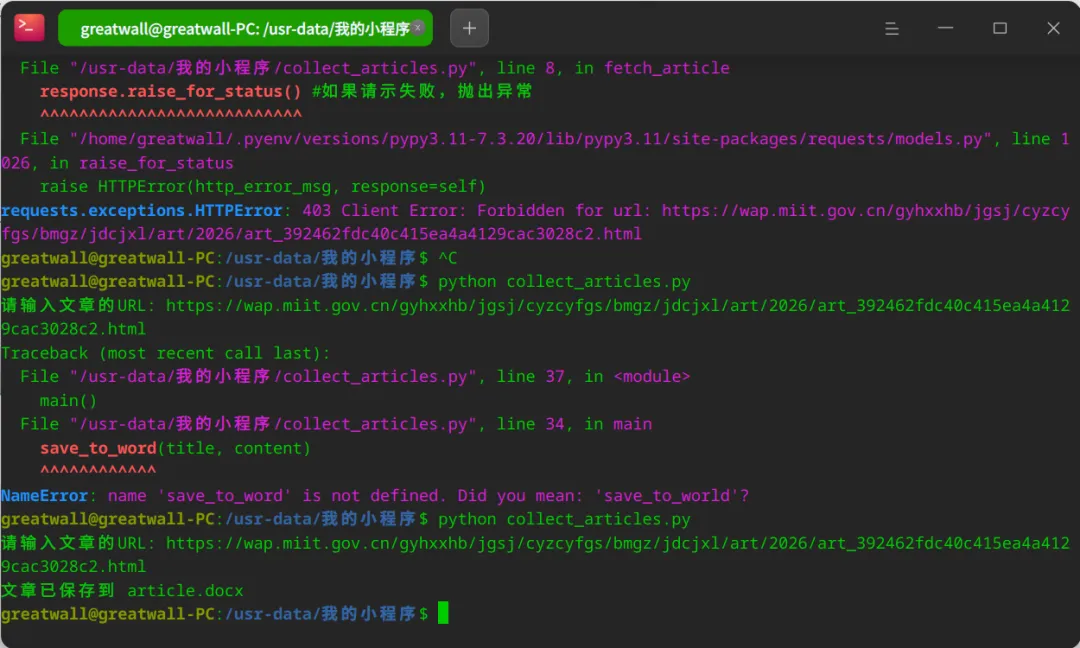
import requests from bs4 import BeautifulSoupfrom docx import Documentdef fetch_article(url): headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 safari/537.3'} #发送HTTP请求获取网页内容 response = requests.get(url, headers=headers) response.raise_for_status() #如果请示失败,抛出异常 #使用BeautifulSoup解析网页内容 soup = BeautifulSoup(response.text, 'html.parser') #根据网页结构提取文章标题和正文 #这里需要根据具体的网页结构调整 title = soup.find('h1').get_text() paragraphs = soup.find_all('p') article_text = '\n'.join([para.get_text() for para in paragraphs]) return title, article_textdef save_to_word(title, content, filename='article.docx'): #创建一个新的word文档 doc = Document()s doc.add_heading(title, level=1) doc.add_paragraph(content) doc.save(filename) print(f'文章已保存到 {filename}')def main(): url = input("请输入文章的URL: ") title, content = fetch_article(url) save_to_word(title, content)if __name__ == "__main__": main()