2python之数据整合及分科室研究
- 2026-07-04 11:09:17
写在前面的话
有点奇怪。昨天早晨,侄子在,老妈炒了几个菜。本来是一个正常的早饭,但老爸卡卡喝糊涂,不吃菜,我说,爸你吃点吧,趁热。老爸说,不吃,我喝稀饭就行。我说,你吃点吧,侄子一个人也吃不了,现在不是从先,不够吃的。老爸说:真不吃,早上吃点清淡的挺好。我不再劝了,老爸像我奶一样,越劝越不吃。我没想通,每天叨菜,侄子来了,反而不吃了。前天也是,早上一直催我接侄子,7点多就出发了,中间路过一个服务区,我说,去上个厕所吧,还有四十分钟就到了。老爸说,不用了,赶紧走吧。我说,我去一下吧,有点忍不住了。到了服务区,让老爸去,他不去。我上完,抽支烟,我说,爸出来透透气,休息一下。老爸说,不用不用,我不下去了。安全带扣的板板正正。我有点气又有点想笑,有必要这样吗,晚接十分八分有什么呢?
[318]--------底部有张生活照片
【关键词】python、数据整合、分科室、专家系统
一、python相关
1.数据整合
描述:现在专家系统返回的数据与正常数据不太一样,需要整合一下。
开工:
第一步:专家系统数据
20241223周一时间段:1551-1600现在数据出来很慢,截图如下:

图2a-1
注:从截图看出,用时将近4分钟。还有个奇怪的现象是:出了疾病问诊后,又出现了一行,【根据您的描述】,这一行不知从哪来的,需要追踪一下。
a.追踪时间慢
20241223周一时间段:1640-1700现在的流程是:用户提交了问题,把聊天记录集合起来,交给知识库抽取,之后,再提交通义千问进行回答。其中知识库提取耗费了不少时间,现在和龙哥沟通后,直接拿聊天记录问通义千问,不再时行知识库抽取,这样会节省时间。按照这个思路做,直接问通义千问,龙哥给的参考事例如下:
