Claude Code的运作机制:Linux工具调用 vs RAG
- 2026-07-04 20:07:34


为什么 Claude Code 使用终端工具(grep, glob, find)进行代码发现,而不是使用目前主导生态系统的嵌入(Embeddings)/向量搜索(RAG) 方案?
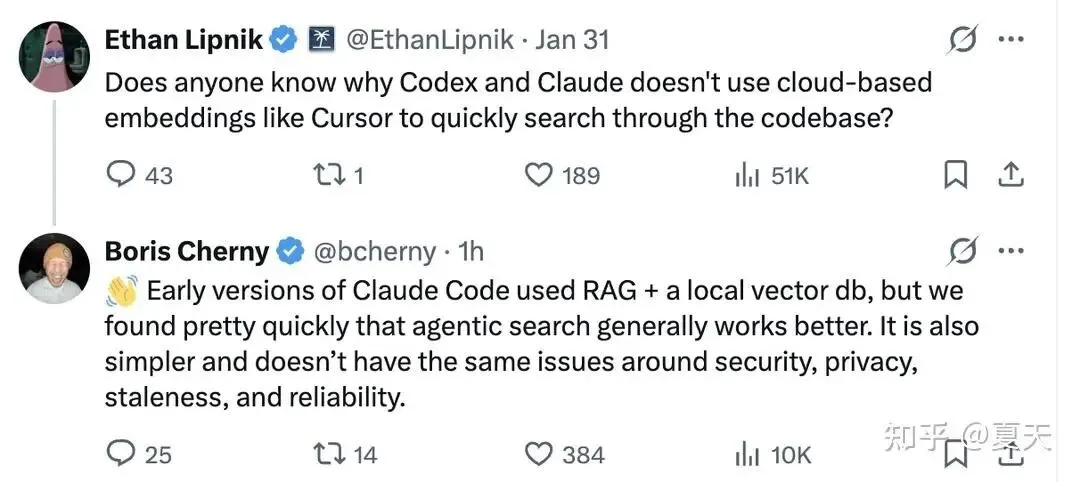
来自 Anthropic 的简短回答(Boris, Latent Space 播客, 2025年5月):
“We tried very early versions of Claude that actually used RAG… Eventually, we landed on just agentic search as the way to do stuff. And there were two big reasons…One is it outperformed everything. By a lot.And this was surprising.”

