本篇聚焦大商所网站的每日会员成交持仓排名数据的获取,目标是得到官方网站展示的排名前若干名的期货公司的成交量,多头持仓量和空头持仓量(下图)。
需要说明的是,目前国内各家商品交易所对于合约的头部成交持仓数据的发布规则各有不同。上期所、大商所和广期所只公布每个品种的各合约数据,没有公布品种的总数据,郑商所则同时公布品种的总数据和各合约的数据。此外交易所也规定,合约需要满足持仓量大于某阈值的前提下才会公开该合约的成交持仓数据,不同品种的阈值也不尽相同。比如大商所的规则是只要合约持仓大于2万手就会公布排名。一、某日期的上市合约代码数据下载
首先在大商所API文件里找到“日成交持仓排名”的地址URL
http://www.dce.com.cn/dceapi/forward/publicweb/dailystat/memberDealPosi
请求参数有四个:variteyId代表品种代码,填all可获得全部品种数据;tradeDate填写需要获取数据的日期;contractId填写合约代码;tradeType填写1代表期货,填2代表期权。
{"varietyId":"a","tradeDate":"20251010","contractId":"a2601","tradeType":"1"}
但在使用中发现一个问题,就是在发送请求时,contractId一次只能填入一个特定的合约代码(比如‘a2601’),不能填写多个合约(这样会返回空值),不像varietyId只填一个‘all’就能全部搞定。所以如果想获得全部合约的成交持仓排名数据,首先需要想办法获得指定日期的全部上市合约的合约代码,然后跑循环依次发送数据请求。
api文档里没有专门返回全部上市合约的URL,但可以通过其他URL顺便获取上市合约。经过尝试,决定使用每日行情数据的URL接口来获得当日上市的全部合约列表,这个URL返回的是当天所有上市合约的开高低收成交持仓等等,使用它的原因是可以根据他返回的成交量,把成交不活跃的合约筛除,减少后续循环的次数。筛选后,我们把合约代码组成一个列表。编写函数以及运行后获得的上市合约列表结果如下:
def _get_dce_contract_list_2026(date, dce_token): """ 获取标的合约列表 url = "http://www.dce.com.cn/dceapi/forward/publicweb/dailystat/dayQuotes" #每日行情数据的接口URL headers = {"apikey": "5aib9o54hldy", "Authorization": f"Bearer {dce_token}", "Content-Type": "application/json" } payload = {"varietyId":"all","tradeDate":date,"tradeType":"1","lang":"zh"} #请求参数 r = requests.post(url, headers=headers,json=payload) data_json = r.json() df = data_json['data'] temp_list = [] for i in df: if not i['contractId'].endswith('F'): #带F的合约是大商所最新上市的月均价合约,这里处理把它删除,不列入最终结果之内,也可以保留 temp_list.append(i['contractId']) return temp_list
二、指定日期合约成交持仓排名数据下载
获得合约列表后,需要写一个循环结构,每次向网站请求一个合约的数据。数据结果是三张表:成交排名表,多头持仓排名表和空头持仓排名表。我们的处理方法是按照排名将三表合并成一表,然后创建一个字典结构,键为合约代码,值就是合并后的表。具体细节较多,在代码里做适当注释。
需要说明的是第13行的time.sleep(10),因为遇到了大商所网站的限流。由于是循环请求数据,网站对于一段时间内的请求次数是有限制的,超过一定次数后需要休息1分钟(报错中提示的是1分钟),再发送请求。所以还需要在这段循环代码中解决这个问题,解决方法也很简单,就是每次循环前,暂停10秒钟即可,减少单位时间内的发送请求次数。def futures_dce_position_rank_2026(date_str: str, dce_token:str) -> dict: # 用上一步的函数来获取上市合约代码 symbol_list = _get_dce_contract_list_2026(date_str,dce_token) # 准备成交持仓排名数据的网址和请求头 url = "http://www.dce.com.cn/dceapi/forward/publicweb/dailystat/memberDealPosi" headers = {"apikey": "5aib9o54hldy", "Authorization": f"Bearer {dce_token}", "Content-Type": "application/json"} dict_temp = {} # 