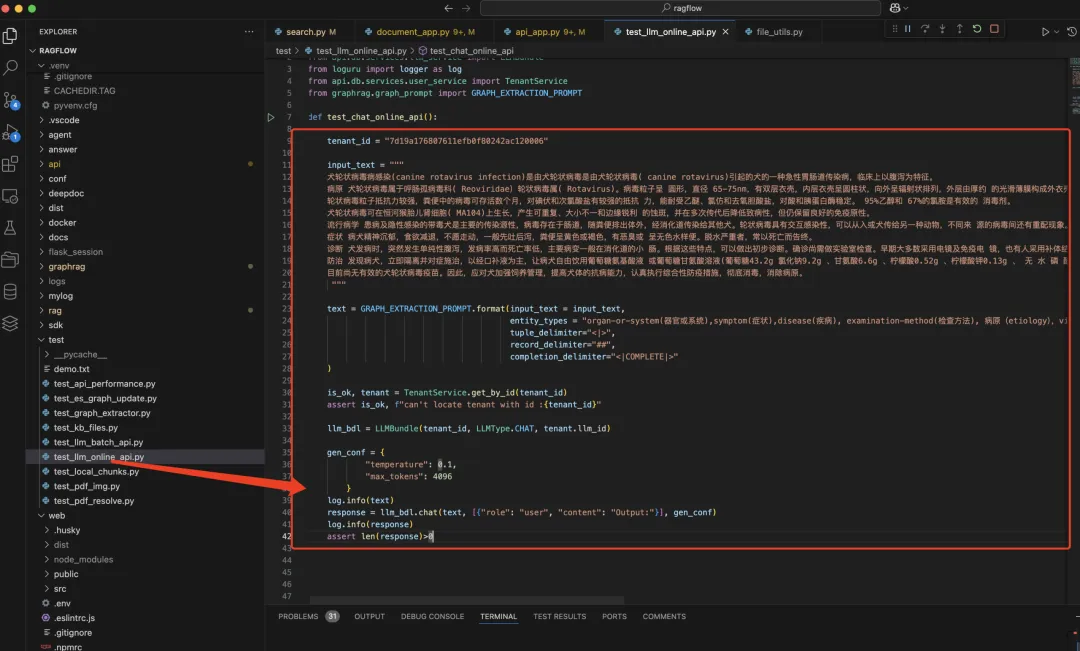
图2a-2
注:接下来,按照这个思路,找一下在哪里提交请求的通义提问。
b.找通义千问
20241223周一时间段:1812-182020241223周一时间段:1900-1920
看了下龙哥的测试用例,最主要的是有个LLBMbundle方法,思路是把之前方法复制一份,把抽取的部分去掉,就可以,写新方法如下:
先改一部分,原代码如下:
answer = chat_mdl.chat(prompt, msg[1:], gen_conf) chat_logger.info("User: {}|Assistant: {}".format( msg[-1]["content"], answer)) res = decorate_answer(answer) res["audio_binary"] = tts(tts_mdl, answer) yield res
注:这个要改chat_mdl.chat(prompt中的prompt,追踪一下prompt怎么生成的,并且把和prompt相关的全注释掉。
现在代码如下:
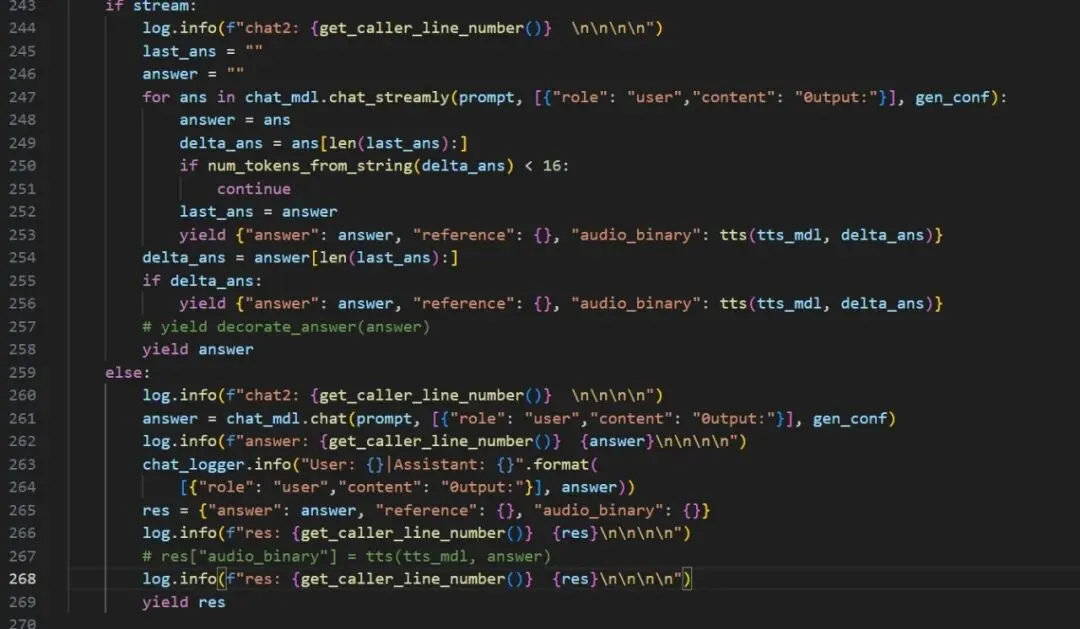
图2a-3
注:运行结果如下:
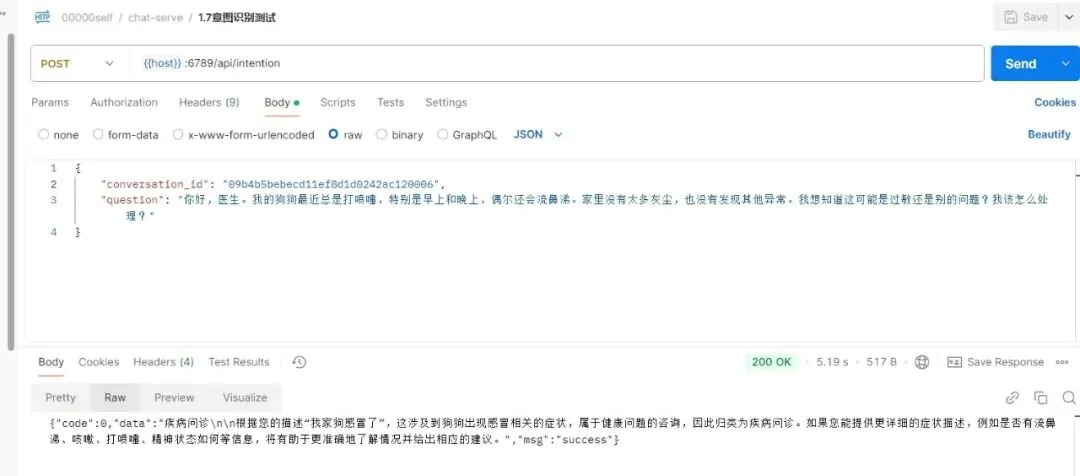
图2a-4
