最近听某个律师朋友说,虽然现在AI、数字化已经很普遍了,但其实还有很多垂直行业的数据要靠手工拉,比如律师常用的专利信息,需要从各个国家的专利网站去查询,诸如USPTO(美国专利商标局)、谷歌Patent等,然后汇总到Excel中,重复性和碎片化非常严重,这可是上百个国家、上亿条数据呀。
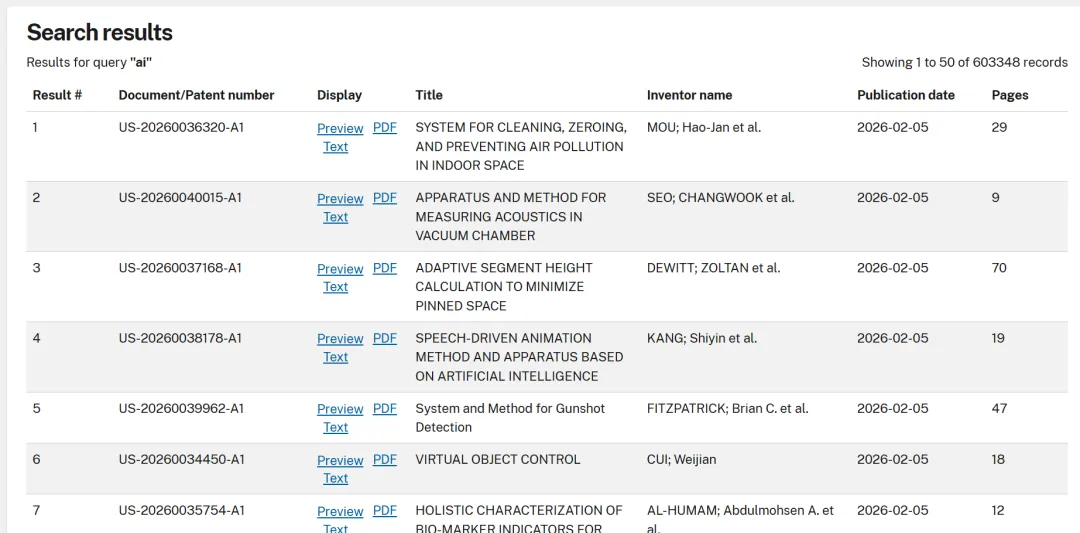
像专利信息这类的数据,为什么缺少整合平台去统一采集整理呢?
主要有三个难点,首先是这些数据过于分散和琐碎,不同信息源的数据格式差异很大,文本、数字、表格等,很难统一去检索。
其次各大专利数据库对于爬虫采集防范措施很严,会采用JavaScript 动态渲染、 CAPTCHA验证、IP封锁、浏览器指纹检测等方法去阻止自动化采集程序,所以难度是非常高的。
最重要的一点是,得确保数据采集的安全性,这些专利数据是公开数据,原则上没问题,但数据采集过程不能干扰到网站的正常运行,还得符合不同国家的合规性要求。
所以我打算用Python结合亮数据的网页解锁API去采集数据,并搭建一个可以交互的GUI系统,支持通过专利号或者关键词去检索不同网站的专利信息,并能直接展示和导出结果Excel。
