在一些特定的任务场景中,并发编程能够显著提升程序的执行效率。最早接触并发编程,是在处理海量年报文本时,需要从大量相互独立的 PDF 中提取符合特定规则的内容。由于这些年报之间不存在任何依赖关系,当时通过多进程并行处理,任务的整体执行时间被大幅压缩。而最近在调用大语言模型 API 的过程中,再次体会到了并发编程的价值,尤其是异步编程在 IO 密集型场景下所展现出的巨大优势。因此,决定系统性地梳理并学习这一部分内容,并将理解过程整理成文。由于我也是刚刚接触这部分知识,如有疏漏,欢迎批评指正。
并发编程并不是一个陌生的概念。无论是后端服务中高并发请求的处理、数据分析中的并行计算,还是现代 AI 系统中的多任务调度,其底层都离不开对并发模型的理解。
从硬件发展的角度看,随着摩尔定律逐渐逼近物理极限,单核 CPU 的频率提升已经难以持续。多核 CPU 成为常态后,如何更充分地利用有限的计算资源,在同一时间处理更多任务,成为软件层面必须面对的问题,而这正是并发编程所要解决的核心。
与并发密切相关、也最容易被混淆的概念是并行。Go 语言的设计者之一 Rob Pike 曾对两者作出过清晰区分:
并发指的是同时处理多件事,并行是同时做多件事,二者不同但有联系。
并发强调的是逻辑上的同时发生。多个任务在时间维度上交错推进,由调度器统一管理,它们未必真的在同一时刻执行。而并行则是物理意义上的同时执行,依赖多核 CPU 或多处理器,在同一时间点运行多条指令。
因此,并发不一定是并行,但并行一定属于并发的一种实现形式。
在 Python 语境下,并发编程中最常被讨论的三种执行与调度单元是:进程、线程和协程。它们的根本区别在于——谁负责调度、资源如何隔离、切换成本有多高。
进程是操作系统进行资源分配和调度的基本单位。每个进程都拥有独立的地址空间、文件描述符、堆和栈,不同进程之间在内存层面完全隔离。这种隔离带来了良好的安全性和稳定性,但也意味着进程间通信成本较高。进程的创建和销毁需要操作系统内核参与,开销相对昂贵,因此更适合用于任务粒度较大、运行时间较长的场景。
线程是在进程内部进一步划分出的执行单元。一个进程可以包含多个线程,这些线程共享进程的大部分资源,但各自拥有独立的程序计数器和栈。由于共享内存,线程的创建和切换成本明显低于进程,线程间通信也更加高效。但与此同时,共享状态也引入了数据竞争、死锁等并发问题,使得程序调试和维护成本上升。
协程与进程、线程的最大不同在于,它并不是由操作系统调度的执行单元,而是由程序自身控制调度的一种“用户态并发”。如果说线程是操作系统管理的工人,那么协程就是“用户态”的轻量级线程,或者可以理解为一位拥有极高时间管理技巧的超级工人。协程的调度完全由程序自己(通常是用户空间的调度器或事件循环)控制,而不需要操作系统的内核介入。这意味着协程的切换几乎不消耗内核资源,速度极快。协程的核心思想是协作,当一个协程遇到需要等待的事情(比如等待网络数据返回)时,它会主动让出 CPU 的控制权,让另一个协程继续执行,而不是像线程那样傻傻地被操作系统强制挂起。
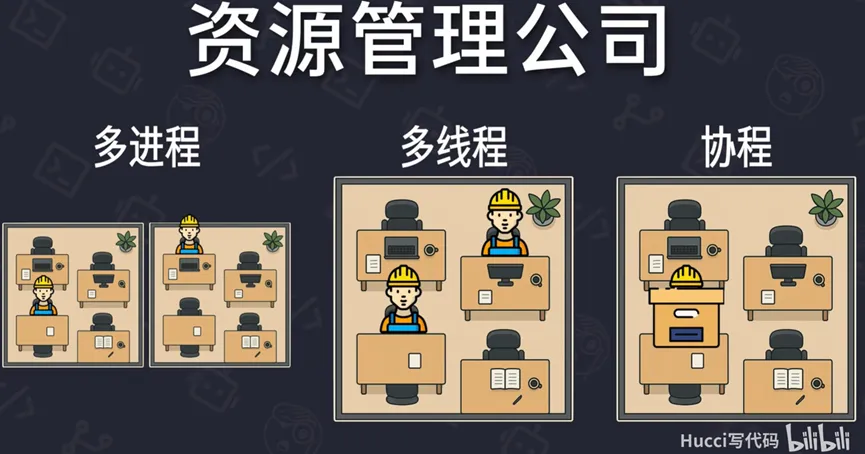
参考B站的一个UP主(Hucci)所举的一个非常形象的例子,便于读者通俗理解上述含义。假设你的操作系统是一家资源管理公司,管理着电脑上的各种资源,尤其是CPU时间还有内存。在这家资源管理公司当中,有很多个办公室,有的办公室负责微信,有的负责三角洲行动,每个办公室因此也会被分配到一定的资源,这每一间办公室就可以看作成一个进程。当然,每个办公室都要有各自的员工,最少有一个工人,这个工人就是主线程;也可以用很多工人,每个工人有各自的任务,每个人工人也就可以看成一个线程。那一个工人也可以同时负责多个小任务,比如接收消息的工人又要接收网络数据,又要处理本地缓存,他可以在网络数据还没到的时候,先处理本地缓存,数据到了再去处理网络数据。这种切换工作的方式叫做协程。所以,协程仅仅是一种工作方式、调度方式,而进程和线程是真实存在的。
在实际开发中,并不存在一种“通用最优”的并发模型。选择的关键在于任务是计算密集型,还是 IO 密集型。
计算密集型任务的主要时间消耗在 CPU 运算上,例如视频编解码、复杂数值计算、大规模特征工程或机器学习训练。在这类场景中,CPU 始终处于高负载状态。
在 Python 中,多线程并不适合此类任务。一方面,线程频繁切换会引入额外开销;更关键的是,GIL会限制同一时刻只有一个线程执行 Python 字节码,使多线程无法在多核 CPU 上真正并行。
多进程通过创建多个独立的解释器实例,每个进程拥有各自的 GIL,可以将任务分配到不同 CPU 核心上并行执行,从而显著提升性能。虽然进程的启动成本较高,但在长时间、高强度计算任务中,这一代价是完全值得的。
IO 密集型任务的特点是:CPU 运算时间很少,大部分时间都在等待外部响应,例如网络请求、数据库查询或磁盘读写。
