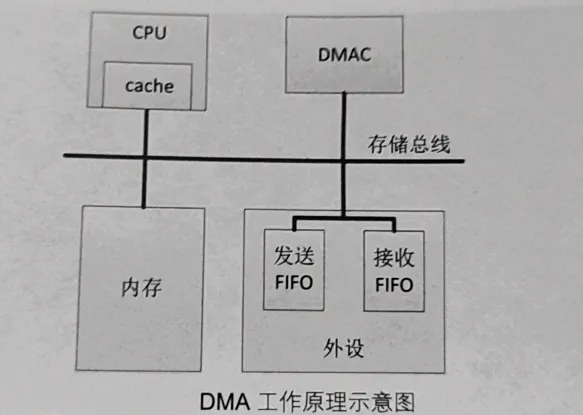
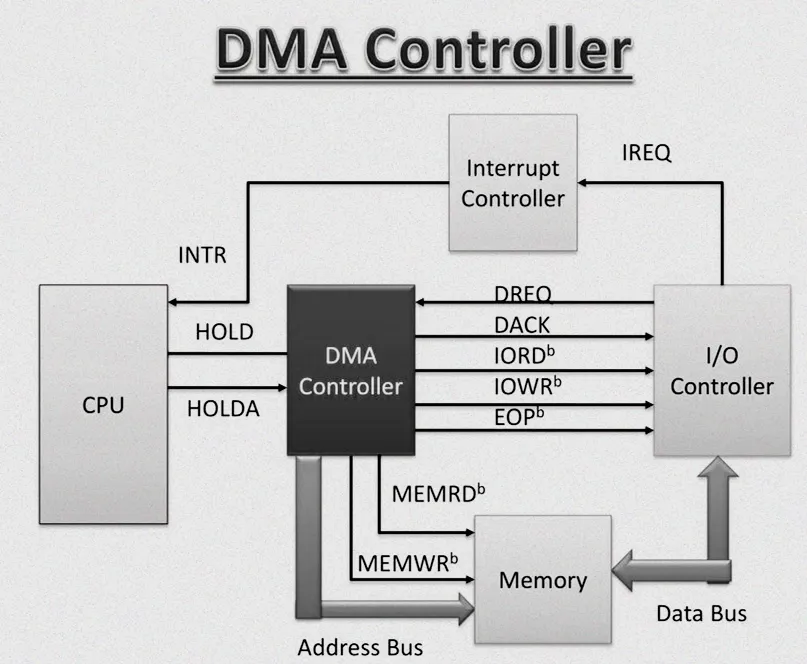
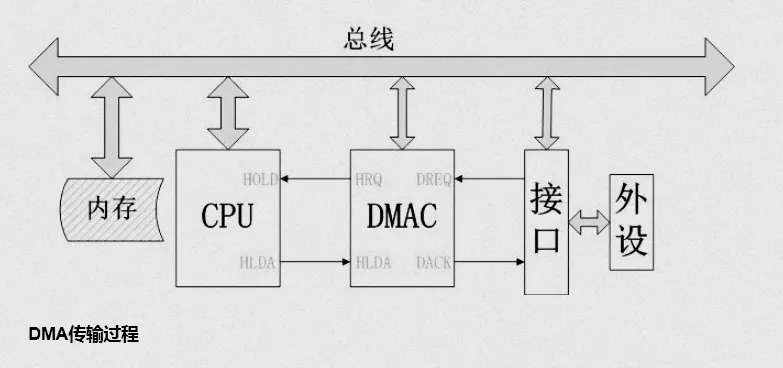
在计算机的世界里,数据传输就像是一场繁忙的物资搬运工作。在早期,CPU 就如同一位勤劳的 “搬砖工”,亲力亲为地参与每一次数据的搬运。当外设(如网卡、磁盘等)需要与内存进行数据交换时,CPU 需要一条指令接着一条指令地将数据从内存读取到寄存器,再从寄存器写入到外设,反之亦然。这种传统的编程 I/O(PIO)方式,虽然能够完成数据传输任务,但效率极其低下。想象一下,CPU 本应专注于运行复杂的算法、处理系统调度等高价值任务,却不得不花费大量时间在重复性的数据搬运上,就如同让一位高级工程师天天去做体力搬运工作,实在是大材小用。而 DMA 技术的出现,就像是为数据传输配备了一位 “专属快递员”。DMA,即 Direct Memory Access(直接内存访问),它允许外部设备绕过 CPU,直接与内存进行高速数据交换。当有数据传输需求时,CPU 只需向 DMA 控制器下达 “任务清单”,包括源地址、目标地址、传输数据量以及传输方向等参数,然后 DMA 控制器就会接管系统总线,独立完成数据的搬运工作。在这个过程中,CPU 可以去执行其他更重要的任务,大大提高了系统的整体效率。
以网卡为例,当我们的计算机通过网络接收数据时,千兆甚至万兆网络接口卡每秒要处理大量的数据包。如果没有 DMA,CPU 需要频繁地响应网卡中断,逐个读取数据包并写入内存,这将导致 CPU 负载急剧升高,系统性能大幅下降。而借助 DMA,网卡可以直接将接收到的数据包写入内核缓冲区,CPU 只需在传输完成后进行一些简单的处理,极大地减轻了 CPU 的负担,提高了网络通信的速度。
再看磁盘 I/O,磁盘控制器使用 DMA 来读写文件系统缓存。当我们从硬盘读取一个大文件时,DMA 可以直接在硬盘和内存之间传输数据,避免了 CPU 介入每个数据块的传输过程,使得文件读取速度大幅提升。同样,在图形处理领域,现代显卡通过 DMA 传输显存数据,能够快速地将渲染所需的数据从内存传输到显卡,从而实现流畅的图形显示和高效的视频编辑等操作。
可以说,DMA 技术是 Linux 高性能 I/O 的 “隐形功臣”,它在幕后默默地提升着系统的性能,使得各种高性能的应用场景成为可能。在接下来的内容中,我们将深入探讨 Linux DMA 技术的原理、实现机制以及在实际开发中的应用。
一、Linux DMA 的底层逻辑
1.1 DMA 的核心使命
Linux DMA 子系统肩负着一项核心使命,那就是在 CPU 可见的虚拟 / 物理地址与设备可见的总线地址(DMA 地址)之间,构建起一座稳固且高效的桥梁。这看似简单的任务,实则面临着诸多复杂而棘手的技术挑战,其中最为关键的有以下三大难题。
首先是地址转换难题。不同设备的寻址能力千差万别,它们通常只能访问有限的物理地址范围,这个范围由设备的 dma_mask 所定义。而内核在分配内存时,可能会将内存分配到高地址区域,这就导致设备无法直接访问这些内存。DMA 子系统必须精准地判断设备的寻址能力,通过巧妙的地址转换机制,确保提供给设备的地址在其可访问的范围之内。例如,在一些 32 位设备中,dma_mask 可能只能覆盖较低的 4GB 地址空间,如果内核分配的内存位于 4GB 以上的高地址区域,DMA 子系统就需要采取特殊的转换方式,让设备能够 “看到” 并访问这些内存 。
缓存一致性问题也不容小觑。在现代计算机系统中,CPU 为了提高数据访问速度,普遍配备了多级高速缓存。当 CPU 访问内存时,首先会在缓存中查找数据,如果缓存中存在(即缓存命中),就直接从缓存中读取或写入数据;只有在缓存未命中时,才会访问主存。而 DMA 传输是直接访问物理内存,这就可能导致一个问题:如果 CPU 修改了缓存中的数据,但尚未将这些数据写回到主存,此时设备通过 DMA 访问主存,读取到的就是旧数据,从而引发数据不一致的错误。为了解决这个问题,DMA 子系统必须提供有效的缓存一致性机制,确保 CPU 缓存和主存之间的数据同步。
内存连续性问题同样困扰着 DMA 的实现。一些老式设备或者对内存访问有特殊要求的设备,要求 DMA 缓冲区在物理内存上必须是连续的。然而,内核的页分配器(如伙伴系统)在系统运行一段时间后,由于内存的频繁分配和释放,会产生内存碎片,很难再分配出大块连续的物理内存。这就需要 DMA 子系统寻找其他解决方案,以满足设备对连续内存的需求。
1.2 四类 DMA 内存类型
为了应对上述复杂多样的挑战,满足不同设备和应用场景的需求,Linux 内核精心设计了四类 DMA 内存类型,每一种类型都犹如一把独特的 “钥匙”,精准适配特定的场景。
1.2.1 一致性 DMA 内存(Coherent DMA Memory)
一致性 DMA 内存就像是 CPU 和设备之间的 “实时共享空间”。它的工作原理基于非缓存(uncached)或写通(write - combining)模式。在这种模式下,无论是 CPU 对内存的写入,还是设备对内存的写入,都会立即对另一方可见,就好像两者直接共享了同一份数据,无需任何额外的同步操作,硬件自动保证了数据的一致性。
在代码实现上,我们可以通过 dma_alloc_coherent () 函数来分配一致性 DMA 内存,使用 dma_free_coherent () 函数进行释放。例如:
#include<linux/dma-mapping.h>#include<linux/device.h>staticintmy_probe(struct device *dev){ dma_addr_t dma_handle; size_t size = 1024; void *cpu_addr; // 分配DMA缓冲区 cpu_addr = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL); if (!cpu_addr) { dev_err(dev, "DMA alloc failed\n"); return -ENOMEM; } // 使用CPU地址和DMA地址 dev_info(dev, "CPU addr: %p, DMA addr: %pad\n", cpu_addr, &dma_handle); // 释放DMA缓冲区 dma_free_coherent(dev, size, cpu_addr, dma_handle); return 0;}
这种内存类型适用于一些小块数据且频繁交互的场景,比如设备的控制结构体、描述符环等。这些数据需要在 CPU 和设备之间频繁传递,并且对数据的一致性要求极高,一致性 DMA 内存能够很好地满足这些需求。不过,由于其非缓存的特性,数据访问速度相对较慢,这也是在使用时需要权衡的地方。
1.2.2 流式 DMA(Streaming DMA)
