1秒处理1亿行,这8个Python库彻底让Excel消失
- 2026-07-06 01:56:35
处理数据的时候,我发现 Excel 有时候不好用,不是说它的功能不好用,而是它的隐形转换和不可复现输在起跑线上了。日期格式错乱、大文件卡死、逻辑难以追踪,这些问题在工程化项目中是致命的。

所以,我整理了一套 Python 工具栈。它们不搞花哨的噱头,只解决具体的问题。
DuckDB:轻松搞定亿级数据
如果在单机上处理几百兆到几 GB 的数据,Pandas 的内存占用简直让我抓狂。DuckDB 的出现填补了 SQLite 和分布式数据库之间的空白。它是一个进程内的 OLAP 数据库,最大的特点是零配置和向量化计算。DuckDB 可以直接对 CSV、Parquet 或 JSON 文件执行 SQL 查询,无需将数据全部加载到内存。
import duckdb# 直接对 Parquet 文件执行 SQL,无需建库建表# 这里的 query 类似于 Pandas 的 dataframe,但计算是在 DuckDB 引擎中完成的result = duckdb.sql(""" SELECT department, AVG(salary) as avg_salary FROM 'employees.parquet' WHERE join_date > '2022-01-01' GROUP BY department ORDER BY avg_salary DESC""").df()print(result)Ibis:写一次代码,到处运行
Ibis 和 DuckDB 是目前数据工程领域的黄金搭档。Ibis 将业务逻辑与执行引擎分离,这也是它的核心。可以使用类似 Pandas 的 Python API 来编写查询逻辑,后端可以无缝切换为 DuckDB、ClickHouse、BigQuery 甚至是 PySpark。
使用 Ibis 驱动 DuckDB 时,既享受了 Python 代码的优雅和类型检查,又利用了 DuckDB 极速的执行引擎。一举两得,棒棒哒。
import ibis# 连接到 DuckDB 后端(也可以是 SQLite, Postgres 等)con = ibis.duckdb.connect()# 惰性读取数据,此时并未真正加载table = con.read_csv("sales_data.csv")# 构建查询表达式expr = ( table.filter(table["status"] == "completed") .group_by("region") .aggregate(total_revenue=table["amount"].sum()) .order_by(ibis.desc("total_revenue")))# 只有调用 execute() 时才会生成 SQL 并执行print(expr.execute())Polars:多线程时代的 DataFrame
Pandas 是单线程的,而 Polars 是用 Rust 编写的,天生支持并行计算。在处理大规模数据集时,Polars 的速度通常比 Pandas 快数倍。它的设计理念采用了“惰性求值”(Lazy Evaluation),先构建查询计划,经优化器优化后再执行,这能极大减少内存开销。