其中会用到Python的requests、pandas、tkinter等工具包,requests通过亮数据网页解锁API去请求数据,这样能直接绕过繁琐的反爬机制,并且能保证合规性。
pandas用来处理采集到的数据,比如格式调整、脏数据清洗等,tkinter则用于搭建GUI框架,它是python内置模块,非常轻量,适合开发专利查询这类轻应用。
这里简单介绍下什么是亮数据网页解锁API,这是整个开发环节的难点。
前面提到很多网站会设置各种门槛,去拦截网络爬虫,亮数据把应对这些拦截机制的技术封装到一个API里,比如代理ip池、解锁器、动态处理、cookies管理等,它支持通过python、javascript等编程语言去调用,这样就大大降低了数据采集难度,可以集中精力去开发系统和分析数据。
https://get.brightdata.com/weijun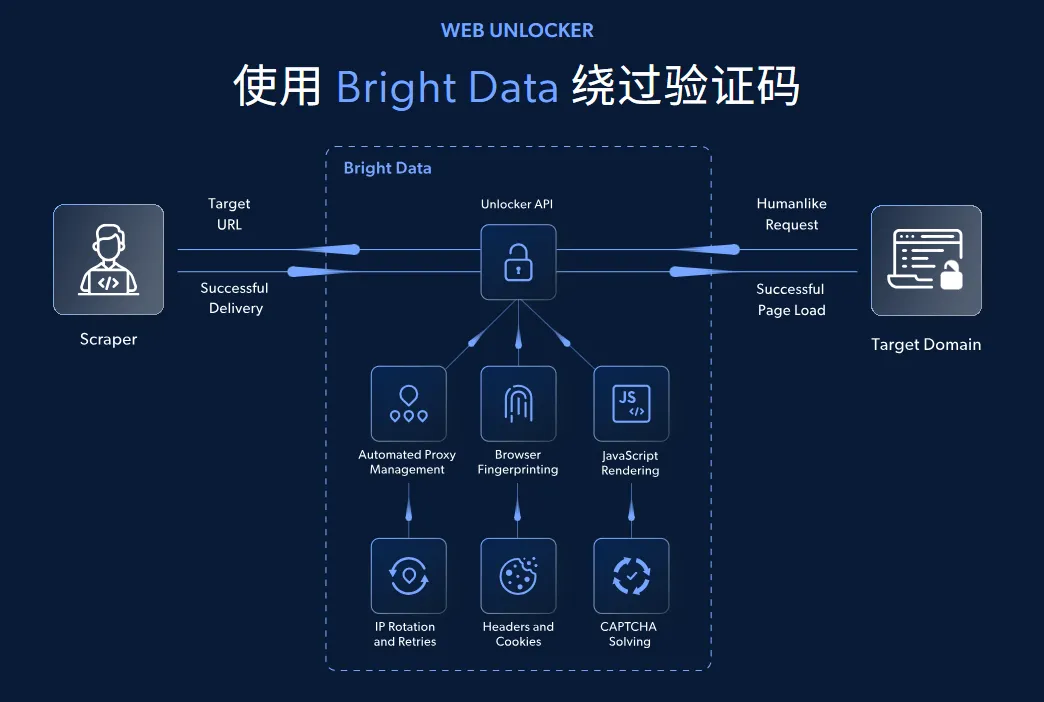
