很早之前就想给技术小伙伴们分享一篇关于Linux日志排查提效的实战指南。线上服务突然变慢?
用户反馈支付失败?
监控报警 CPU 飙升?
别慌!在 Linux 服务器上,你不需要图形界面,也不需要下载整个日志——只需掌握 grep、awk、sed、less 这四件神器,就能在海量日志中精准定位问题。
它们分工明确、配合默契,堪称日志排查的“黄金四件套”:
grep:快速搜索关键词(如异常、错误码)
less:高效浏览大文件(支持回溯与实时跟踪)
sed:按时间窗口切片日志(从 GB 级日志中提取关键片段)
awk:结构化分析字段数据(统计、聚合、识别异常模式)
下面,我们通过五个真实实战场景,手把手教你如何用好这套组合技。
实战一:用grep快速定位Java异常(开发/运维日常)
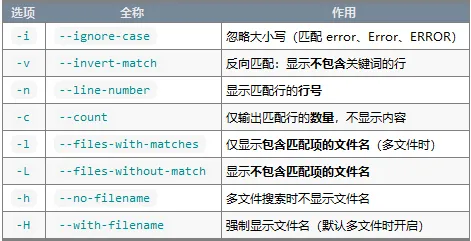
grep语法 grep [选项] '搜索模式' 文件...
常用选项(Options)
上下文控制(关键!)
使用场景
场景1:服务突然大量报错,告警显示“NullPointerException”。你需要查看完整堆栈。 Java 异常通常跨多行,仅匹配异常类名会丢失上下文。
推荐做法:
# 查找异常,并显示其后50行(覆盖典型堆栈)grep -A 50 "java.lang.NullPointerException" /app/logs/service.log
但输出太多?加上less 分页查看完整堆栈,效率翻倍:
grep -A 50 "NullPointerException" /app/logs/service.log | less
进阶:若日志按天轮转,查所有历史日志:
grep -A 50 "NullPointerException" /app/logs/service.log*
场景2:结合正则表达式,精准匹配。
# 匹配 HTTP 5xx 错误grep -E 'HTTP/1\.[01]" 5[0-9]{2}' access.log# 匹配 IPv4 地址grep -E '\b([0-9]{1,3}\.){3}[0-9]{1,3}\b' service.log
场景3:tail+grep 组合命令,威力倍增
# 实时监控异常tail -f service.log | grep -i -A 30 "exception"
# 多条件筛选grep 'ERROR' service.log | grep '开票异常'
场景4:翻历史日志 or 查压缩日志
# 未压缩日志grep -H -A 20 "Timeout" *.log
# 压缩日志(.gz) 无需解压,直接分析!zgrep -H -A 20 "Timeout" *.gz
场景5:快速统计异常频率 判断问题是偶发还是雪崩:
# 单文件grep -c "Connection refused" service.log# 多文件(带文件名)grep -c "OutOfMemory" *.log
输出示例:
service.log:28service.log.2025-12-18:317
一眼锁定异常高峰!
