一、XDP 技术概览
1.1 XDP 诞生的技术背景
现在高速网络10G、40G甚至100G网卡随处可见,但很多人都会遇到一个问题:带宽上去了,Linux系统处理数据的速度却没跟上。核心原因就是Linux内核协议栈“力不从心”——它的包处理逻辑太繁琐,就像一条狭窄的小巷,就算有再多数据,也只能慢慢挤过去,直接成了网络性能的瓶颈。
为了解决这个问题,内核旁路(Kernel Bypass)技术就应运而生了。说通俗点,就是给数据包开“绿色通道”,跳过复杂的内核协议栈,直接让用户程序来处理,少走弯路,速度自然就提上来了。
而XDP,就是Linux内核旁路技术里的“尖子生”。比起另一种常见的DPDK,XDP最大的优势是贴合Linux原生生态,不用额外搞复杂的环境适配,相当于给Linux量身定做的高性能工具,上手和部署都更方便,这也是它近几年越来越火的原因。
1.2 到底什么是 XDP?
XDP,全称 eXpress Data Path,即快速数据路径,是基于 eBPF(Extended Berkeley Packet Filter)机制的一项 Linux 内核技术。它就像是一位技艺高超的网络数据处理大师,能够在内核空间中对数据包进行高性能的处理和转发。通过巧妙地利用 eBPF 的强大功能,XDP 可以在数据包到达网络驱动层的第一时间,就对其进行针对性的高速处理。
XDP 为用户提供了一个极为灵活的编程接口,这就好比给了开发者一个充满无限可能的 “网络实验室”。在这个 “实验室” 里,开发者可以根据实际需求,自由地编写各种自定义的网络功能。无论是对数据包进行精确的过滤,还是实现高效的转发策略,又或是进行复杂的网络流量监控与分析,XDP 都能轻松胜任。与传统的用户空间数据包处理方式相比,XDP 就像是一位短跑冠军,能够显著降低数据包处理的延迟,同时,还能像一位节能大师一样,降低 CPU 的占用率,使得系统资源得到更合理的利用。
1.3 XDP 核心价值与适用场景
XDP 的核心价值主要体现在三个关键方面。其一,它能够大幅提升网络性能。在面对海量的网络数据时,XDP 凭借其高效的处理机制,能够让数据快速地在网络中传输,就像拓宽了网络的 “高速公路”,避免了数据拥堵,大大提高了数据的传输效率。其二,XDP 在降低延迟方面表现卓越。它能够让数据包在最短的时间内得到处理和转发,对于那些对时间要求极高的应用场景,如实时通信、在线游戏等,XDP 的低延迟特性能够为用户带来更加流畅的体验,就像为用户消除了网络中的 “卡顿障碍”。其三,XDP 还能有效地降低 CPU 占用。它能够合理地分配系统资源,让 CPU 从繁重的网络数据包处理任务中解放出来,去处理其他更重要的工作,从而提高整个系统的运行效率。
基于这三点,XDP的应用场景特别广:比如做DDoS防御,能快速识别恶意流量并丢弃,相当于给服务器装了个“快速防火墙”;日常的防火墙、负载均衡,用XDP也能提升效率;还有数据中心的流量调度,用XDP能轻松应对爆发式的流量高峰。
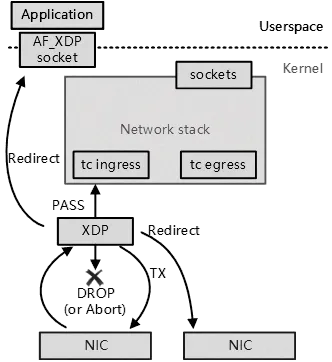
二、AF_XDP 核心工作原理
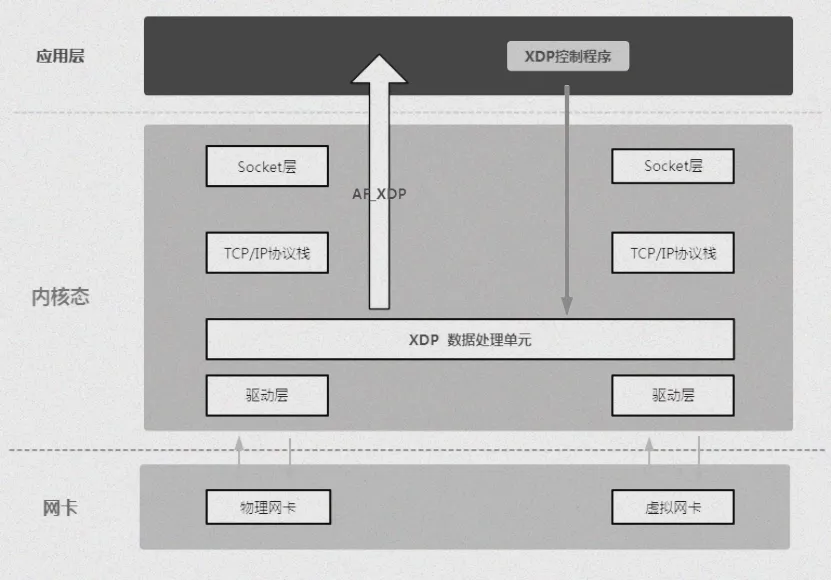
在深入了解 AF_XDP 的核心工作原理之前,先明确它在 XDP 技术体系中的关键地位。AF_XDP,作为 XDP 技术的一种重要应用场景,是一种专门为实现高性能网络数据处理而设计的 Linux socket。它就像是一座桥梁,架设在用户程序与网络数据之间,通过巧妙的设计,实现了数据包的高效收发。与传统的 socket 不同,AF_XDP 不走寻常路,它无需经过复杂繁琐的内核协议栈,大大减少了数据处理的中间环节,从而显著提升了网络性能 。
2.1 AF_XDP 整体架构设计
AF_XDP 的整体架构设计精巧而独特,它需要与 XDP 程序紧密配合,才能完美地完成数据包的收发任务。XDP 程序就像是一个智能的网络数据筛选器,它会依据以太网帧的关键信息,如 MAC 地址、五元组信息等,对数据包进行精准的过滤和重定向。只有经过 XDP 程序筛选和处理后的数据包,才会被传递给 AF_XDP 进行后续的处理。
