期刊图复现 | Python 画 SHAP 环形蜂巢图 + 玫瑰花图
- 2026-07-04 04:33:44
很多时候做完模型训练后,会遇到两个“解释性”层面的需求:
特征到底谁更重要?(全局重要性排序) 重要性背后到底发生了什么?(同一特征在不同样本上的贡献分布、正负方向、以及与特征取值高低的关系)
传统条形图往往只能回答第 1 个问题;而 SHAP summary/beeswarm 虽然能回答第 2 个问题,但在做“图形化呈现”时不够紧凑。本文基于这个思路,把这两个问题合并到一张图里:
复现期刊及图片

复现结果
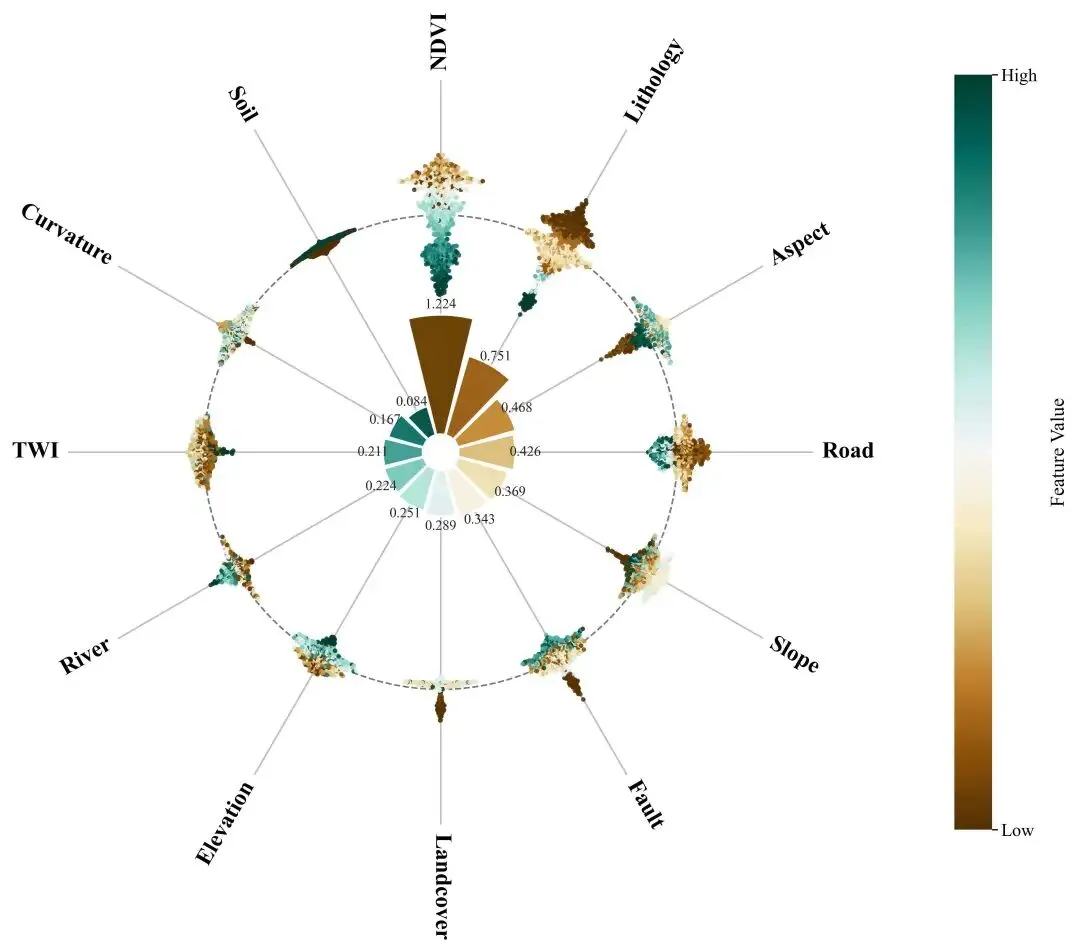
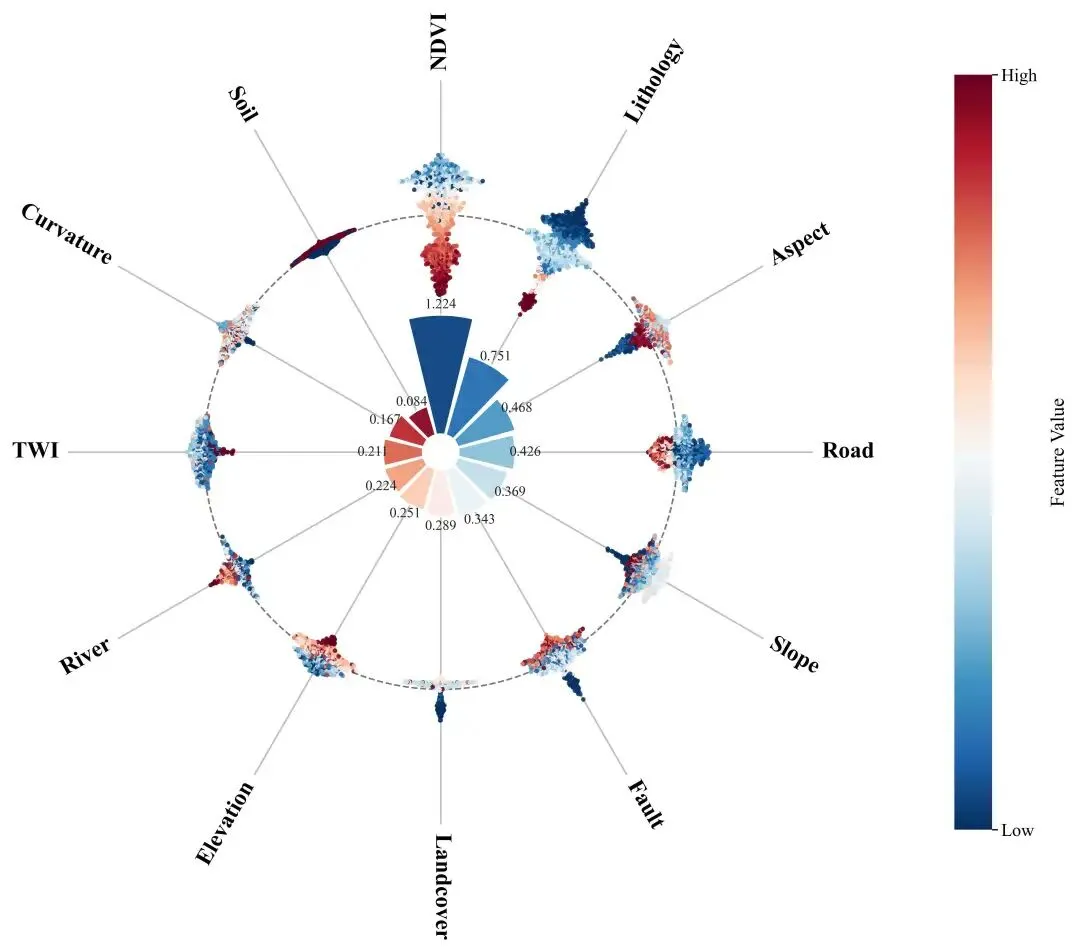
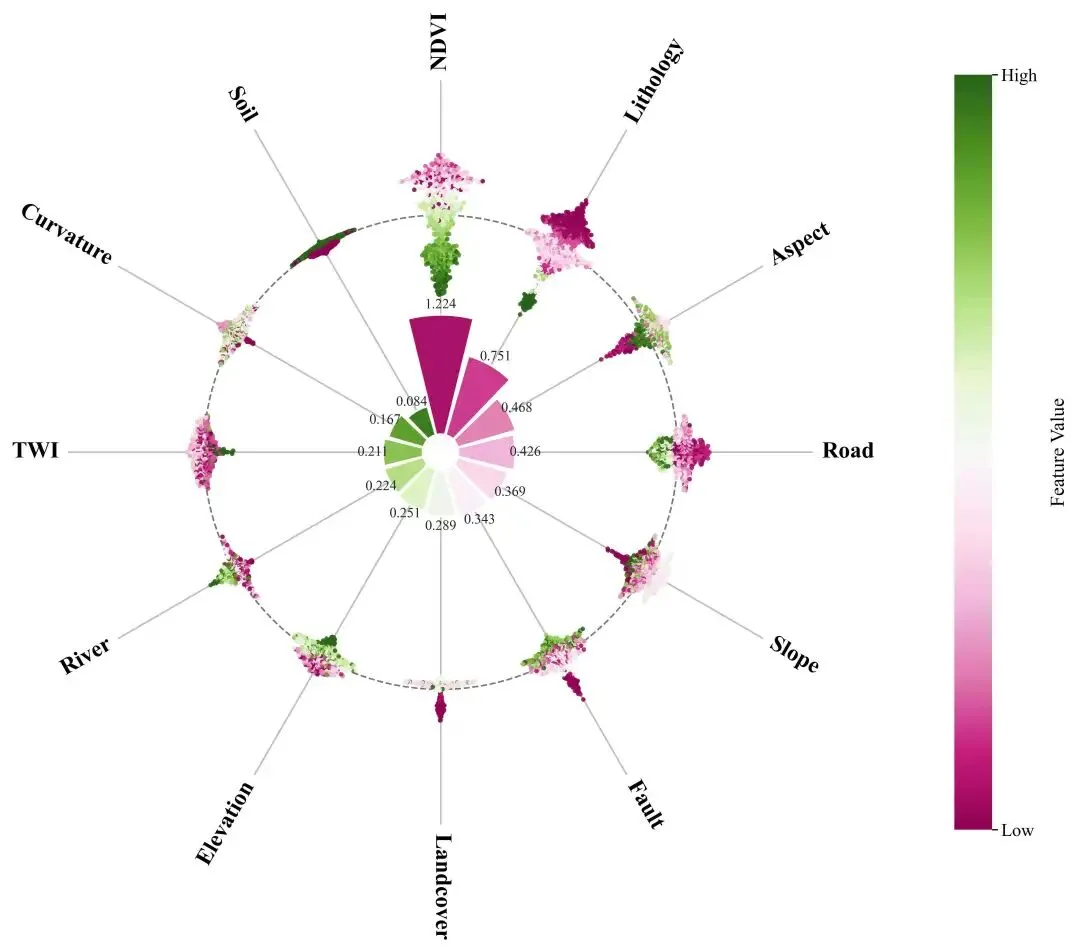
内圈玫瑰花图(环形柱):用 mean(|SHAP|)表达全局重要性,配合数值标注,直观看到“谁更重要”。外圈环形蜂巢图(极坐标 beeswarm):把每个样本的 SHAP 值映射到半径方向,再在角度方向做“蜂群抖动”防重叠;颜色用原始特征值(Low→High)映射,直观看到“高值/低值分别倾向推动正类还是负类”。
这类“内圈总结 + 外圈分布”的组合图特别适合论文插图或汇报:读者第一眼看重要性,第二眼看机制,而且画面非常紧凑。
为了让读者快速“读懂图”,建议你在文章/图注里给出一行读图规则:“看内圈花瓣高度=重要性;看外圈点在虚线圆内外=贡献正负;看点的颜色=特征取值高低(Low→High)。”
# 01_全局配置与参数from __future__ import annotationsfrom pathlib import Pathimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport shapimport xgboost as xgbplt.rcParams["font.family"] = "Times New Roman"plt.rcParams["axes.unicode_minus"] = Falseplt.rcParams["figure.dpi"] = 300plt.rcParams["savefig.bbox"] = "tight"plt.rcParams["font.size"] = 12RANDOM_SEED = 42CSV_FILE = "分类样本.csv"TARGET_COL = "label"OUTPUT_DIR = Path("images") # 输出目录(自动创建)CLASS_INDEX_FOR_SHAP = 0# 多分类时选哪一类的 SHAPTOP_N = None# 只画前 N 个特征(None=全部)COLOR_SCHEMES = [ ("RdBu_r", "RdBu_r"), ("Viridis", "viridis"), ("YlGnBu", "YlGnBu"),]1) 数据与模型:把分类问题“标准化”到可解释的输入输出
想画 SHAP 图,第一步不是“画”,而是把输入和输出变得稳定且可复现:特征矩阵必须是纯数值(分类变量要 one-hot),标签必须是可控的整数编码,模型要固定随机种子。这样做的好处是:
你后续计算的 SHAP 值维度稳定( (n_samples, n_features)),不会因为某一列是字符串而报错。同一份数据重复跑出来的结果一致(对比实验、换配色、换图形参数才有意义)。 多分类场景下,你能明确“我现在解释的是哪一类(class)”,避免把不同类别的贡献混在一张图里产生误读。
这篇文章以 XGBoost 分类器为例:它在科研场景里足够常见、效果稳定,而且 shap.TreeExplainer 对树模型速度非常快,适合做可视化。
另外两个常见“坑”也建议提前处理:(1)缺失值:XGBoost 可以处理缺失,但你的 one-hot 后矩阵如果混入 object 类型或 NaN 传播到字符串列,后面会很难排查;稳妥做法是先把数据清洗到“纯数值”。(2)列名与可读性:如果后续要发表/展示,建议把列名提前改成简洁但不含歧义的英文缩写;本文脚本也支持把长列名映射为 F1..Fn(便于排版),同时导出映射表。
defto_numeric_matrix(X: pd.DataFrame) -> pd.DataFrame: non_numeric = [c for c in X.columns ifnot pd.api.types.is_numeric_dtype(X[c])]return pd.get_dummies(X, columns=non_numeric, drop_first=False) if non_numeric else Xdata = pd.read_csv(CSV_FILE)X = to_numeric_matrix(data.drop(columns=[TARGET_COL]))# 标签编码:把任意字符串/整数标签统一成 0..K-1,并保留映射关系y_raw = data[TARGET_COL]y, y_classes = pd.factorize(y_raw, sort=True)print("类别映射:", dict(enumerate([str(v) for v in y_classes])))n_classes = len(y_classes)objective = "binary:logistic"if n_classes == 2else"multi:softprob"eval_metric = "logloss"if n_classes == 2else"mlogloss"model = xgb.XGBClassifier( n_estimators=300, max_depth=4, learning_rate=0.05, subsample=0.8, colsample_bytree=0.8, random_state=RANDOM_SEED, n_jobs=-1, objective=objective, eval_metric=eval_metric, num_class=(n_classes if n_classes > 2elseNone),)model.fit(X, y)2) 计算 SHAP:把“黑箱预测”拆成逐特征的加性贡献
在树模型里,SHAP 的核心输出是:对每个样本、每个特征,给一个实数贡献值(可正可负)。在分类任务中要注意两点细节:
二分类 vs 多分类的返回格式差异在一些版本组合下,
explainer.shap_values(X)可能返回 list(长度=类别数),也可能直接返回 array。稳妥做法是:检测list就按CLASS_INDEX_FOR_SHAP取某一类再画。把“重要性”定义成可排序的标量为了做内圈“玫瑰花柱”,需要每个特征一个标量。最常用也最稳健的是:
mean(|SHAP|)。它忽略正负方向,回答“这个特征对模型输出的平均影响强度有多大”。
做完这一步,你会得到两套信息:
mean_abs:长度为n_features的一维数组,给内圈排序/花瓣高度用。shap_values:形状(n_samples, n_features)的二维数组,给外圈蜂巢点阵用(看到分布、方向、异质性)。
解释上可以把它理解成一种“可加性分解”:模型对某个样本的输出,是“基线值 + 各特征贡献”的叠加。mean(|SHAP|) 只是在全体样本上把贡献的强度取了平均,因此特别适合做“全局重要性”;而外圈保留每个样本点,适合回答“在不同样本上这个特征到底怎么起作用”。
explainer = shap.TreeExplainer(model)shap_values = explainer.shap_values(X)# 兼容二/多分类:如果是 list,则选定一个类别来画if isinstance(shap_values, list): shap_values = shap_values[CLASS_INDEX_FOR_SHAP]shap_values = np.asarray(shap_values, dtype=float) # (n_samples, n_features)mean_abs = np.mean(np.abs(shap_values), axis=0)order = np.argsort(mean_abs)[::-1] # 重要性从高到低if TOP_N isnotNone: order = order[: int(TOP_N)]X_sel = X.iloc[:, order].to_numpy(dtype=float, copy=False)shap_sel = shap_values[:, order]mean_abs_sel = mean_abs[order]feature_names = [str(c) for c in X.columns]labels_sel = [feature_names[i] for i in order]3) 玫瑰花图(内圈):用极坐标环形柱表达全局重要性
“玫瑰花图”本质是极坐标柱状图:每个特征占一个角度扇区(theta),柱子的高度表示该特征的重要性(这里用 mean(|SHAP|))。为了画得更“出版级”,这里有几个关键处理:
高度缩放:重要性往往差异很大,直接用原值画,弱特征会几乎看不见。可以先把 mean_abs线性归一到[0,1],再映射到[MIN_H, MAX_H]的柱高范围。最短花瓣高度: MIN_H不是“美化”,它是为了避免某些特征在图上完全消失,从而导致读者误以为“没有该特征”。数值标注:公众号读者通常更希望“看见数值”,而不只是一堆颜色。每个花瓣顶部标注 mean(|SHAP|),图的解释成本会显著下降。
如果你希望“花瓣颜色也表达信息”,常见做法是用同一 colormap 对花瓣按重要性上色(越重要越深),但本文脚本把花瓣颜色做成均匀渐变,更多是为了增强层次与美观;真正的“信息承载”交给外圈颜色(特征值),避免信息冲突。