import polars as pl# 扫描文件而非读取,启用 Lazy 模式q = ( pl.scan_csv("large_dataset.csv") .filter(pl.col("age") > 30) .select(["name", "salary", "department"]) .group_by("department") .agg(pl.col("salary").mean().alias("avg_salary")))# collect() 触发实际计算df = q.collect()print(df)PyArrow Compute:底层的计算基石
PyArrow 不仅仅是数据格式标准,其 compute 模块提供了一套高性能的向量化计算函数。很多现代数据工具(包括 Pandas 2.0+)底层都在使用它。如果需要对数组进行极速的数学运算或字符串处理,且不想引入 DataFrame 的额外开销,可以考虑一下 PyArrow Compute。
import pyarrow as paimport pyarrow.compute as pc# 创建 Arrow 数组arr_a = pa.array([10, 20, 30, 40, None])arr_b = pa.array([2, 4, 5, 8, 1])# 使用计算内核进行向量化乘法,自动处理 None 值result = pc.multiply(arr_a, arr_b)# 过滤数据mask = pc.greater(result, 50)filtered = pc.filter(result, mask)print(filtered)TinyDB:面向文档的轻量级存储
并非所有项目都需要 PostgreSQL。对于配置文件管理、小型爬虫数据存储或单机小工具,TinyDB 非常合适。它是一个纯 Python 编写的文档型数据库,数据存储在 JSON 文件中,API 像操作 Python 列表一样自然。
from tinydb import TinyDB, Querydb = TinyDB('local_storage.json')User = Query()# 插入数据db.insert({'name': 'Alice', 'role': 'admin', 'points': 85})db.insert({'name': 'Bob', 'role': 'user', 'points': 60})# 查询数据results = db.search(User.role == 'admin')print(results)Rill:开发者的 BI 工具
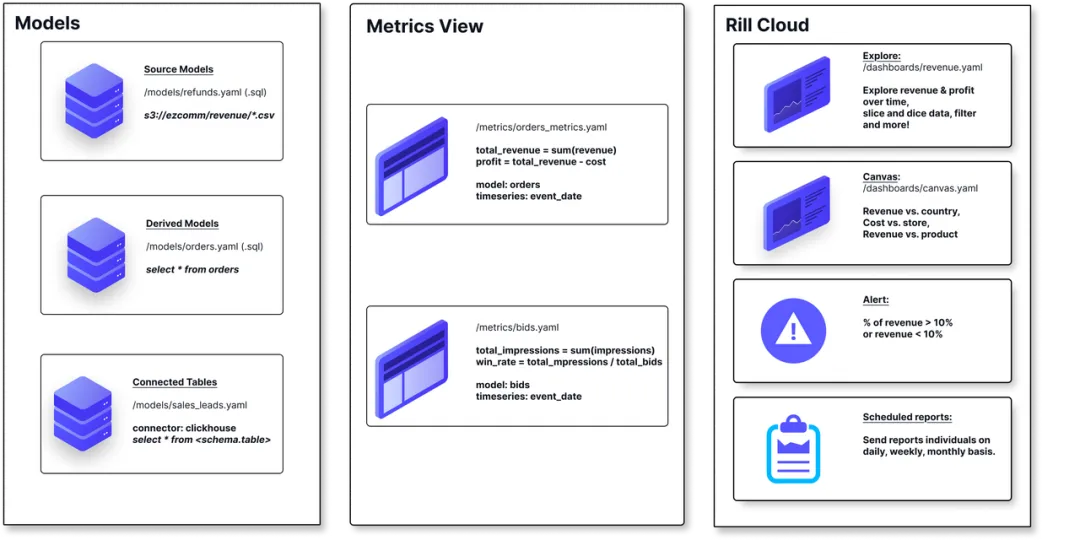
虽然 Rill 更像是一个工具而非传统的 Python 库,但它在现代 Python 数据栈中地位独特。Rill 基于 DuckDB,能够快速读取本地数据(CSV, Parquet),并瞬间生成交互式的 BI 仪表盘。它解决了“为了看个图表还要搭一套 Superset”的痛点,非常适合快速探索数据分布。
Numba:让 Python 跑出 C 的速度
当代码中包含大量原生 for 循环(如科学计算、复杂算法)时,Python 的解释器性能往往成为瓶颈。Numba 是一个 JIT(即时)编译器,通过加一行装饰器,就能将 Python 函数编译成机器码运行。
