1. 创始时间与作者
2. 官方资源
GitHub 地址:https://github.com/pandas-dev/pandas
PyPI 地址:https://pypi.org/project/pandas/
文档地址:https://pandas.pydata.org/docs/
官网地址:https://pandas.pydata.org/
3. 核心功能
4. 应用场景
1. 数据清洗与预处理
import pandas as pd# 读取数据df = pd.read_csv('sales_data.csv')# 数据清洗df_clean = (df .drop_duplicates() # 删除重复行 .dropna(subset=['customer_id', 'amount']) # 删除关键列缺失值 .assign(purchase_date = lambdax: pd.to_datetime(x['purchase_date']), # 日期转换category = lambdax: x['category'].fillna('Unknown'), # 填充缺失类别amount = lambdax: x['amount'].clip(0, 10000) # 处理异常值 ) .query('amount > 0') # 过滤无效交易)# 保存清洗后数据df_clean.to_csv('cleaned_sales_data.csv', index=False)2. 金融数据分析
import pandas as pdimport numpy as np# 创建模拟金融数据dates = pd.date_range('2023-01-01', periods=100)stocks = pd.DataFrame({'AAPL': np.random.normal(0.001, 0.02, 100).cumsum() +150,'GOOG': np.random.normal(0.0008, 0.018, 100).cumsum() +2800,'MSFT': np.random.normal(0.0009, 0.015, 100).cumsum() +300}, index=dates)# 计算技术指标stocks['AAPL_MA20'] = stocks['AAPL'].rolling(20).mean()stocks['GOOG_RSI'] = (stocks['GOOG'] .diff() .apply(lambdax: x if x>0 else 0) .rolling(14).sum() /stocks['GOOG'].diff().abs().rolling(14).sum() *100)# 相关性分析correlation = stocks[['AAPL', 'GOOG', 'MSFT']].corr()# 可视化import matplotlib.pyplot as pltstocks[['AAPL', 'AAPL_MA20']].plot(title='Apple Stock Price with 20-day MA')plt.show()3. 时间序列分析
import pandas as pd# 创建时间序列数据date_rng = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D')ts = pd.Series(np.random.randint(100, 1000, size=len(date_rng)),index=date_rng,name='sales')# 重采样为月度数据monthly_sales = ts.resample('M').sum()# 时间序列分解from statsmodels.tsa.seasonal import seasonal_decomposedecomposition = seasonal_decompose(monthly_sales, model='additive')# 季节性分析seasonal_avg = (monthly_sales .groupby(monthly_sales.index.month) .mean() .rename(lambdax: pd.Timestamp(2023, x, 1).strftime('%b')))# 预测(使用简单移动平均)forecast = monthly_sales.rolling(3).mean().iloc[-1]print(f"12月销售预测: ${forecast:,.2f}")4. 大数据处理优化