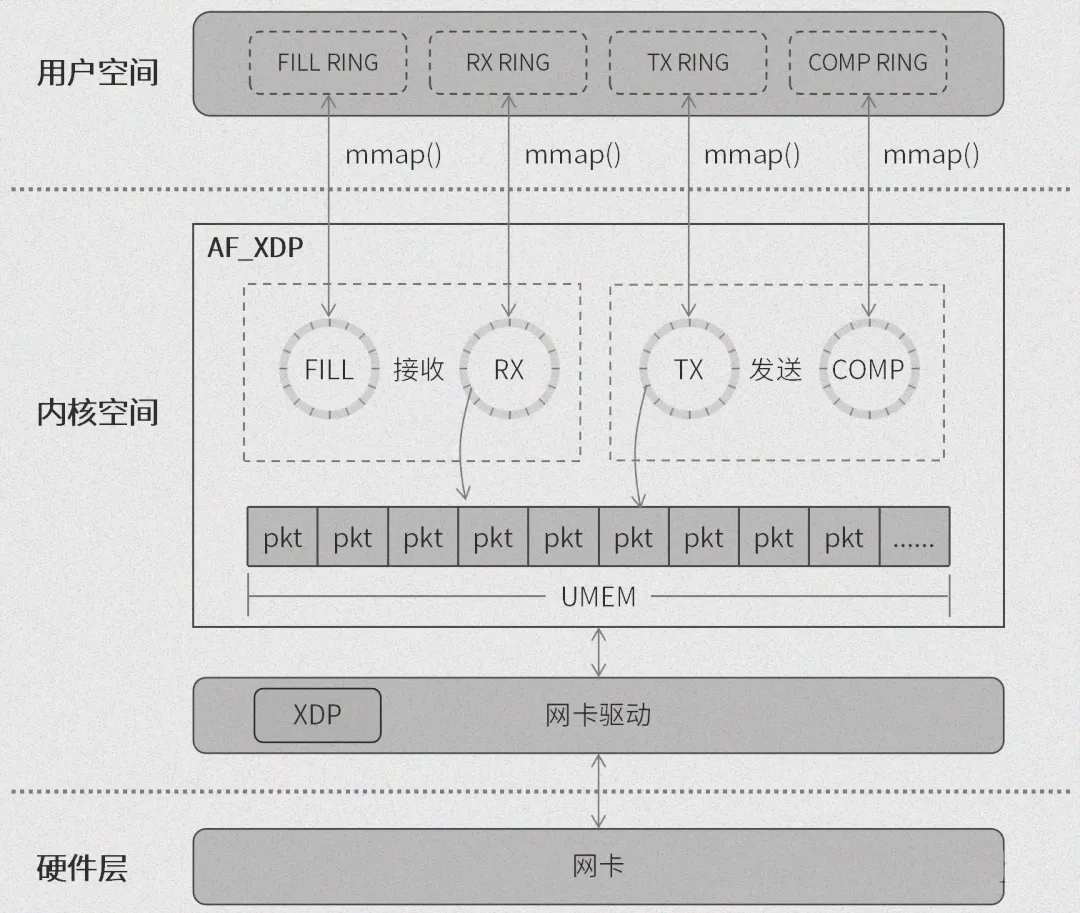
在这个架构中,用户程序、AF_XDP 和 XDP 共同操作一个至关重要的共享内存区域,我们称之为 UMEM(User Space Memory,用户空间内存)。UMEM 就像是一个数据交换的 “大仓库”,接收和发送的数据包都会暂时存储在这里。而网络数据包的接收和发送过程,离不开 4 个无锁环形队列的协同工作,它们就像是一条条高效的数据传输通道,确保了数据包的有序流动。
2.2 UMEM 共享内存机制
UMEM 共享内存的申请,是通过 setsockopt 函数来完成的。这一过程就像是在内存的 “海洋” 中,划出了一片专属的 “领地”,供用户程序和内核共同使用。UMEM 共享内存通常以 4K 为一个单元,每个单元就像是一个 “小房间”,可以存储一个数据包。一般情况下,UMEM 共享内存会包含 4096 个这样的单元,形成一个庞大的数据包存储 “矩阵”。
无论是用户程序还是内核,都可以直接对 UMEM 这块内存区域进行操作。这意味着在发送和接收数据包时,只需要进行简单的内存拷贝,就像在同一个房间里搬运物品一样,无需进行复杂的系统调用,大大提高了数据处理的效率。不过,用户程序需要承担起维护 UMEM 内存使用记录的责任,详细记录每一个 UMEM 单元的使用状态,是 “已被占用” 还是 “空闲可用”。同时,为了能够快速定位到每个 UMEM 单元在内存中的位置,还会为每个记录分配一个相对地址,就像是给每个 “小房间” 都编上了唯一的门牌号 。
2.3 无锁环形队列实现
AF_XDP socket 中一共有 4 个无锁环形队列,它们各自有着明确的分工。填充队列(FILL RING),就像是一个 “原材料供应站”,负责为接收数据包提供可用的 UMEM 单元;已完成队列(COMPLETION RING),则像是一个 “成品验收处”,用于标识内核已经成功传输完成、可以再次被用户空间使用的数据包;发送队列(TX RING),是数据包发送的 “出发站”,负责将用户程序准备发送的数据包传递给内核;接收队列(RX RING),则是数据包接收的 “终点站”,用户程序从这里获取接收到的数据包。
这些环形队列的创建方式,主要是通过 setsockopt 函数来实现的。以创建 FILL RING 为例,代码如下:
setsockopt(fd, SOL_XDP, XDP_UMEM_FILL_RING, &umem->config.fill_size, sizeof(umem->config.fill_size));
环形队列本质上是对数组进行封装后得到的数据结构,它由 5 个重要部分组成。生产者序号 (producer),就像是生产线上的 “进度指示器”,用于指示数组当前可生产的元素位置,如果队列已满,就像生产线堆满了产品,将不能再生产;消费者序号 (consumer),则像是消费环节的 “进度跟踪器”,用于指示当前可消费的元素位置,如果队列已空,就像商店里没有商品了,将不能再消费;队列长度(len),即数组的总长度,规定了这个 “数据仓库” 的大小;队列掩码(mask),其值等于 len - 1,生产者和消费者序号不能直接使用,需要与掩码配合使用,通过进行与运算,可以准确获取到数组的索引值,就像在一个大仓库里,通过特定的计算方式找到具体的货架位置;固定长度数组,数组的每一个元素都记录了 UMEM 单元的相对地址,如果 UMEM 单元中有发送和接收的数据包,还会记录数据包的长度,就像仓库里的每个货架都记录了存放物品的位置和相关信息 。
2.4 AF_XDP 数据包接收流程
AF_XDP 的数据包接收流程,是一个环环相扣的精密过程。首先,XDP 程序需要获取可用的 UMEM 单元,而这些信息就记录在 FILL RING 中。FILL RING 就像是一个记录着空闲 “小房间” 信息的账本,用户程序会根据 UMEM 使用记录,定期地往 FILL RING 中 “添加” 可用的 UMEM 单元,就像不断地在账本上更新空闲房间的信息。
