每年因数据湖并发写入冲突导致的线上事故,在各大厂的复盘文档里从未缺席。今天我们撕开 Delta Lake 的源码,看看这个 GitHub 8.6K Star 的项目,到底是怎么在"一堆文件"上硬生生实现数据库级别的事务保障的。
 Delta Lake Logo
Delta Lake Logo一、灵魂拷问:你的数据湖"可靠"吗?
先来个灵魂拷问。如果你的团队正在用 HDFS / S3 做数据湖,你敢说以下场景不会出问题吗?
场景一:凌晨3点,两个 Spark 任务同时写同一张表。 任务 A 刚写了一半 Parquet 文件,任务 B 读到了这些不完整的数据,下游报表直接炸了。
场景二:上线前误跑了一个 DELETE 脚本。 生产表里 300 万条核心数据没了,没有事务回滚,只能从备份恢复——如果你有备份的话。
场景三:每小时一个微批,跑着跑着目录里攒了 50 万个小文件。 查询性能断崖式下降,list 操作就要 10 分钟。
场景四:上游悄悄改了个字段类型。 你的 ETL Pipeline 静默地写入了脏数据,一周后才被 BI 同学发现。
这些不是假设,是数据工程团队每天都在经历的真实痛点。
而 Delta Lake 给出的答案是:在文件系统之上,用一套事务日志协议,硬生生造出数据库级别的 ACID 事务。 
项目信息卡
- 🔗 仓库地址:https://github.com/delta-io/delta
- ⭐ Star 数:8.6K | 🍴 Fork 数:2K | 👥 贡献者:417+
- 📝 语言:Scala 78.6% + Java 18.4% + Python 2.6%
- 📜 协议:Apache 2.0(Linux 基金会项目)
- 🏢 贡献组织:Adobe、Apple、Amazon、Microsoft、阿里巴巴、字节跳动等 70+ 家
二、架构全景:四层设计,一张图看懂
直接看源码中 build.sbt 的模块定义,Delta Lake 采用了清晰的四层架构:

这四层各司其职:
| | |
|---|
| 应用层 | SQL/DataFrame/Streaming API | python/ |
| 引擎集成层 | | spark/ |
| Kernel 核心层 | | kernel/kernel-api/ |
| 存储层 | | storage/ |
💡 关键设计决策:4.0 版本引入的 Delta Kernel 是重大架构升级——将核心协议逻辑从 Spark 中彻底解耦,让任何引擎只需实现一个 Engine 接口就能原生读写 Delta 表。
三、核心机密:事务日志——在文件上造"数据库"
3.1 _delta_log/ 目录:一切的起点
打开任何一个 Delta 表的存储路径,你都会看到一个 _delta_log/ 目录。这就是 Delta 的"大脑"——所有的表状态变更都记录在这里。

每个 JSON 文件就是一次"提交"(commit),包含了一系列 Action。源码中(spark/src/main/scala/org/apache/spark/sql/delta/actions/actions.scala)定义了这些核心类型:
// 所有表状态变更的基类sealed trait Action{def wrap: SingleActiondef json: String = JsonUtils.toJson(wrap)}// 协议版本——控制向前/向后兼容case class Protocol(minReaderVersion: Int, minWriterVersion: Int, ...)// 表元数据——Schema、分区列、表属性case class Metadata(id: String, schemaString: String, partitionColumns: Seq[String], ...)// 新增文件——记录数据文件的路径、大小、分区值case class AddFile(path: String, partitionValues: Map[String, String], size: Long, ...)// 删除文件——逻辑删除(物理文件还在,等 VACUUM 清理)case class RemoveFile(path: String, deletionTimestamp: Option[Long], ...)
这个设计的精妙之处在于:数据文件本身是不可变的 Parquet 文件,所有的"增删改"都只是在事务日志里追加新的 Action。DELETE 不会真的删文件,UPDATE 是"删旧文件 + 加新文件"。
3.2 读取一张表 = 重放日志 + 过滤
当你执行 spark.read.format("delta").load("/data/my_table"),底层做了什么?
