【前言】笔者是一名互联网用户研究员,近期运用「大模型及Python」进行了超长用户对话文本的分析,本文将分享一套经过实战验证的‘Python+大模型’组合方法论,教你如何快速高效处理大规模文本数据。(说明:本次所涉及案例均进行了脱敏处理,只展示部分思路,实操时需根据项目情况灵活调整)
本文结构:
一、运用大模型及Python开展分析的【两种场景说明】
二、【纯Python代码场景】分析:
(一)案例1:合并用户与客服的对话记录
(二)案例2:针对数据处理结果进行描述性统计分析
(三)案例3:裁切AI生成的组合图
三、【Python代码中调用大模型场景】分析**:
(一)完整分析步骤说明:
(二)如何评估大模型打标结果:
一、运用大模型及Python开展分析的【两种场景说明】
| | |
| | 需要调用大模型接口(API)进行处理,Python代码中需要嵌入「系统提示词」 |
| | |
| 结构化调整想要的数据“本身已经有了”,只是格式不对。 | 非结构化转结构化想要的数据“本身没有”,需要模型理解并生成。 |
| • 合并用户与客服的多行对话记录• 批量裁切/处理图片• 问卷数据的交叉统计 | • 给大段文本打标(如不满原因)• 判断打标结果置信度• 提取关键信息如关键原文 |
| 简单线性(代码可能也需调试):明确需求 → 大模型生成Python代码 → 运行 → 核验 | 复杂迭代:运用大模型写系统提示词及代码→大模型初步分析→对比小样本人工打标结果进行「系统提示词调试 」→ 全量跑数 |