要说明下,这个GUI系统仅是个人测试研究用的试验品,且是demo版本,不用作任何的商业用途。
接下来是开发前的环境配置和系统准备。
首先是Python 环境,建议用Python 3.8或更高版本,并通过pip安装好以下几个第三方工具包,tkinter是内置模块,不需要再安装。
- requests:用于发送 HTTP 请求,与Brightdata API交互
接下来是获取亮数据API密钥,需要在亮数据官网注册一个账号,登录后在控制台中创建一个Web Unlocker项目,你会看到API Key,这个密钥是访问Web Unlocker服务的凭证,一定要保存好。
https://get.brightdata.com/weijun
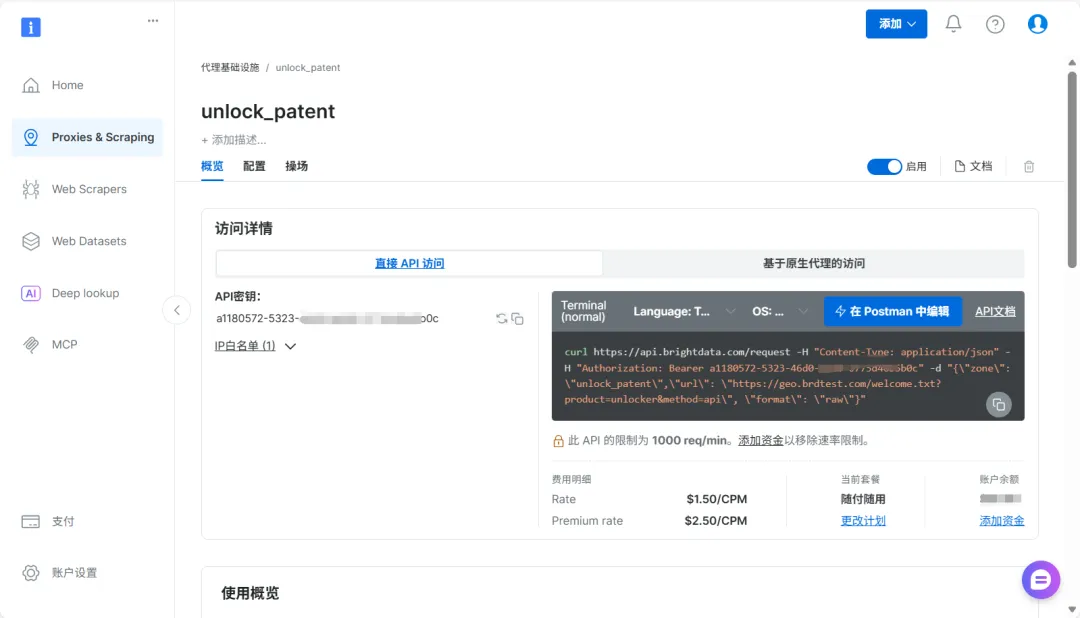
控制台中会提供示例代码,可以作为requests采集的主代码模板。
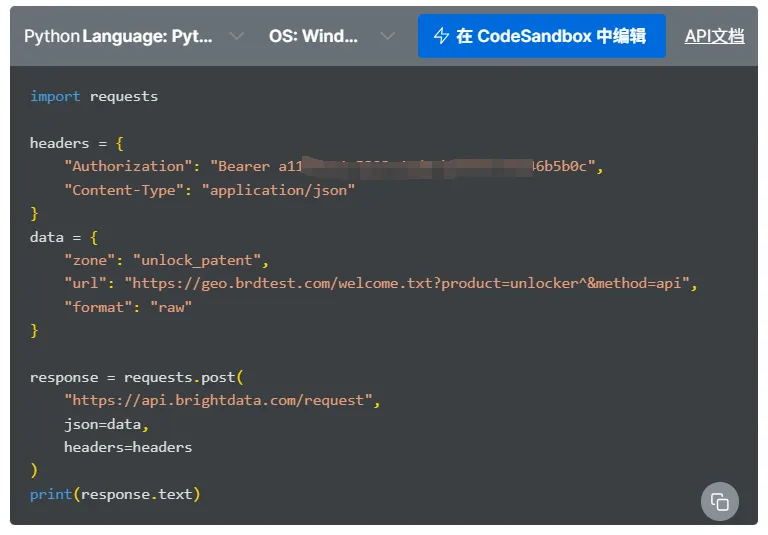
这里要注意API的使用限制,免费试用账号通常有流量限制,正式使用需要购买套餐。
