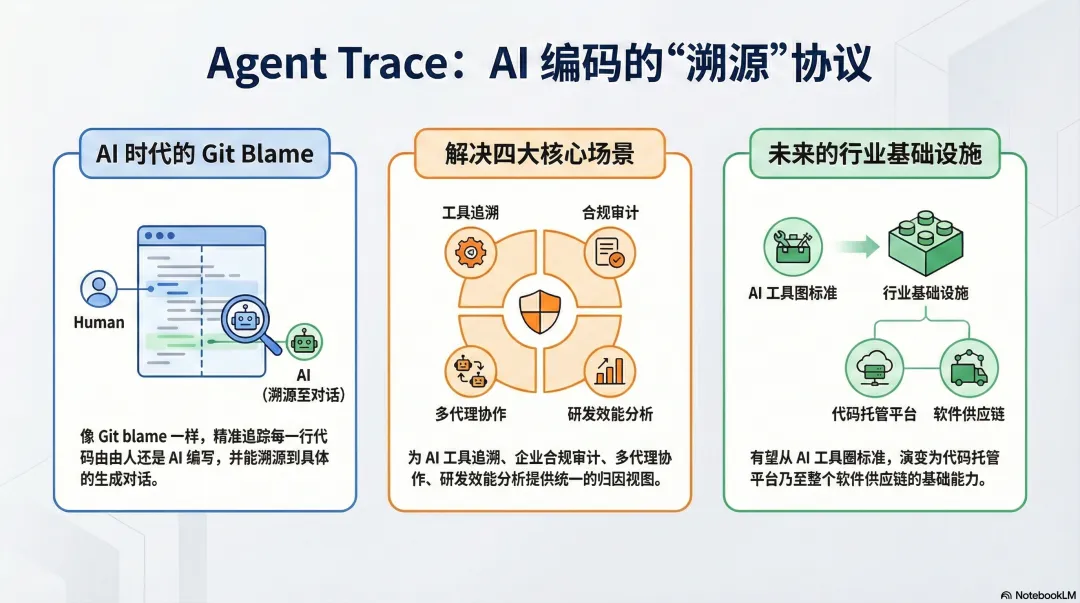
「这个协议现在主要是为「AI 编码助手/代理 + 团队代码仓库」服务的归因与审计基础设施,将来有机会长成类似「AI 时代的 Git blame / SBOM 标准」。」
一、现在这个规范主要面向哪些场景?
结合文档里的设计,可以看到它不是「玩票性质的 metadata」,而是瞄准几类很现实的场景:
AI 编码工具本身:Cursor、Claude Code、Copilot 等
这一点在结构上很明显:
- 顶层有
tool 字段(name, version),显然是给具体 AI 工具写入用的。 -
contributor.type 支持 ai / human / mixed / unknown,就是为了 IDE 里高亮「这几行是谁写的」。 -
conversation.url 指向的是「产生这段代码的对话」,related 里还能挂 session、prompt 等。
这些特性特别适合下面这些功能:
- 「在 IDE 里按行标记 AI 产出」:比如在代码左侧 gutter 显示一个图标,鼠标悬停就能看到「由某某模型、某次对话生成」。
- 「多次对话、多模型协作」:同一个文件里可以有多个 conversations,每个 conversation 下挂若干
ranges,适合复杂的「反复让 AI 改代码」流程。 - 「追溯问题代码对应的对话」:某段代码出 bug,可以顺着
conversation.url 找回当时那轮 agent 对话,理解它为什么这么写。
简而言之:最直接的受益者是「AI coding agents / IDE 插件」生态。
团队/企业的合规、审计、风险管控
文档多次强调:
- 不管是
vcs 支持 Git/JJ/Hg/SVN,还是 revision 精确到 commit,都是为了「和版本控制严密挂钩」。 -
metadata 是开放扩展的,可以加各种 confidence、vendor 自定义字段。
这天然支持企业内部的场景,比如:
- 「安全/合规审计」:某次事故后要搞清楚「这段关键逻辑是人写的还是 AI 写的?哪一版引入的?」。
- 「风险分级」:可以在 CI 或内部工具中,对「关键模块被 AI 新改动的行」做更严格的 code review 流程。
- 「对外合规披露」:以后如果监管要求「对外提供的软件要说明 AI 参与程度」,这个记录可以作为基础数据源。
「因为 Agent Trace 明确说自己不管「法律所有权」「训练数据 provenance」,所以它更像是工程层面的操作日志,很契合企业工程体系内部的合规/审计需求。」
分布式协作开发:多人 + 多代理 + 跨工具
contributor.type 里有 mixed,再结合 per-range 的 contributor override,很适合这些复杂场景:
在这种情况下:
- 可以用
conversation 代表「某个代理/工具在某个阶段的一轮操作」; - 用每个
range 上的 contributor 覆盖,表示「这里被谁最后实际写/改了」。
「这对未来的「多代理协作开发」场景很关键:你需要一个统一的归因视图,才能在「一堆 agent 乱改」之后保持可追踪性。」
研发效能分析:量化「AI 提升了多少生产力」
有了按行的 attribution,再配合 Git 历史,很多「以前只能估」的分析可以真正量化:
- 「一段时间内,仓库新增/修改的行里多少是 AI 贡献的;」
- 不同模型在不同类型任务(比如测试 vs 核心业务逻辑)上的使用分布。
协议本身没写这些「怎么统计」,但它把关键原子数据结构(line range + contributor + model_id + vcs revision)都给你了——这非常符合「底层标准,交给上层工具做分析」。
二、从规范设计看,它未来可能往哪几个方向发展?