import matplotlib as mplm = len(order)theta = np.linspace(0.0, 2.0 * np.pi, m, endpoint=False)width = 2.0 * np.pi / float(m) * 0.92center_hole_r = 0.18# 中心空洞半径bar_max_h = 1.20# 花瓣最大高度min_h = 0.30# 最短花瓣(避免“消失”)min_mean = float(np.nanmin(mean_abs_sel))max_mean = float(np.nanmax(mean_abs_sel))if max_mean <= min_mean: heights = np.full_like(mean_abs_sel, min_h, dtype=float)else: scaled = (mean_abs_sel - min_mean) / (max_mean - min_mean) heights = min_h + np.clip(scaled, 0.0, 1.0) * (bar_max_h - min_h)fig = plt.figure(figsize=(8, 8))ax = plt.subplot(111, projection="polar")ax.set_theta_direction(-1) # 顺时针ax.set_theta_offset(np.pi / 2.0) # 0 度在正上方ring_colors = mpl.colormaps.get_cmap("viridis")(np.linspace(0.05, 0.95, m))ax.bar(theta, heights, width=width, bottom=center_hole_r, color=ring_colors, edgecolor="white", linewidth=1.2, alpha=0.98, zorder=3)for th, h, v in zip(theta, heights, mean_abs_sel): ax.text(th, center_hole_r + h + 0.10, f"{float(v):.3f}", ha="center", va="center", fontsize=8.5, color="#222222", zorder=6)4) 环形蜂巢图(外圈):把 SHAP 分布“搬到”极坐标上
外圈的目标不是再做一次“排序”,而是把每个特征的样本级贡献分布画出来:同一特征在不同样本上可能正负并存、幅度差异很大,这正是解释模型机制最关键的信息。
核心思想可以拆成三个映射:
半径映射(贡献→距离)设定一个外圈基准半径
r0,再把 SHAP 值按最大绝对值归一,映射到[r0 - scale, r0 + scale]。SHAP > 0的样本点落在r0外侧,表示“推动模型输出更偏向该类”。SHAP < 0的样本点落在r0内侧,表示“抑制该类”。角度抖动(beeswarm→蜂巢质感)同一扇区里点很多会重叠,所以在角度方向做小幅抖动:先按 SHAP 值分箱,再按
0,+1,-1,+2,-2...给出偏移序号,最终转成dtheta。点阵密集时会形成“蜂巢/蜂群”视觉效果。颜色映射(特征值→Low/High)对每个特征,把原始特征值做分位数截断后归一到
[0,1],再上色。这样能有效避免极端值把颜色拉爆,读者看到的是“主要样本的趋势”,而不是几个异常点在抢戏。
读图时你可以这样“快速判断关系”:
如果某特征的高值(偏黄/偏亮)主要落在 r0外侧,通常意味着“特征值越高越推动该类”;如果高值主要落在 r0内侧,则倾向“高值抑制该类”;如果颜色在内外两侧都很混杂,说明该特征与输出的关系可能非单调,或者存在与其他特征的交互(这时可以进一步看 interaction SHAP 或分组分析)。
