文/华哥聊数据 | 十年磨一剑的大数据老兵,个人微信ID:bba80108
开篇:当你的数据库开始“理解”业务
想象一下:
- 你输入一句自然语言:“上个月北京地区 GMV 最高的商品类目是什么?”
- 系统自动调用大模型生成 SQL,在毫秒级返回结果;
- 或者你搜“懂 Java 的后端工程师”,系统不仅匹配关键词,还能理解语义,并结合简历 Embedding 向量做智能召回;
- 更神奇的是,它还能画出“技术栈依赖图”,告诉你这位候选人用过哪些框架……
这不是未来——这是字节跳动刚刚落地的现实。
2024 年末,字节启动 DataMind 项目,目标是打造一个 “AI + Data”深度融合的一站式引擎。当时,市面上没有现成产品能满足需求,于是他们选择与 Apache Doris 开源社区深度共建。经过一年打磨,相关能力已作为核心特性,集成进 2025 年 11 月正式发布的 Apache Doris 4.0.1。
今天,我们就用通俗易懂的方式,拆解这个“会思考”的数据引擎是怎么炼成的。
本文所有功能均来自 Apache Doris 4.0.1 官方发布,非概念演示。
一、为什么传统数据平台搞不定 AI?
在 AI 大模型爆发前,数据平台只需“存得下、查得快”。但 AI 应用带来了三大新挑战:
| | |
| | 需要原生支持 Embedding、JSON、Array |
| 特征存在 Redis/HBase,模型在 PyTorch | |
| | |
于是,企业被迫搭建“烟囱式架构”:Flink 算特征 -> HBase 存特征 -> Milvus 做向量检索 -> 自研服务做 Rerank -> ClickHouse 做报表……系统复杂、数据不一致、延迟高、成本贵。
字节的答案很干脆:能不能只用一个引擎,搞定所有事?
二、DataMind 核心三板斧(现已集成至 Doris 4.0.1)
字节没有重复造轮子,而是与 Doris 社区合作,在 即将发布的 4.0.1 版本中 原生集成 AI 能力。核心就三块:
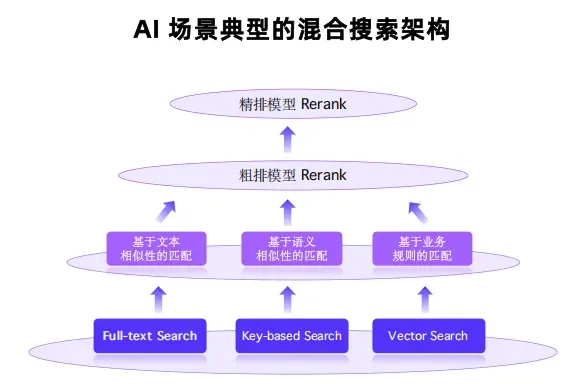