from numba import jitimport time# 不使用 @jit 时,Python 循环较慢# 使用 nopython=True 强制生成机器码@jit(nopython=True)def heavy_computation(n): total = 0 for i in range(n): total += i * 2 return totalstart = time.time()print(heavy_computation(100_000_000))print(f"耗时: {time.time() - start:.4f} 秒")Bonobo:轻量级 ETL 框架
对于不需要 Airflow 这种重型调度系统的数据迁移任务,Bonobo 提供了一种基于图(Graph)的轻量级 ETL 方案。它使用纯 Python 代码定义数据流向,逻辑清晰,非常适合处理中小规模的数据清洗和转换任务。
import bonobodef extract(): yield {'id': 1, 'name': ' Item A '} yield {'id': 2, 'name': ' Item B '}def transform(row): return { 'id': row['id'], 'name_clean': row['name'].strip().upper() }def load(row): print(f"Loading: {row}")def get_graph(**options): graph = bonobo.Graph() graph.add_chain(extract, transform, load) return graphif __name__ == '__main__': # 实际运行时使用 bonobo run parser = bonobo.get_argument_parser() with bonobo.parse_args(parser) as options: bonobo.run(get_graph(**options))上述库涵盖了从数据存储、计算引擎到 ETL 流程的各个环节,Python的库,需要的肯定是 Python 环境。
而且码农怎么可能只有一个项目需要维护呢?肯定是有的依赖最新的 Python 3.14,有的则必须跑在 Python 3.8 甚至古老的 Python 2.7 上维护遗留系统。系统自带的 Python 环境一旦弄乱,修复起来就头大了。
那这时候我们就要请上 ServBay 了。
ServBay 为开发者提供了一个隔离且纯净的开发环境。它最大的优势是一键部署和多版本共存。
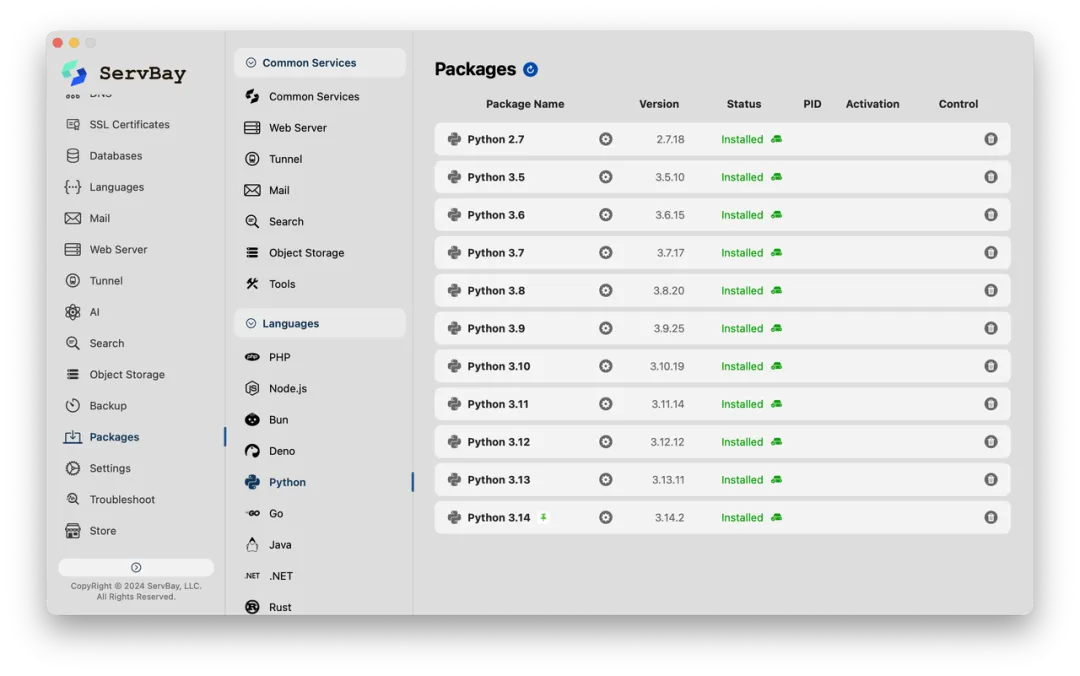
极速安装: 还在用命令行就out了。ServBay 点击即可安装好包含常用组件的开发环境。 全版本支持: 它支持从最新的 Python 3.x 到早期的 Python 2.x 版本。 环境隔离: ServBay 的环境独立于系统,不会污染系统自带的 Python,保证了系统的稳定性。
数据处理的边界正在被这些新兴的工具不断拓展。对于开发者而言,保持对新技术的敏感度,同时拥有一个随时能推倒重来且互不干扰的好工具,也是提高效率的关键。
#python #python库 #ServBay #python开发
欢迎关注ServBay 服务号👇

立即下载ServBay,加速你的工作效率