进入开发,建议创建一个专门的项目目录,比如 "patent_search_system",然后在该目录下创建以下文件。
patent_scraper.py:封装requests请求亮数据API模块
gui_interface.py:创建专利数据采集可视化交互界面模块
excel_exporter.py:专利数据Excel导出模块
这次采集的专利数据源主要有2个,USPTO(美国专利商标局)、Google Patent(谷歌专利),为了统一管理这两个数据源,系统采用了抽象工厂模式设计,每个数据源都实现了相同的接口,包括:
detect_query_type:检测查询类型:专利号还是关键词
search_across_sources:跨源检索并解析专利
这样设计的好处是,当需要添加新的数据源时,只需要实现这些接口即可,不需要修改主程序的代码,提高了系统的可扩展性。
为了让不同数据源的查询结果能够统一展示,系统定义了一套标准的数据结构。每个专利记录包含以下核心字段:
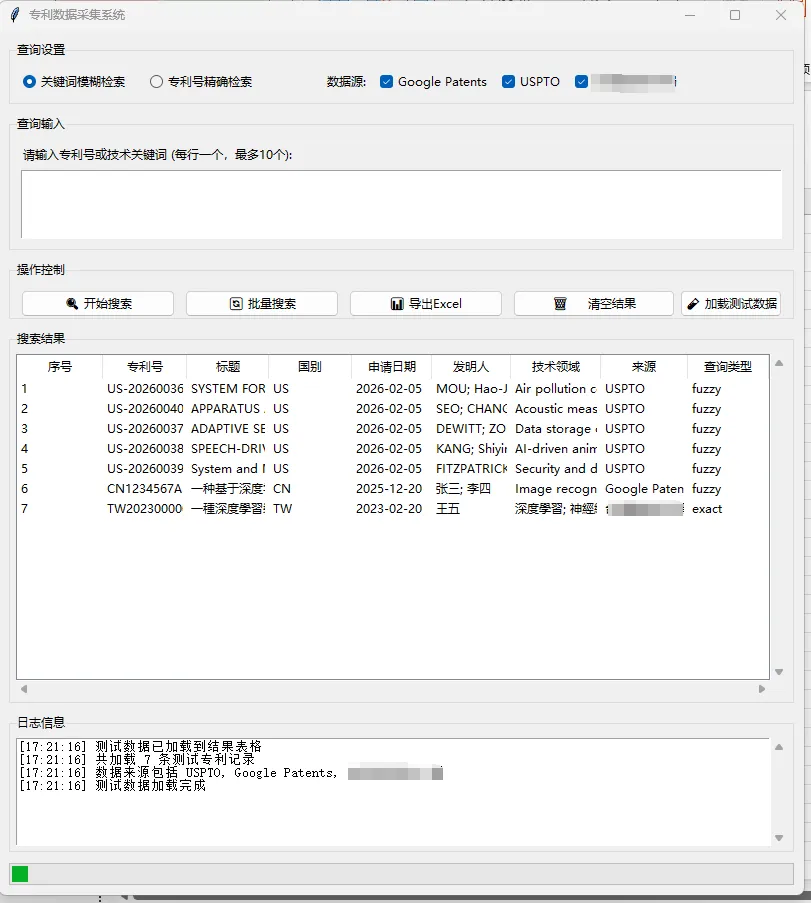
最终实现的功能界面如下:
这个数据结构参考了专利信息的国际标准,应该能够满足大多数应用场景的需求,在数据解析阶段,系统会将从不同数据源获取的原始数据转换为这个标准格式。
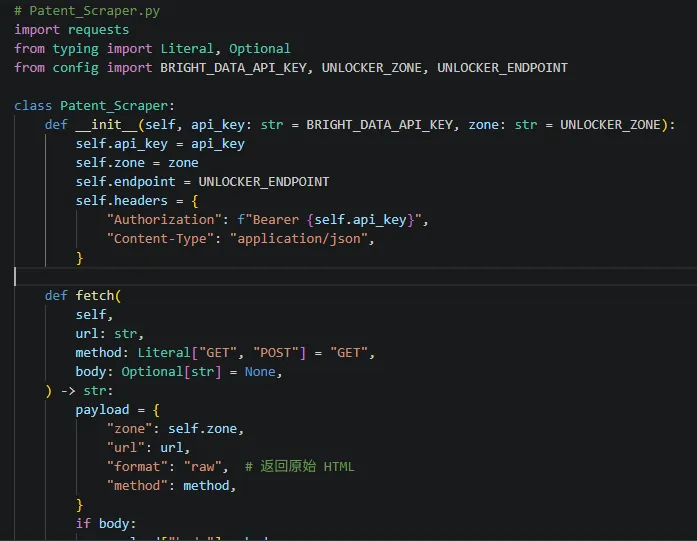
这里面涉及到一个最重要的开发环节是封装Web Unlocker调用,去请求不同站点的网页数据,需要填写之前申请的unlock api key信息,并按照模板开发代码。
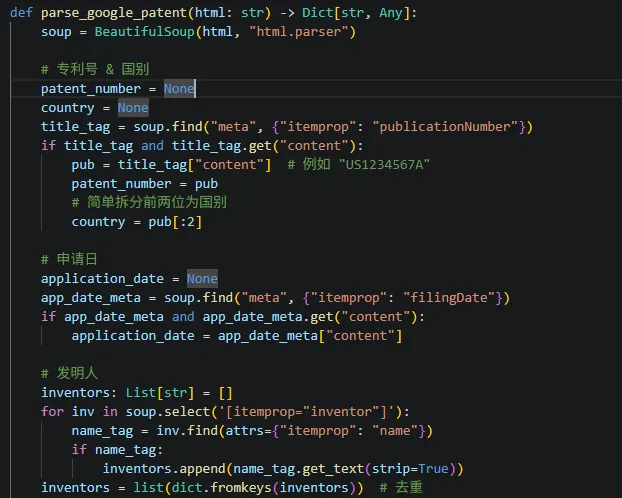
获取网页数据后,再对不同站点的字段信息进行解析,需要你进入开发者界面,根据页面结构做优化。
再开发数据导出功能,使用pandas包来实现。
开发好关键模块后,再开发GUI交互界面,将整个采集的功能和数据集成在系统上。
最后,执行主程序main.py,打开一个GUI程序,输入关键词,进行模糊查询,就能得到结果。
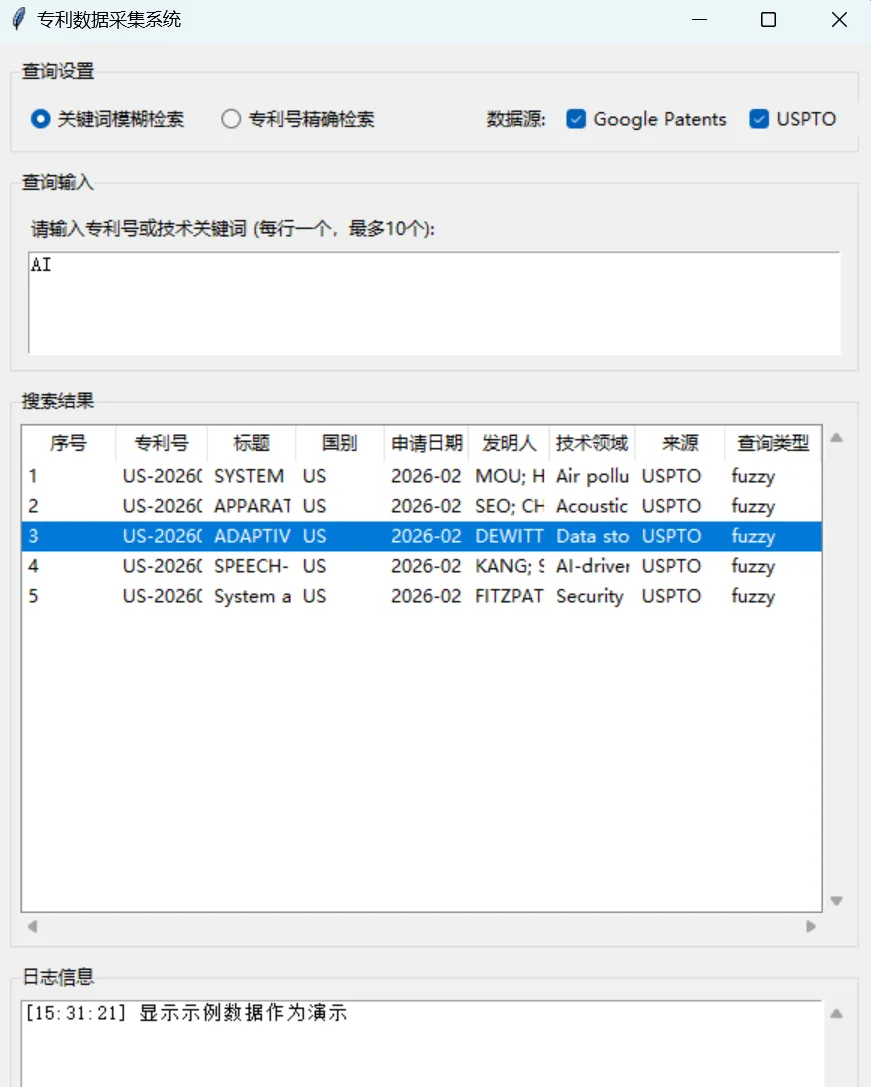
这样就用Python结合亮数据搭建一个完整的数字化应用,将各种专利站点数据集中到一个专利查询系统里,可以批量检索、导出数据,大大节省了时间。