| 把需求发给大模型,让它写 Python 代码帮你干活。 | 写好System Prompt,用 Python 批量把数据喂给大模型。 |
二、【纯Python代码场景】分析:
(一)案例1:合并用户与客服的对话记录
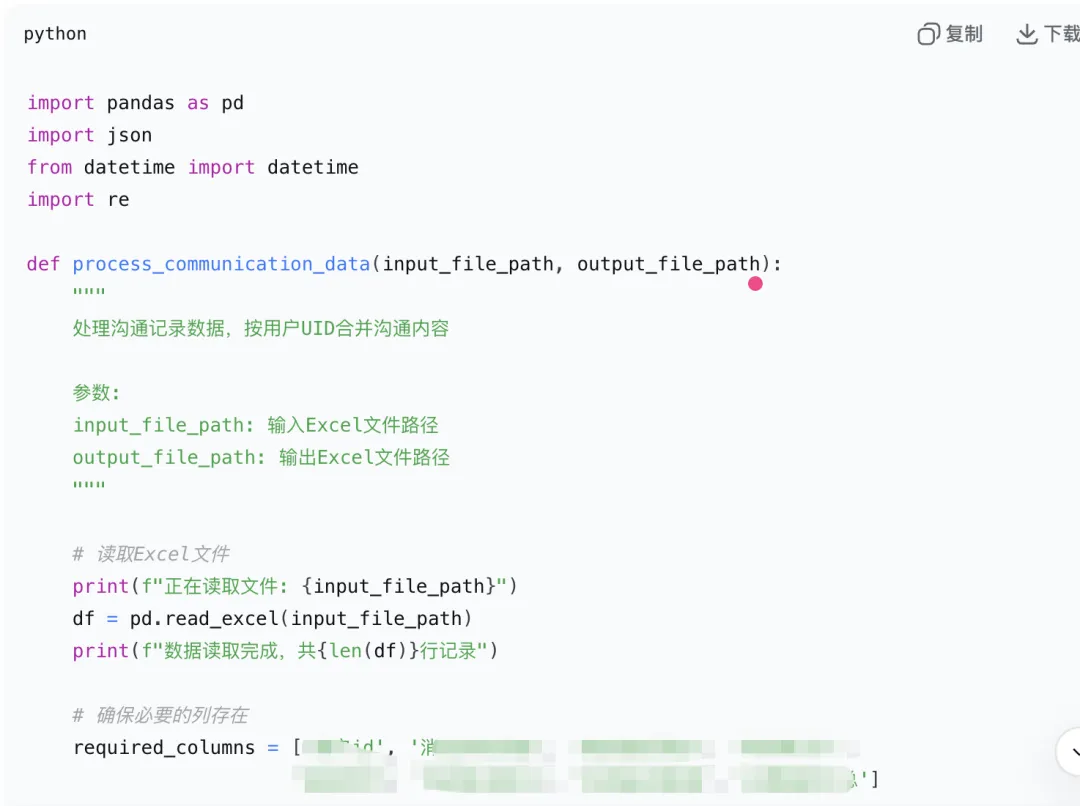
1、【步骤一】明确需求,将需求转化为清晰指令词
你是XX用户研究员,你要使用大模型做【XX调研】,用户通过XX方式会与XX产生对话记录,一个用户会产生多行聊天记录,本次目标需要把一个用户的所有对话记录汇总到一起
表格字段【XX发送人】包括「A、B」两种人,如果【XX发送人】是A,表示字段【消息内容】是A说的;如果【消息发送人】是B,表示字段【消息内容】是B说的
2、【步骤二】大模型根据需求生成代码

3、【步骤三】运行代码
4、【步骤四】代码初步调试
6、【步骤六】若数据不符合需求,继续调试代码
(二)案例2:针对数据处理结果进行描述性统计分析
1、【步骤一】给大模型输入清晰需求指令词
重新运行出结果了,我怎样写代码可以给出以下统计数据
一、两次XX原因
二、不同维度的原因差异
2、【步骤二】大模型根据需求生成代码
3、【步骤三】运行代码
4、【步骤四】可进行数据检验
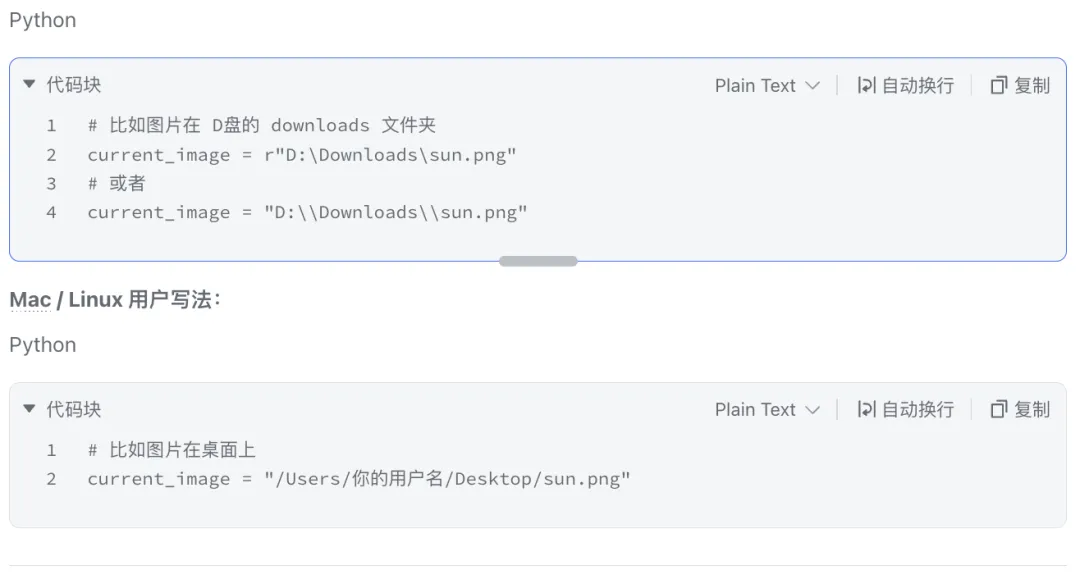
(三)案例3:裁切AI生成的组合图
背景:我让AI生成一个《太阳公公》主题的10页绘本图片,AI会直接生成10张组合图,调试代码后逐步生图也不稳定,我就萌生了让AI裁切图片的想法

