使用 Python 构建实时产品推荐系统原型
- 2026-07-06 03:15:23
使用 Python 构建实时产品推荐系统原型
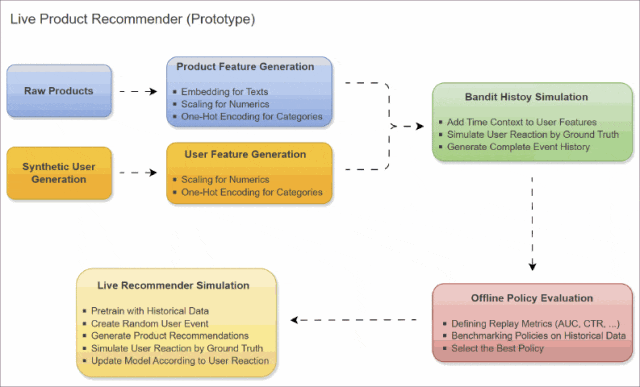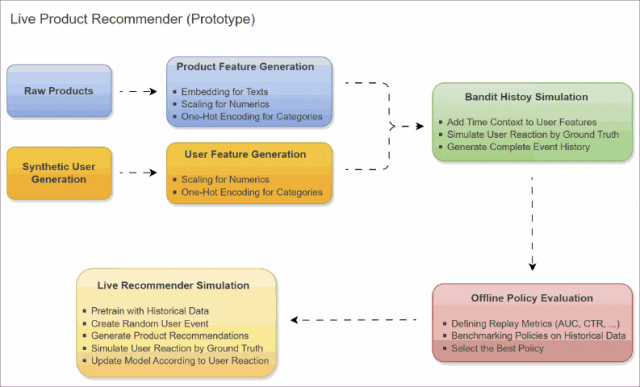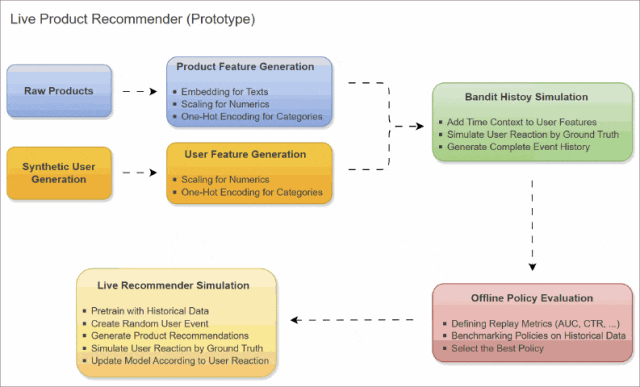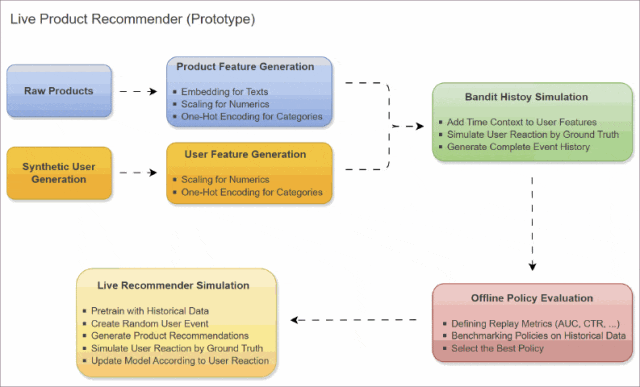
传统推荐系统难以应对冷启动用户和短期上下文信息。情境多臂老虎机算法(Contextual Multi-Armed Bandits,CMAB)能够持续在线学习,并根据实时上下文信息平衡信息利用(Exploitation)和探索(exploration)。在第一部分中,我们构建了一个 Python 原型来模拟用户行为并验证算法,为可扩展的实时推荐奠定了基础。
概述
传统的推荐系统,例如协同过滤[1] ,应用广泛,但存在局限性。它们难以应对冷启动问题 (新用户没有历史记录),并且严重依赖长期信号。此外,它们常常忽略短期上下文信息, 例如时间、设备、位置或会话意图,并且可能错过一些细微差别,例如用户早上想喝咖啡,晚上想吃披萨 。
情境多臂老虎机(CMAB)[2]通过在线学习 来弥补这些差距。
作为一种实用的强化学习形式[3] ,CMAB 能够实时平衡两个目标:
1. 利用: 推荐已知有效的方法。 2. 探索: 尝试一些不太常见的选项,以发现新的心头好。
CMAB 通过根据实时上下文做出决策,能够立即适应不断变化的用户行为。
为什么选择 CMAB?