流式 DMA 是 Linux 系统中最为常用的 DMA 类型,它就像是一条高效的数据传输 “流水线”。内核为其分配的是普通的、可缓存的内存,这意味着它可以充分利用 CPU 缓存的优势,对于大块数据的传输性能表现尤为出色。
在进行 DMA 传输前和传输后,驱动程序需要扮演一个 “协调者” 的角色,显式地调用同步函数。在传输前,调用 dma_sync_single_for_device () 函数,通知 CPU 将缓存中的数据写回主存并失效缓存,确保设备读取到的是最新的数据;传输完成后,调用 dma_sync_single_for_cpu () 函数,通知 CPU 预取设备写入主存的数据到缓存,保证 CPU 后续访问的数据是最新的。通过这种方式,有效地解决了缓存一致性问题。
在 API 使用上,我们通过 dma_map_single () 函数来创建流式 DMA 映射,返回设备可访问的 DMA 地址;使用 dma_unmap_single () 函数来销毁映射。结合同步函数,其典型的使用方式如下:
dma_addr_t dma_handle;dma_handle = dma_map_single(dev, buf, size, direction);if (dma_mapping_error(dev, dma_handle)) { // 错误处理}// 调用同步函数,准备设备访问dma_sync_single_for_device(dev, dma_handle, size, direction);// 使用dma_handle进行DMA传输// 传输完成后,调用同步函数,准备CPU访问dma_sync_single_for_cpu(dev, dma_handle, size, direction);dma_unmap_single(dev, dma_handle, size, direction);
流式 DMA 适用于许多场景,比如文件系统的读写操作、网络数据包的收发等。在这些场景中,往往需要传输大量的数据,流式 DMA 利用 CPU 缓存的特性,能够显著提高数据传输的效率。
1.2.3 直接映射(Direct Mapping)
直接映射堪称 DMA 操作的 “黄金路径”,一旦条件满足,它就能实现数据的高速、零拷贝传输。当设备的 dma_mask 足够大,能够覆盖整个物理内存时,物理地址(PA)就可以直接作为 DMA 地址(DA)使用,无需进行任何复杂的地址转换。这就好比在内存和设备之间建立了一条 “直达通道”,数据可以直接在两者之间快速传输,实现了真正意义上的零拷贝,大大提高了数据传输的性能。
要实现直接映射,设备必须具备足够宽的地址总线,通常是 64 位,这样才能支持对整个物理内存的寻址。或者,系统通过 I/O 内存管理单元(IOMMU)提供了平坦的 I/O 虚拟地址(IOVA)空间,同样可以满足直接映射的条件。在 Linux 内核中,直接映射的逻辑主要由 direct.c 模块负责处理。这种方式虽然性能极高,但对设备和系统的硬件条件要求也较为苛刻。
1.2.4 SWIOTLB:硬件 IOMMU 缺失时的 “后备方案”
当设备的 dma_mask 较小,例如只能访问低 32 位地址,而内核分配的内存却位于高地址时,直接映射就无法实现了。此时,SWIOTLB(Software I/O TLB)就像一位 “救火队员”,作为软件层面的 “bounce buffer”(弹跳缓冲区)机制介入。
SWIOTLB 会预先在低地址空间分配一块内存池,当需要映射高地址内存时,它会先将数据从高地址拷贝到低地址的 bounce buffer 中,然后将 bounce buffer 的地址交给设备进行访问。传输完成后,再根据数据传输的方向,将数据从 bounce buffer 拷贝回高地址内存。虽然这种方式解决了设备无法访问高地址内存的问题,但不可避免地带来了额外的数据拷贝开销,导致性能显著下降。因此,在实际应用中,应尽量避免使用 SWIOTLB,只有在硬件 IOMMU 不可用的情况下,才将其作为一种兼容性保障的后备方案。
1.3 核心数据结构:支撑 DMA 子系统的 “骨架”
在 Linux DMA 子系统中,有两个核心数据结构起着至关重要的作用,它们就像是支撑整个系统的 “骨架”,确保了 DMA 功能的高效实现。
1.3.1 struct device:设备 DMA 能力的 “信息库”
struct device 是 Linux 设备模型的核心结构,它就像是一个设备的 “信息宝库”,其中包含了丰富的 DMA 相关信息。在这个结构体中,dma_ops 字段是一个指向 dma_map_ops 结构的指针,它就像是一把 “钥匙”,决定了该设备使用哪种 DMA 实现方式,比如是直接映射、IOMMU 还是 SWIOTLB 等。dma_mask 和 coherent_dma_mask 字段则定义了设备能够寻址的最大物理地址,这对于 DMA 子系统在进行地址转换和内存分配时,判断设备的寻址能力至关重要。
cma_area 字段指向为该设备预留的连续内存分配器(CMA)区域,CMA 区域主要用于为设备提供大块连续的物理内存,满足一些对内存连续性有要求的设备需求。dma_io_tlb_mem 字段则指向 SWIOTLB 内存池,当设备需要使用 SWIOTLB 机制时,该字段就会发挥作用。总之,struct device 结构体承载了设备与 DMA 子系统交互的关键信息,是驱动程序与 DMA 子系统沟通的重要桥梁。
1.3.2 struct dma_map_ops:实现 DMA 多态性的 “函数指针表”
struct dma_map_ops 是 DMA 子系统实现多态性的关键所在,它就像是一个 “函数指针表”,定义了一系列标准的 DMA 操作接口,如 alloc、free、map_page、unmap_page、sync_single_for_cpu 等。不同的底层实现,比如 direct.c、swiotlb.c 或者 IOMMU 驱动,会根据自身的特点填充这个结构体,提供各自的实现方式。
上层驱动程序在进行 DMA 操作时,并不需要关心具体的硬件实现细节,只需要通过 dev->dma_ops 间接调用这些接口即可。这种设计模式实现了驱动程序与具体硬件的解耦,使得驱动开发者可以更加专注于功能的实现,而无需花费大量精力去了解底层硬件的差异,大大提高了代码的可移植性和可维护性。
1.4 Linux DMA 子系统目录结构:模块化设计一览
Linux 内核的 DMA 子系统采用了模块化的设计理念,其代码结构清晰,分工明确。在 Linux 6.6 内核中,DMA 子系统的核心代码主要位于 kernel/dma/ 目录下,各个文件各司其职,协同工作。
mapping.c 文件是 DMA 子系统的通用接口层,它就像是一个 “总调度员”,是驱动程序与 DMA 子系统直接交互的入口。所有对外的 dma_* API 都在这个文件中实现,并且它负责根据设备的 dma_ops 和配置信息,将驱动程序的请求准确无误地分发到正确的底层实现模块,无论是直接映射、SWIOTLB 还是 IOMMU。