1、【步骤一】给大模型输入清晰需求指令词
这个图片用Python拆分成10个独立图形,代码怎么写
2、【步骤二】大模型根据需求生成代码
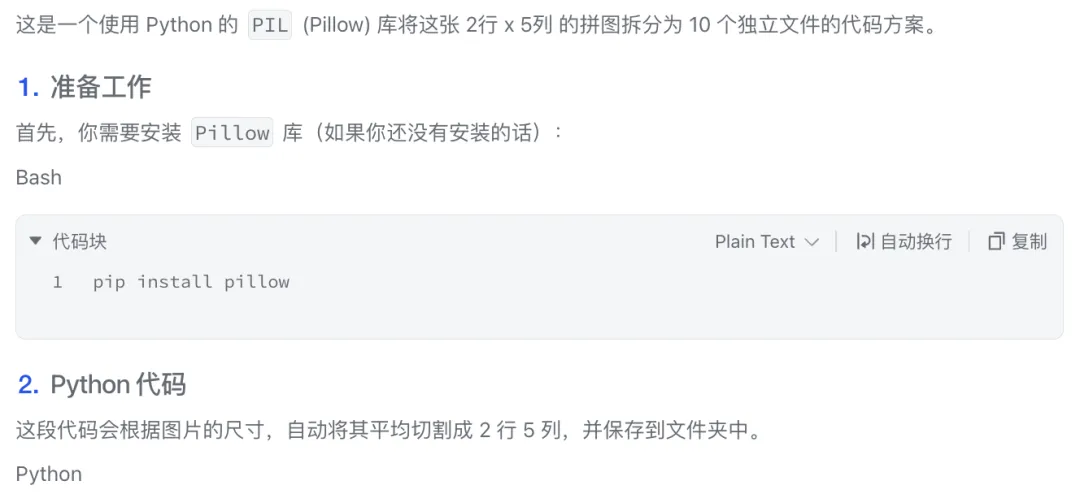
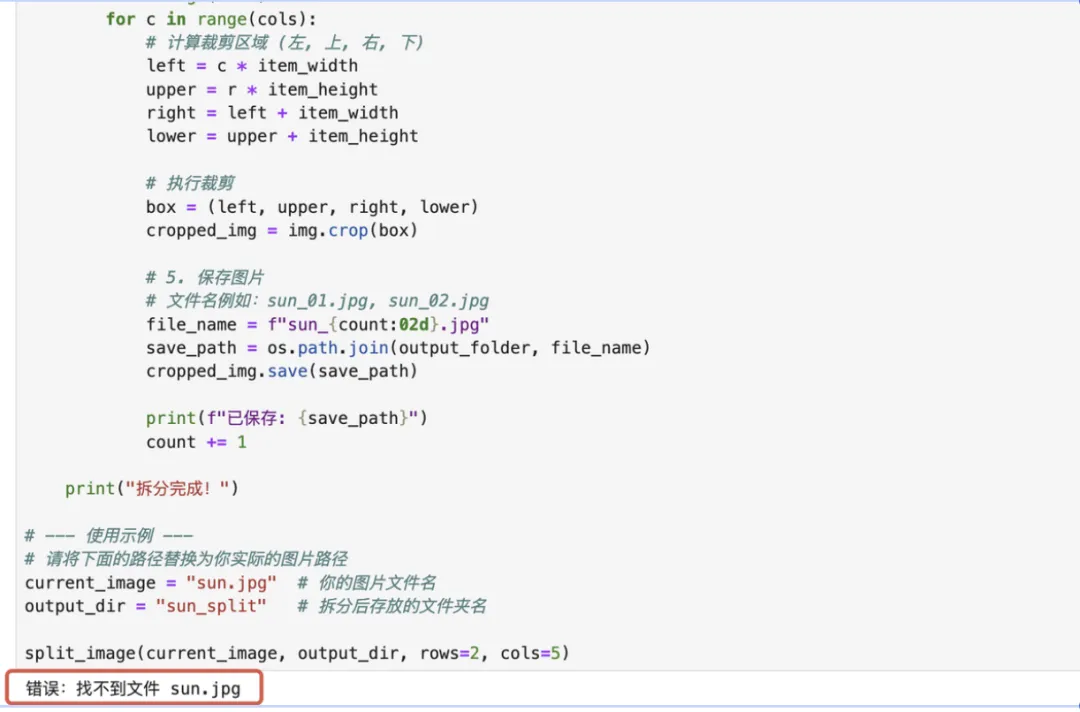
import osfrom PIL import Imagedef split_image(image_path, output_folder, rows=2, cols=5):""" 将图片拆分成 rows * cols 个网格,并保存为独立文件 """# 1. 打开图片if not os.path.exists(image_path): print(f"错误:找不到文件 {image_path}") return img = Image.open(image_path) img_width, img_height = img.size # 2. 计算每个小图的宽度和高度# 注意:这里假设图片是完美对齐的网格。# 如果图片四周有不想要的白边,可以先用 img.crop() 裁剪掉外围 item_width = img_width // cols item_height = img_height // rows # 3. 创建输出文件夹if not os.path.exists(output_folder): os.makedirs(output_folder) print(f"图片尺寸: {img_width}x{img_height}") print(f"单个小图尺寸: {item_width}x{item_height}") print("开始拆分...") # 4. 