• 超越 A/B 测试: CMAB 不追求找到一个全局最佳方案,而是实现一对一个性化 ,根据当前用户的具体情况选择最佳方案。 • 实时适应: 与很快就会过时的批量训练模型不同,CMAB 会逐步更新,使其成为新闻/产品推荐、动态定价或库存感知排名的理想选择。
目前已有多种 CMAB 实现方案,包括Vowpal Wabbit[4]和River ML[5] 。本文中,我们使用Mab2Rec[6]进行离线策略评估,并使用MABWiser[7]构建实时推荐系统原型。
数据流的机会
CMAB 在数据流环境 中表现出色。它与Kafka 和Flink 等平台集成,直接从事件流中学习,创建反馈循环,从而在亚秒级的时间内响应用户意图的趋势和变化。
本系列文章的第一部分 (本文)构建了一个完整的Python 原型 ,用于验证算法并模拟用户行为。第二部分 (即将发布)将把该原型扩展到分布式、事件驱动的架构。
技术栈
我们正在使用Python 3.11 构建这个原型。
工程说明: 我们特意选择了 Python 3.11,因为我们技术栈的部分组件(特别是
mabwiser依赖项)依赖于pandas的旧版本(< 2.0)。在 Python 3.12 及更高版本中,安装这些依赖项通常会导致编译时间过长或因缺少二进制 wheel 文件而导致编译失败。
我们使用uv[8]进行 Python 环境管理。核心库包括:
• MABWiser:[7]引擎。它实现了核心的上下文老虎机算法。 • Mab2Rec:[6]该具。一个用于简化推荐系统流程的高级封装器。 • TextWiser:[9]用于将原始文本特征转换为数值嵌入。 • scikit-learn: 用于特征缩放和编码。 • Faker 和 Pandas: 用于合成数据生成和模拟。
开发环境可以按如下方式构建:
1$ git clone https://github.com/jaehyeon-kim/streaming-demos.git 2$ cd streaming-demos 3$ uv python install 3.11 4$ uv venv --python 3.11 venv 5$ source venv/bin/activate 6(venv) $ uv pip install -r product-recommender/requirements.txt 7(venv) $ uv pip list | grep -E "mab|wiser|panda|numpy|scikit|faker" 8# Using Python 3.11.14 environment at: venv 9# faker 40.1.210# mab2rec 1.3.111# mabwiser 2.7.412# numpy 1.26.413# pandas 1.5.314# scikit-learn 1.8.015# textwiser 2.0.2帖子源代码
本文的源代码可在streaming-demos[10] GitHub 存储库的product-recommender 文件夹中找到。
数据生成
我们首先需要产品和用户数据来生成所需的功能。
产品
我们利用一组200 个原始产品 ,每个产品都包含产品 ID、名称、文本描述、价格和高级类别。
以下是一些样品产品列表:
用户
我们使用Faker生成1000 个合成用户 。每个用户都被赋予年龄、性别、位置和流量来源等静态属性。这些属性将作为我们 Bandit 算法的“上下文”。
以下是我们部分用户群体的示例:
请注意,街道地址、邮政编码、城市、州和国家/地区均已省略,因为特征生成仅使用纬度和经度。
特征工程
Bandit 算法处理的是数值向量,而非原始文本。换句话说,除非将 "Burger" 转换为数字,否则它们无法进行解析。为了解决这个问题,我们开发了一个转换流程来正确准备数据:
1. 产品特征: 我们使用 TextWiser将原始产品描述转换为向量嵌入。这使得模型能够理解“汉堡”和“三明治”在语义上比“汉堡”和“耳机”更接近。我们还对类别(产品类别)应用了独热编码,并对价格应用了 MinMax 缩放。最后,我们添加了一个二元特征is_coffee,咖啡产品(例如,浓缩咖啡、卡布奇诺)的该特征值为 1,其他产品为 0。2. 用户特征: 与产品特征类似,我们对类别(性别和流量来源)应用了独热编码,对数值字段(年龄、纬度和经度)应用了 MinMax 缩放。 3. 管道工件: 我们将这些转换器保存为 preprocessing_artifacts.pkl。这使得我们的系统能够在推理过程中立即将任何新的用户/产品记录转换为兼容的特征向量。
经过处理的产品特性示例:
请注意,各描述现在是如何用 txt_0…txt_9 嵌入表示的。
经过处理的用户特征示例:
请注意,年龄、纬度和经度均已归一化到 0 到 1 之间,分类字段为二元字段。
老虎机历史模拟
为了评估我们的模型是否能够真正学习用户行为 ,我们需要一个受控的真实标签(Ground Truth) ,它是一个预言机(Oracle),用于确定“模拟用户点击推荐内容“的可能性。
