python入门基础知识! 新手必备
- 2026-07-04 02:08:13
python入门基础知识! 新手必备1)条件判断方法: in方法:判断内容是否存在字符串中 •表达式:a in b •判断a是否在b中,是则返回True,否则为False not方法:返回表达式结果的'相反值'。如果表达式结果为真,则返回False •表达式:a not in b •判断a是否不在b中,不在则返回True,否则为False is方法: 判断的是 内存地址是否相同 •表达式:a is b •判断a,b的内存地址是否相同,是则返回True,否则为False 2)取值方法: •可以通过下标进行取值 a[2] •切片a[2:3] •通过for循环取值 3)元素判断与操作的方法: 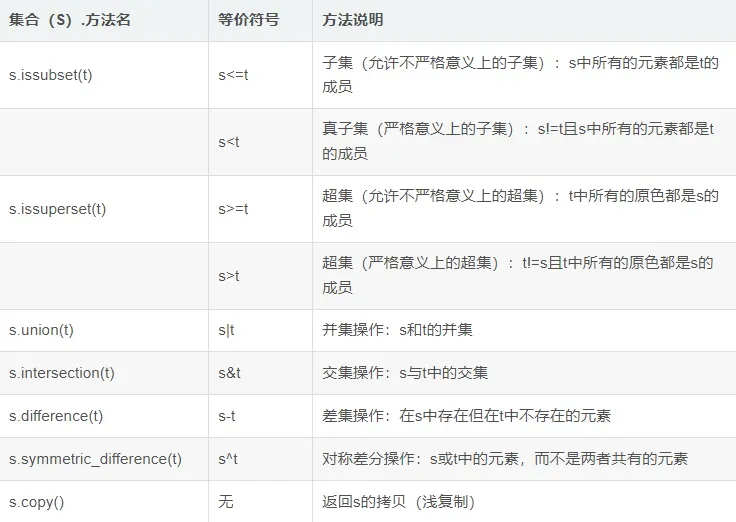
基本的类
python最基础、最常用的类主要有int整形,float浮点型,str字符串,list列表,dict字典,set集合,tuple元组等等。int整形、float浮点型一般用于给变量赋值,tuple元组属于不可变对象,对其操作一般也只有遍历。而str字符串,list列表,dict字典,set集合是python里面操作方法较为灵活且最为常用的,掌握这4中类型的操作方法后基本就可以灵活使用python中基本的大部分类型。
str字符串
a.endswith('d') #判断字符串a是否以d结尾,执行结果为布尔值a.starstwith('d')) #判断字符串a是否以d开头,执行结果为布尔值a.isalnum() #判断字符串a是否包含数字和字母,返回结果为布尔值a.isalpha() #判断字符串a是否都是英文字母,返回结果为布尔值a.isdigit() #判断字符串a是否都为数字,返回结果为布尔值a.isspace() #判断字符串a是否都为空格,返回结果为布尔值a.istitle() #判断字符串a是否首字母大写,返回结果为布尔值a.islower() #判断输入的字符串是否为小写字母,返回结果为布尔值a.isupper()#判断输入的字符串是否为大写字母a.lower() #将字符串中的大写字母变成小写a.upper() #将字符串中的小写字母变成大写a.swapcase() #大小写字母反转a.capitalize() #对字符串的首字母进行大写a.title()#对字符串中空格隔开的所有首字母进行大写
4)去除字符串指定元素方法
#(参数缺省时去除空格)(返回结果字符串)a.lstrip('m') #去掉字符串左边的元素a.rstrip('m') #去掉字符串右边的元素a.strip('m') #去掉两边的元素,中间的元素不可去除
5)join方法
#join是用来通过 某个字符串 拼接 一个可迭代对象的每个元素--->join(可迭代对象参数类型)'m'.join(str) #将字符串str中的每个元素都使用m连接,返回一个新字符串,原字符串str的内容未修改'm'.join(list) #将列表转换为字符串,每个元素之间使用m连接
6)替换方法
#replacest.replace('a', 'b',n) #将字符串st中的前n个元素a替换为b,n缺省时默认替换所有符合条件的元素a#映射,可以做密码加密使用:p = str.maketrans('abcdefg', '1234567') #前面的字符串和后面的字符串进行映射,a-->1,c-->3'ccaegg'.translate(p) #输出结果按照上面的maketrans做映射后的字符串,执行结果为:331577#tab转化为空格st.expandtabs(tabsize = 8) 把字符串st的tab转为空格,默认为8个
7)检索
a.find(b, 3, 10) #从前往后查找字符串a中b的第一个字符的索引,3,15 是查找范围开始、结束的下标值,缺省时查找整个字符串a.rfind(b,3,10) #从后往前查找字符串a[2])#按照索引查找第3个元素a.index(b)#从左往右按值查找索引a.rindex(b)#从右往左按值查找索引a.count(b))#统计b在字符串a中出现的次数
8)切割字符串
#spilt(返回结果类型为list)a.spilt(b)#按照b分割字符串,缺省时默认为空格a.splitlines() #按照换行符分割,是每一行的内容作为list的一个元素#partition()(返回结果类型为tuple)a.partition(b)#将字符串a以从左往右第一个b为中心分为三部分a.rpartition(b)#将字符串a以从右往左第一个b为中心分为三部分
9)随机字符库string