- 找到最近的 Checkpoint(
_last_checkpoint 文件指向 v3) - 读取 Checkpoint(v3.checkpoint.parquet —— 包含 v0~v3 的合并状态)
- 重放后续的 JSON 日志(v4.json、v5.json)
- 合并出当前存活的文件列表(所有 AddFile 减去所有 RemoveFile)
这就是源码中 SnapshotImpl 和 LogReplay 做的事情。每个 Snapshot 就是表在某个版本的"一致快照"。
四、让数据工程师夜夜安睡的秘密:OCC 并发控制
前面场景一的问题——两个任务同时写同一张表——Delta 是这么解决的:
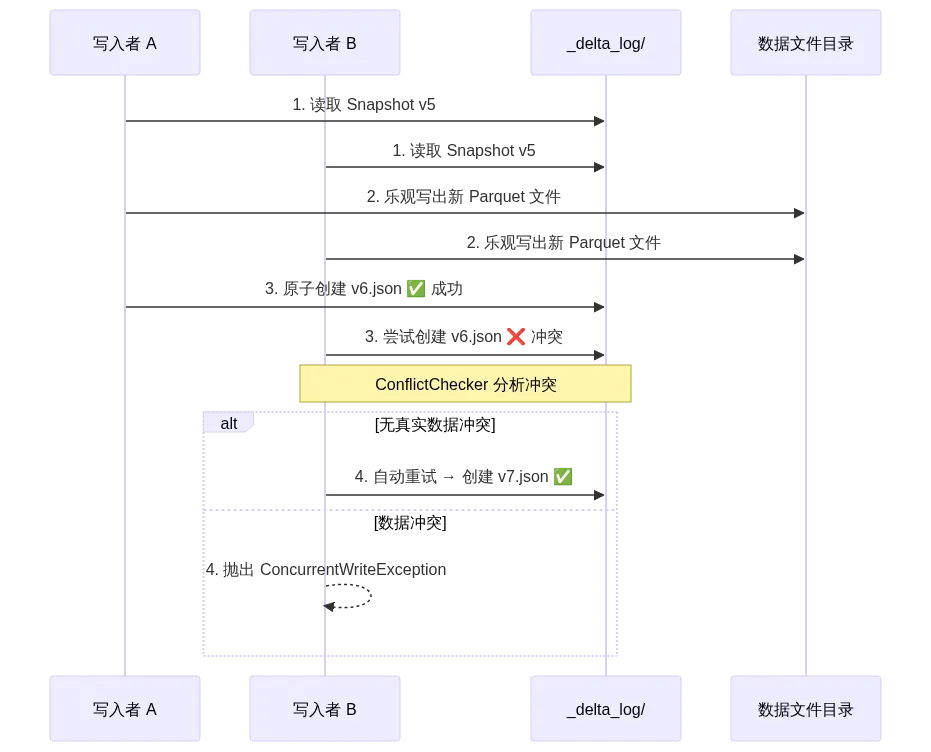
核心实现在 OptimisticTransaction.scala。源码中的 ConflictChecker 非常聪明——它不会一刀切地拒绝所有并发写入,而是精确分析冲突范围:
// ConflictChecker 记录的事务读取信息case class CurrentTransactionInfo( val readPredicates: Vector[DeltaTableReadPredicate], // 读了哪些分区/条件 val readFiles: Set[AddFile], // 读了哪些文件 val readWholeTable: Boolean, // 是否全表扫描 val readAppIds: Set[String], // 幂等写入 ID val metadata: Metadata, val actions: Seq[Action], ...)
只有当并发写入真正影响了当前事务读取的数据时,才会报冲突。 比如任务 A 写分区 date=2026-02-27,任务 B 写分区 date=2026-02-26,完全互不影响,自动成功。
而存储层的 LogStore 保证了最关键的三个底线(来自 storage/src/main/java/io/delta/storage/LogStore.java):
/** * 1. Atomic visibility — 文件要么完整可见,要么不可见 * 2. Mutual exclusion — 同一路径只有一个 writer 能成功 * 3. Consistent listing — 写入后的文件必须在后续 list 中出现 */public abstract class LogStore {public abstract void write(Path path, Iterator<String> actions, Boolean overwrite, Configuration hadoopConf) throws IOException;public abstract Iterator<FileStatus> listFrom(Path path, Configuration hadoopConf) throws IOException;}
不同存储的实现策略完全不同:HDFS 用原子重命名,S3 用条件写入(S3 没有原子 rename!),Azure 用条件 ETag,GCS 用 if-generation-match。
五、Kernel 架构:让所有引擎"说同一种话"
Delta 4.0 最大的架构变革是 Delta Kernel——一个纯 Java 的、引擎无关的核心库。
来看 kernel/kernel-api/src/main/java/io/delta/kernel/ 下的核心接口:
// 表入口 —— 一切从这里开始public interface Table {static Table forPath(Engine engine, String path); Snapshot getLatestSnapshot(Engine engine); TransactionBuilder createTransactionBuilder(Engine engine, String engineInfo, Operation op);void checkpoint(Engine engine, long version);}// 一致快照 —— 某个版本的不可变视图public interface Snapshot {long getVersion(); StructType getSchema(); ScanBuilder