循环结构,每次输入一个symbol(合约代码)并申请这个合约的数据 for symbol in symbol_list: time.sleep(10) #每次循环前休息10秒,减少单位时间的请求次数,防止访问频繁被限流 payload = {"varietyId": ''.join(re.findall(r'[a-zA-Z]', symbol)), "tradeDate": date_str, "contractId": symbol, "tradeType": "1" } r = requests.post(url, headers=headers,json =payload) data_json = pd.DataFrame(r.json()['data']) # df_qty是当日该合约的成交量排名最多的前20家期货公司及成交量 df_qty = pd.DataFrame(data_json['qtyFutureList'].apply(parse_json_str).tolist()) df_qty.rename(columns={'qtyAbbr':'vol_party_name','todayQty':'vol','qtySub':'vol_chg'},inplace = True) # df_buy是当日该合约的多头持仓排名最多的前20名期货公司及多头持仓量 df_buy = pd.DataFrame(data_json['buyFutureList'] .apply(parse_json_str).tolist()) df_buy.rename(columns={'buyAbbr': 'long_party_name','todayBuyQty':'long_open_interest','buySub':'long_open_interest_chg'}, inplace=True) # df_sell是当日该合约的空头持仓排名最多的前20名期货公司及空头持仓量 df_sell = pd.DataFrame(data_json['sellFutureList'].apply(parse_json_str).tolist()) df_sell.rename(columns={'sellAbbr': 'short_party_name','todaySellQty':'short_open_interest','sellSub':'short_open_interest_chg'}, inplace=True) # 将三个df按照排名合并成一个df,并加上variety品种名和合约代码symbol两列 temp_df = pd.concat([df_qty,df_sell,df_buy],axis = 1) temp_df['variety'] = payload['varietyId'].upper() temp_df['symobl'] = symbol.upper() # 将最后的df存入字典中,键为合约代码,返回值为字典 dict_temp[symbol] = temp_df return dict_temp
第22行用了一个parse_json_str函数,主要是对原始数据的一些技术处理# 定义JSON解析函数(处理可能的格式错误)def parse_json_str(input_data): """ 处理混合类型的输入: 1. 若已是dict,直接返回 2. 若是字符串,尝试解析为dict 3. 空值/其他类型,返回空dict """ # 1. 先判断是否已是dict类型 if isinstance(input_data, dict): return input_data # 2. 处理空值(NaN、空字符串) if pd.isna(input_data) or str(input_data).strip() in ["", "nan"]: return {} # 3. 处理字符串类型(尝试解析JSON) try: return json.loads(str(input_data)) except JSONDecodeError: # 清理特殊字符后重试(应对不标准的JSON格式) cleaned_str = str(input_data).replace("'", '"').replace("\n", "").replace("\t", "").strip() try: return json.loads(cleaned_str) except: return {"error": "JSON解析失败", "raw_data": str(input_data)[:50]}
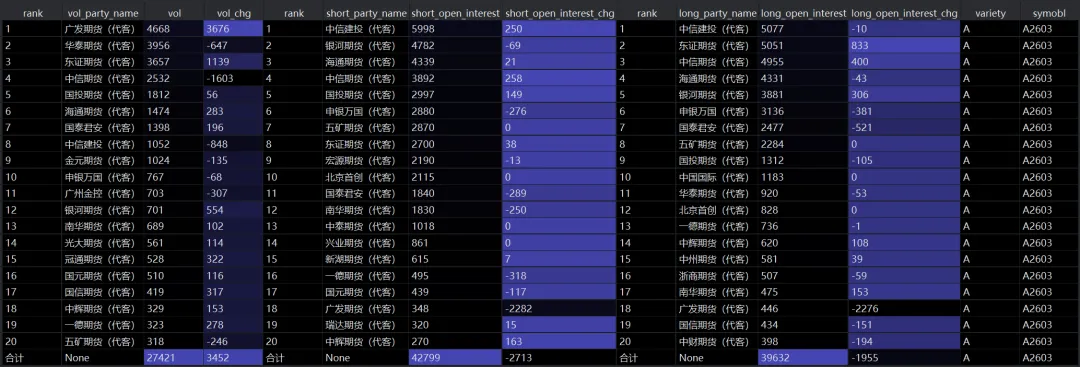
最终得到的结果,就是一个字典,每个元素是合约代码,以及对应的一张成交持仓排名表格。和网站显示的内容一致。下一篇将基于获取的的数据进行清洗和处理,最终目标是得到奇货可查网展示的数据。本篇完整代码可以后台回复“大商所成交持仓排名”获取。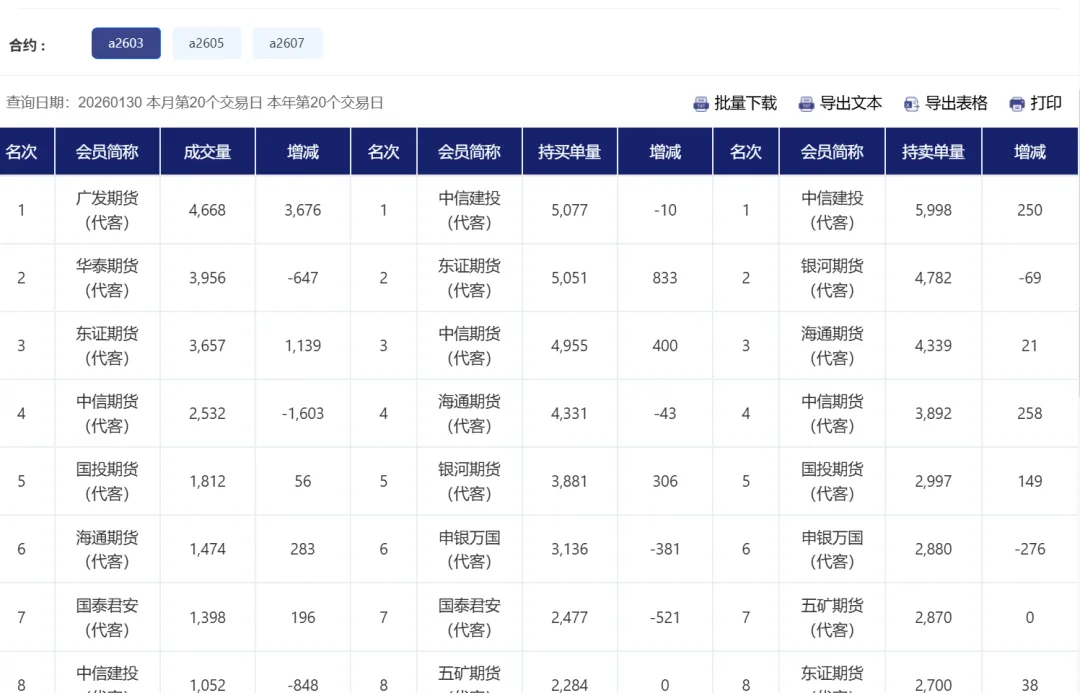
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