direct.c 和 direct.h 文件则专注于直接映射的实现,它们处理物理地址可以直接作为 DMA 地址的 “快速路径”。同时,这两个文件中还包含了对 CMA 和 DMA 原子池的调用逻辑,为直接映射提供了必要的支持。
swiotlb.c 文件主要负责软件 IOTLB 的实现,它完整地实现了 bounce buffer 机制,包括内存池的管理、slot 的分配以及数据的拷贝(bounce)等操作,是 SWIOTLB 功能的核心实现文件。
coherent.c 文件承担着一致性内存管理的重任,它主要处理通过设备树(reserved - memory)或平台代码为特定设备预留的一致性内存池,确保一致性 DMA 内存的正确分配和使用。
contiguous.c 文件实现了 CMA(Contiguous Memory Allocator)的集成,提供了从 CMA 区域分配大块物理连续内存的接口,供 direct.c 等模块在需要时调用,以满足设备对连续内存的需求。
pool.c 文件负责 DMA 原子池的管理,为那些不能睡眠的原子上下文,比如中断处理程序,提供小块 DMA 内存的快速分配服务,确保在这些特殊场景下 DMA 操作的高效进行。
通过对这些文件的协同分析,我们可以清晰地看到 Linux DMA 子系统的模块化架构,各个模块之间既相互独立又紧密协作,共同构建了一个高效、灵活的 DMA 管理系统。
二、 核心框架解析:Linux DMA 的两大技术支柱
2.1 DMA Mapping:设备与内存的 “地址翻译官”
在 Linux 的 DMA 体系中,DMA Mapping 扮演着一个至关重要的角色,它就像是设备与内存之间的 “地址翻译官”。我们知道,CPU 使用虚拟地址来访问内存,这是一种经过内存管理单元(MMU)映射后的逻辑地址,主要是为了提供内存保护、地址空间隔离以及虚拟内存等功能,方便操作系统对内存进行高效管理。而设备(如网卡、硬盘控制器等)则是直接通过物理总线访问内存,它们只能识别总线地址(也称为 DMA 地址)。这就好比两个说不同语言的人,CPU 说的是 “虚拟地址语言”,设备说的是 “总线地址语言”,如果没有一个 “翻译官”,它们之间就无法顺畅地交流,数据传输也就无法完成 。
Linux 内核将 DMA Mapping 分为两大类,以适配不同的传输场景。
2.1.1 一致性映射(Coherent DMA Mapping)
一致性映射就像是为 CPU 和设备搭建了一座 “实时同步桥梁”。它会分配一块特殊的内存,这块内存同时被 CPU 和 DMA 设备访问,并且内核会保证该内存的缓存一致性。也就是说,无论 CPU 写入数据,还是 DMA 设备读取或写入数据,双方都能立即看到最新的数据,就好像它们在共享同一份实时更新的文档。
在代码实现上,我们可以使用 dma_alloc_coherent 函数来分配一致性 DMA 内存。例如:
#include<linux/dma-mapping.h>#include<linux/device.h>staticintmy_driver_probe(struct device *dev){ dma_addr_t dma_handle; size_t size = 1024; // 分配1KB内存 void *cpu_addr = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL); if (!cpu_addr) { dev_err(dev, "Failed to allocate coherent DMA memory\n"); return -ENOMEM; } // 使用cpu_addr进行CPU访问,dma_handle进行设备访问 //... // 释放内存 dma_free_coherent(dev, size, cpu_addr, dma_handle); return 0;}
这种映射方式适用于一些对数据一致性要求极高的场景,比如 NVMe SSD 的提交队列(SQ)和完成队列(CQ)。这些队列长期存在,并且需要 CPU 与 NVMe SSD 控制器频繁交互,任何数据不一致都可能导致严重的错误,所以一致性映射能够很好地满足它们的需求。不过,由于一致性映射需要硬件支持缓存一致性协议,并且为了保证一致性,可能会有额外的性能开销,比如频繁地刷新缓存等。
2.1.2 流式映射(Streaming DMA Mapping)
流式映射则像是一个 “临时翻译服务”,它适用于一次性数据传输的场景,如文件读写、网络数据包收发等。在这种模式下,驱动程序在每次 DMA 传输前,动态地将一个已存在的内存缓冲区映射供 DMA 使用,并在传输结束后立即解除映射。
它不保证硬件 / CPU 缓存一致性,这就需要驱动程序在访问缓冲区之前,显式地调用同步函数来刷新缓存,从而同步缓冲区。例如,在数据从 CPU 传输到设备时,调用 dma_sync_single_for_device 函数,通知 CPU 将缓存中的数据写回主存,确保设备读取到的是最新数据;在数据从设备传输到 CPU 时,调用 dma_sync_single_for_cpu 函数,使 CPU 缓存失效,保证 CPU 读取的是设备写入主存的最新数据。
其 API 使用示例如下:
#include<linux/dma-mapping.h>#include<linux/device.h>staticintmy_driver_transfer_data(struct device *dev, void *buf, size_t size, enum dma_transfer_direction dir){ dma_addr_t dma_handle; dma_handle = dma_map_single(dev, buf, size, dir); if (dma_mapping_error(dev, dma_handle)) { dev_err(dev, "DMA map single failed\n"); return -EINVAL; } // 调用同步函数,准备设备访问 dma_sync_single_for_device(dev, dma_handle, size, dir); // 进行DMA传输 //... // 传输完成后,调用同步函数,准备CPU访问 dma_sync_single_for_cpu(dev, dma_handle, size, dir); dma_unmap_single(dev, dma_handle, size, dir); return 0;}
流式映射的优点在于它可以使用普通的、可缓存的内存,能够充分利用 CPU 缓存的优势,对于大块数据的传输性能表现出色。同时,它的灵活性高,可以映射任意已有的内存缓冲区。但缺点是需要手动管理同步时机,如果忘记同步,很容易导致数据不一致的问题,并且其实现复杂度相对较高,需要开发者深入理解缓存一致性的原理。