getScanBuilder(); List<String> getPartitionColumnNames();}// 读路径public interface Scan { CloseableIterator<FilteredColumnarBatch> getScanFiles(Engine engine); Optional<Predicate> getRemainingFilter();}// 写路径public interface Transaction { StructType getSchema(Engine engine); TransactionCommitResult commit(Engine engine, CloseableIterable<Row> dataActions);}
而引擎要做的,就是实现 Engine SPI 接口:
public interface Engine { ExpressionHandler getExpressionHandler(); // 表达式求值 JsonHandler getJsonHandler(); // JSON 解析 FileSystemClient getFileSystemClient(); // 文件系统操作 ParquetHandler getParquetHandler(); // Parquet 读写}
这意味着:Flink、Trino、Presto、甚至你自己的引擎,只要实现这 4 个 Handler,就能完整地读写 Delta 表,享受所有事务保障。不再需要引入庞大的 Spark 依赖。
六、读写路径全拆解
深入源码,Delta 的读写路径设计得极其清晰:

几个值得关注的源码细节:
写路径中的 transformLogicalData(Transaction.java)——负责将用户写入的逻辑数据转换为物理数据。这一步会处理列映射(Column Mapping)、默认值填充、分区值校验等。源码中明确写道:
// 如果启用了列映射模式,当前阻止写入(列映射需要特殊处理物理列名)blockIfColumnMappingEnabled(transactionState);// 如果数据中包含 Variant 类型,当前阻止写入(实验特性)blockIfVariantDataTypeIsDefined(tableSchema);
读路径中的 transformPhysicalData(Scan.java)——做了三件关键事情:
- 行追踪(Row Tracking):如果表开启了 Row Tracking,将物理行 ID 转换为逻辑行 ID
- 删除向量(Deletion Vector):用 RoaringBitmap 标记哪些行已被删除,避免读到脏数据
七、生产场景全覆盖:不只是"加了个事务"
7.1 流批一体:同一张表,实时写、离线读
这是 Delta Lake 最杀手级的场景。源码中的 DeltaSource(Structured Streaming Source)和 DeltaSink(Streaming Sink)实现了完整的流批一体:
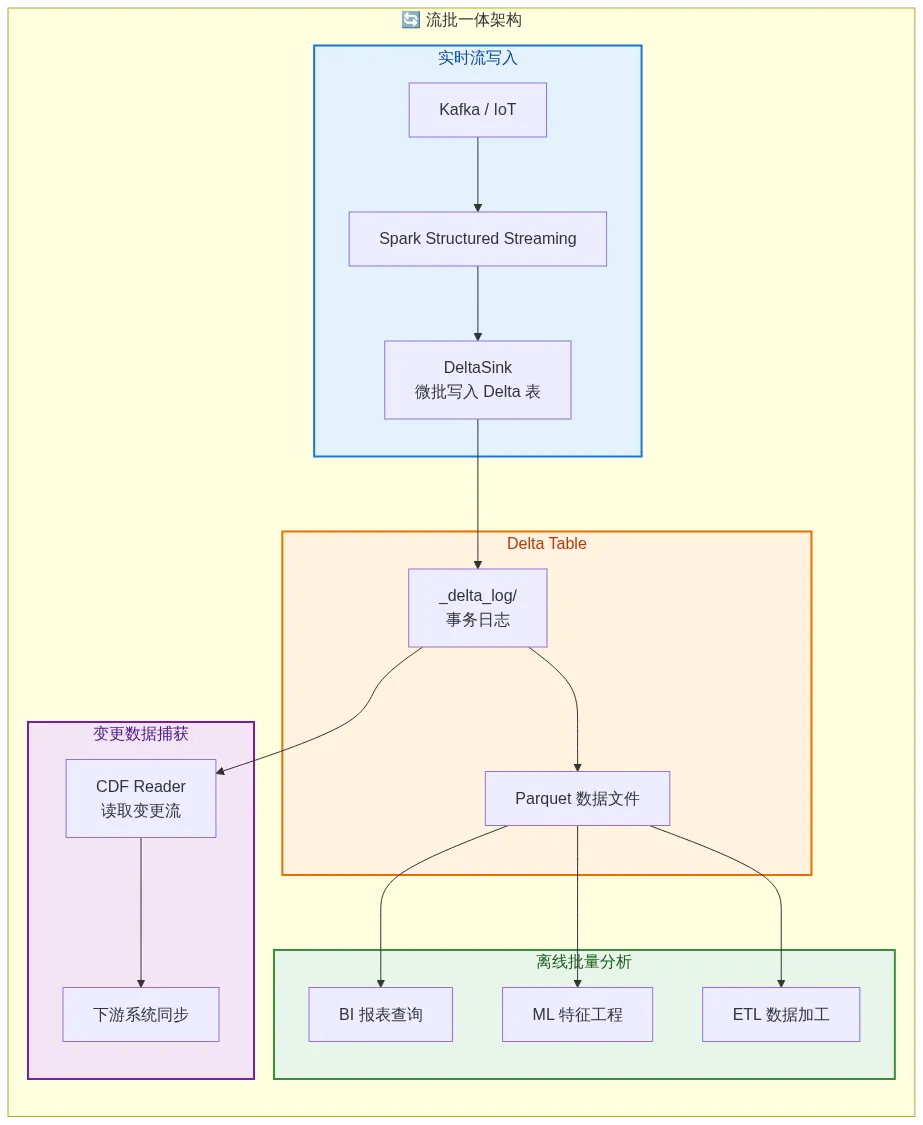
流式写入,批量查询永远看到一致快照,CDC 还能捕获变更增量——一张表,三种用法。
7.2 SQL DML:数据湖终于能 UPDATE 和 DELETE 了
从 commands/ 目录的源码来看,Delta 支持完整的 DML:
| | |
|---|
| INSERT | WriteIntoDelta | |
| UPDATE | UpdateCommand | 读旧文件 → 修改 → 写新文件 + AddFile + RemoveFile |
| DELETE | DeleteCommand | 读旧文件 → 过滤 → 写新文件(或用 Deletion Vector) |
| MERGE INTO | MergeIntoCommand | 源表和目标表 JOIN → 按条件 insert/update/delete |
| OPTIMIZE | OptimizeTableCommand | |
| VACUUM | VacuumCommand | 物理删除过期的 RemoveFile 文件(默认保留 7 天) |
| RESTORE | RestoreTableCommand | |
| CLONE | CloneTableCommand | |