场景6:多文件与递归搜索
# 搜索当前目录下所有 .log 文件grep "Exception" *.log# 递归搜索子目录(含子目录中的 .log)grep -r "NullPointerException" /app/logs/# 递归 + 只搜 .log 文件(避免二进制文件干扰)grep -r --include="*.log" "Timeout" /app/logs/
场景7:多条件搜索
#多条件 ANDgrep "ERROR" app.log | grep "database"#多条件 ORgrep -E "ERROR|FATAL|CRITICAL" app.log
实战二:用less快速侦察
场景:客户说“开票 89797238 在 16:35失败”,你要从 5GB 日志中找到相关记录。
less 是处理 GB 级日志的首选工具:
按需加载,内存友好;支持双向搜索、实时跟随。
在 less 中操作:
按 Shift + G → 跳到日志末尾(最新内容)
输入 ?89797238 → 向上反向搜索订单号
按 n → 继续向上找更早的日志(比如重试记录)
发现日志还在写?按 Shift + F → 进入实时模式(类似 tail -f)
想退出实时模式?按 Ctrl + C
退出less 按 q
效果:30 秒内定位到完整开票链路,包括请求、回调、失败原因。特别适合客诉复现、链路追踪等场景。
实战三:时间窗口手术刀,用sed切出事故时间窗
场景:系统在 2025-12-19 15:00–15:15 间出现大量超时,但日志有 12GB,即使 grep 也会返回过多结果,这时就需要 按时间窗口切片。如你只想分析这 15 分钟。
假设日志每行以 [2025-12-19 15:00:00] 开头:
sed -n '/$$2025-12-19 15:00/,/$$2025-12-19 15:16/p' app.log > tmp.log
注意:结束时间略往后延(15:16),确保覆盖 15:15:59 的日志。
效果:原日志 12GB → 切片日志仅 8MB,可轻松scp下载或分析。
实战四:结构化分析,用 awk 挖掘日志中的关键指标
对于格式规范的日志(如 Nginx、Apache、应用 JSON 日志转为字段化文本),awk 是进行聚合、过滤、排序的利器。它能直接在服务器上生成“日志简报”,无需导出数据。
场景1:识别高频失败接口(提升用户体验)
假设你的统计nginx服务日志:
你想知道:哪些接口最近频繁返回 5xx 错误?
# 提取状态码为 5xx 的请求路径,统计频次并排序awk '$9 >= 500 && $9 < 600 {print $11}' access.log \ | sort \ | uniq -c \ | sort -nr \ | head -n 10
输出示例:
20 "http://xxx.com/manage/v5/main.html" 13 "http://xxx.com/manage/v5/main.html?yid=015c487645489ca3098aa6d" 3 "http://xxx.com/v5/xx/xx/xx/index.html?xxkdm=1"
场景2 :发现异常用户行为(安全 & 防刷)
假设日志包含:IP | 时间 | 接口 | 用户ID | 设备类型
你想排查:是否有用户在短时间内高频调用敏感接口?
# 统计每个用户对 /api/v1/reward 接口的调用次数awk '$3 == "/api/v5/reward" {print $4}' app.log \ | sort \ | uniq -c \ | sort -nr \ | head -n 5
输出示例:
312 user_xx21 198 user_xx45 87 user_xx12
若正常用户每天最多调用5次,而 user_xx21 调用了 300+ 次,极可能是脚本攻击!
结合 grep 先过滤时间窗口,再用 awk 分析,效果更佳:
grep "2025-12-19" app.log | awk '$3=="/api/v1/reward" {print $4}'
场景3:找出响应慢的接口 Nginx 日志中的响应时间,假设在最后一列,我们想把响应时间超过3秒的请求找出来。
# $NF 代表最后一列# 打印所有响应时间大于3秒的 URL(假设 URL 在第11列)awk '$NF > 3.000 {print $11, $NF}' access.log
实战五:四件套联动 —— 完整故障排查流程
场景:服务 CPU 飙升,用户反馈“下单卡住”。你被拉进应急群。
第一步:用 less 快速侦察
less /app/logs/app.logShift + G # 跳到末尾?Timeout # 向上搜超时关键字
发现大量 TimeoutException,集中在 14:05–14:10。
第二步:用 sed 切片
sed -n '/$$2025-12-19 14:05/,/$$2025-12-19 14:10/p' app.log > /tmp/tmp_1.log
第三步:用 awk 分析切片
# 找出超时最多的接口awk '/TimeoutException/ {print $4}' /tmp/tmp_1.log | sort | uniq -c | sort -nr
第四步:用 grep 验证修复
修复上线后,实时监控是否还有超时:
tail -f /app/logs/app.log | grep "TimeoutException"
无输出 = 问题已解决!
结语
高手和新手的区别,不在于知道多少工具,而在于能否用最简单的命令,解决最复杂的问题。
现在就去试试!打开你的服务器,动起手来,你会发现:排查问题,原来可以这么快。
👉原创不易,欢迎小伙伴们点击“在看”并转发,让更多开发者看到!感谢各位!❤️
作者:李军 | 架构师 & 技术布道者
原创文章,转载请注明出处。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