接着,XDP 程序开始消费 FILL RING 中的 UMEM 单元,将其用于存放接收到的网络数据包。当数据包接收完成后,XDP 程序会将 UMEM 单元和数据包长度重新 “打包”,填充至 RX RING 队列中,这就像是将装满货物的 “包裹” 放到了接收队列的传送带上,生产出一个待接收的数据包。
最后,用户程序会时刻检测 RX RING,当发现有待接收的数据包时,就会 “出手” 消费 RX RING 中的数据包。用户程序将数据包信息从 UMEM 单元中拷贝至自己的缓冲区,就像从传送带上取下包裹并打开查看里面的物品。同时,为了保证接收流程的持续进行,用户程序还需要再次填充 FILL RING 队列,就像补充账本上的空闲房间信息,推动 XDP 继续接收新的数据。
2.5 AF_XDP 数据包发送流程
AF_XDP 的数据包发送流程同样严谨有序。用户程序首先会将需要发送的数据写入 UMEM 中,就像将待发送的货物放入仓库的指定 “小房间”。然后,通过 TX RING 通知内核,这里有数据包需要发送,TX RING 就像是一个 “通知信号灯”,告诉内核有新的任务来了。
内核在接收到通知后,会从 UMEM 中读取数据,并将其发送出去,就像仓库管理员根据通知,将货物从仓库中取出并发送出去。在这个过程中,已完成队列(COMPLETION RING)也发挥着重要作用,它会记录下那些已经成功传输完成的数据包信息,以便用户程序和内核进行后续的处理和管理,就像一个记录着已发货订单的账本,方便查询和统计 。
三、XDP 三种工作模式详解
XDP有三种工作模式,没有好坏之分,关键看你的硬件条件和使用场景。大家可以根据自己的情况选择,不用盲目追求高性能。
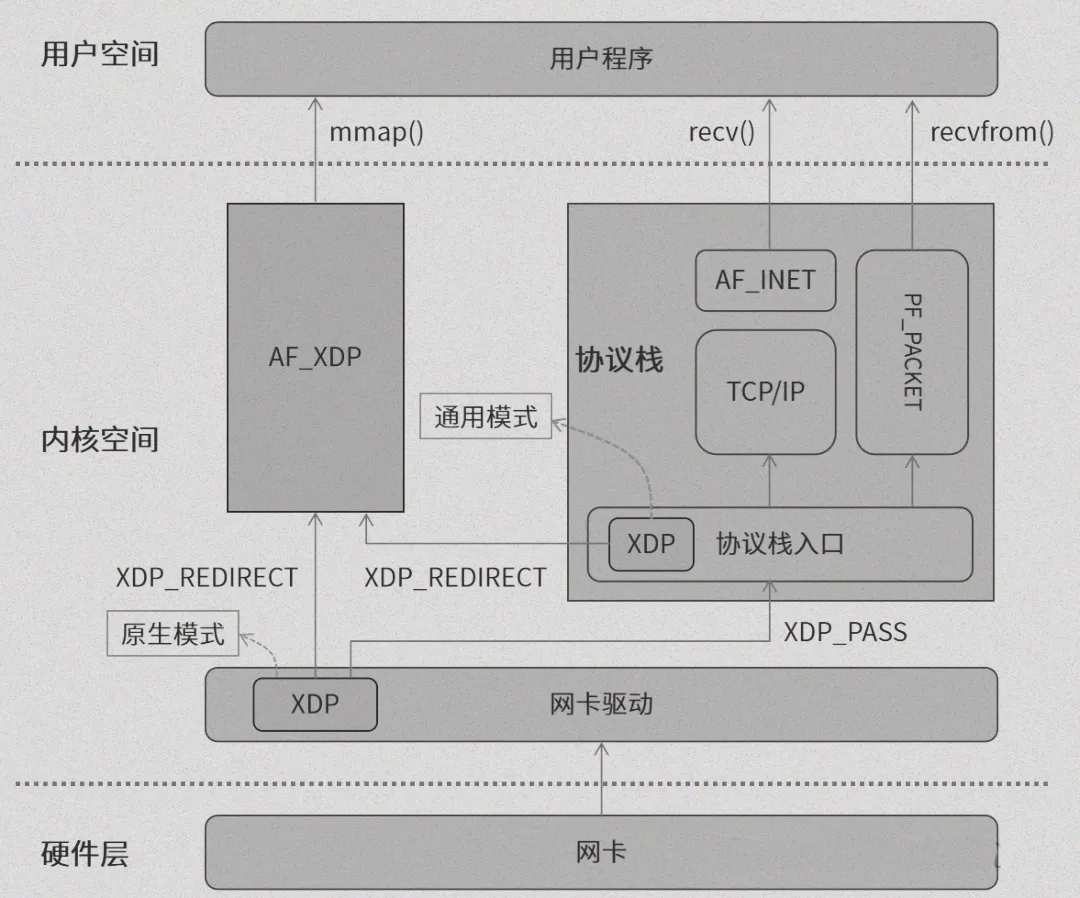
3.1 原生驱动模式 XDP_DRV
原生驱动模式,也被称为 Native XDP,是 XDP 的默认工作模式。在这种模式下,XDP BPF 程序就像是一位站在网络数据接收最前沿的卫士,直接运行在网络驱动的早期接收路径之中。它的优势十分显著,由于能够在网络数据进入系统的第一时间进行处理,所以性能表现极为出色。
然而,原生驱动模式也有其局限性,它对网卡驱动有着较高的要求,并非所有的网卡驱动都能支持这一模式。常见的如 Intel 的 ixgbe、i40e 系列网卡驱动,以及 Mellanox 的 mlx5_core 等网卡驱动,对 XDP_DRV 模式提供了良好的支持 。如果你想要知道自己的网卡驱动是否支持原生驱动模式,可以使用 ethtool 工具来一探究竟。通过执行 “ethtool -i eth0” 命令,如果输出中包含 “supports-xdp: true”,那就说明你的网卡驱动支持 XDP,为进一步使用原生驱动模式奠定了基础 。
3.2 通用 SKB 模式 XDP_SKB
通用 SKB 模式,即 Generic XDP,是一种兼容性极佳的工作模式。在这种模式下,XDP 程序运行的位置处于驱动之后、内核协议栈入口之前。它最大的优点在于,无需网卡驱动提供专门的支持,只要内核版本满足一定要求,就能够顺利运行 XDP 程序。这就好比一把万能钥匙,几乎可以在任何环境中使用,极大地降低了使用门槛,使得 XDP 技术能够被更广泛地应用和测试 。
不过,这种通用性也带来了一定的性能损耗。与原生驱动模式相比,通用 SKB 模式在处理数据包时,需要进行额外的操作,比如分配套接字缓冲区(SKB),这就导致了其性能要低于原生驱动模式。因此,通用 SKB 模式通常更适合用于对性能要求不是特别苛刻的测试场景,为开发者提供了一个便捷的测试环境 。
3.3 硬件卸载模式 XDP_HW
硬件卸载模式,也就是 Offloaded XDP,代表了 XDP 技术的高性能极致追求。在这种模式下,XDP BPF 程序直接被卸载到网卡硬件中,就像是将数据处理的重任直接交给了网卡这个 “超级助手”。这种方式使得数据包的处理无需依赖主机 CPU,大大减轻了主机 CPU 的负担,从而显著提升了性能 。