2.2 DMA Engine:屏蔽硬件差异的 “通用抽象层”
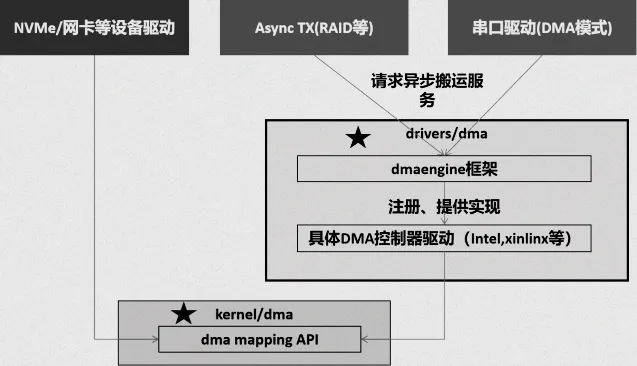
DMA Engine 是 Linux 内核中为传统外设 DMA 传输设计的通用抽象框架,它就像是一个 “通用翻译器”,核心目标是屏蔽不同厂商 DMA 控制器的硬件差异,为上层外设驱动(如网卡、声卡、串口驱动)提供统一的 DMA 操作接口,极大地简化了驱动开发的过程,并提升了代码的复用性。
其代码实现位于内核源码的 drivers/dma/ 目录下,与 DMA Mapping 的代码位置(kernel/dma/)不同,这也从侧面反映了它们不同的职责和定位。在这个目录下,包含了各种具体 DMA 控制器的驱动代码,以及实现 DMA Engine 核心逻辑的文件。
以网卡驱动开发为例,在没有 DMA Engine 之前,不同厂商的网卡 DMA 控制器可能有不同的寄存器布局、操作方式和中断处理逻辑。驱动开发者需要针对每一款网卡,深入了解其硬件细节,编写大量与硬件紧密耦合的代码。而有了 DMA Engine 之后,驱动开发者只需要使用 DMA Engine 提供的统一接口,如 dma_request_channel 获取 DMA 通道、dmaengine_submit 提交 DMA 传输请求等,就可以实现数据的高效传输,无需关心底层硬件的具体实现。
例如,下面是一段简单的使用 DMA Engine 进行内存到内存数据拷贝的代码示例:
#include<linux/dmaengine.h>#include<linux/device.h>staticintmy_memcpy_with_dmaengine(struct device *dev, void *dst, void *src, size_t size){ struct dma_chan *chan; struct dma_slave_config config; struct dma_transaction tx; int ret; // 请求DMA通道 chan = dma_request_channel(DMA_MEMCPY, NULL, NULL); if (!chan) { dev_err(dev, "Failed to request DMA channel\n"); return -ENODEV; } // 配置DMA从设备 memset(&config, 0, sizeof(config)); config.direction = DMA_MEM_TO_MEM; config.src_addr = (dma_addr_t)src; config.dst_addr = (dma_addr_t)dst; config.src_maxburst = 16; config.dst_maxburst = 16; config.src_addr_width = DMA_SLAVE_BUSWIDTH_32BIT; config.dst_addr_width = DMA_SLAVE_BUSWIDTH_32BIT; ret = dmaengine_slave_config(chan, &config); if (ret) { dev_err(dev, "Failed to configure DMA slave\n"); dma_release_channel(chan); return ret; } // 提交DMA传输请求 memset(&tx, 0, sizeof(tx)); tx.chained = false; tx.src_addr = (dma_addr_t)src; tx.dst_addr = (dma_addr_t)dst; tx.len = size; ret = dmaengine_submit(chan, &tx); if (ret) { dev_err(dev, "Failed to submit DMA transaction\n"); dma_release_channel(chan); return ret; } // 启动DMA传输 dma_async_issue_pending(chan); // 等待传输完成 dmaengine_terminate_sync(chan); // 释放DMA通道 dma_release_channel(chan); return 0;}
通过这段代码,我们可以清晰地看到 DMA Engine 提供的接口的使用方式,以及它如何将复杂的硬件操作抽象化,使得驱动开发变得更加简洁和高效。
对比 DMA Mapping 和 DMA Engine,DMA Mapping 主要关注的是如何为设备提供可访问的内存,并处理好地址转换和缓存一致性等问题;而 DMA Engine 则侧重于提供统一的 DMA 操作接口,屏蔽硬件差异,实现数据的高效传输。两者相互配合,共同构建了 Linux 强大的 DMA 体系。
2.3 补充知识点:DMA 的传输模式与地址类型
2.3.1 传输模式:Block DMA 与 Scatter-Gather DMA
在 DMA 的数据传输过程中,有两种主要的传输模式,它们各自有着独特的特点和适用场景,就像是不同类型的运输工具,适用于不同的货物运输需求。
Block DMA
Block DMA,也被称为传统的普通 DMA,它就像是一辆只能运输整箱货物的卡车,一次 DMA 传输只能处理一个物理上连续的内存区域。例如,当我们需要从磁盘读取一个文件时,如果文件在磁盘上的存储位置是连续的,并且文件大小不超过内存中连续可用空间的大小,那么就可以使用 Block DMA 来进行传输。它的硬件复杂度相对较低,因为它只需要处理单一的连续内存块,控制逻辑较为简单。在一些对数据传输要求不高、数据存储相对连续的场景中,Block DMA 能够很好地发挥作用,比如早期的软盘驱动器数据传输,由于软盘的数据存储方式相对简单,使用 Block DMA 就可以满足其基本的传输需求。
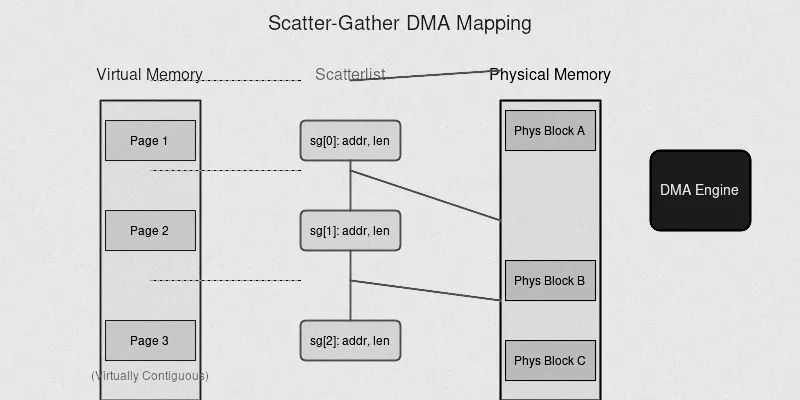
Scatter-Gather DMA
Scatter-Gather DMA 则像是一支拥有多辆卡车的运输车队,单次 DMA 传输可以处理多个物理上不连续的内存区域。这些不连续的内存区域通过一个链表来描述,DMA 控制器得到链表首地址后,会根据链表的指引,依次传输下一块物理上连续的数据,直到所有数据传输完毕。这种传输模式的出现,主要是为了应对现代计算机系统中内存碎片化的问题。随着系统的运行,内存会被频繁地分配和释放,导致内存空间变得碎片化,很难找到大块连续的内存区域。而 Scatter-Gather DMA 能够将分散在不同内存区域的数据,通过链表组织起来,一次性完成传输,大大提高了数据传输的效率。