import pandas as pdimport dask.dataframe as dd# 处理大型CSV文件(内存优化)df = pd.read_csv('large_dataset.csv', usecols=['col1', 'col2', 'col5'], dtype={'col1': 'category'})# 使用Dask并行处理超大数据集ddf = dd.read_csv('very_large_*.csv', blocksize=256e6) # 256MB块大小result = (ddf[ddf['value'] >100] .groupby('category') ['sales'] .mean() .compute(num_workers=8) # 使用8个核心)# 使用Polars加速(替代实现)import polars as pldf_pl = pl.read_csv('large_dataset.csv')result = (df_pl .filter(pl.col('value') >100) .groupby('category') .agg(pl.col('sales').mean()) .collect())5. 底层逻辑与技术原理
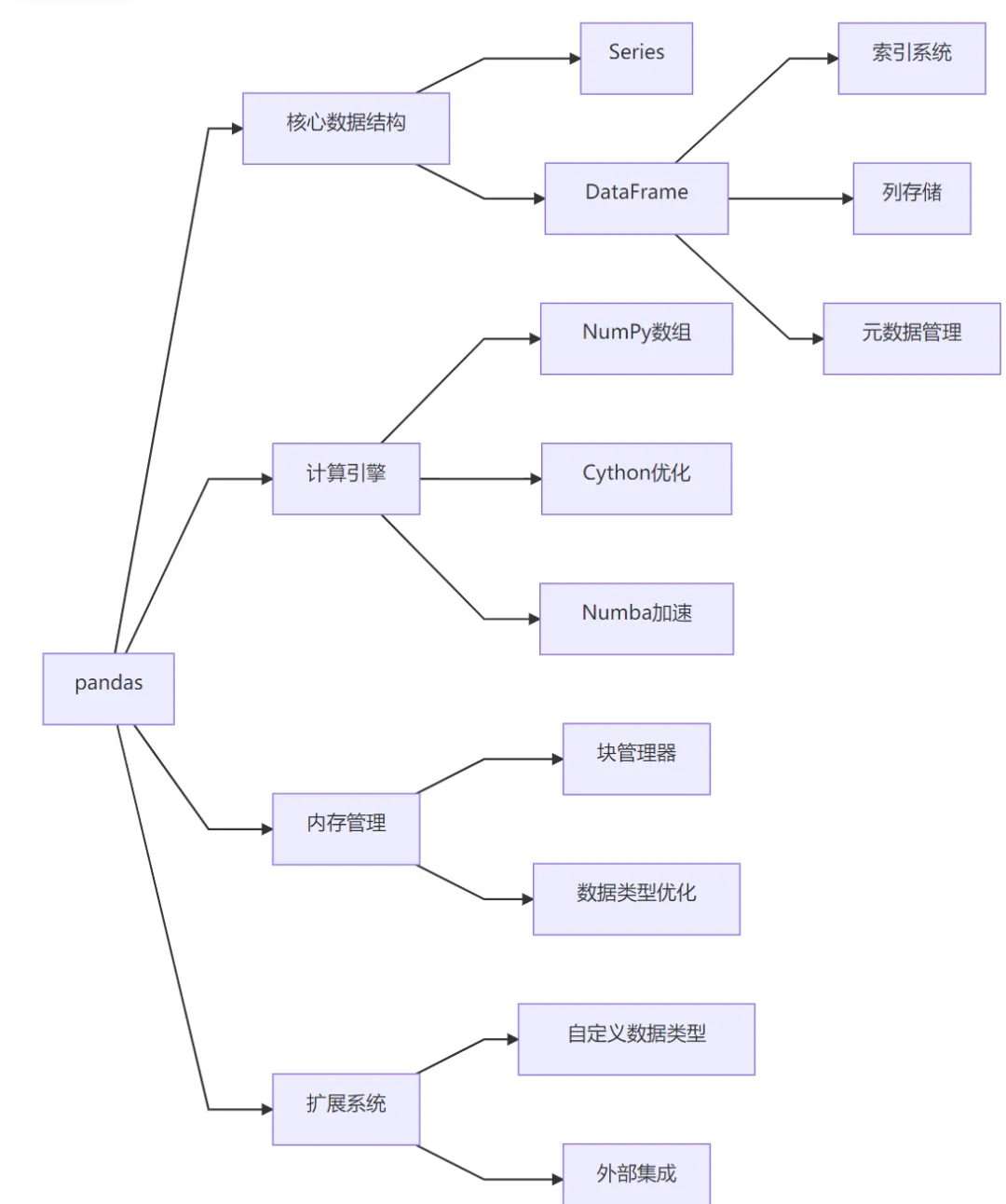
核心架构
关键技术实现
数据结构优化:
DataFrame:列式数据结构,类似内存中的数据库表
Series:带索引的一维数组,类似有标签的NumPy数组
索引系统:高效的基于标签的索引(MultiIndex支持多维索引)
内存管理:
性能优化:
Cython加速核心算法(分组、合并、聚合等)
向量化操作基于NumPy
查询优化器(eval()方法)
多线程支持(read_csv等I/O操作)
扩展系统:
自定义数据类型扩展
访问器(.str, .dt, .cat)
与PyArrow集成实现零拷贝数据交换
6. 安装与配置
基础安装
pip install pandas
完整安装(推荐)
pip install "pandas[performance, aws, excel, parquet]"
可选依赖
| 功能 | 依赖包 | 安装命令 |
|---|
| Excel支持 | openpyxl, xlsxwriter | pip install openpyxl xlsxwriter |
| 数据库连接 | SQLAlchemy | pip install SQLAlchemy |
| 并行处理 | Dask | pip install dask |
| 高性能替代 | PyArrow | pip install pyarrow |
| 内存优化 | fastparquet | pip install fastparquet |
环境要求
| 组件 | 最低要求 | 推荐配置 |
|---|
| Python | 3.8+ | 3.10+ |
| NumPy | 1.20.3+ | 1.24+ |
| 内存 | 1GB | 8GB+(大数据处理) |
| CPU | 双核 | 8核+ |
7. 核心组件详解
数据结构对比
| 结构 | 维度 | 主要用途 | 示例 |
|---|
| Series | 1维 | 单列数据,时间序列 | pd.Series([1,2,3], index=['a','b','c']) |
| DataFrame | 2维 | 表格数据,多列数据集 | pd.DataFrame({'col1': [1,2], 'col2': ['a','b']}) |
| Panel (已弃用) | 3维 | 三维数据集 | 被MultiIndex DataFrame替代 |
关键方法分类
| 类别 | 方法 | 描述 |
|---|
| 数据读取 | read_csv, read_excel | 从文件加载数据 |
| 数据查看 | head, tail, describe | 初步查看数据 |
| 数据选择 | loc, iloc, query | 行/列选择 |
| 数据清洗 | dropna, fillna, replace | 处理缺失值和异常值 |
| 数据转换 | assign, apply, map | 数据计算与转换 |
| 数据合并 | merge, join, concat | 组合多个数据集 |
| 分组聚合 | groupby, pivot_table | 数据分组与汇总 |
| 时间序列 | resample, shift, rolling | 时间相关操作 |
| 输入输出 | to_csv, to_sql, to_parquet | 数据导出 |
8. 高级用法
1. 自定义数据处理管道
import pandas as pdfrom sklearn.preprocessing import StandardScaler# 创建处理管道def data_pipeline(df):return (df .pipe(clean_data) .pipe(feature_engineering) .pipe(normalize_data) )def clean_data(df):return (df .drop_duplicates() .dropna(subset=['price']) .query('price > 0') )def feature_engineering(df):return df.assign(price_per_sqft = df['price'] /df['sqft'],age = pd.Timestamp.now().year-df['year_built'] )def normalize_data(df):scaler = StandardScaler()df[['price', 'sqft']] = scaler.fit_transform(df[['price', 'sqft']])return df# 使用管道df = pd.read_csv('real_estate.csv')processed_df = data_pipeline(df)2. 高性能数据操作