Anthropic 给出的理由(源自官方渠道)
1. 性能表现(“大幅超越一切”)
根据 Boris 的说法,当被问及基准测试时:
“这主要靠‘感觉(Vibes)’,也就是内部的直观感受。虽然有一些内部基准测试,但主要还是感觉它更好用。”
如果我们接受这个说法,这意味着在编程及相关任务中,工具调用比 RAG 更有效。但我对某些细分场景(如超大规模代码库、跨多个代码库协作等)仍持保留意见。
一个显而易见的事实是:消耗和生成更多 Token 的方法通常表现更好,这恰好也符合 LLM 供应商的商业模式。Token 越多,模型的表达和处理能力就越强。如果 Token 增加的同时准确率也提升了,对他们来说是双赢。这可能意味着 Anthropic 在训练中使用了高质量的工具使用数据,特别是在编程领域。
这也意味着 Claude Code 的架构可能非常简洁。它并没有构建复杂的编排逻辑或检索管道,而是依靠模型本身来“驱动”决策。其核心可能就是一个简单的 While 循环:
while(tool_call_remaining):execute_tool_call();pass_results_to_model();check_tool_call();当然,复杂之处不在于循环,而是在每次调用前的上下文组装(注入项目规则、技能 Schema 等)以及调用后的状态管理(压缩、会话持久化等)。现在的流行说法叫“上下文工程”。Anthropic 的赌注很明确:投资于模型的驱动能力,而不是构建一个复杂的“驱动程序”。
2. 简洁性与零基础设施
每一个 RAG 系统都始于一种“不信任”:即认为模型无法靠自己找到东西。
索引税(The Indexing Tax):
RAG 系统必须支付这笔费用:数据过期、偏移、安全风险和维护成本。
- RAG 的基础设施负担:
索引维护、嵌入服务依赖、向量数据库操作。 - Claude Code 的方案:
无服务器、无索引、仅靠 CLI,在任何代码库上即开即用。
3. 安全角度
索引必须存储在某个地方。如果第三方提供商被黑,对公司来说是巨大的责任风险。智能体搜索让大部分代码库保持在本地。RAG 需要存储整个代码库的表示,而工具调用则是“按需”决定搜索和探索哪些文件。
4. 符合“苦涩的教训(Bitter Lesson)”哲学
“一切皆模型。模型才是最终获胜的关键。随着模型变强,它会吞噬掉其他所有组件。”
Token 堆积问题
每一轮对话,上下文都会激增:
第1轮:~1,000 tokens 第2轮:~2,500 tokens ... 第5轮:~12,000 tokens
这种“浪费”源于智能体在探索时的不确定性(列出目录、猜测性打开文件、模糊搜索等)。
为什么“自回归 + 工具调用”在 Token 成本高昂的情况下依然有效?
核心在于:每一轮交互都为模型提供了更好的决策信息。
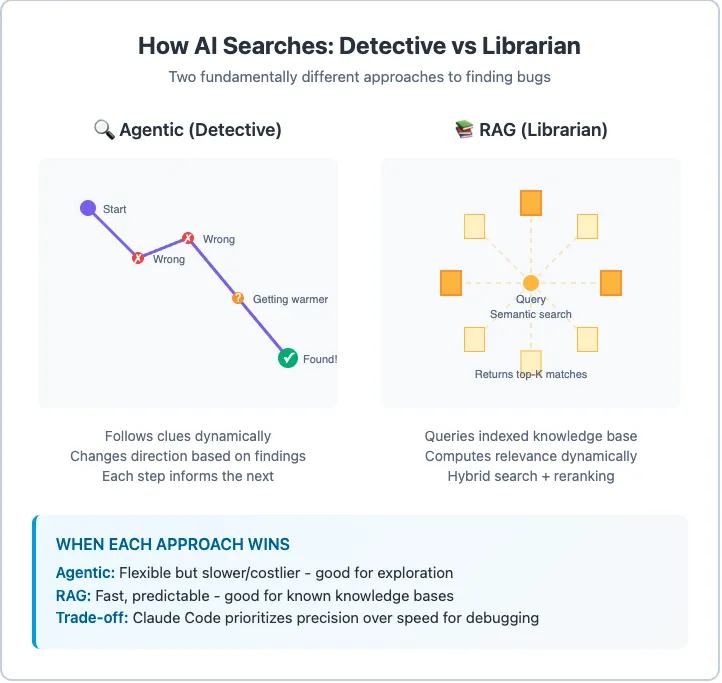
- RAG (单次):
查询 → 检索 → 完成(祈祷它是对的)。 - 智能体搜索 (迭代):
查询 → 结果 → “嗯,不太对” → 优化查询 → 更好的结果 → “接近了”……
模型可以根据发现的内容进行纠偏、缩小范围、追踪引用。这种动态适应是单次检索无法实现的。
权衡分析矩阵
倾向于智能体搜索的理由?
- 组合性(Unix 哲学):
可以轻松与其他命令行工具组合,如 tail -f app.log | claude -p "分析异常"。 - 无状态性:
每一轮搜索都是针对当下的现实,没有过期的索引。 - 模型即智能:
RAG 把智能外包给了检索系统(切片策略、重排序),而智能体搜索让智能留在模型内部。 - 可调试性:
你能看到模型具体执行了哪个 grep命令,而不是看到一堆莫名其妙的向量片段。
大胆猜一下:Claude Code 会改变路线吗?
大概率不会。 因为它符合 Anthropic 的哲学,减少了基础设施负担,且随着模型能力的提升,这种方案会自动变得更强。
未来的优化方向可能是:
更智能的搜索工具(解决 grep的版本差异)。更好的上下文管理(压缩)。 - 混合方案:
轻量化的本地索引(如 SQLite FTS5)+ 模型驱动的查询优化。
总结
Claude Code 选择智能体搜索而非 RAG,是一种哲学上的承诺:
简洁 胜过 基础设施 模型智能 胜过 检索工程 新鲜度 胜过 优化 安全 胜过 便利
对于大多数开发工作流,尤其是探索和开发阶段,智能体搜索表现出色。随着模型越来越聪明,这种方法的优势将愈发明显。
一对一的体系化学习路线规划制定。都是本人亲自辅导。目前本人在阿里巴巴集团工作,长期担任校招面试官,可以从面试官的角度帮大家提升。
真实场景的模拟面试。
项目定制、亮点和深度挖掘。
简历修改和包装。


我是夏天,阿里巴巴Java技术专家一枚。
以后这里就是我们交流、成长的基地啦,希望能帮助大家学习CS少走弯路。
先立个flag:我希望这是一个对计算机专业大学生真正有用的公众号,能高质量的陪伴你走完大学四年。
编程学习路上踩过的坑、好的学习资料我都会在这里分享给大家~
大家也可以扫码加我个人微信,交个朋友,欢迎围观朋友圈!


戳“阅读原文”领82本计算机高分经典书籍