循环切图 count = 1for r in range(rows): for c in range(cols): # 计算裁剪区域 (左, 上, 右, 下) left = c * item_width upper = r * item_height right = left + item_width lower = upper + item_height # 执行裁剪 box = (left, upper, right, lower) cropped_img = img.crop(box) # 5. 保存图片# 文件名例如:sun_01.jpg, sun_02.jpg file_name = f"sun_{count:02d}.jpg" save_path = os.path.join(output_folder, file_name) cropped_img.save(save_path) print(f"已保存: {save_path}") count += 1 print("拆分完成!")# --- 使用示例 ---# 请将下面的路径替换为你实际的图片路径current_image = "sun.jpg" # 你的图片文件名output_dir = "sun_split" # 拆分后存放的文件夹名split_image(current_image, output_dir, rows=2, cols=5)

3、【步骤三】运行代码
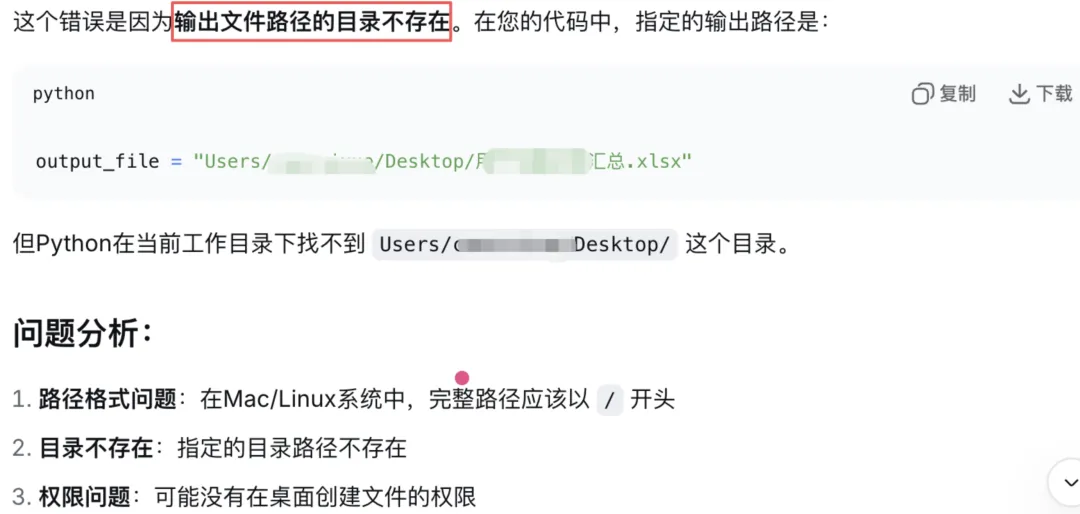
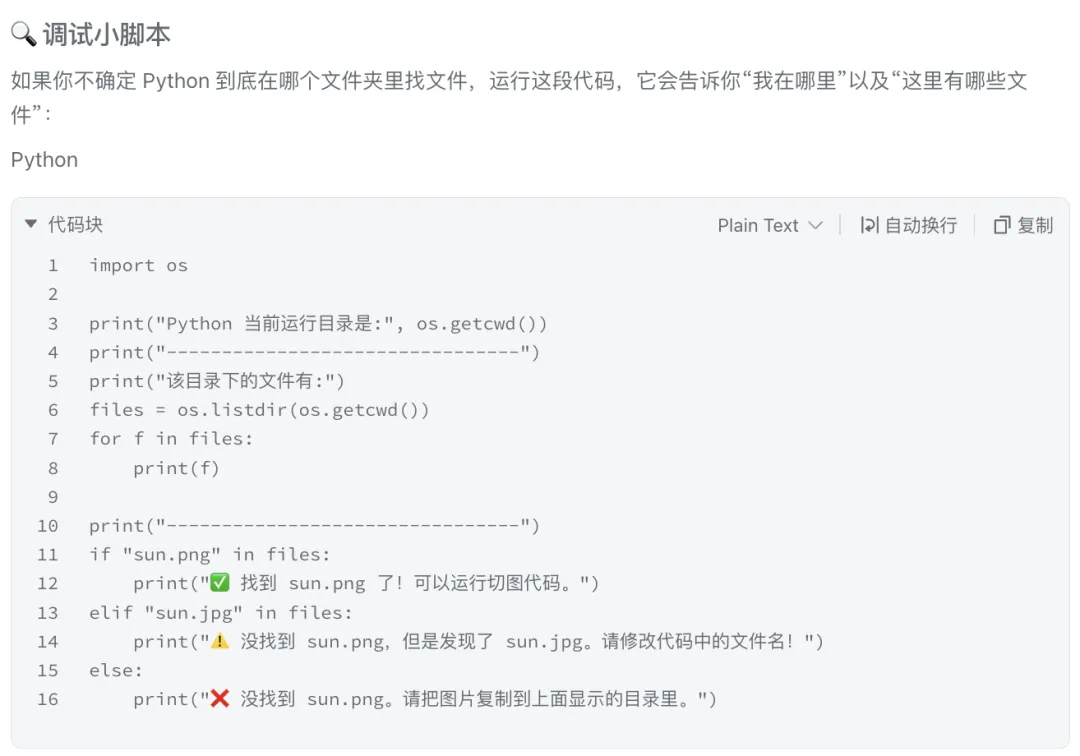
4、【步骤四】调试代码
告诉大模型【错误:找不到文件 sun.png】
大模型输出如下:
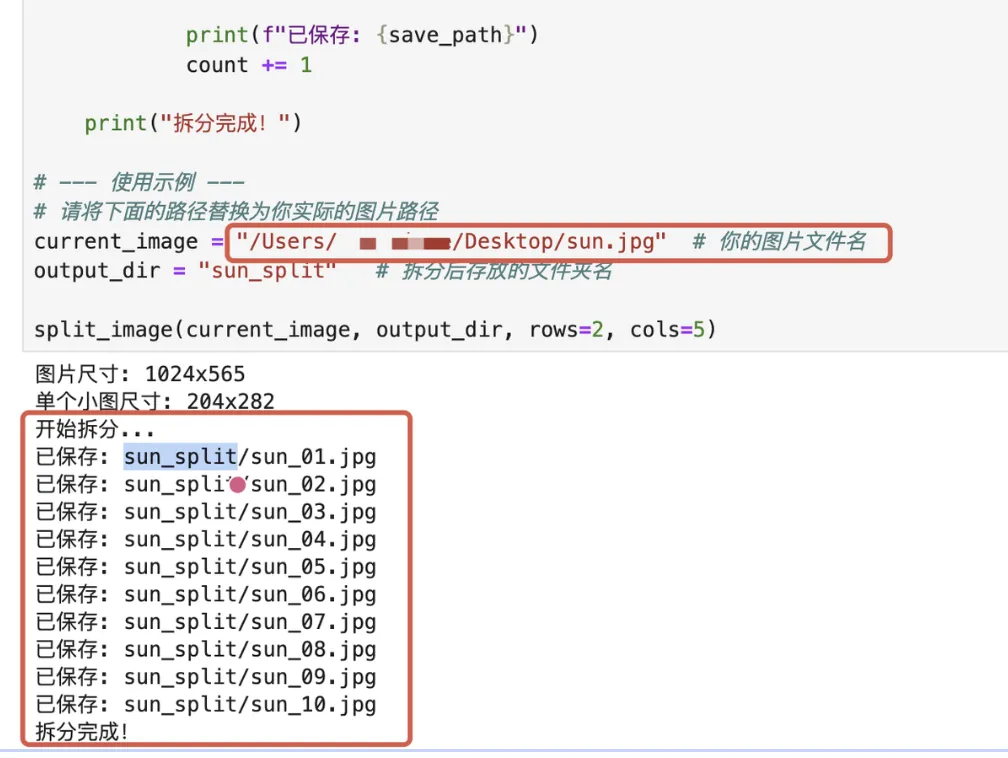
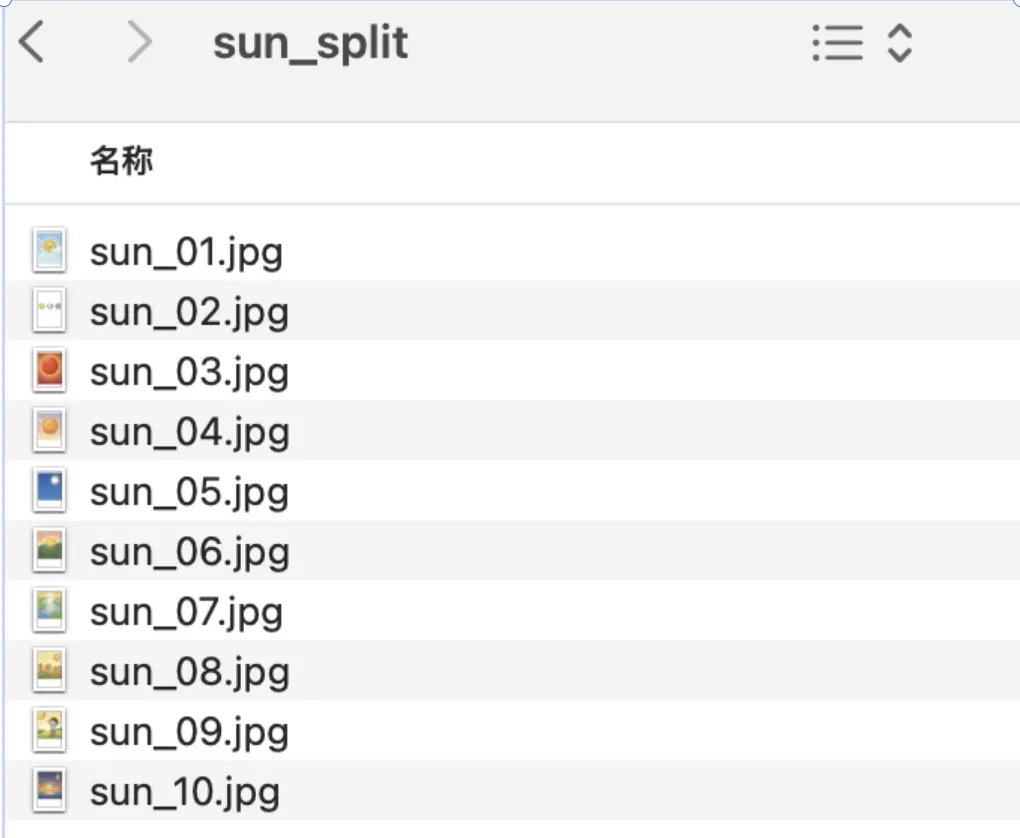
5、【步骤五】使用调试后代码重新运行,超快就输出了要求结果
三、【Python代码中调用大模型场景】分析:
(一)完整分析步骤说明:
核心逻辑:整个过程要经历「明确需求→大模型编写代码及系统提示词 → 少量数据测试(调试系统提示词)→ 全量数据跑数 」的复杂过程。
1、【步骤一】给大模型输入清晰需求指令词
你是XX用户研究专家,你需要使用大模型做【XX原因调研】,你现在有用户与客服的对话记录数据,总共有XX个用户,每行展示一个用户的信息,包含【内容等】几个字段,现在你需要撰写Python代码,通过运行Python代码,在代码中运行【系统提示词】,让大模型对【每名用户的对话内容进行XX原因打标】,请提供相关代码
2、【步骤二】大模型输出初版解决思路及对应代码,含系统提示词(System Prompt)
📝系统提示词(System Prompt) 编写技巧:
Role(角色):你是一名资深用户研究专家...
Context(背景):这是一份用户与客服的对话记录...