然而,这种模式的实现对硬件的要求极高,目前支持硬件卸载模式的网卡数量相对较少。其中,Netronome 网络流处理器是少数支持该模式的网卡之一 。这就使得硬件卸载模式在应用场景上受到了一定的限制,通常只适用于那些对网络性能有极高要求,并且拥有特定硬件支持的场景。
3.4 三种模式对比与切换验证
这三种工作模式在性能、硬件要求和适用场景等方面存在着明显的差异。从性能角度来看,硬件卸载模式由于直接在网卡硬件中处理数据包,性能最高;原生驱动模式次之,它能够在早期接收路径快速处理数据包;通用 SKB 模式则因额外的操作步骤,性能相对较低 。
在硬件要求方面,硬件卸载模式需要特定的网卡支持,条件最为苛刻;原生驱动模式也依赖特定的网卡驱动;而通用 SKB 模式对硬件没有特殊要求,兼容性最强 。
适用场景上,硬件卸载模式适用于对性能要求极高的专业领域,如大型数据中心的核心网络处理;原生驱动模式适用于大多数高性能网络场景,只要网卡驱动支持,就能发挥出良好的性能;通用 SKB 模式则主要用于测试和验证 XDP 程序的功能,以及在一些对性能要求不高的普通场景中使用 。
如果需要在不同模式之间进行切换,可以通过修改系统的配置文件或者使用相关的命令行工具来实现。例如,使用 iproute2 工具加载 XDP 程序时,可以通过不同的参数来指定工作模式。通过 “ip link set dev eth0 xdpdrv obj xdp_pass_kern.o” 命令可以将网卡 eth0 设置为原生驱动模式并加载 XDP 程序;而 “ip link set dev eth0 xdpgeneric obj xdp_pass_kern.o” 则是设置为通用 SKB 模式 。切换完成后,可以通过一些网络测试工具,如 iperf 等,来验证网络性能是否符合预期,确保模式切换的成功和系统的正常运行 。
四、AF_XDP 核心组件:xsk 与 umem
4.1 xsk 与 umem 基础关系
在 AF_XDP 的高性能网络数据处理体系中,xsk 与 umem 是两个至关重要的核心组件,它们之间的紧密协作,为数据包的高效收发奠定了坚实的基础。
xsk,即 AF_XDP socket,它是用户程序与网络数据交互的关键接口,就像是一扇通往网络世界的 “高速大门”。通过这个特殊的 socket,用户程序能够以一种高效的方式与网络进行数据传输,绕过了传统内核协议栈的复杂流程,大大提高了数据处理的速度。
umem,也就是用户空间内存(User Space Memory),则是一个共享内存区域,它就像是一个数据交换的 “大仓库”。在 AF_XDP 的架构中,用户程序、AF_XDP 和 XDP 都可以直接对 umem 进行操作。无论是接收来自网络的数据包,还是准备发送出去的数据包,都会暂时存储在 umem 这个 “大仓库” 中。umem 通常以 4K 为一个单元,每个单元就像是仓库中的一个 “小房间”,可以存储一个数据包。一般情况下,umem 会包含 4096 个这样的单元,形成一个庞大的数据包存储矩阵。
xsk 与 umem 之间存在着紧密的联系。xsk 通过与 umem 的协同工作,实现了数据包的快速收发。在接收数据包时,xsk 从 umem 中获取可用的内存单元,用于存储接收到的数据包;在发送数据包时,xsk 将用户程序准备发送的数据包写入 umem,然后通知内核进行发送。这种紧密的配合,使得数据在用户程序和网络之间的传输变得更加高效,就像一条顺畅的高速公路,数据能够快速地流动。
4.2 收发包队列体系设计
AF_XDP 的收发包队列体系设计精巧,是实现高性能网络数据处理的关键所在。这个体系主要由填充队列(FILL RING)、已完成队列(COMPLETION RING)、发送队列(TX RING)和接收队列(RX RING)这 4 个无锁环形队列组成,它们各自承担着独特的职责,共同协作完成数据包的收发任务。