import stringstring.ascii_letters#输出所有的大小写字母string.digits #输出所有(0-9)的数字string.ascii_letters #输出大小写的英文字母string.ascii_lowercase #输出小写英文字母string.ascii_uppercase #输出小写英文字母
10)格式化字符串
#format(修饰符及说明符同c语言)"{name}huh{age}".format(name='byz', age=18)#格式化字符串显示"{name}huh{age}".format_map({'name': 'zhangsan', 'age': 18}) #格式化字典#占位符%(修饰符及说明符同c语言)"%d%f%s"%(2,3.14,"huh")#对齐a.center(n, b) #长度总共为n,将字符串a放在中间,两边补充b显示a.ljust(n, b) #长度总共为n,将字符串a放在左边,右边补充b显示a.rjust(n, b) #长度总共为n,将字符串a放在右边,左边补充b显示a.zfill(n) #长度总共为n,将字符串a放在右边,左边补充'0'显示
11)编码
str.decode(encodeing[,replace]) 编码strstr.encode(encodeing[,replace]) 解码str
list列表
1)增加
<list>.append(<obj>)追加到尾部<list>.insert(<index>,<obj>)在index处插入obj<list>.extend(<list>)合并列表到尾部
2)删除
del list[<index>]直接删除<list>.pop(<index>)删除并返回指定元素<list>.remove(<obj>)删除找到的第一个obj<list>.clear()清空列表
3)修改
<list>[<index>]=<obj>将index处的元素直接修改为<obj>4)检索
<list>.index(<obj>)返回从左开始匹配到的第⼀个<obj>的索引<list>.count(<obj>)返回<obj>的个数
5)排序
<list>.sort(key=<排序规则>,reverse=<boolen>)#对列表的一种操作sorted(<可迭代对象>,key=<排序规则>,reverse=<boolen>)#返回一个新的排序过的列表<list>.reverse()反转
6)复制
list.copy():返回list的浅拷贝dict字典
.clear() #清除字段里所有的元素.copy() #字典的浅复制.formkeys() #创建字典,以序列seq中的元素作为键,val为字典所有对应键的初始值.get(key,default=None) #设置不在字典中默认的值.key in dict #键是否在字典里,返回true或false.items() #以列表的方式遍历(键,值)元组数组.keys() #使用list()转换为列表.setdefault(key,default=None) #为不存在于字典中的键,添加或设置键为default.update() #把字典里的键和值更新到另一个字典里.values() #使用list()转换为列表.pop(key[.default]) #删除字典键的值,返回删除键的值.popitem() #随机删除字典中的一对键值(一般删除末尾的一对)
set集合
1)以下方法返回一个新的集合
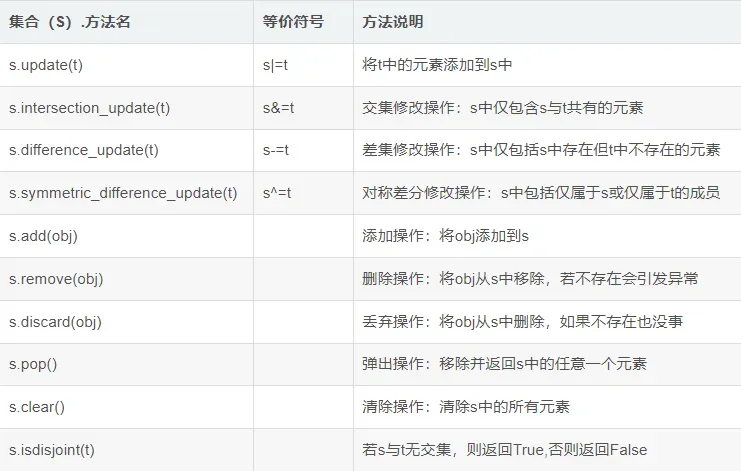
2)以下方法是对原来集合s的操作
内置方法
较多的内置方法也是python区别于其他编程语言的一个特点,熟练掌握这些内置方法的使用就已经可以实现python大部分的功能,灵活使用python的内置方法可以大幅度提高代码的速度以及减少代码量。
类型转换
bool(object):返回object对应的布尔值str(object, encoding=encoding, errors=errors):返回object对应的以encoding编码的字符串errors是转换失败时的操作int(value,base=10):将value强制转换为10进制int型若value为数字,则不可改变base的值;若为字符串,则base为value进制数float(value):将value转换为浮点数complex(real,imaginary):返回一个complex对象复数(real+imaginary j)第一个参数也可是表示复数的字符串,此时省略第二个参数list(iterable):创建一个iterable对应的列表tuple(iterable):返回一个新建的iterable的元组set(iterable):返回一个新建的iterable的set对象dict(key1=value1,key2=value2...):创建字典对象enumerate(iterable, start=0):将iterable转化为一个enumerate枚举对象start:开始枚举的编号enumerate对象是一个可迭代对象,每次迭代为(number,iterable[i])