Task(任务):请分析用户不满的最主要原因。
Constraints(约束):严格基于事实,不要过度推断等
Reason(原因分类):包含哪些分类
Format(输出):请输出 JSON 格式,包含字段 Reason(原因分类), Evidence(原话证据)。

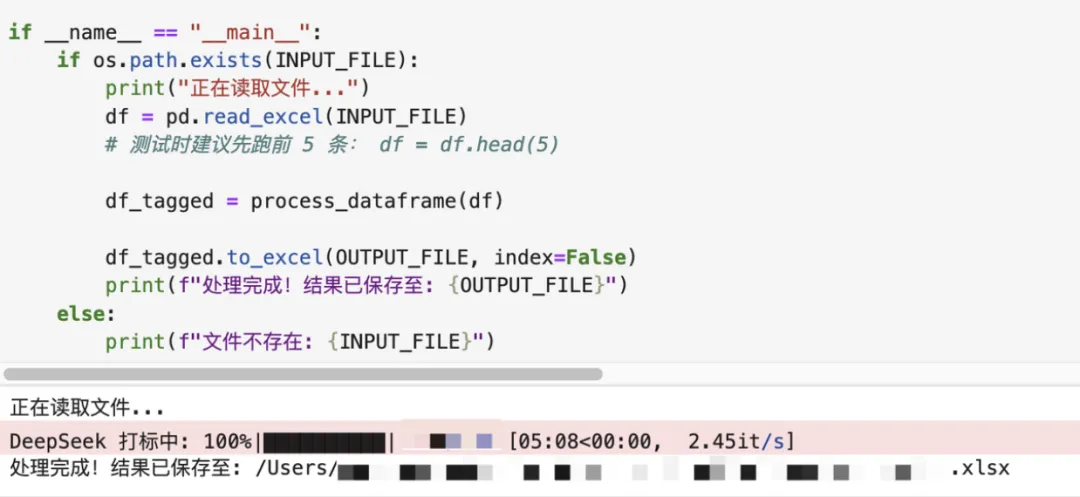
import pandas as pdimport jsonimport osimport timeimport concurrent.futuresfrom tqdm import tqdmfrom openai import OpenAI # 需要安装: pip install openai pandas openpyxl# ================= 配置区域 =================# 请替换为你的 API Key 和 Base URL# 例如使用 DeepSeek, 阿里通义, 或是 OpenAI 原生API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" BASE_URL = "https://api.openai.com/v1" # 如果是用DeepSeek,填 https://api.deepseek.comMODEL_NAME = "gpt-4o" # 或 "deepseek-chat", "qwen-max" 等# 输入和输出文件路径INPUT_FILE = "/Users/.xlsx" # 上一步处理好的文件OUTPUT_FILE = "/Users/.xlsx"# ===========================================# 初始化客户端client = OpenAI(api_key=API_KEY, base_url=BASE_URL)def get_system_prompt():""" 定义系统提示词:这是用户研究专家的核心指令 """return """你是一名XX用户研究专家。你的任务是分析【客服与用户的对话记录】,通过对话内容推断用户的【XX原因】。请仔细阅读用户的对话记录,必须严格按照以下【原因分类】进行打标(只选择最主要的一个原因):【原因分类】:XX【输出格式】:请直接输出一个JSON格式的数据,不要包含Markdown标记(如 ```json),包含以下字段:- "reason_category": "从上述分类中选一个具体的分类名称"- "reason_detail": "用简练的语言概括具体情况(不超过20字)"- "confidence": "高/中/低" (判断你对这个结论的置信度)- "key_quote": "摘录用户表达原因的原话(如果没有原话则留空)"【示例】:用户说:"XX。"输出:{"reason_category": "XX", "reason_detail": "XX", "confidence": "XX", "key_quote": "XX"}"""def analyze_user_reason(text):""" 调用大模型进行分析 """if not text or pd.isna(text) or len(str(text)) < 5: return { "reason_category": "数据缺失/无效", "reason_detail": "对话记录为空或过短", "confidence": "低", "key_quote": "" } # 截断过长的文本,防止超过Token限制(通常取最后4000字符往往包含了XX原因,也可取全量)# 如果是全量分析,建议保留全部,除非报错 conversation_content = str(text)[-5000:] messages = [ {"role": "system", "content": get_system_prompt()}, {"role": "user", "content": f"请分析以下对话记录:\n\n{conversation_content}"} ] try: completion = client.chat.completions.create( model=MODEL_NAME, messages=messages, temperature=0.1, # 低温度保证输出稳定 response_format={"type": "json_object"} # 强制JSON模式(如果是OpenAI或支持该参数的模型) ) result_str = completion.choices[0].message.content # 清洗可能存在的 markdown 符号 result_str = result_str.replace("```json", "").replace("```", "").strip() return json.loads(result_str) except Exception as e: print(f"Error processing: {e}") return { "reason_category": "API调用失败", "reason_detail": str(e), "confidence": "低", "key_quote": "" }def process_dataframe(df):""" 多线程处理DataFrame """ results = [] # 只需要处理有对话内容的行 total_rows = len(df) print(f"开始处理 {total_rows} 条数据,使用模型: {MODEL_NAME}") # 线程池并发处理with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor: # 提交任务# 假设你的列名是 '对话文本' 或 '对话内容',请根据实际文件调整 content_col = '对话文本' if '对话文本' in df.columns else '对话内容'if content_col not in df.columns: print(f"错误:找不到对话内容列,你的列名是: {df.columns}") return df future_to_index = { executor.submit(analyze_user_reason, row[content_col]): index for index, row in df.iterrows() } # 进度条for future in tqdm(concurrent.futures.as_completed(future_to_index), total=total_rows, desc="打标进度"): index = future_to_index[future] try: data = future.result() results.append({ "index": index, "XX一级归因": data.get("reason_category"), "XX详情": data.get("reason_detail"), "置信度": data.get("confidence"), "用户原话": data.get("key_quote") }) except Exception as exc: print(f'Row {index} generated an exception: {exc}') # 将结果合并回原DataFrame result_df = pd.DataFrame(results).set_index("index") final_df = df.join(result_df) return final_dfif __name__ == "__main__": # 1. 读取数据if os.path.exists(INPUT_FILE): print("正在读取文件...") df = pd.read_excel(INPUT_FILE) # 如果是为了测试,可以先只取前10条# df = df.head(10) # 2. 开始打标 df_tagged = process_dataframe(df) # 3. 保存结果 df_tagged.to_excel(OUTPUT_FILE, index=False) print(f"处理完成!结果已保存至: {OUTPUT_FILE}") # 4. 简单打印一下统计结果if "XX一级归因" in df_tagged.columns: print("\n=== 初步归因统计 ===") print(df_tagged["XX一级归因"].value_counts()) else: print(f"文件不存在: {INPUT_FILE}")

3、【步骤三】根据大模型回复及代码运行结果「初步调试代码」
(说明:以下罗列了部分真实调试场景)
1)【场景一】大模型第一次生成的代码中提示「# 截断过长的文本,防止超过Token限制」,因为这个可能会有影响,所以我让大模型修改代码保留全量数据
# 截断过长的文本,防止超过Token限制(通常取最后4000字符往往包含了XX原因,也可取全量)
# 如果是全量分析,建议保留全部,除非报错
conversation_content = str(text)[-5000:]
我需要保留全量文本
def get_system_prompt():""" 针对全量长文本优化的System Prompt """return """你是一名XX用户研究专家。你的任务是分析【XX】,通过对话内容推断XX。### ⚠️ 重要处理原则:1. **全量扫描**:**XX原因可能出现在对话的任何位置**(早期、中期或晚期)。2. **忽略噪音**:记录中可能包含大量XX。请**忽略**这些单向信息,重点寻找**XX发送的回复**。3. **定位关键点**:重点寻找XX等意图的时刻。### 原因分类(Codebook):1. XXX(此处省略)### 输出格式:请直接输出一个JSON格式的数据,不要包含Markdown标记,包含以下字段:- "reason_category": "从上述分类中选一个"- "reason_detail": "简练概括(20字以内)"- "confidence": "高/中/低"- "key_quote": "摘录XX表达原因的原话(非常重要,必须是原话,不要XX的话)""""def analyze_user_reason(text):""" 调用大模型进行全量分析(无截断) 以下代码省略。。。。。
2)【场景二】让大模型生成用DeepSeek v3.2模型处理数据的代码
我计划用DeepSeek v3.2模型,代码应该怎么改
# ================= 配置区域 (DeepSeek 版本) =================# 1. API Key: 请前往 https://platform.deepseek.com/api_keys 申请# 格式通常是以 sk- 开头的字符串API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" # 2. Base URL: DeepSeek 官方兼容接口地址 (注意不要写错)BASE_URL = "https://api.deepseek.com"# 3. 模型名称: # DeepSeek V3 模型的标准 API 名称是 "deepseek-chat"# (DeepSeek 官方目前没有 v3.2 这个特定名称,通常 deepseek-chat 指向的就是最新的 V3)MODEL_NAME = "deepseek-chat" # ==========================================================
3)【场景三】大模型输出原文太简单,继续调试「系统提示词」
我的代码是这样的,目前有一个问题,生成的用户原话太简单了,生成原话这块是否可以扩展