填充队列(FILL RING),就像是一个 “原材料供应站”,它的主要任务是为接收数据包提供可用的 UMEM 单元。用户程序会根据 UMEM 的使用记录,定期地往 FILL RING 中添加可用的 UMEM 单元,就像不断地为 “原材料供应站” 补充物资。当 XDP 程序需要接收数据包时,就会从 FILL RING 中获取这些可用的 UMEM 单元,用于存放接收到的网络数据包。
已完成队列(COMPLETION RING),则像是一个 “成品验收处”,它用于标识内核已经成功传输完成、可以再次被用户空间使用的数据包。当内核完成数据包的发送或接收操作后,会将对应的 UMEM 单元信息添加到 COMPLETION RING 中。用户程序通过检测 COMPLETION RING,就可以知道哪些数据包已经完成传输,从而对这些 UMEM 单元进行重新利用,为下一次的数据传输做好准备。
发送队列(TX RING),是数据包发送的 “出发站”。用户程序将需要发送的数据写入 UMEM 后,会通过 TX RING 通知内核,这里有数据包需要发送。内核在接收到通知后,会从 UMEM 中读取数据,并将其发送出去。TX RING 就像是一个 “通知信号灯”,它确保了用户程序和内核之间在数据包发送过程中的有效沟通。
接收队列(RX RING),是数据包接收的 “终点站”。XDP 程序在接收到网络数据包并将其存储在 UMEM 中后,会将 UMEM 单元和数据包长度信息填充至 RX RING 队列中。用户程序通过检测 RX RING,当发现有待接收的数据包时,就会从 RX RING 中获取数据包信息,并将其从 UMEM 单元中拷贝至自己的缓冲区,完成数据包的接收操作。
在数据包的收发过程中,这 4 个队列相互协作,形成了一个高效的数据传输流水线。例如,在接收过程中,FILL RING 不断为 XDP 程序提供可用的 UMEM 单元,XDP 程序接收数据包后将其存入 UMEM 并更新 RX RING,用户程序从 RX RING 获取数据包并处理,同时将处理后的 UMEM 单元信息更新到 COMPLETION RING,为下一次接收做好准备。在发送过程中,用户程序将数据写入 UMEM 并通过 TX RING 通知内核,内核发送完成后更新 COMPLETION RING,用户程序可以根据 COMPLETION RING 的信息进行后续处理。这种协同工作方式,确保了数据包能够快速、准确地在用户程序和网络之间传输。
4.3 BPF 相关核心 API
4.3.1 xsk/umem 操作 API
在 AF_XDP 的开发中,有一系列的 BPF 相关核心 API 用于对 xsk 和 umem 进行操作,这些 API 为开发者提供了灵活且强大的工具,以实现高效的网络数据处理。
首先是 socket 创建 API,通过基本的 socket () 系统调用可以创建 AF_XDP socket(xsk)。示例代码如下:
int sock = socket(AF_XDP, SOCK_RAW, 0); if (sock < 0) { perror("socket"); exit(EXIT_FAILURE);}
这段代码使用 socket 函数创建了一个 AF_XDP 类型的 socket,如果创建失败,会打印错误信息并退出程序。
对于 umem 的配置,主要通过 setsockopt 函数来实现。例如,申请 UMEM 共享内存时,可以使用以下代码:
struct xsk_umem_config umem_config = { .fill_size = 8192, .comp_size = 2048, .frame_size = 2048, .frame_headroom = 2 };struct xsk_umem *umem;int ret = xsk_umem__create(&umem, buffer, size, &umem_config.fill, &umem_config.comp, &umem_config);if (ret) { perror("xsk_umem__create"); return ret;}ret = setsockopt(sock, SOL_XDP, XDP_UMEM_REG, umem, sizeof(*umem));if (ret) { perror("setsockopt XDP_UMEM_REG"); xsk_umem__destroy(umem); return ret;}