注:直接问通义千问进行意图识别,返回的是一段,不是我列出的几个,明天见面龙哥帮着看看吧。速度倒是提上来了(5秒)。改下提示词试试。
c.修改提示词
20241224周二时间段:0934-0940修改提示词如下:
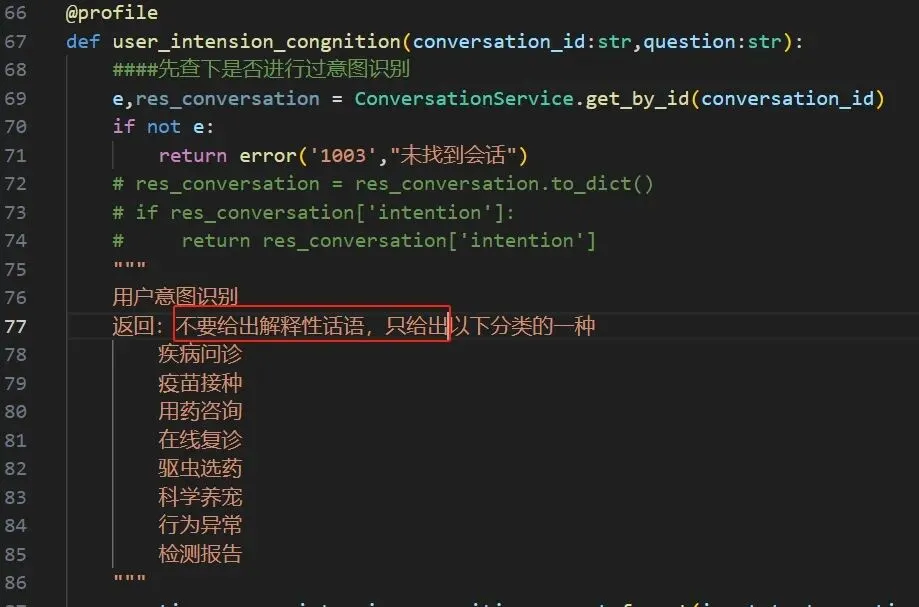
图2a-5
注:看下运行效果,效果没啥改变。用截取的方式做一下。修改程序如下:
answer = answer[0:4] answer = answer.strip()
注:这个效果就非常好了,如下:
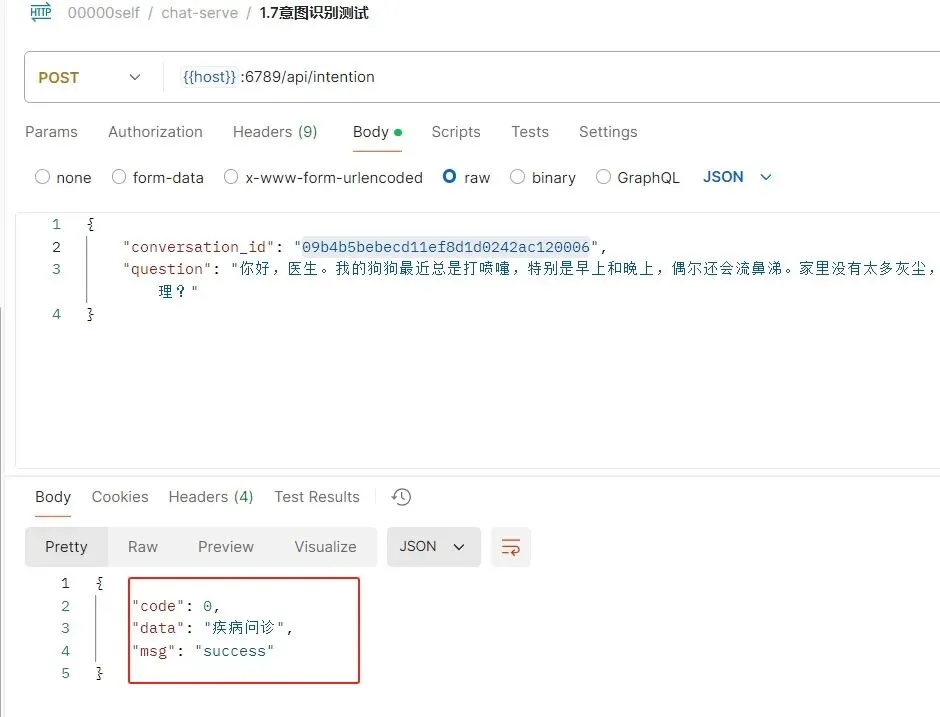
图2a-6
注:这个至此完成,接下来,要看数据存没存数据库。
d.存数据库
20241224周二时间段:1012-1020看下上述数据存没存数据库,截图如下:
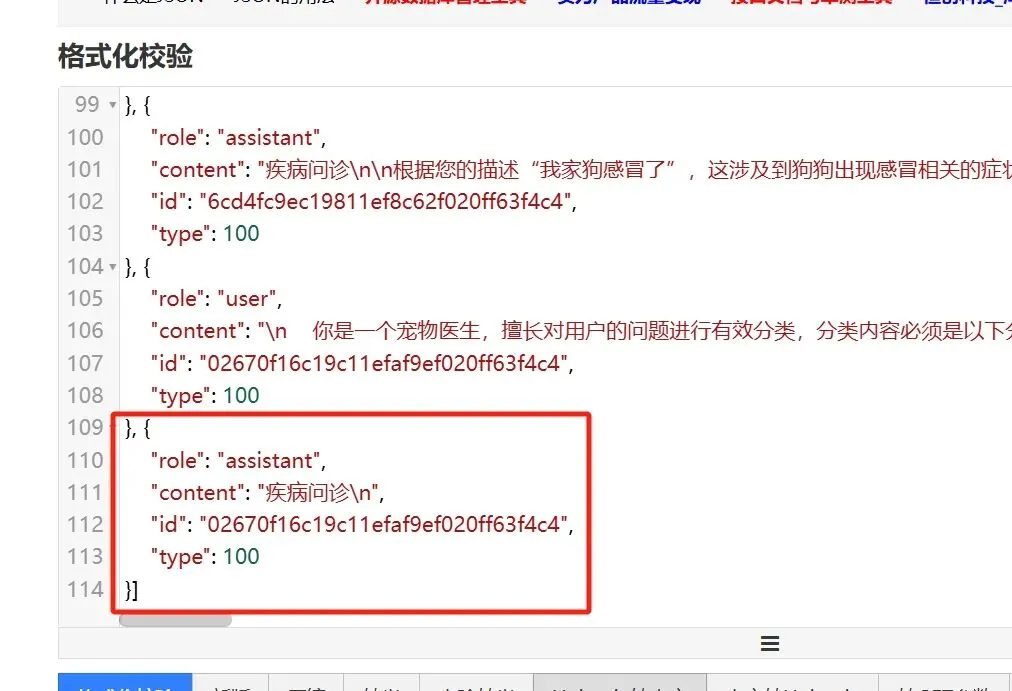
图2a-7
注:看了下,是存了的,接下来,就做分科室了,也是用新写的阉割函数。
第二步:分科室
a.修改程序
20241224周二时间段:1017-102020241224周二时间段:1020-1040
调用新写的函数,用postman进行测试,看了下要给出的结果,如下:
""" 分诊医生分诊断 返回诊断科室:消化道,呼吸道、皮肤、五官等 """
注:就是说不像上面固定的4个字,所以,要进行匹配,修改如下:
answer = chat_mdl.chat(prompt, [{"role": "user","content": "0utput:"}], gen_conf) answer = answer.split('\n\n', 1)[0] answer = answer.strip()