至关重要的是,这个预言机对模型是隐藏的 。模型的任务是完全通过反复试验来推断这些模式。
我们还会将动态上下文 特征(例如时间 、星期几) 在交互发生时注入到用户个人资料中。这些时间信号会创建出真实且不断变化的模式,模型必须能够适应这些模式。
仿真逻辑
该模拟以类的形式实现GroundTruth,我们定义了控制用户行为的具体规则:
• 从较低的基准 logit(-2.5)开始,模拟普遍较低的点击概率。 • 规则 1:早晨咖啡偏好: 如果用户在早上浏览商品,并且该商品是咖啡产品,则大幅提高评分。 • 规则 2:周末舒适食品: 如果比赛在周末进行,且食物是披萨或汉堡和三明治,则给予适度的正面提升。 • 规则 3:预算敏感性: 如果用户年龄较轻(标准化年龄 < 0.25)且商品价格昂贵(标准化价格 > 0.8),则施加较大的负面惩罚。 • 规则 4:流量来源偏好: 如果用户是通过搜索访问的,则根据用户意图进行少量推广。 • 使用 sigmoid 函数将最终 logit 得分转换为点击概率,然后对伯努利试验进行采样,以模拟是否发生点击。
1# product-recommender/recsys-engine/src/bandit_simulator.py 2class GroundTruth: 3 """ 4 The HIDDEN FORMULA (Ground Truth) for click simulation. 5 Determines user click behavior based on context and item features. 6 """ 7 8 @staticmethod 9 def calculate_probability(user_ctx: dict, item_ctx: dict) -> float:10 """11 Computes the probability that a user clicks an item.12 Uses logistic regression-style scoring with domain-specific rules.13 """14 score = -2.5 # Base logit: starts with a low probability1516 # Rule 1: Morning Coffee17 # Users are more likely to click coffee in the morning18 if user_ctx.get("is_morning") == 1 and item_ctx.get("is_coffee") == 1:19 score += 2.52021 # Rule 2: Weekend Comfort Food22 # Users tend to choose Pizza or Burgers on weekends23 if user_ctx.get("is_weekend") == 1:24 if item_ctx.get("cat_Pizzas") == 1 or item_ctx.get("cat_Burgers & Sandwiches") == 1:25 score += 1.82627 # Rule 3: Budget Constraint28 # Young users (<25 years) avoid expensive items (normalized price > 0.8)29 user_age = user_ctx.get("age", 0.5) # normalized age 0-130 item_price = item_ctx.get("price", 0.5) # normalized price 0-131 if user_age < 0.25 and item_price > 0.8:32 score -= 3.03334 # Rule 4: Traffic Bias35 # Users arriving via Search have a slightly higher propensity to click36 if user_ctx.get("traffic_source_Search") == 1:37 score += 0.53839 # Convert logit score to probability using sigmoid function40 return 1 / (1 + np.exp(-score))4142 def will_click(self, user_ctx: dict, item_ctx: dict, fake: Faker) -> int:43 """44 Simulates a Bernoulli trial (click = 1, no click = 0) based on probability.45 """46 prob = self.calculate_probability(user_ctx, item_ctx)47 return 1 if fake.random.random() < prob else 0数据准备