在这段代码中,首先定义了 umem 的配置参数,包括填充队列大小、完成队列大小、数据帧大小和头部空间等。然后使用 xsk*umem*_create 函数创建 umem,并通过 setsockopt 函数将 umem 注册到内核。如果任何一步出现错误,都会进行相应的错误处理。
这些 API 的使用,使得开发者能够根据实际需求,灵活地配置 xsk 和 umem,为实现高性能的网络数据处理提供了基础。通过合理地设置 socket 和 umem 的参数,可以优化数据传输的效率,满足不同应用场景的需求。
4.3.2 队列交互与控制 API
为了实现收发包队列之间的高效交互与控制,AF_XDP 提供了一系列专门的 API。这些 API 就像是网络数据处理的 “交通指挥棒”,确保了数据包在各个队列之间的有序流动。
对于环形队列的操作,有一系列的函数可供使用。以填充队列(FILL RING)为例,xsk_ring*prod*reserve 函数用于预留一定数量的元素空间,xsk_ring*prod*fill_addr 函数用于填充元素的地址,xsk_ring*prod*_submit 函数则用于提交预留的元素。示例代码如下:
uint32_t idx;int ret = xsk_ring_prod__reserve(&umem->fq, num_elements, &idx);if (ret!= num_elements) { perror("xsk_ring_prod__reserve"); return ret;}for (int i = 0; i < num_elements; i++) { *xsk_ring_prod__fill_addr(&umem->fq, idx + i) = element_address;}xsk_ring_prod__submit(&umem->fq, num_elements);
在这段代码中,首先使用 xsk_ring*prod*reserve 函数预留了 num_elements 个元素空间,并获取了起始索引 idx。然后通过循环使用 xsk_ring*prod*fill_addr 函数填充每个元素的地址,最后使用 xsk_ring*prod*_submit 函数提交这些预留的元素,完成对填充队列的操作。
在接收队列(RX RING)和发送队列(TX RING)的操作中,也有类似的函数。例如,xsk_ring*cons*peek 函数用于查看队列中是否有可消费的元素,xsk_ring*cons*pop 函数用于取出并消费队列中的元素。通过这些函数,用户程序可以方便地从 RX RING 中获取接收到的数据包,以及将待发送的数据包放入 TX RING 中。
这些队列交互与控制 API 的存在,使得开发者能够精确地控制数据包在各个队列之间的流动,实现高效的数据收发。通过合理地运用这些 API,可以优化数据处理的流程,提高网络性能,满足不同应用场景对网络数据处理的严格要求。
五、AF_XDP 高性能的底层秘密
AF_XDP 之所以能够在网络数据处理领域展现出卓越的性能,背后离不开一系列精心设计的底层技术支撑。这些技术就像是隐藏在幕后的 “超级引擎”,为 AF_XDP 的高效运行提供了源源不断的动力。
5.1 零拷贝与内核旁路
在传统的网络数据处理流程中,数据包往往需要在用户空间和内核空间之间进行多次拷贝,同时伴随着频繁的系统调用,这无疑会带来巨大的开销,就像在数据传输的道路上设置了重重障碍,降低了数据处理的速度。