import pandas as pdimport numpy as np# 创建1000万行数据df = pd.DataFrame({'id': np.arange(10_000_000),'value': np.random.rand(10_000_000),'category': np.random.choice(['A','B','C','D'], 10_000_000)})# 高效分组聚合 (使用NumPy)result = (df.groupby('category') .agg({'value': ['sum', 'mean', lambdax: np.percentile(x, 95)] }))# 使用eval优化复杂计算df.eval('value_squared = value ** 2', inplace=True)# 并行处理from pandarallel import pandarallelpandarallel.initialize(progress_bar=True)df['processed'] = df.parallel_apply(lambda row: complex_operation(row), axis=1)3. 时间序列高级分析
import pandas as pdimport yfinance as yf# 获取股票数据data = yf.download('AAPL', start='2020-01-01', end='2023-12-31')# 技术指标计算data['MA20'] = data['Close'].rolling(20).mean()data['MA50'] = data['Close'].rolling(50).mean()data['Volatility'] = data['Close'].pct_change().rolling(30).std() *np.sqrt(252)# 事件驱动分析 (产品发布)events = pd.Series(index=pd.to_datetime(['2020-10-13', '2021-09-14', '2022-09-07']), data=1, name='event')event_study = (data['Close'] .pct_change() .rolling(5) .mean() .reset_index() .merge(events.reset_index(), on='Date', how='left') .fillna(0))# 时间序列预测 (Prophet)from prophet import Prophetmodel = Prophet(yearly_seasonality=True, daily_seasonality=False)prophet_df = data['Close'].reset_index().rename(columns={'Date':'ds', 'Close':'y'})model.fit(prophet_df)future = model.make_future_dataframe(periods=90)forecast = model.predict(future)4. 数据库集成
import pandas as pdfrom sqlalchemy import create_engine# 创建数据库连接engine = create_engine('postgresql://user:password@localhost:5432/mydb')# 读取SQL数据到DataFramequery = """ SELECT user_id, SUM(amount) AS total_spent FROM transactions WHERE transaction_date > '2023-01-01' GROUP BY user_id"""df = pd.read_sql(query, engine)# 处理数据df['spending_category'] = pd.cut(df['total_spent'],bins=[0, 100, 500, 1000, float('inf')],labels=['Low', 'Medium', 'High', 'VIP'])# 写回数据库df.to_sql('user_spending_categories', engine, if_exists='replace', index=False)# 使用DuckDB内存分析import duckdbresult = duckdb.query(""" SELECT spending_category, AVG(total_spent) FROM df GROUP BY spending_category""").to_df()9. 最佳实践