我们生成 10,000 个历史事件作为“离线训练”数据集。此过程包括随机选择一个用户和一个产品,然后向 Oracle 询问“他们是否点击了?”。
由于用户和产品是随机匹配的(并非通过推荐系统),平均点击率 (CTR) 自然较低。在本例中,CTR 约为13.65% ,这作为我们的基准值。
本文包含三个主要脚本:prepare_data.py 用于特征工程和多臂老虎机历史模拟,evalue.py 用于离线策略评估,以及 live_recommender.py 用于实时推荐。每个脚本都接受一个 --seed 参数,默认值为*1237。*只要随机种子保持不变,运行这些脚本就会产生相同的输出。
1(venv) $ python product-recommender/recsys-engine/prepare_data.py 2[2026-01-26 19:16:09] INFO : Generating 1000 synthetic users... 3[2026-01-26 19:16:09] INFO : Saved raw users to: .../users.csv 4[2026-01-26 19:16:09] INFO : Starting Feature Engineering... 5[2026-01-26 19:16:09] INFO : Saved User Features: (1000, 11) 6[2026-01-26 19:16:10] INFO : Saved Product Features: (200, 21) 7[2026-01-26 19:16:10] INFO : Saved Pipeline Artifacts to: .../preprocessing_artifacts.pkl 8[2026-01-26 19:16:10] INFO : Loaded 1000 users and 200 products. 9[2026-01-26 19:16:10] INFO : Generating 10000 events...10[2026-01-26 19:16:10] INFO : Done. Saved Training Log to .../training_log.csv11[2026-01-26 19:16:10] INFO : Avg Click Rate: 13.65%12[2026-01-26 19:16:10] INFO : Data Preparation Complete.主数据集(training_log.csv)结合了用户特征、动态上下文(例如is_morning)、产品 ID和交互结果(response):
离线策略评估
我们使用 Mab2Rec 对 10,000 个历史事件中的几种策略进行了基准测试。
候选策略
• 随机: 基准设置。不加任何设置地推荐商品。 • 人气: 推荐全局点击率最高的商品。 • *结果:*一般(AUC 约为 0.59)。虽然比随机选择要好,但仍然无法捕捉到具体的规则,例如“早晨咖啡”和“周末披萨”。 • LinGreedy: 具有 ϵ 贪婪探索的不相交线性回归。 • LinUCB(获奖者): 具有置信上限的 不相交线性回归。 • LinTS(汤普森采样): 从概率分布中采样的贝叶斯回归。
获胜者:LinUCB
虽然LinGreedy 实现了最高的理论排名准确率(AUC 0.88),但由于它过早地利用了“安全”的选择,因此点击率较低(CTR 11%)。
LinUCB 是实际的赢家。它的排名准确率( AUC ~0.86 )与LinGreedy 相当,但用户参与度(CTR ~20.5%)几乎是 LinGreedy 的两倍 。
该算法的优势在于它能够平衡两个相互冲突的目标:
1. 利用(exploitation): 它使用点击的预测概率()来寻找好的商品。 2. 探索(exploration): 它会在得分中添加一个置信区间()。如果模型对特定情境不确定(例如,“我以前从未见过用户在晚上 8 点喝咖啡”),则区间会扩大,从而提高得分并强制模型检验该假设。
这使得 LinUCB 能够发现保守的 LinGreedy 模型所错过的高价值机会。
1(venv) $ python product-recommender/recsys-engine/evaluate.py 2Running Benchmark... (This trains and scores all models automatically) 3-------------------------------------------------------------------------------- 4Available Metrics: ['AUC(score)@5', 'CTR(score)@5', 'Precision@5', 'Recall@5'] 5 AUC(score)@5 CTR(score)@5 Precision@5 Recall@5 6Random 0.550000 0.102041 0.003876 0.019380 