在这类场景中,多线程能够显著提升效率。当一个线程因 IO 阻塞时,操作系统可以立即调度其他线程使用 CPU。而且 Python 在执行 IO 操作时会主动释放 GIL,使多线程在 IO 场景下依然有效。
然而,当并发规模进一步扩大(例如成千上万的网络连接)时,多线程模型开始暴露出局限:线程数量受限、内存占用高、内核调度成本不断上升。此时,协程成为处理高并发 IO 的理想选择。协程切换完全发生在用户态,开销极低,一个进程内可以轻松管理成千上万个并发任务。当某个协程等待 IO 时,它不会占用 CPU 资源,事件循环只在数据就绪时将其唤醒,从而显著提升系统吞吐量。
可能一些资料当中会提到,多线程不仅仅能解决IO密集型任务,同样能解决CPU密集型任务。但是,对于Python来说实则不然(确切来说python 3.14以前)。Python当中,解释器只能有一个线程真正运行。所以Python中的多线程其实是多个线程的任务依次执行,而不是同时执行。
GIL,全称 Global Interpreter Lock,是 CPython 解释器中的一种全局互斥锁,用于保证同一时刻只有一个线程在执行 Python 字节码。言简意赅地说,在任何时刻,无论你的 CPU 有多少个核心,Python 解释器只允许一个线程执行 Python 字节码。这意味着,即使你在 Python 中启动了 10 个线程运行在 10 核 CPU 上,同一瞬间也只有一个线程在真正运行,其他线程都在等待争夺这把锁。
GIL 的存在对 Python 的并发编程产生了深远的影响。对于计算密集型任务,Python 的多线程不仅无法利用多核加速,反而可能因为线程之间频繁争夺 GIL 以及由此带来的上下文切换开销,导致运行速度比单线程还要慢。这就是为什么在 Python 中处理繁重的计算任务时,社区一致推荐使用 multiprocessing 模块。多进程通过创建独立的解释器实例,每个进程都有自己的 GIL,从而绕过了这把锁的限制,实现了真正的并行计算。
对于IO 密集型任务,GIL 的影响其实微乎其微。这是因为 Python 解释器在执行 IO 操作(如读写文件、网络通信)时,会主动释放 GIL,允许其他线程获取锁并执行代码。等到 IO 操作完成后,线程再重新申请 GIL。因此,在爬虫、Web 服务器等以网络等待为主的场景下,Python 的多线程依然能够有效地利用 CPU 的空闲时间,大幅提升程序效率。
注:Python 3.14及以后正在逐步引入 opt-in 的 no-GIL 模式。无 GIL 版本需要显式构建,且对第三方扩展存在兼容性要求。
最后举一个简单的模拟LLM API调用场景的例子。
LLM API 的调用具有一个非常显著的特征:等待时间极长,但计算量极小。假设有 50 个智能体同时在调用 API。如果用多线程,你需要开 50 个线程。这 50 个线程在 99.9% 的时间里都在傻等 HTTP 响应。虽然操作系统能处理,但这占用了 50 个线程的栈内存,且涉及无意义的内核调度。相反,如果用协程的话,可以创建 50 个协程任务。在等待 LLM 回复的那几十秒里,这些任务处于挂起状态,几乎不占用 CPU,内存占用微乎其微。Python的事件循环只需要在数据回来时唤醒对应的回调即可。
以下为一个示例代码,仅做展示使用,并不能直接运行。
import asynciofrom concurrent.futures import ThreadPoolExecutor# IO 密集:调用 LLM APIasync def agent_chat(prompt): response = await openai_async_client.chat.completions.create(...) return response# CPU 密集:本地数据分析def analyze_data_locally(dataframe): return dataframe.describe()async def main_controller(): # Step 1:异步调用 LLM plan = await agent_chat("如何分析这个表格?") # Step 2:将 CPU 计算移出事件循环 loop = asyncio.get_running_loop() with ThreadPoolExecutor() as pool: analysis_result = await loop.run_in_executor( pool, analyze_data_locally, my_dataframe ) # Step 3:继续异步调用 LLM summary = await agent_chat(f"分析结果是:{analysis_result},请总结")
参考资料:
在Python中用多线程之前,需要先搞懂这些_哔哩哔哩_bilibili
《流畅的Python》 Luciano Ramalho著
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