对象及属性操作
object():返回一个空对象object不能向该对象添加新的属性或方法。该对象是所有类的基础,它拥有所有类默认的内置属性和方法。callable(object):如果指定的对象是可调用的,则返回True,否则返回False。isinstance(object,class):若object是class指定类型的,返回True,否则返回False若class是一个元组,如果对象是元组中的类型之一,则此函数将返回True。isinstance() 与 type() 区别:type() 不考虑类的继承关系。isinstance() 考虑类的继承关系。id(object):返回object的id值type():返回一个type对象用法1:type(object) :表示object的类型用法2:type(name, bases, dict) :产生一个新类型name:类型名bases:类型的基类元组dict:类内定义的命名空间变量len(object):返回object的项目数,当对象是字符串时,返回字符串中的字符数。memoryview(obj):从指定的对象返回一个内存视图对象。所谓内存视图对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。globals():以字典类型返回当前位置的全部全局变量locals():将本地局部变量作为字典返回。vars(object):返回object的__dic__属性若没有参数,相当于locals()dir(object):返回object的所有属性和方法(列表形式返回)delattr(object,attribute):删除object的attribute属性,相当于del object.attributegetattr(object, attr,[, default]):返回object的属性attr的值default:可选参数,如果attr不存在时返回的值hasattr(object, attribute):如果object有attribute属性,返回True,否则返回Falsesetattr(object,attribute,value):设置object的attribute属性值为valueissubclass(child, father):如果child是father的子类,则返回True,否则返回False。super():用法1:super() -> same assuper(__class__, <first argument>)用法2:super(type) -> unbound superobject用法3:super(type, obj) -> bound superobject; requires isinstance(obj, type)用法4:super(type, type2) -> bound super object; requires issubclass(type2, type)
数学操作
abs(x):返回x的绝对值区别:fabs()函数只适用于float和integer类型,而abs()也适用于复数。round(number,ndigits=None):返回将number四舍五入为小数位数为ndigits的数bin(n):返回整数n的二进制形式的字符串,前缀0bhex(number):返回number的十六进制形式的字符串,前缀0xoct(n):返回整数n的八进制形式的字符串,前缀0odivmod(x,y):返回x除以y的商和余数组成的元组(x//y,x%y)pow(base,exp,mod=None):返回base^exp%modmax(): (iterable,[, default=obj, key=func]):返回iterable中的最大值default为iterable为空时返回的对象(v1,v2...[, key=func]):返回v1,v2..中的最大值key为比较的依据,是func作用在各元素上时返回的值min():同max(),返回最小值sum(iterable,start=0):返回start加iterable内元素的总和
迭代器操作