1. Hybrid Search:三路融合的智能搜索
不是简单的“关键词 or 向量”,而是 文本 + 语义 + 业务规则 三合一。
举个例子:你在招聘系统搜 “有 Spark 经验的算法工程师,base 杭州”。
- 业务规则:city = '杭州' -> 用倒排索引快速过滤;
- 文本相似:MATCH(content, 'Spark') -> 用 BM25 打分;
- 语义相似:将 Query 转为向量,与简历 Embedding 计算余弦相似度。
三路结果合并,再用精排模型打分,返回最匹配简历。
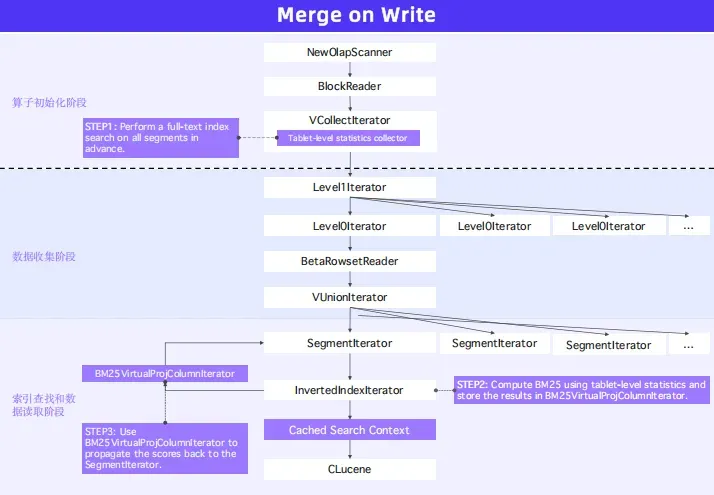
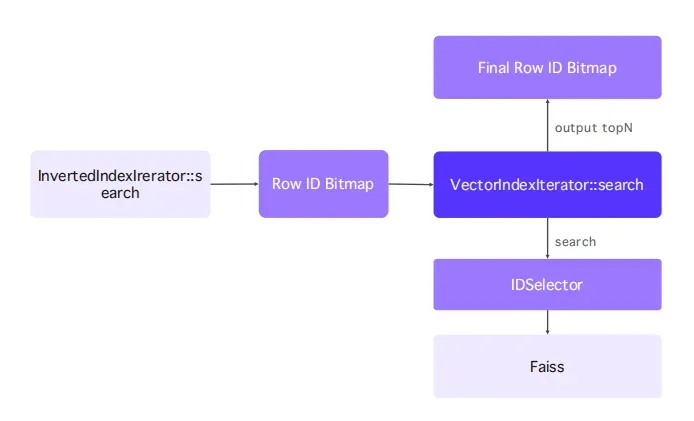
Doris 4.0.1 关键突破:
- Tablet-Level BM25:解决得分漂移问题(合并 Segment 后分数不变);
- Faiss 向量索引集成:支持 HNSW/IVF_PQ,并能与倒排索引协同;
- 虚拟列下推:让 BM25() 和 COSINE_SIMILARITY() 在存储层计算,性能提升 5 倍+。
通俗理解:就像某宝搜索,既看你说的词,也看你真正想要什么。
2. AI Function:SQL 直接调大模型
Doris 4.0.1 新增两个“魔法函数”:
AI_QUERY(model, prompt)
把非结构化文本变成结构化数据。
TEXT_EMBEDDING(model, text)
动态生成文本向量,无需应用层预计算。
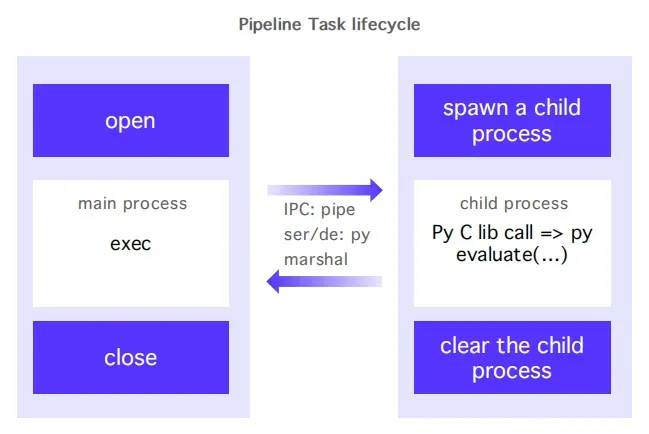
更狠的是 Python UDF(Doris 4.0.1 首次支持):
你可以把自研的 Rerank 模型打包成 .zip,注册为函数,直接在 SQL 里调用!
通俗理解:以前调大模型要写脚本 + API 调用;现在,一条 SQL 全搞定。
3. GraphRAG:从“检索”到“推理”
标准 RAG 只能回答“文档里有没有”,但 GraphRAG 能回答“为什么”和“怎么样”。
怎么做到的?