在网络数据包的传输中,由于数据包在内存中的存储可能是分散的,使用 Scatter-Gather DMA 就可以避免将分散的数据先拷贝到一个连续的内存区域,然后再进行传输的繁琐过程,直接从分散的内存区域中读取数据并传输,减少了内存拷贝的开销,提高了网络传输的性能。在文件系统操作中,当读取或写入一个大文件时,如果文件片段分布在磁盘的不同位置,Scatter-Gather DMA 也可以有效地提高 I/O 操作的速度。
除了这两种基本的传输模式,DMA 还使用 channel(通道)来实现并行传输。每个通道互相独立,拥有自己的寄存器组、请求 / 响应逻辑以及中断信号通路,可以独立服务一个外设或一个外设的某类传输任务。通过这种方式,多个外设可以同时进行 DMA 传输,提高了系统的整体数据传输能力。一些高性能服务器中,多个网卡可以通过各自独立的 DMA 通道,同时进行网络数据的收发,大大提升了服务器的网络吞吐能力。
另外,还可以通过时间分片和上下文快速切换,实现虚拟通道技术。这种技术可以在一个物理通道上,通过分时复用的方式,实现多个虚拟通道的功能,进一步提高了通道的利用率。在一些资源有限的嵌入式系统中,虚拟通道技术可以在不增加硬件成本的前提下,满足多个外设对 DMA 通道的需求。
2.3.2 三大地址:虚拟地址、物理地址、总线地址
在 Linux DMA 的世界里,有三类重要的地址概念,它们就像是三把不同的 “钥匙”,分别开启不同的 “大门”,理解它们之间的关系是掌握 DMA 技术的关键前提。
虚拟地址
虚拟地址是 CPU 使用的地址,它是一种逻辑地址,就像是一个房间的门牌号。在现代操作系统中,为了实现内存保护、地址空间隔离以及虚拟内存等功能,每个进程都被分配了一个独立的虚拟地址空间。例如,在 32 位系统中,每个进程可以拥有 4GB 的虚拟地址空间,进程在运行时,所有的内存访问操作都是基于虚拟地址进行的。虚拟地址通过内存管理单元(MMU)进行转换,最终映射到物理地址。这就好比我们通过门牌号找到对应的房间,但实际进入房间时,需要通过一个 “转换机制”(MMU)来找到房间的实际位置(物理地址)。
物理地址
物理地址是内存芯片上存储单元的实际地址,它是内存的真实位置,就像是房间在大楼中的实际楼层和房间号。当 CPU 需要访问内存时,经过 MMU 的地址转换,将虚拟地址转换为物理地址,才能真正访问到内存中的数据。物理地址是内存硬件层面的地址,与内存的物理布局和芯片特性密切相关。
总线地址
总线地址是设备(如 DMA 设备)使用的地址,用于在设备和内存之间进行数据传输。在没有 I/O 内存管理单元(IOMMU)的情况下,总线地址通常与物理地址一致,或者存在一个固定的偏移量。这是因为设备直接通过物理总线访问内存,所以它所使用的地址需要与内存的物理地址相对应。而在有 IOMMU 的情况下,IOMMU 会对总线地址进行地址映射,将设备使用的总线地址转换为物理地址,实现设备对内存的正确访问。这就好比设备通过一个 “中介”(IOMMU)来找到内存的实际位置,即使内存的物理地址发生了变化,设备只需要使用 IOMMU 映射后的总线地址,就可以正确地访问内存。
理解这三类地址的概念和它们之间的转换关系,对于深入理解 Linux DMA 的工作原理至关重要。在 DMA 传输过程中,需要将 CPU 使用的虚拟地址转换为设备可识别的总线地址,确保数据能够在设备和内存之间准确无误地传输。
三、 实战:从驱动开发到 AXI-DMA 优化
3.1 手把手教你写基础 DMA 驱动:核心步骤拆解
在 Linux 系统中开发基础的 DMA 驱动,就像是搭建一座稳固的桥梁,需要精心规划每一个步骤,确保数据能够在设备和内存之间顺畅传输。下面我们将逐步拆解核心步骤,帮助你掌握 DMA 驱动开发的精髓。
3.1.1 驱动初始化:DMA 控制器与设备配置
驱动初始化是 DMA 驱动开发的第一步,也是至关重要的一步。在这一步中,我们需要调用 init_dma () 函数来配置 DMA 控制器的各项参数,使其能够正常工作。这个过程就像是为 DMA 控制器设置 “工作指南”,明确它的工作方式和职责。
我们需要根据设备的具体需求,设置 DMA 控制器的源地址、目标地址、传输数据长度以及传输方向等关键参数。这些参数就像是为 DMA 控制器规划的 “运输路线”,决定了数据从哪里来,到哪里去,以及运输的数量和方向。例如:
staticintinit_dma(struct device *dev){ struct dma_device *dma_dev; struct dma_chan *chan; // 查找并获取DMA设备 dma_dev = dma_find_device("my_dma_device", dev, NULL, NULL); if (!dma_dev) { dev_err(dev, "DMA device not found\n"); return -ENODEV; } // 获取DMA通道 chan = dma_request_channel(dma_dev, NULL, NULL); if (!chan) { dev_err(dev, "Failed to request DMA channel\n"); dma_release_device(dma_dev); return -ENODEV; } // 设置dma_mask,指定设备的寻址能力 if (!dma_set_mask_and_coherent(chan->device->dev, DMA_BIT_MASK(32))) { dev_err(dev, "DMA mask setting failed\n"); dma_release_channel(chan); dma_release_device(dma_dev); return -EIO; } // 绑定设备与DMA通道 dev_set_dma_ops(dev, &my_dma_ops, NULL); return 0;}
在上述代码中,我们首先使用 dma_find_device 函数查找并获取指定的 DMA 设备,这就像是在众多设备中找到我们需要的那个 “运输工具”。然后,通过 dma_request_channel 函数获取 DMA 通道,这个通道就像是一条专门的数据运输通道,确保数据能够高效传输。接着,使用 dma_set_mask_and_coherent 函数设置 dma_mask,明确设备的寻址能力,避免出现地址访问错误。最后,通过 dev_set_dma_ops 函数将设备与 DMA 通道进行绑定,就像是将设备与运输通道连接起来,确保数据能够准确无误地传输到目标位置。
3.1.2 传输实现:参数设置与启停控制
完成驱动初始化后,接下来就是实现 DMA 传输的核心逻辑。这一步就像是启动一辆装满货物的卡车,需要精确设置各项参数,确保运输过程顺利进行。我们通过 start_dma_transfer () 函数来配置 DMA 传输的关键参数,包括源地址、目的地址和数据长度等。这些参数就像是为卡车规划的具体运输路线和货物数量,决定了数据传输的细节。例如:
staticvoidstart_dma_transfer(struct device *dev, void *src, void *dst, size_t len){ struct dma_chan *chan = dev_get_dma_chan(dev); struct dma_slave_config config; // 配置DMA从设备参数 memset(&config, 0, sizeof(config)); config.direction = DMA_MEM_TO_MEM; config.src_addr = (dma_addr_t)src; config.dst_addr = (dma_addr_t)dst; config.src_maxburst = 16; config.dst_maxburst = 16; config.src_addr_width = DMA_SLAVE_BUSWIDTH_32BIT; config.dst_addr_width = DMA_SLAVE_BUSWIDTH_32BIT; // 配置DMA从设备 if (dmaengine_slave_config(chan, &config)) { dev_err(dev, "Failed to configure DMA slave\n"); return; } // 提交DMA传输请求 struct dma_transaction tx; memset(&tx, 0, sizeof(tx)); tx.chained = false; tx.src_addr = (dma_addr_t)src; tx.dst_addr = (dma_addr_t)dst; tx.len = len; if (dmaengine_submit(chan, &tx)) { dev_err(dev, "Failed to submit DMA transaction\n"); return; } // 启动DMA传输 dma_async_issue_pending(chan);}
在上述代码中,我们首先通过 dev_get_dma_chan 函数获取设备的 DMA 通道,这是数据传输的 “主干道”。然后,使用 dmaengine_slave_config 函数配置 DMA 从设备的参数,包括传输方向、源地址、目的地址以及地址宽度和突发传输大小等,确保设备能够正确接收和发送数据。接着,使用 dmaengine_submit 函数提交 DMA 传输请求,就像是向运输公司提交运输任务。最后,通过 dma_async_issue_pending 函数启动 DMA 传输,让数据开始在设备和内存之间传输。
在 DMA 传输完成后,我们还需要处理中断信号,以通知 CPU 传输已经结束。这就像是卡车到达目的地后,需要向发货人发送到货通知。我们可以通过设置中断处理函数来实现这一功能,例如:
staticirqreturn_tmy_dma_irq_handler(int irq, void *dev_id){ struct device *dev = (struct device *)dev_id; struct dma_chan *chan = dev_get_dma_chan(dev); // 检查DMA传输状态 if (dmaengine_tx_status(chan, NULL, NULL) == DMA_COMPLETE) { // 传输完成,进行相应处理 dev_info(dev, "DMA transfer completed\n"); } else { // 传输出错,进行错误处理 dev_err(dev, "DMA transfer error\n"); } return IRQ_HANDLED;}
在用户空间,我们可以通过 open () 和 ioctl () 函数与内核驱动进行交互,发起 DMA 传输请求。例如:
#include<stdio.h>#include<fcntl.h>#include<sys/ioctl.h>#define MY_DMA_IOC_MAGIC 'Z'#define MY_DMA_IOC_START_TRANSFER _IOWR(MY_DMA_IOC_MAGIC, 0, struct my_dma_transfer)struct my_dma_transfer { void *src; void *dst; size_t len;};intmain(){ int fd = open("/dev/my_dma_device", O_RDWR); if (fd < 0) { perror("open"); return 1; } struct my_dma_transfer transfer; transfer.src = (void *)0x10000000; transfer.dst = (void *)0x20000000; transfer.len = 1024; if (ioctl(fd, MY_DMA_IOC_START_TRANSFER, &transfer) < 0) { perror("ioctl"); } close(fd); return 0;}
在上述代码中,我们定义了一个自定义的 ioctl 命令 MY_DMA_IOC_START_TRANSFER,用于发起 DMA 传输请求。在 main 函数中,我们打开设备文件 /dev/my_dma_device,然后使用 ioctl 函数向内核驱动发送传输请求,传递源地址、目的地址和数据长度等参数。内核驱动接收到请求后,会根据这些参数启动 DMA 传输。
3.1.3 驱动卸载:资源释放与清理
当驱动不再使用时,我们需要进行驱动卸载操作,释放所有占用的系统资源,确保系统的稳定性和资源的有效利用。这就像是在运输任务完成后,需要将卡车归还,并清理运输过程中产生的垃圾。在驱动卸载阶段,我们首先需要调用 dma_free_coherent () 函数释放 DMA 内存,这就像是归还占用的仓库空间。例如:
staticvoidmy_driver_remove(struct device *dev){ void *cpu_addr; dma_addr_t dma_handle; // 获取之前分配的内存地址和DMA句柄 // 假设之前的代码中已经将这些信息存储在设备的私有数据中 struct my_driver_private *priv = dev_get_drvdata(dev); cpu_addr = priv->cpu_addr; dma_handle = priv->dma_handle; // 释放DMA内存 dma_free_coherent(dev, priv->buffer_size, cpu_addr, dma_handle); // 解除地址映射 // 假设之前使用了dma_map_single进行映射 dma_unmap_single(dev, dma_handle, priv->buffer_size, DMA_TO_DEVICE); // 注销DMA通道 struct dma_chan *chan = dev_get_dma_chan(dev); dma_release_channel(chan); // 注销中断 free_irq(dev->irq, dev); // 清理设备私有数据 kfree(priv);}