all(iterable):如果iterable中的所有项目均为true,则all()函数返回True,否则返回False。如果可迭代对象为空,则all()函数也将返回True。any(iterable):如果iterable中的任何项目为true,则any()函数将返回True,否则返回False。如果可迭代对象为空,则any()函数将返回False。iter():返回一个迭代器:若参数只有一个(iterable),则返回对应的迭代器若参数为(callable,sentinel),则每次迭代时调用callable直到返回值为sentinelnext(iterator[, default]):返回迭代器iterator下一个要迭代的元素若迭代器结束,则返回defaultfrozenset(iterable):返回一个iterable转变为的不可更改的Frozenset对象filter(func,iterable):返回iterable中经func函数判断为真的部分组成的迭代器map(function,iterable,...):返回一个function作用于iterable中每个元素得到的新元素组成的map对象(可迭代对象)zip(iterables...):返回一个zip对象,它是一个元组的迭代器,其中每个传递的迭代器中的对应的元素配对为一个元组如果传递的迭代器具有不同的长度,则项目数最少的迭代器将确定新迭代器的长度。利用 * 号操作符,可以将元组解压为列表。range(start=0,stop[,step=1]):返回一个range对象(数字序列从start到stop,左开右闭,步长step)slice(start,end,step):返回一个切片对象。切片对象用于指定如何对序列进行切片。可以指定在哪里开始切片以及在哪里结束切片。还可以指定step。参数同range()reversed(sequence):返回sequence的反向迭代器sorted(iterable, key=None, reverse=False):返回iterable的以key排序的列表。reverse:是否反向
字符串操作
ascii(object):ascii()函数返回任何对象(字符串,元组,列表等)的可读版本。ascii()函数将用转义符替换所有非ascii字符:chu(x):返回Unicode代码为x的字符format(value, format_spec=''):返回按format_spec格式化后的字符串,同string.format()方法ord(c):返回字符c的unicode编码
字节操作
bytearray(x, encoding, error):返回一个bytearray对象,将对象转换为字节数组对象,或创建指定大小的空字节数组对象。x:创建bytearray对象时使用的源。如果它是一个整数,将创建一个指定大小的空bytearray对象。如果是字符串,需要encoding参数。encoding:字符串的编码error:指定编码失败时的处理方法。bytes(x, encoding, error):返回一个bytes对象。将对象转换为字节对象,或创建指定大小的空字节对象。参数同bytearraybytes()和bytearray()之间的区别在于,bytes()返回一个无法修改的对象,而bytearray()返回可以修改的对象。
编译输入输出
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1, *, _feature_version=-1)source:表示一个Python模块、语句或表达式的字符串filename:用于运行时的错误消息mode:编译模式flags:哪条未来的语句影响代码编译dont_inherit:如果为True,停止编译继承optimize=-1,_feature_version=-1eval(source, globals=None, locals=None,):执行source指定的python表达式source:字符串类型的python表达式或者经过compile()返回的对象(单个表达式)globals:包含全局参数的字典locals:包含局部变量的字典exec(source, globals=None, locals=None,):执行source指定的python代码(可以是大代码块)input(prompt):提示prompt后返回输入对应的字符串print(value,..., sep=' ', end='\n', file=sys.stdout,flush=False):value--表示输出的对象。输出多个对象时,需要用 , (逗号)分隔。sep -- 用来间隔多个对象。end-- 用来设定以什么结尾file-- 要写入的文件对象(具有write方法)flush--为 True时输出流会被强制刷新,为False则会被缓存。(print输出时会先缓存到缓冲区,最后输出)