7Popularity 0.592857 0.192308 0.007752 0.038760 8LinGreedy 0.885185 0.117647 0.004651 0.023256 9LinUCB 0.860317 0.204545 0.006977 0.03488410LinTS 0.640798 0.211538 0.008527 0.04263611ClustersTS 0.550505 0.153846 0.004651 0.02325612--------------------------------------------------------------------------------为什么 LinUCB 在 CTR 方面优于基线
这是线下策略评估 的核心概念。
该基准测试并非 测试历史记录中的每一行数据。它使用了一种称为拒绝抽样(Rejection Sampling) (或简称“匹配 (Matching)”)的技术。
以下是mab2rec计算20.5% 的具体方法:
1. 日志(历史记录): 由于是随机生成的,因此包含“好的决策”和“坏的决策”。 • A 行:早晨用户 → → 显示披萨 → →不点击 (糟糕的随机选择) • B 行:早晨用户 → → 显示咖啡 → →点击 (幸运随机选择) 2. 测试(LinUCB): 该模型很智能。它知道早上来的用户想要咖啡。 • 对于 A 排,LinUCB 说:“我推荐咖啡 。” • 不匹配! 历史记录显示的是披萨。我们无法得知如果显示的是咖啡会发生什么。此行将被忽略。 • 对于 B 排,LinUCB 说:“我推荐咖啡 。” • 匹配! 历史记录显示为咖啡。我们知道结果(点击)。此行已计入。
数据集平均值( 13.7% )包含了所有“糟糕的随机选择”(A 行)。LinUCB 分数( 20.5% )则过滤掉了 这些糟糕的选择。它实际上反映的是: *“在极少数情况下,随机历史记录确实显示了正确的产品(B 行),用户是否点击了该产品?”*由于 LinUCB 只关注“正确的产品”,因此这些特定匹配的点击率远高于随机结果的平均值。
实时推荐系统模拟
选定模型后,我们构建了一个实时推荐脚本。该脚本在一个持续循环中同时充当服务器、用户和训练器的角色。
步骤 1:预训练(离线回放)
我们不想从一个“愚蠢的”模型开始。我们加载 10000 个历史事件(training_log.csv)并运行model.fit()。这使得老虎机在实时循环开始之前就对世界有了基本的了解。
步骤 2:在线循环
我们模拟一系列用户访问:
1. 用户到达: 从用户池中随机选择一个用户。 2. 上下文关联: 注入一个模拟时间戳(例如,介于周一上午 8:00 和周六晚上 9:00 之间)。这是模型必须响应的关键“上下文”。 3. 推荐: LinUCB 计算所有 200 种产品的得分,并返回前 5 名。 4. 反应: GroundTruthOracle 决定用户是否点击。5. 在线更新: 我们调用 model.partial_fit()。这将立即更新矩阵(A 和 b)。 下一个推荐将反映这一新学习结果。
以下是来自实时循环的 30 条推荐记录示例。
1(venv) $ python product-recommender/recsys-engine/live_recommender.py 2[2026-01-26 19:18:49] INFO : Loaded 1000 users 3[2026-01-26 19:18:49] INFO : Loading artifacts... 4[2026-01-26 19:18:53] INFO : Loaded 200 products. 5[2026-01-26 19:18:53] INFO : Pre-training model from history... 6[2026-01-26 19:18:53] INFO : Model pre-trained on 10000 events. 7 8--- STARTING LIVE LOOP (30 visits) --- 910User 0153 (56 yo) @ Tue 21:17 -> Recs: [058, 126, 018, 200, 085] -> Clicked: 058 (❌)11User 0909 (21 yo) @ Thu 12:12 -> Recs: [165, 087, 026, 147, 157] -> Clicked: 165 (❌)12User 0406 (30 yo) @ Thu 01:43 -> Recs: [147, 089, 165, 127, 105] -> Clicked: 147 (❌)13User 0317 (31 yo) @ Sat 18:54 -> Recs: [042, 051, 008, 018, 040] -> Clicked: 042 (✅)14User 0246 (44 yo) @ Sun 06:31 -> Recs: [192, 139, 008, 040, 051] -> Clicked: 192 (✅)15User 