在上述代码中,我们首先从设备的私有数据中获取之前分配的内存地址和 DMA 句柄,然后使用 dma_free_coherent 函数释放 DMA 内存,使用 dma_unmap_single 函数解除地址映射。接着,通过 dma_release_channel 函数注销 DMA 通道,就像是关闭数据运输通道。最后,使用 free_irq 函数注销中断,清理设备的私有数据,确保没有任何资源残留。规范释放资源对于驱动的稳定性和系统的健康运行至关重要,如果资源没有正确释放,可能会导致内存泄漏、系统崩溃等严重问题。
3.2 进阶实战:AXI-DMA 驱动优化的核心技巧
在嵌入式系统开发中,AXI-DMA(Advanced eXtensible Interface Direct Memory Access)因其高速的数据传输能力而被广泛应用。然而,要充分发挥 AXI-DMA 的性能优势,对其驱动进行优化是必不可少的。下面我们将深入探讨 AXI-DMA 驱动优化的核心技巧,帮助你提升系统的整体性能。
3.2.1 AXI-DMA 硬件架构:接口与缓冲区管理
AXI-DMA 的硬件架构是理解其工作原理和进行驱动优化的基础。它主要由 AXI 总线接口和 DMA 控制器组成,就像是一个高效的物流中心,负责在内存和外设之间快速传输数据。AXI 总线接口包括 AXI 读通道和 AXI 写通道,它们分别负责数据的读取和写入操作,就像是物流中心的进货通道和出货通道,分工明确,确保数据的高效传输。
在 AXI-DMA 的硬件架构中,流控制和缓冲区管理起着关键作用。流控制机制就像是交通警察,确保数据传输的顺序和速率,避免数据拥堵和丢失。缓冲区管理则涉及到缓冲区的创建、分配、映射以及在传输过程中的管理,直接影响着 DMA 操作的性能。缓冲区的大小、对齐方式等参数对传输效率有着重要影响。例如,较大的缓冲区可以减少数据传输的次数,但可能会占用更多的内存资源;而缓冲区的对齐方式不当,则可能导致数据访问错误,降低传输效率。因此,合理配置缓冲区是优化 AXI-DMA 驱动的基础。
3.2.2 性能调优三大方向:中断、内存与调度
在 Petalinux 环境下,我们可以从以下三个核心方向对 AXI-DMA 驱动进行性能调优,以实现数据的高效传输和系统资源的合理利用。
优化中断处理
在传统的 AXI-DMA 驱动中,每次数据传输完成都会产生一个中断信号,通知 CPU 进行处理。然而,频繁的中断响应会占用大量的 CPU 资源,降低系统的整体性能。为了优化这一问题,我们可以采用批量中断的方式,即将多个数据传输任务合并为一组,只有当这一组任务全部完成时,才产生一个中断信号。这样可以大大减少 CPU 的中断响应次数,提高系统的运行效率。
在驱动代码中,我们可以通过设置 DMA 控制器的相关寄存器,调整中断触发的条件和频率。例如,将多个较小的数据传输任务组合成一个较大的传输任务,在传输完成后统一触发中断。同时,我们还可以优化中断服务程序,减少其执行时间,使其能够快速处理中断事件,避免长时间占用 CPU 资源。
优化内存管理
内存管理是影响 AXI-DMA 性能的另一个重要因素。在 Linux 系统中,内存的分配和管理是一个复杂的过程,而 AXI-DMA 对内存的连续性和访问效率有着较高的要求。为了满足这一需求,我们可以利用连续内存分配器(CMA,Contiguous Memory Allocator)来分配连续的物理内存。CMA 就像是一个专门为 AXI-DMA 准备的内存仓库,它可以在系统启动时预留一块连续的内存区域,供 AXI-DMA 在需要时使用。
在 Petalinux 环境下,我们可以通过修改设备树文件,配置 CMA 内存区域的大小和属性。例如,在设备树文件中添加如下配置:
reserved-memory { #address-cells = <1>; #size-cells = <1>; ranges; cma_region: cma@0 { compatible = "shared-dma-pool"; reg = <0x0 0x10000000>; /* 1GB的CMA区域 */ no-map; };};
这样,系统启动时就会预留 1GB 的连续内存作为 CMA 区域,供 AXI-DMA 使用。在驱动代码中,我们可以通过调用相关的内核函数,从 CMA 区域中分配内存,确保 AXI-DMA 能够使用连续的物理内存进行数据传输,提高传输效率。
优化多通道任务调度
AXI-DMA 通常支持多个通道,每个通道可以独立进行数据传输。在多通道应用场景下,合理的任务调度可以充分利用硬件资源,提高系统的整体性能。我们可以根据不同任务的优先级和数据传输需求,动态分配通道资源,确保重要任务能够优先得到处理。
例如,在一个同时进行视频采集和网络数据传输的系统中,视频采集任务对实时性要求较高,我们可以将其分配到优先级较高的通道上,确保视频数据能够及时传输;而网络数据传输任务对实时性要求相对较低,可以分配到优先级较低的通道上。在驱动代码中,我们可以通过设置 DMA 通道的优先级和调度策略,实现多通道任务的高效调度。
在衡量 AXI-DMA 驱动优化的效果时,我们可以使用传输速率、CPU 利用率等指标。通过对比优化前后这些指标的变化,我们可以直观地评估优化措施的有效性,进而不断调整优化策略,实现 AXI-DMA 驱动性能的最大化。
3.3 实战踩坑:常见问题与排查方法
在 DMA 驱动开发的过程中,难免会遇到各种各样的问题,这些问题就像是路上的绊脚石,阻碍着我们实现高效的数据传输。下面我们将总结一些常见问题,并提供相应的排查方法,帮助你快速解决问题,顺利完成驱动开发。
缓存一致性导致的数据错乱
在 DMA 传输过程中,由于 CPU 缓存和内存之间的一致性问题,可能会出现数据错乱的情况。当 CPU 修改了缓存中的数据,但尚未将这些数据写回到内存时,DMA 设备直接从内存中读取数据,就会读取到旧数据,导致数据不一致。
为了解决这个问题,我们需要在 DMA 传输前后,正确调用同步函数,确保缓存和内存之间的数据一致性。在使用流式 DMA 映射时,在数据传输前,调用 dma_sync_single_for_device 函数,将 CPU 缓存中的数据写回到内存,并使缓存失效,确保设备读取到的是最新数据;在数据传输完成后,调用 dma_sync_single_for_cpu 函数,使 CPU 缓存失效,确保 CPU 读取的是设备写入内存的最新数据。
地址映射失败
地址映射是 DMA 驱动开发中的一个关键环节,如果地址映射失败,DMA 设备将无法正确访问内存,导致数据传输失败。地址映射失败的原因可能有多种,其中 dma_mask 配置不正确是一个常见的原因。dma_mask 定义了设备能够寻址的最大物理地址范围,如果 dma_mask 设置过小,设备将无法访问某些内存地址,从而导致地址映射失败。