# 修改前:# - "key_quote": "摘录XX表达原因的原话"# 修改后(优化版):def get_system_prompt():"""定义系统提示词 - 优化原话提取版"""return """你是一名XX用户研究专家。你的任务是分析XX,通过对话内容推断XX原因。# 背景(省略)# 处理原则:1. **全量扫描**:原因可能出现在对话的任何位置。2. **忽略噪音**:忽略单向通知,重点寻找**XX发送的回复**。3. **推断与证据**:必须基于事实,不要过度猜测。# 原因分类 Codebook:(此处保持你原有的分类列表,此处省略以节省篇幅...)# ⚠️ 关键指令:关于【用户原话提取】的要求1. **完整性**:不要只摘录几个字。请摘录包含上下文的完整句子,甚至是连续的2-3句话,以便还原当时的语境。2. **多点证据**:如果用户在不同时间点多次提到了原因,请将这些原话拼接在一起,中间用“ || ”隔开。3. **第一人称**:必须是原话,严禁自己总结或改写。4. **对话还原**:如果原因是基于双方对话产生的(例如A问“是觉得难吗?”,B回“对”),请把A的问题也一并摘录,格式为:[A:...] [B:...]。# 输出格式:请直接输出一个JSON格式的数据,不要包含Markdown标记,包含以下字段:- "reason_category": "从上述分类中选一个"- "reason_detail": "简练概括(20字以内)"- "confidence": "高/中/低"- "key_quote": "这里放入提取的详细原话,长度不限,越详细越好""""
4、【步骤四】少量数据测试(Few-Shot Testing),结合人工打标结果,逐步优化直到确认系统提示词(核心是原则、分类)
1)【场景一】打标涉及分类「没有历史调研积累时」
| | |
| - 以人工打标结果作为“系统提示词分类”的基础,通过对比人工与大模型的差异,不断优化提示词。
| - 让大模型先针对「少量样本探索打标」,人工针对同样数量样本进行打标,根据二者差异反向优化提示词。
|
| - 有时间采取“小步快跑”策略,分多轮进行迭代,确保每一次优化都有据可依
| |
| - 确保了 Prompt 的分类基础是经过人工深思熟虑的。
| |
| - 人工打标的样本要尽量覆盖到每一个分类,确保系统提示词分类的基础完整性。
| - 初始提示词设置要相对宽泛(如要求输出一级/二级分类),给模型发挥空间。
|
| - 人工精细打标 30 个样本→大模型跑同样 30 个→对比差异 →调整 Prompt(补充分类/规则/说明/示例)。
- 人工再增加 30 个(共 60 个)→大模型跑同样60 个→对比差异→再次微调 Prompt(补充分类/规则/说明/示例)。
- 人工再增加 40 个(共 100 个)→大模型跑这 100 个→ 计算准确率/召回率 →若达标则全量跑数,若不达标继续优化。
| - 抽选 100 个样本,设置宽泛的系统提示词(例如:“请输出一级和二级分类,不限类别”)→大模型优先打标。
- 人工审查这 100 个样本的 AI 结果(也可以人工单独打标,先不看大模型结果)→发现 AI 的错误或亮点→ 确立最终的编码分类→调整 Prompt(补充分类/规则/说明/示例)。
- 使用优化后的 Prompt,重新跑这 100 个样本 →计算准确率/召回率 →若达标则全量跑数,若不达标继续优化。
|
2)【场景二】打标涉及分类「有历史调研积累时」,可直接复用编码分类
| |
| - 直接复用已验证过的“系统提示词”和“编程分类”,让大模型先跑一批数据,人工采用**“盲测”**方式进行验证,重点评估历史标准是否适配新数据。
|
| - 相似业务迁移:例如业务 A 和业务 B 模式高度相似,可直接复用业务 A 的分类体系。
- 长期追踪调研:针对同一个项目进行间隔(如月度/季度)分析时,直接沿用上期的分类标准。
|
| 步骤 ①:大模型预跑 (Pre-run) • 使用历史积累的提示词,让大模型针对新数据进行打标。💡 避坑指南:建议先跑 100-200 条样本作为测试集。虽然可以直接跑全量,但在未确定历史提示词是否“水土不服”之前,全量跑数存在浪费 Token 费用的风险。步骤 ②:随机抽样 (Random Sampling) • 人工从大模型的打标结果中,随机抽取 50-100 条数据作为“验证集”。步骤 ③:盲测打标 (Blind Labeling) • 人工在不看大模型打标结果的前提下(避免产生先入为主的偏见),依据业务标准对这 50-100 条数据进行打标。步骤 ④:一致性比对 (Cross-Check) • 将“人工归因”与“大模型归因”进行比对,计算一致性(准确率/召回率)。步骤 ⑤:迭代决策 (Iteration)• 若一致性高:说明历史标准依然适用,可直接全量跑数。• 若一致性低:分析差异原因(是出现了新场景?还是旧规则失效?),据此优化提示词。 |
5、【步骤五】全量数据跑数
(二)如何评估大模型打标结果:
1、准确率&召回率介绍:
| | |
| | |
| | |
| | |
| | (正确分析出的目标数量) / (所有实际存在的目标数量) |
| 模型标记了 100 个用户是“嫌贵”。经人工核查,只有 80 个是真的嫌贵,20 个搞错了。👉 准确率 = 80% | 实际上全量数据里有 100 个用户是“嫌贵”,模型只把其中 60 个标记出来了,漏掉了 40 个。👉 召回率 = 60% |
| 你抽查了 100 个人,AI 有 80 个人的归因跟你的判断一模一样,👉整体准确率= 80% | 100个抽样数据中,你成功分析原因有60个,AI成功分析原因仅有50个👉整体召回率就是50/60=83% |
| - 你会看到很多错误的数据,导致决策偏差(例如误以为某问题很严重,其实是模型乱标的)。
| - 你会错过关键问题(例如实际上很多人因为“XX”不满,但模型没识别出来,导致你以为XX没问题)。
|
| 衡量大模型在根据提示词进行筛选、判断或生成时,其输出结果的精确程度。高准确率意味着模型返回的答案中无关或错误的信息较少,用户对其信任度高。 | 衡量大模型在根据提示词进行检索、归纳或提取时,其发现全部相关信息的完备程度。高召回率意味着模型漏掉的关键信息较少,分析结果更全面。 |
| 双高 (F1-Score 高):既不瞎报,也不漏报。 | 双高 (F1-Score 高):既不瞎报,也不漏报。 |
2、准确率&召回率理想目标:
3、【准确率、召回率】不同数值表现的含义及解法:
【后记】以上是我基于真实实战经验,整理的运用「大模型及Python」进行非结构化文本分析的方法论,若有其他建议或问题,欢迎留言讨论。