Deletion Vector 是 Delta 的重要优化:DELETE 操作不再需要重写整个 Parquet 文件,而是用 RoaringBitmap 标记被删除的行号。源码在 DeletionVectorUtils 和 DMLWithDeletionVectorsHelper 中。
7.3 时间旅行:误操作后的后悔药
-- 查看表的所有历史版本DESCRIBE HISTORY my_table;-- 查询 3 天前的数据SELECT * FROM my_table TIMESTAMP AS OF '2026-02-24';-- 查询特定版本的数据SELECT * FROM my_table VERSION AS OF 42;-- 回滚到上一个版本RESTORE TABLE my_table TO VERSION AS OF 41;
源码中 Table.java 定义了三种快照获取方式:
Snapshot getLatestSnapshot(Engine engine);Snapshot getSnapshotAsOfVersion(Engine engine, long versionId);Snapshot getSnapshotAsOfTimestamp(Engine engine, long millisSinceEpochUTC);
7.4 Schema 演进 & 强制执行
Delta 同时支持 Schema Enforcement(拒绝不兼容写入)和 Schema Evolution(安全地添加新列)。Protocol action 中的 minReaderVersion 和 minWriterVersion 确保只有能理解当前表特性的客户端才能读写。
八、进阶特性一览
源码中还能看到大量面向企业生产的高级特性:
| | |
|---|
| Deletion Vectors | 用 RoaringBitmap 标记删除行,避免重写整个文件 | deletionvectors/ |
| Row Tracking | 行级追踪(Row ID + Row Commit Version) | GenerateRowIDs.scala |
| Column Mapping | | DeltaColumnMapping.scala |
| Iceberg 兼容(UniForm) | | iceberg/ |
| Hudi 兼容 | | hudi/ |
| Delta Sharing | | sharing/ |
| Unity Catalog 集成 | | kernel/unitycatalog/ |
| Variant 类型 | | VariantType.java |
| Clustered Table | | commands/optimize/ |
九、和竞品的关键差异
| | | |
|---|
| 起源 | | | |
| 核心目标 | | | |
| Kotlin 依赖 | | | |
| UniForm 互操作 | | | |
| 流批一体 | | | |
| 社区规模 | | | |
| 生产验证 | | | |
Delta Lake 的独特优势在于 UniForm——你用 Delta 写入,Trino 用 Iceberg 协议读取,Hudi 客户端也能读取。一次写入,通吃所有格式。
十、写在最后
回到开头的四个场景:
- 并发写入冲突 → OCC 乐观并发 + ConflictChecker 精确冲突检测 ✅
- 误操作无法回滚 → 事务日志 + 时间旅行 + RESTORE ✅
- 小文件爆炸 → OPTIMIZE 自动合并 + VACUUM 空间回收 ✅
- Schema 漂移 → Schema Enforcement 强制校验 + Protocol 版本控制 ✅
Delta Lake 做到了一件很难的事情:在"一堆文件"上,用精巧的日志协议和乐观并发控制,实现了数据库级别的事务保障,同时保持了数据湖的开放性和低成本。
如果你的数据湖还在"裸奔",是时候给它穿上 Delta 的"铠甲"了。
📎 延伸阅读
- Delta Transaction Log Protocol 规范
- Lakehouse: A New Generation of Open Platforms(论文)
- Delta Kernel: A Game-Changer(官方博客)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