defscale_to_unit_interval(values: np.ndarray, q_low: float = 5.0, q_high: float = 95.0) -> np.ndarray: values = values.astype(float) lo, hi = np.nanpercentile(values, [q_low, q_high])ifnot np.isfinite(lo) ornot np.isfinite(hi) or hi <= lo:return np.full_like(values, 0.5, dtype=float)return (np.clip(values, lo, hi) - lo) / (hi - lo)defbeeswarm_offsets_1d(values: np.ndarray, nbins: int = 45, spacing: float = 1.0) -> np.ndarray: values = np.asarray(values, dtype=float) offsets = np.zeros(values.shape[0], dtype=float) finite = np.isfinite(values)ifnot np.any(finite) or np.allclose(values[finite].min(), values[finite].max()):return offsets v = values[finite] edges = np.linspace(v.min(), v.max(), nbins + 1) bin_id = np.clip(np.digitize(v, edges, right=False) - 1, 0, nbins - 1) finite_idx = np.flatnonzero(finite)for b in range(nbins): idx = finite_idx[np.flatnonzero(bin_id == b)]for k, ii in enumerate(idx): step = (k + 1) // 2 sign = 1.0if (k % 2 == 1) else-1.0 offsets[ii] = 0.0if k == 0else sign * step * spacingreturn offsets# 外圈几何参数(可作为“蜂巢密度/外扩幅度”的主要调参入口)r0 = center_hole_r + bar_max_h + 1.00# 外圈基准半径(虚线圆位置)swarm_scale = 0.80# SHAP 径向展开幅度theta_spread = width * 0.32# 抖动角度幅度(越大越“蜂巢”但越拥挤)abs_shap_max = float(np.nanmax(np.abs(shap_sel))) or1.0value_cmap = mpl.colormaps.get_cmap("viridis")circle_theta = np.linspace(0.0, 2.0 * np.pi, 720)ax.plot(circle_theta, np.full_like(circle_theta, r0), linestyle="--", color="#777777", linewidth=1.0, zorder=2)for i in