0974 (61 yo) @ Sun 15:52 -> Recs: [051, 009, 058, 059, 124] -> Clicked: 051 (✅)16User 0234 (26 yo) @ Fri 13:30 -> Recs: [036, 103, 002, 186, 070] -> Clicked: 070 (✅)17User 0360 (35 yo) @ Fri 13:06 -> Recs: [015, 171, 069, 038, 036] -> Clicked: 015 (❌)18User 0513 (51 yo) @ Fri 03:47 -> Recs: [058, 073, 124, 074, 051] -> Clicked: 058 (❌)19User 0640 (33 yo) @ Fri 21:08 -> Recs: [023, 124, 073, 126, 090] -> Clicked: 023 (❌)20User 0363 (31 yo) @ Wed 19:54 -> Recs: [200, 126, 085, 018, 067] -> Clicked: 067 (✅)21User 0718 (58 yo) @ Thu 19:23 -> Recs: [018, 086, 036, 019, 047] -> Clicked: 018 (✅)22User 0390 (49 yo) @ Sat 21:15 -> Recs: [018, 042, 040, 036, 049] -> Clicked: 018 (✅)23User 0425 (39 yo) @ Sat 22:11 -> Recs: [042, 018, 040, 043, 056] -> Clicked: 043 (✅)24User 0792 (21 yo) @ Wed 10:39 -> Recs: [192, 139, 102, 073, 189] -> Clicked: 189 (✅)25User 0190 (41 yo) @ Wed 04:14 -> Recs: [200, 124, 057, 076, 015] -> Clicked: 124 (✅)26User 0544 (41 yo) @ Sun 17:01 -> Recs: [009, 020, 051, 036, 087] -> Clicked: 036 (✅)27User 0192 (17 yo) @ Sat 01:08 -> Recs: [055, 139, 041, 042, 008] -> Clicked: 055 (✅)28User 0757 (55 yo) @ Wed 02:15 -> Recs: [200, 124, 037, 015, 076] -> Clicked: 200 (✅)29User 0904 (60 yo) @ Sun 22:41 -> Recs: [042, 018, 103, 019, 041] -> Clicked: 019 (✅)30User 0552 (39 yo) @ Wed 22:26 -> Recs: [126, 018, 058, 036, 195] -> Clicked: 036 (✅)31User 0540 (36 yo) @ Sun 07:52 -> Recs: [043, 073, 041, 192, 014] -> Clicked: 043 (✅)32User 0326 (26 yo) @ Thu 05:15 -> Recs: [200, 124, 057, 139, 076] -> Clicked: 200 (❌)33User 0834 (29 yo) @ Sun 02:07 -> Recs: [051, 002, 036, 103, 057] -> Clicked: 036 (✅)34User 0290 (21 yo) @ Sat 15:28 -> Recs: [051, 038, 036, 040, 008] -> Clicked: 038 (✅)35User 0275 (18 yo) @ Mon 11:56 -> Recs: [189, 002, 160, 078, 103] -> Clicked: 189 (✅)36User 0327 (23 yo) @ Mon 07:29 -> Recs: [192, 189, 139, 190, 193] -> Clicked: 192 (✅)37User 0144 (67 yo) @ Sat 20:37 -> Recs: [043, 036, 018, 014, 009] -> Clicked: 018 (✅)38User 0497 (60 yo) @ Mon 16:13 -> Recs: [015, 171, 069, 038, 049] -> Clicked: 015 (❌)39User 0508 (64 yo) @ Tue 08:50 -> Recs: [192, 194, 190, 189, 123] -> Clicked: 194 (✅)4041--- END LOOP ---实时模拟评估