当遇到地址映射失败的问题时,我们首先要检查 dma_mask 的配置是否正确。可以通过查看设备的硬件手册,确定设备的寻址能力,然后根据实际情况调整 dma_mask 的设置。此外,还需要检查内存分配和映射的相关代码,确保内存地址的合法性和映射的正确性。
SWIOTLB 性能瓶颈
在一些情况下,当设备的 dma_mask 较小,无法覆盖整个物理内存时,Linux 内核会使用 SWIOTLB(Software I/O TLB)来进行地址转换。SWIOTLB 通过在低地址空间分配一块 bounce buffer,将高地址内存的数据拷贝到 bounce buffer 中,然后让设备访问 bounce buffer。然而,这种方式会带来额外的数据拷贝开销,导致性能瓶颈。
为了解决 SWIOTLB 的性能瓶颈问题,我们应尽量启用 IOMMU(I/O Memory Management Unit)。IOMMU 可以提供硬件层面的地址转换功能,避免了 SWIOTLB 的软件拷贝开销,大大提高了数据传输的效率。如果硬件支持 IOMMU,我们可以通过修改内核配置,启用 IOMMU 功能,从而提升系统性能。
在排查问题时,日志分析是一个非常有效的工具。我们可以通过查看内核日志,获取 DMA 驱动运行时的详细信息,包括地址映射、传输状态、中断处理等。通过分析这些日志信息,我们可以快速定位问题所在,并采取相应的解决措施。例如,如果日志中出现 “DMA mapping error” 的错误提示,我们就可以根据提示信息,检查地址映射的相关代码和配置,找出 ## 四、 进阶优化与避坑:打造高性能 DMA 应用
4.1 缓存一致性优化:从原理到实践方案
在 DMA 传输中,缓存一致性问题是影响性能的关键因素之一。当 CPU 修改了缓存中的数据,而设备直接访问内存时,就可能读取到旧数据,导致数据不一致。这就好比两个人同时编辑一份文档,一个人在本地修改后没有保存,另一个人直接从服务器读取,就会拿到旧版本的文档。
为了解决这个问题,我们可以采用硬件自动同步和软件显式同步两种方式。硬件自动同步通常依赖于一致性内存,这种内存采用非缓存或写通模式,硬件会自动保证 CPU 和设备对内存的访问是一致的,就像两个人使用实时在线文档,任何一方的修改都会立即同步给对方。
而软件显式同步则是在流式 DMA 中,通过驱动程序在传输前后显式调用同步函数来实现。在数据从 CPU 传输到设备前,调用 dma_sync_single_for_device 函数,将 CPU 缓存中的数据写回内存并使缓存失效,确保设备读取到最新数据;传输完成后,调用 dma_sync_single_for_cpu 函数,使 CPU 缓存失效,保证 CPU 读取的是设备写入内存的最新数据。这就像是在文档传输前,手动保存并上传最新版本,传输后再从服务器下载最新版本。
在实际应用中,我们需要根据数据传输的特点来选择合适的方式。对于高频小数据的传输,由于数据量小且传输频繁,使用一致性内存可以简化编程模型,确保数据的实时一致性,就像频繁修改的小文件使用实时在线文档更方便。而对于大块批量数据的传输,流式 DMA 结合合理的同步时机可以充分利用 CPU 缓存,提高传输效率,同时避免过度同步导致的性能损耗。比如在传输大文件时,先将数据缓存到内存中,在传输完成后再进行一次同步,而不是每次小数据传输都进行同步,这样可以减少同步操作的开销。
4.2 内存分配策略:CMA、原子池与普通内存的选型
内存分配策略的选择对于 DMA 性能也有着重要影响。在不同的场景下,我们需要根据内存的连续性、分配的原子性以及性能要求等因素,合理选择 CMA(Contiguous Memory Allocator)、原子池(pool.c)与普通内存。
当需要大块连续物理内存时,CMA 是首选。例如在视频采集、图像处理等场景中,需要连续的内存空间来存储一帧帧的图像数据或视频流数据,CMA 可以在系统启动时预留一块连续的内存区域,供设备在需要时使用。在 Petalinux 环境下,我们可以通过修改设备树文件来配置 CMA 内存区域的大小和属性,如:
reserved-memory { #address-cells = <1>; #size-cells = <1>; ranges; cma_region: cma@0 { compatible = "shared-dma-pool"; reg = <0x0 0x10000000>; /* 1GB的CMA区域 */ no-map; };};
在驱动代码中,可以通过 dma_alloc_coherent 函数从 CMA 区域分配内存,确保设备能够使用连续的物理内存进行数据传输,提高传输效率。
对于中断等原子上下文场景,由于不能睡眠,需要快速分配内存,此时 DMA 原子池(pool.c)就发挥了作用。原子池预先分配了一些小块内存,当有原子上下文的内存分配请求时,可以快速从原子池中获取内存,避免了在中断处理中进行复杂的内存分配操作导致的延迟。在使用原子池时,需要注意其内存大小和分配策略,确保能够满足原子上下文的需求。
而在普通场景中,流式 DMA 的可缓存内存是常用的选择。这种内存分配方式灵活,能够利用 CPU 缓存提高数据访问速度。在进行流式 DMA 映射时,需要注意同步函数的调用,确保缓存一致性。
4.3 IOMMU 与 SWIOTLB 选型:性能与兼容性的权衡
在 DMA 应用中,IOMMU(I/O Memory Management Unit)和 SWIOTLB(Software I/O Translation Lookaside Buffer)的选型是一个需要谨慎考虑的问题,它涉及到性能与兼容性的权衡。
IOMMU 是一种硬件设备,它通过地址映射表将设备使用的 I/O 虚拟地址(IOVA)转换为物理地址,实现设备对内存的访问。这种硬件地址映射方式具有高性能的特点,能够实现大地址空间的访问,并且支持设备虚拟化和安全隔离。在服务器和高端嵌入式系统中,由于对性能要求较高,并且硬件通常支持 IOMMU,因此优先启用 IOMMU 是提升 DMA 性能的关键。在使用 IOMMU 时,需要配置 IOMMU 域,将设备附加到相应的域中,并进行地址映射操作。
而 SWIOTLB 是一种软件后备方案,当硬件不支持 IOMMU 或者 IOMMU 无法处理某些情况时,SWIOTLB 就会发挥作用。它通过在低地址空间预分配一块内存池作为 bounce buffer,当设备需要访问高地址内存时,先将数据从高地址拷贝到 bounce buffer 中,然后设备访问 bounce buffer,传输完成后再将数据拷贝回高地址内存。这种方式虽然保证了兼容性,但不可避免地带来了额外的数据拷贝开销,导致性能下降。在老旧硬件场景中,由于硬件不支持 IOMMU,只能使用 SWIOTLB 来保障设备的正常工作,但需要注意其性能瓶颈,尽量减少大数据量的传输操作。