我觉得可以拆成「技术演化」和「生态演化」两个层面来看。
技术层面:从「文件级 JSON」长成「基础设施级」能力
现在的形态是:
- 「怎么存」刻意不规定(可以是本地文件、git notes、数据库等)。
未来自然的演化方向包括:
「标准化的存储形态」
- 焊死在 Git 生态里(比如主推用 git-notes、特定 ref、或 commit 附件存储)。
- 或者出一套推荐实践:某种目录结构 / 文件命名约定,方便工具发现和读取。
「增量/合并策略」
- 现在只是描述单个 trace record,将来会遇到 rebases / merge / cherry-pick 下 attribution 怎么合并的问题。
- 文档 FAQ 也说「对此开放,可能影响未来规范」,我认为极有可能会:
- 要么在 spec 里增加与 merge/rebase 相关的字段或约定;
「更强的 hash 与稳定标识」
- 目前的
content_hash 是一串字符串,例子用 murmur3。未来可能: - 引入行级/片段级的稳定 ID 方案,让代码移动/复制时归因更可靠。
「总体来看,它很容易演变成一种「AI Blame Index」:独立于 Git、又紧密依附于 Git。」
生态层面:从「Cursor 出的 RFC」变成「跨工具行业标准」
如果走顺的话,我能想象几个发展阶段:
「第一阶段:AI IDE / 代理工具快速跟进」
- Cursor、Claude Code、Copilot、Windsurf 这类工具,只要愿意做「AI 归因」故事,采用一个现成中立协议比自己造轮子更划算。
- 尤其是
model_id 明确跟 [models.dev] 约定挂钩,天然就能和未来的「模型注册表 / 市场」打通。
「第二阶段:代码托管平台支持显示/查询」
- 比如 GitHub / GitLab / Gitea 之类的:
- 在 PR diff 里显示「哪些行是 AI 贡献」;
- API 增加对 Agent Trace 的读取端点。
- 一旦这一步走通,Agent Trace 就会变成平台级能力,而不仅仅是 IDE 附加值。
「第三阶段:被纳入更大范围的软件供应链标准体系」
可以类比今天的软件供应链里:
- 代码签名 / provenance 协议(比如 SLSA)负责构建链路的可信性。
未来 Agent Trace 有机会变成:
- 「代码来源维度的 SBOM 子集」:说明这份代码里哪些行是 AI 写的,用了哪些模型、哪些代理流程。
- 如果监管或行业自律开始要求「关键系统中 AI 参与情况要可追踪」,它就是天然的技术落地方向之一。
业务层面:围绕「AI 归因」衍生的新功能与产品
当归因数据变成标准格式、且跨工具共享之后,可以顺势长出一堆东西:
「质量和风险评估工具」
- 针对「AI 贡献密度高」的代码做自动化检测、加重审查;
「模型与工具效果评测」
- 结合 bug、rollbacks 等数据,分析「哪个模型在什么场景下靠谱」;
- 归因到具体模型版本(model_id 带版本),评估模型升级的影响。
「开发者个人视图」
- 统计「我最近多少提交是 AI 帮忙写的」「我在哪些模块上更多依赖 AI」;
- 用于自我认知、绩效讨论、甚至个性化学习推荐(你在哪些技术栈上 AI 介入更多)。
「面向法律/合约的「附加材料」」
- 虽然 spec 明说自己不处理「法律所有权」,但现实中:
- Agent Trace 至少能作为一个「技术事实记录」被拿出来讨论。
三、也顺便说说我看到的几个关键设计取向
这些取向会直接影响它未来可能长成的形状:
「刻意不碰「所有权」「训练数据」等高政治敏感议题」
- 专注在「谁、在何时、通过什么会话,把哪几行改成了什么样」,是工程层面最稳妥的一层。
- 这让它更容易被不同立场的厂商和团队接受,为后续在更高层面的合规/法律讨论提供「共识的技术基础」。
「「会话」作为核心中间层,而不是直接挂在模型或工具上」
conversation + ranges 这个结构,天然适配代理化的世界观(用户和 agent 交互是一系列 session,对话产生若干代码修改)。- 以后无论是自然语言对话式 agent、脚本化 agent、或复杂的工具链,理论上都能在「会话」这层抽象下来。
「高度可拓展的 metadata 与 vendor namespace」
- dev.cursor 这种反向域名的做法,把「标准核心」和「厂商自定义」明确隔离开:
- vendor namespace -> 差异化竞争。
四、我个人对它未来形态的一点判断
综合上面这些设计和当下大环境,我大概会这样看它的潜力:
短期:「成为「AI IDE / 代理工具圈」事实标准」,谁先支持,谁可以在「工程可追踪性」故事上占优势;
中期:被代码托管平台和企业内部工程平台接入,「变成 CI/CD、Code Review、审计系统的基础数据之一」;
更远一点:如果 AI 参与编码成为绝对主流,那么:
- Agent Trace 或类似协议,很可能会变成「每个 serious 代码仓库都默认存在的层」,像今天的 Git blame / CI config 一样日常;
- 它本身也许会被并入更大的「AI 软件供应链标准」里,但核心思想——按行跟踪 AI 贡献 + 可追溯到会话与模型——大概率会保留下来。
从这个角度看,现在这种 0.1.x 的 RFC,更像是在抢一个叙事原点:以后大家再讨论「AI 写代码的工程可追踪性」,很可能会以这个结构作为起点来扩展和改造。
- https://agent-trace.dev/ ↩