- 构建知识图谱:用 AI_QUERY 从文档中抽实体(如“Doris”、“物化视图”);
- 聚类 + 生成报告:用 Leiden 算法聚类,再用 LLM 生成摘要;
- 多跳查询:用户问“Doris 如何优化查询?”,系统会联想相关技术点,拼接上下文,生成结构化答案。
通过 Doris 的 AI Function 和 Python UDF,可在 SQL 中编排 GraphRAG 全流程,无需额外部署图数据库。为降低门槛,字节还提供了 Python/Go SDK,一行代码就能构建 GraphRAG:
通俗理解:不再是“关键词匹配”,而是像人类一样联想、推理、总结。
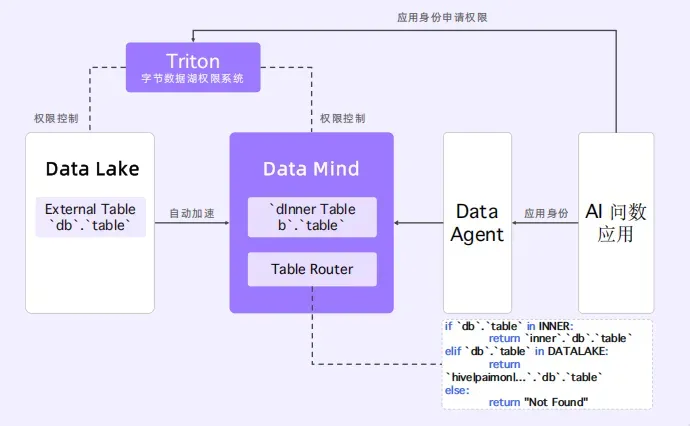
三、企业落地:AI 问数如何安全又高效?
很多公司想做“AI 问数”,但卡在两个问题:
- 数据分散
- 权限失控:数据同步到 Doris 后,DBA 能直接看敏感数据。
字节的解法很巧妙(已集成至 Doris 4.0.1 生态):
无感加速 + 权限穿透
- 用在写 SQL 时,只需用湖上表名(如 hive.db.sales);
- 权限仍由数据湖系统控制,即使 DBA 有 Doris 密码,没申请权限也看不到数据。
这样,AI 只需理解一套 Schema,安全也不打折。
附:添加华哥聊数据个人微信,备注:Doris领取资料↓四、避坑指南:字节踩过的雷,你别再踩
坑 1:向量维度太大,BE 内存爆了
- 现象:768 维 Embedding 存 ARRAY,单行超 3KB。
- 解法:
- 或开启 Doris 4.0.1 的 large_column_compression。
坑 2:Python UDF 卡死(GIL 问题)
- 解法:
- Doris 4.0.1 默认采用多进程架构,绕过 GIL;
坑 3:BM25 分数每天变
- 原因
- 解法:必须用 Tablet-Level BM25(Doris 4.0.1 首发支持)。
五、效果:效率翻倍,成本减半
字节内部某推荐业务落地后:
典型场景包括:
- 智能简历搜索
- CapCut 内容治理
- PRD2Code
结语:未来的数据库,会自己“思考”
DataMind 的实践证明:AI 时代的数据库,不再是被动的“仓库”,而是主动的“智能体”。
而 Apache Doris 4.0.1(2025 年 11 月发布),正是这一变革的里程碑。它由字节跳动与开源社区共同打造,将 Hybrid Search、AI Function、GraphRAG 等能力原生集成,让 OLAP 引擎真正成为 AI Native 应用的统一底座。
最后送大家一句话:未来不属于“只会存数据”的数据库,而属于“能理解、会推理、可生成”的智能引擎。
如果你觉得这篇文章有启发,欢迎点赞 + 在看 + 转发,让更多数据同行看到!更重要的是——点个关注【华哥聊数据】,追更不迷路!我们不止讲概念,更输出可落地的解决方案。下期见








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