注:使用【answer = answer.split('\n\n', 1)[0]】,可以匹配\n\n之前的,不限定字符数量。
遇到问题了, 它还返回疫病问诊,而不是分科,看下是不是提示词没过来。
b.追踪提示词
20241224周二时间段:1020-104020241224周二时间段:1040-110020241224周二时间段:1100-1120
现在返回的不太对,返回如下:
"你好,看起来在提问部分没有正确输入问题内容。请提供具体关于你的宠物的健康问题描述,以便我能进行正确的分类。"注:这个不知哪里错了,追踪一下。
c.提示词有特殊字符
20241224周二时间段:1511-1520换了下问题,终于可以了,如下:
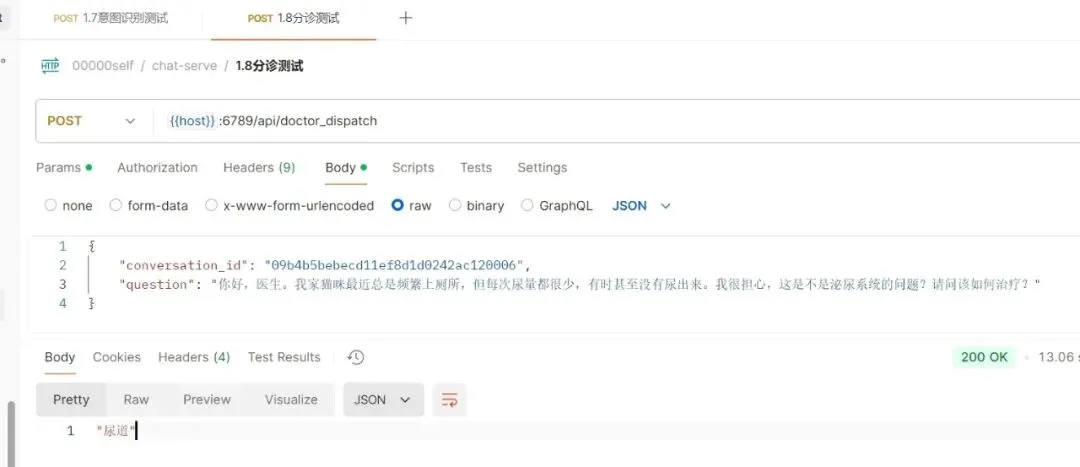
图2a-8
注:接下来,搞一下专家提问。
第三步:专家测试
20241224周二时间段:1518-1520专家测试要把前两步连起来,并由专科医生大模型进行回答。现在输出有点小问题,输出是这样的,如下:
看起来您复制的格式可能有点小问题,根据您的描述,我将直接进行分类。对于您提到的狗狗总是打喷嚏,特别是在早上和晚上,偶尔还会流鼻涕的情况,这属于:呼吸道如果您有更多关于宠物健康的问题或者需要进一步的帮助,请随时告诉我。
注:就是说要找的【呼吸道】不是在开头,而是在中间,截取时,要进行优化了。优化的思路是:多传个参数ask_type 0:一般询句 1:意图识别 2分科室,根据询问类型进行匹配,前期先匹配所有的,修改代码如下:
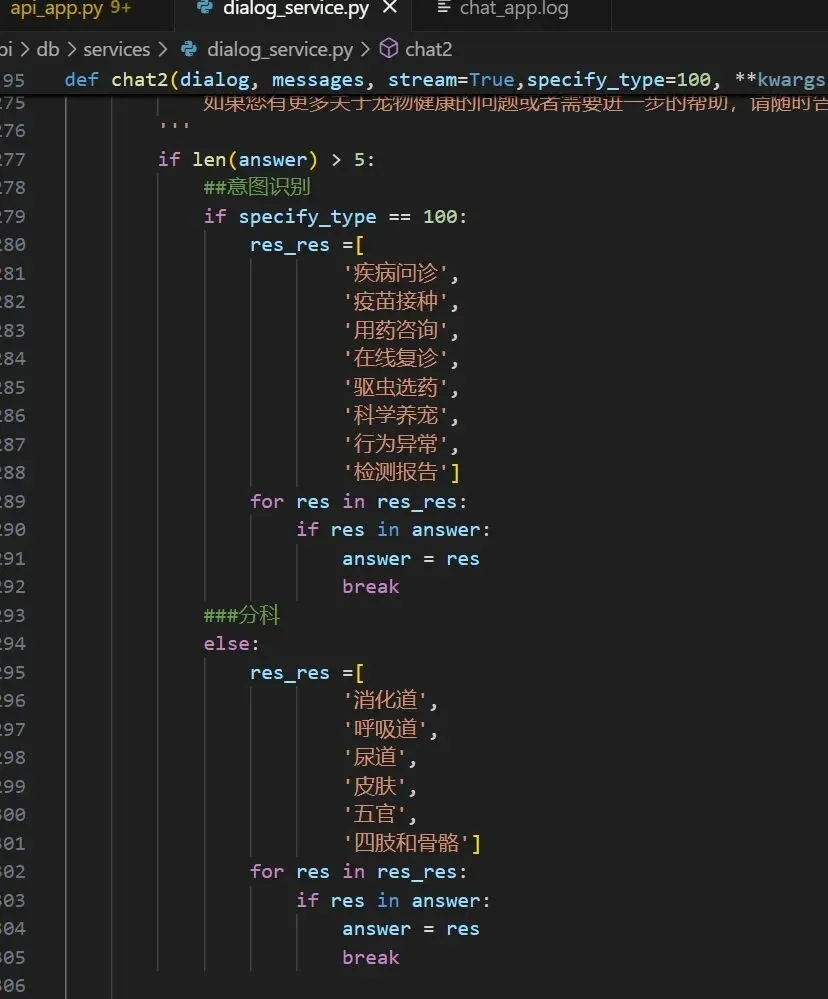
图2a-9
注:这是利用原来的specify_type做的分类,还可以,测试下效果。效果测试不好,因为程序有问题,修改如下:
sub_answer = answer.split('\n\n', 1)[0] sub_answer = sub_answer.strip() log.info(f"sub_answer: {get_caller_line_number()} {sub_answer}\n\n\n\n") ####处理返回 '''【看起来您复制的格式可能有点小问题,根据您的描述,我将直接进行分类。 对于您提到的狗狗总是打喷嚏,特别是在早上和晚上,偶尔还会流鼻涕的情况,这属于: 呼吸道 如果您有更多关于宠物健康的问题或者需要进一步的帮助,请随时告诉我。】 ''' if len(sub_answer) > 5: ##意图识别 if specify_type == 100: res_res =[ '疾病问诊', '疫苗接种', '用药咨询', '在线复诊', '驱虫选药', '科学养宠', '行为异常', '检测报告'] for res in res_res: if res in answer: answer = res break ###分科 else: res_res =[ '消化道', '呼吸道', '尿道', '皮肤', '五官', '四肢和骨骼'] for res in res_res: if res in answer: answer = res break else: answer = sub_answer
注:这个里面要引入sub_answer的概念,因为如果answer被截断了,再匹配也匹配不上了。
2.python教程相关
描述:把python教程见缝插针的过一遍,有用的写到题库里。
开工:
第一步:python中的多行
20241224周二时间段:1040-110020241224周二时间段:1100-1120
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠 ** 来实现多行语句,例如:
total = item_one + \ item_two + \ item_three
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠 **,例如:
total = ['item_one', 'item_two', 'item_three', 'item_four', 'item_five']
二、wp相关
三、生活照片
拍摄于2023年12月9日,8:11:07,在家里给二宝拍的,当时二宝一岁两个月。接侄子的后续是:我回到车上,我抽了两口就扔了,当一个人在焦急的等你时,你还怎么抽的下去。我发动车子,在行走的过程中,我看老爸时不时动一下,我知道他想上厕所了,但没有服务区了,我真是理解不了,还有就是到侄子学校门口,侄子联系不上,我说,我们先在车里等吧,联系上了,咱们再从车里出来,老爸坚持在门口等,让我有点心疼,也有点无奈,虽说不理解,但尊重吧,不知我老了是不是这个状态。

图2c-1
《本文完》