该模型表现出色,点击率达到 80%(30 次点击中有 24 次成功) 。
主要观察结果:
• 早晨咖啡规则已验证: 该模型成功识别出工作日的特定“早晨咖啡”偏好(ID 189-194)。 • 证据:用户 0327 (星期一 07:29)被推荐了一个完全由咖啡组成的列表(ID 192、189、139、190、193),并点击了长黑咖啡(192) 。 • 证据:用户 0508 (周二 08:50)和用户 0792 (周三 10:39)被以类似的方式定位,并分别点击了冰巧克力(194) 和馥芮白(189) 。 • 周末舒适食品实锤: 周六和周日,无论时间如何,这家店都全力转型供应披萨 和汉堡 。 • 证据:用户 0317 (周六 18:54)和用户 0425 (周六 22:11)收到的列表主要由披萨 ID(042、040、043)组成,并点击了澳式披萨(042) 和肉食爱好者披萨(043) 。 • 证据: 即使在周日清晨,用户 0540 (周日 07:52)也优先点击了 “肉食爱好者披萨”(043) ,这表明在这种情况下,“周末”信号压倒了“早晨”信号。 • “禁止点击”区域(工作日): 大多数故障(❌)发生在工作日下午或深夜 (例如,周四 12:12、周五 13:06、周五 03:47)。 • 理由: 我们的“真实值”公式明确定义了上午和周末的特定提升幅度。但它并未明确定义“周二晚上”的偏好,导致交互概率较低,模型也难以准确预测。
结论: LinUCB 算法已成功逆向工程出隐藏逻辑(时间 + 上下文),并积极利用该逻辑来提高用户参与度。
为什么点击率 (CTR) 这么高 (80%)?
• 在实际生产系统中,点击率 (CTR) 通常为 2-5%。我们的模拟结果由于采用了前五名“安全网” 机制,点击率达到了约 80%。通过展示 5 个相关项目,每个项目在上下文匹配时大约有 50% 的点击概率,列表中至少出现一个点击的概率接近 97%。 • 为了演示,这种高信号是故意设置的。它清晰地表明该架构有效,并且模型已经学习了规则,而不会受到真实随机性的干扰。
接下来是什么?
我们已成功构建了一个能够学习基于时间偏好的情境老虎机算法原型。然而,这个 Python 脚本在生产环境中存在诸多局限性:
1. 可扩展性: Disjoint LinUCB为每个产品维护一个矩阵。如果产品数量达到 1000 万,单个服务器的内存将会耗尽。2. 延迟: 训练过程( partial_fit)会阻塞推理过程(recommend)。在实际系统中,不能让用户等待模型更新。3. 容错性: 如果脚本崩溃,学习到的状态将会丢失。 4. 并发性: 单个 Python 进程无法处理数千个并发请求。
在第二部分:使用 Flink、Kafka 和 Redis 扩展在线学习中 ,我们将把这个原型转换为事件驱动架构 :
• Kafka 将异步传输点击事件。 • Flink 将处理分布式、有状态模型的训练。 • Redis 将提供模型矩阵,以实现亚毫秒级推理。
敬请关注!
https://jaehyeon.me/blog/2026-01-29-prototype-recommender-with-python/
引用链接
[1] 协同过滤: https://en.wikipedia.org/wiki/Collaborative_filtering[2] **情境多臂老虎机(CMAB)** : https://en.wikipedia.org/wiki/Multi-armed_bandit#Contextual_bandit[3] 强化学习形式: https://en.wikipedia.org/wiki/Reinforcement_learning[4] **Vowpal Wabbit** : https://vowpalwabbit.org/[5] **River ML** : https://riverml.xyz/latest/[6] **Mab2Rec** : https://github.com/fidelity/mab2rec[7] **MABWiser** : https://github.com/fidelity/mabwiser[8] **uv** : https://docs.astral.sh/uv/[9] **TextWiser:** : https://github.com/fidelity/textwiser[10] streaming-demos: https://github.com/jaehyeon-kim/streaming-demos[11] stephen.parker@example.net: mailto:stephen.parker@example.net[12] brianna.williams@example.net: mailto:brianna.williams@example.net[13] carlos.hunt@example.com: mailto:carlos.hunt@example.com[14] charles.martin@example.com: mailto:charles.martin@example.com