而 AF_XDP 采用的零拷贝机制,就像是为数据传输开辟了一条 “绿色通道”,彻底避免了这些问题。在 AF_XDP 的架构中,数据包直接从网卡通过 DMA(直接内存访问)技术传输到用户空间预先分配好的内存区域,无需经过内核空间的中转和拷贝。这就好比快递包裹直接从发货地送到收件人手中,省去了中间的多个转运环节,大大减少了数据传输的时间和资源消耗 。
同时,AF_XDP 实现的内核旁路技术,让数据包能够跳过复杂的内核协议栈,直接由用户程序进行处理。传统的内核协议栈在处理数据包时,需要进行大量的协议解析、路由查找等操作,这些操作不仅繁琐,而且耗时。而 AF_XDP 绕过内核协议栈后,就像运动员跨越了重重障碍,直接冲向终点,能够快速地对数据包进行处理,显著提高了网络数据处理的效率和性能。
5.2 无锁并发设计
在多线程或多进程的并发环境下,锁竞争往往是影响性能的一个重要因素。传统的网络编程中,为了保证数据的一致性和安全性,常常会使用锁机制来同步多个线程或进程对共享资源的访问。然而,锁的使用会带来额外的开销,当多个线程或进程同时竞争同一把锁时,就会产生锁冲突,导致线程或进程的阻塞和等待,这就像是多个车辆在狭窄的路口争抢通行权,造成交通堵塞,降低了系统的并发性能 。
AF_XDP 通过采用无锁环形队列和精心设计的无锁数据结构,巧妙地避免了锁竞争的问题。在 AF_XDP 的收发包队列体系中,填充队列(FILL RING)、已完成队列(COMPLETION RING)、发送队列(TX RING)和接收队列(RX RING)都是无锁环形队列。这些队列利用硬件提供的原子操作指令,如比较并交换(CAS,Compare And Swap)指令,来实现对队列的并发访问控制。例如,在往队列中添加元素时,通过 CAS 指令可以原子地更新队列的生产者指针,确保在多线程环境下,多个线程能够安全地同时向队列中添加元素,而不会产生数据冲突 。
这种无锁并发设计,使得 AF_XDP 在多线程或多进程环境下,能够充分发挥多核处理器的优势,让各个线程或进程能够高效地并行处理网络数据,就像多条车道同时畅通无阻地运行车辆,大大提高了系统的并发性能和整体吞吐量 。
5.3 轻量级报文处理路径
AF_XDP 的 XDP 程序运行在网卡驱动层,这使得它能够在数据包到达系统的早期阶段就对其进行处理。与传统的网络协议栈处理方式相比,AF_XDP 的处理路径要简单得多。传统的网络协议栈需要从链路层开始,逐层对数据包进行解析和处理,经过网络层、传输层,最终到达应用层,这个过程涉及到大量的协议解析和处理逻辑,就像一个复杂的生产流水线,每个环节都需要耗费一定的时间和资源 。
而 AF_XDP 的 XDP 程序在网卡驱动层就可以根据预先定义好的规则,对数据包进行快速的过滤、转发或丢弃等操作。例如,在 DDoS 防御场景中,XDP 程序可以在驱动层就识别出恶意的攻击流量,并直接将其丢弃,无需将这些数据包传递到内核协议栈进行进一步的处理。这种轻量级的报文处理路径,就像是一个精简的快速通道,大大简化了数据包的处理流程,减少了处理时间和资源消耗,从而提高了网络数据处理的效率和性能 。
5.4 与传统协议栈的性能差异
为了更直观地展示 AF_XDP 与传统协议栈在性能上的差异,我们来看一组实际的测试数据。在相同的硬件环境下,使用 iperf 等网络测试工具,分别对传统协议栈和 AF_XDP 进行性能测试 。
测试结果显示,在吞吐量方面,AF_XDP 能够达到传统协议栈的数倍甚至更高。例如,在 10Gbps 的网络环境下,传统协议栈的吞吐量可能只能达到 6 - 7Gbps 左右,而 AF_XDP 则可以轻松突破 9Gbps,甚至接近网络带宽的极限。这是因为 AF_XDP 通过零拷贝、内核旁路等技术,减少了数据处理的开销,使得数据包能够更快速地在网络中传输 。
在延迟方面,AF_XDP 也表现得更加出色。传统协议栈由于复杂的处理流程,数据包从接收端到发送端的延迟通常在几十微秒甚至更高。而 AF_XDP 通过轻量级的报文处理路径和高效的处理机制,能够将延迟降低到几微秒甚至更低,大大提高了数据传输的实时性。例如,在对实时性要求极高的在线游戏场景中,AF_XDP 的低延迟特性可以让玩家的操作指令更快地传输到服务器,从而获得更流畅的游戏体验 。