内存优化技巧
# 优化数据类型df = df.astype({'id': 'int32','price': 'float32','category': 'category'})# 分块处理大文件chunk_iter = pd.read_csv('huge.csv', chunksize=100000)for chunk in chunk_iter:process(chunk)性能优化技巧
# 使用向量化操作替代applydf['new_col'] = df['col1'] *0.2+df['col2'] *0.8# 使用query代替布尔索引result = df.query('col1 > 100 & col2 == "A"')# 使用eval优化复杂表达式df.eval('result = (col1 + col2) / col3', inplace=True)数据质量检查
# 数据质量报告def data_quality_report(df):return pd.concat([df.dtypes.rename('dtype'),df.isna().mean().rename('missing_pct'),df.nunique().rename('unique_values'), (df.min() if df.shape[0] >0 else pd.Series()).rename('min'), (df.max() if df.shape[0] >0 else pd.Series()).rename('max') ], axis=1)dq_report = data_quality_report(df)可视化集成
# 直接使用pandas绘图import matplotlib.pyplot as pltax = df.plot.scatter(x='age', y='income', c='price', colormap='viridis')plt.title('Age vs Income Colored by Price')plt.savefig('scatter.png')# 与Seaborn集成import seaborn as snssns.pairplot(df[['age', 'income', 'price']])plt.show()
10. 与同类工具对比
| 特性 | pandas | Polars | Vaex | Dask DataFrame |
|---|
| API易用性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 单机性能 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 内存效率 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 大数据支持 | ❌ | ✅ | ✅ | ✅ |
| 多线程支持 | ✅有限 | ✅ | ✅ | ✅ |
| GPU支持 | ❌ | ✅ | ❌ | ❌ |
| 成熟度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 生态系统 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
11. 行业应用案例
金融行业
风险管理分析
投资组合优化
高频交易数据处理
信用评分模型开发
电子商务
医疗健康
临床试验数据分析
疾病预测模型
医疗资源优化
患者分群分析
制造业
科研领域
总结
pandas 是 Python 数据科学生态系统的核心,核心价值在于:
数据操作效率:提供直观、高效的数据结构和操作方法
数据清洗能力:强大的缺失值、异常值和重复值处理工具
时间序列支持:专业级时间序列处理功能
生态系统集成:与NumPy、Matplotlib、Scikit-learn等无缝集成
技术演进:
关键特性:
适用场景:
数据清洗与预处理
探索性数据分析(EDA)
特征工程
时间序列分析
统计建模与机器学习数据准备
生成数据报告和可视化
安装使用:
pip install pandas
学习资源:
官方文档:https://pandas.pydata.org/docs/
书籍:《Python for Data Analysis》(作者:Wes McKinney)
教程:https://pandas.pydata.org/pandas-docs/stable/getting_started/intro_tutorials
社区:https://stackoverflow.com/questions/tagged/pandas
截至2023年,pandas在PyPI的月下载量超过 1亿次,是Python数据科学领域使用最广泛的库。项目遵循 BSD 3-Clause 开源协议,已成为数据分析和科学计算的事实标准。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