range(m): shap_i = shap_sel[:, i] feat_i = X_sel[:, i] colors = value_cmap(scale_to_unit_interval(feat_i)) offsets = beeswarm_offsets_1d(shap_i) max_off = float(np.max(np.abs(offsets))) if offsets.size else0.0 dtheta = np.zeros_like(offsets) if max_off <= 0else (offsets / max_off) * theta_spread r = r0 + (shap_i / abs_shap_max) * swarm_scale th = theta[i] + dtheta ax.scatter(th, r, s=7.5, c=colors, alpha=0.88, linewidths=0.0, zorder=5, rasterized=True)5) 批量配色导出 + 总结:一张图同时回答“谁重要”和“为什么重要”
到这里,内圈负责“全局重要性”,外圈负责“局部贡献分布 + 特征值梯度”,两者叠在同一极坐标系上,就能同时回答:
谁更重要:看内圈花瓣高度和标注数值( mean(|SHAP|))。重要性来自哪里:看外圈点云在 r0内外的分布(正负贡献),以及颜色(低值/高值)与正负贡献的对应关系。
实用建议(非常适合写在图注或方法部分):
想突出“少数关键特征”,把 TOP_N设置成10~20,图会更干净。多分类时一定明确 CLASS_INDEX_FOR_SHAP;建议在导出图名里也写上类别名,避免后续混淆。蜂巢更“松”还是更“密”,优先调 r0(外圈离内圈距离)和theta_spread(角度抖动幅度)。如果某些特征的颜色几乎都在一端,优先检查该特征是否离散/常数列;必要时对离散特征单独处理(比如更换 colormap 或只显示分组颜色)。
现在绘图代码都不支持免费获取了,20/篇文章。同时欢迎加入小编科研绘图VIP群,198/年,保证每年更新40篇以上的科研绘图相关文章,涵盖机器学习模型(回归和分类)的shap分析、还有各种如皮尔逊分析等相关的图,以及期刊复现图,源代码直接复制或者打开就能绘图。同时进群还赠送微信推文中所有绘图代码以及科研绘图SHAP分析软件和依赖图分析软件,且免费更新使用。后期还会免费赠送一些科研绘图小软件,还有拼图软件(开发中)VX:GISyanjiushengya!!!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 前特斯拉AI总监:AI编程最大的谎言是 “提效”!
- 我想掀翻桌子:当一个影评人决定用代码“杀死”剪辑软件
- Linux 命令学习之网络相关
- 邹军:钛合金加工,90%的编程员都在用"笨办法"亏钱
- Linux 终端快捷键,速记超简单
- 零代码升级 充电桩OCPP 1.6协议安全配置如何快速升级到Security Profile 2/3
- 某司发布“AI全栈强制令”:程序员代码产能要提升5倍才合格!网友:“'数字泰勒主义'这词扎心了……”
- 2/5/2026 AI新信息 | AI编程工具竞争加剧,开发者生态加速演变
- 写代码查裁员名单,这两名 Pinterest 工程师把自己也“查没了”
- 千问发布编程专用模型,微软OneDrive商业版独立订阅停售