在 CPU 占用率方面,AF_XDP 同样具有明显的优势。传统协议栈在处理大量网络数据时,需要消耗大量的 CPU 资源来进行协议解析、数据拷贝等操作,导致 CPU 占用率居高不下。而 AF_XDP 通过减少不必要的操作和高效的并发处理,能够将 CPU 占用率保持在较低的水平。这意味着系统可以将更多的 CPU 资源分配给其他重要的任务,提高了整个系统的运行效率 。
通过这些性能对比数据,可以清晰地看到 AF_XDP 在处理网络数据时,相较于传统协议栈具有更高的性能和效率,能够更好地满足现代高速网络环境下对网络数据处理的严格要求 。
六、XDP 实践与总结
6.1 基础使用要点
很多同学看完理论,想上手实践,这里给大家讲几个关键要点,避免踩坑:
第一,环境搭建。内核版本至少4.8以上,建议用5.0以上,兼容性更好;网卡驱动要支持XDP(原生模式),用“ethtool -i eth0”查看即可。
第二,编写XDP程序。遵循eBPF规范,不用写太复杂,先从简单的例子入手,比如下面这个“丢弃所有数据包”的程序:
#include<vmlinux.h>#include<bpf/bpf_helpers.h>#include<bpf/bpf_core_read.h>#include<bpf/bpf_tracing.h>SEC("xdp")intxdp_drop_all(struct xdp_md *ctx){ return XDP_DROP; // 丢弃所有数据包}char _license[] SEC("license") = "GPL";
第三,编译和加载。用clang+LLVM编译:“clang -O2 -target bpf -c xdp_drop_all.c -o xdp_drop_all.o”;加载到网卡:“ip link set dev eth0 xdp obj xdp_drop_all.o sec xdp”;卸载:“ip link set dev eth0 xdp off”。
第四,AF_XDP收发包。重点关注UMEM的配置,队列大小要根据业务调整,不要太小(容易丢包),也不要太大(浪费内存);收发包时,记得及时回收UMEM单元,避免内存泄露。
6.2 技术局限与优化方向
XDP虽然强,但不是万能的,有几个局限要注意,避免踩坑:
1. 没有缓存队列,突发流量容易丢包。比如遇到DDoS攻击,大量流量瞬间涌入,XDP处理不过来,就会丢包,影响防御效果;
2. 对IP分片不友好。处理大数据包分片时,容易出现组装失败,导致数据传输异常;
3. 程序专用性强,通用性差。比如为DDoS防御写的程序,改改才能用于负载均衡,开发维护成本有点高。
针对这些局限,也有相应的优化方向和研究热点。在缓存队列方面,可以考虑在用户空间或内核空间实现缓存机制,以应对突发流量。比如在用户空间创建一个环形缓冲区,当 XDP 接收到数据包时,如果来不及处理,可以先将数据包暂存到这个缓冲区中,避免丢包 。
对于 IP 分片问题,可以研究开发专门的 IP 分片处理模块,使其能够与 XDP 程序协同工作。该模块可以在 XDP 处理数据包之前,对 IP 分片进行预处理,将分片数据包重新组装成完整的数据包,再交给 XDP 进行后续处理 。
为了提高 XDP 程序的通用性,可以探索开发一种通用的 XDP 编程框架。在这个框架下,可以通过配置文件或简单的参数设置,快速地生成适用于不同场景的 XDP 程序,减少重复开发的工作量,提高开发效率 。
从技术发展方向来看,XDP 可能会进一步优化其性能和功能。一方面,它可能会与其他新兴技术,如人工智能、机器学习等相结合,实现更智能的网络流量分析和处理。例如,通过机器学习算法,XDP 可以自动识别网络流量中的异常行为,提前进行预警和防御,增强网络的安全性 。另一方面,XDP 也会不断完善对各种网络协议和应用场景的支持,使其能够适应更加复杂和多样化的网络环境,为用户提供更加全面和优质的网络服务 。