文件操作
任何编程语言都需要对文件系统进行操作,且大部分的编程语言的文件操作方法大致相似,如果掌握了其中一种,其他编程语言的文件操作也可手到擒来。
打开文件
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)打开一个文件,并将其作为文件对象返回。file:文件地址mode:文件打开模式buffering:寄存行缓冲区的大小(整数),-1为默认大小encoding:打开文件时的编码格式newlines:若不设置,universal newlines mode工作(不同操作系统换行符不一样)
文件对象的属性
f.bufferf.closed:若f已经关闭,则返回True,否则返回Falsef.encoding:文件的编码格式f.errorsf.line_bufferingf.mode:文件打开模式f.name:文件名f.newlines:f.write_through
文件对象的操作
f.close():用于关闭一个已打开的文件。关闭后的文件不能再进行读写操作, 否则会触发 ValueError 错误。close() 方法允许调用多次。当 file 对象,被引用到操作另外一个文件时,Python 会自动关闭之前的 file 对象。使用 close() 方法关闭文件是一个好的习惯。在某些情况下,由于缓冲的原因,对文件所做的更改可能要等到关闭文件后才能显示。f.detach():将底层缓冲区与f分离并返回它。在分离基础缓冲区之后,f位于不可用状态。f.fileno():返回一个整型的文件描述符(file descriptor FD 整型),可用于底层操作系统的 I/O 操作。文件描述符:open()函数的file参数,除了可以接受字符串路径外,还可以接受文件描述符,文件描述符是个整数,对应程序已经打开的文件。标准输入使用文件描述符0,标准输入使用1,标准错误使用2,程序中打开的文件使用3、4、5...等数字。f.flush():用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。f.isatty():如果文件流是交互式的,则返回True.例如:连接到终端设备。f.read(size):从文件的指针位置开始返回指定的字节数。size:可选,要返回的字节数。默认值-1,表示整个文件。f.readable():如果文件可读,则返回True,否则返回False。f.readline(size):从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符size:可选的,从行返回的字节数。默认值-1,表示整行。f.readlines(sizehint):返回一个列表,其中包含文件中的每一行作为列表元素。sizehint:可选的,sizehint从文件中读取的字节数,如果返回的字节数超过sizehint,将不再返回任何行。默认值为-1,这意味着将返回所有行。f.reconfigure(encoding=None, errors=None, newline=None, line_buffering=None, write_through=None) :使用新参数重新配置文本流。这也会进行隐式的流刷新。f.seek(offset):设置文件流中的当前文件位置并返回该位置。如果操作成功,则返回新的文件位置,如果操作失败,则函数返回 -1。offset:必需的参数,代表需要移动偏移的字节数f.seekable():如果文件可查找,则返回True,否则返回False。如果文件允许访问文件流,则该文件是可查找的f.tell():返回文件流中的当前文件位置。f.truncate(size=None):将文件大小调整至给定的字节数。如果未指定大小,将使用当前位置。size:可选的,截断后文件的大小(以字节为单位)f.write(str):将指定的文本str写入文件。返回写入文本大小。指定文本将被插入的位置取决于文件模式和流位置.在文件关闭前或缓冲区刷新前,字符串内容存储在缓冲区中,这时你在文件中是看不到写入的内容的。如果文件打开模式带 b,那写入文件内容时,str (参数)要用 encode 方法转为 bytes 形式,否则报错f.writable():如果文件可写,返回True,否则返回False。f.writelines(list):将列表list的元素写入文件。文本插入的位置取决于文件模式和流位置。换行需要指定换行符 \n。
感谢阅读 Python新手安装包、等等更多Python资料
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

