学习完动静态库实操,我们需要深入底层 —— 目标文件(.o)、库文件(.a/.so)、可执行程序,本质都是 ELF 格式文件,搞懂 ELF 才能真正理解链接和加载原理。源文件经gcc -c编译后生成可重定位目标文件(.o),特点:- 修改单个源文件后,只需重新编译该文件生成.o,无需全量编译,提升效率
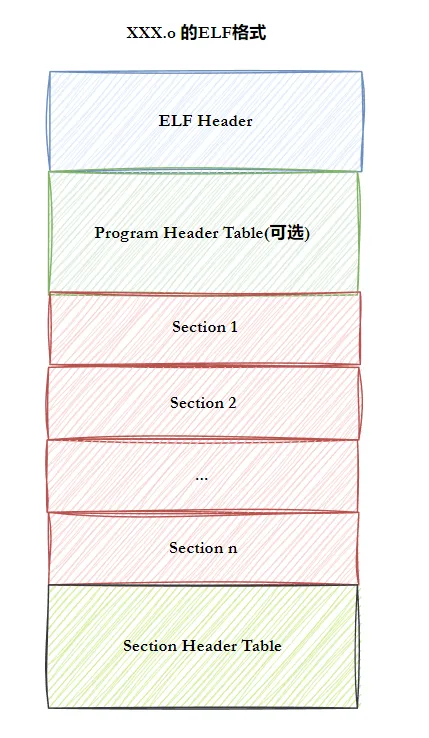
无论哪种ELF文件,核心结构都由四部分构成,从文件开头到结尾依次为:- ELF头(ELF Header):位于文件最开头,描述文件基本特征(如ELF版本,机器架构,文件类型,程序头表/节头表的位置和大小),核心作用是"定位文件的其他部分"
- 程序头表(Program Header Table):列举所有有效的段(segment)及属性(起始地址、长度、权限),面向程序加载阶段(操作系统加载时使用),可执行文件和动态库必需
- 节(Section):ELF的基本组成单位,是代码和数据的“逻辑划分”,常见节包括:
.text.data:数据节,存放已初始化的全局变量和静态变量(可读可写);.bss:未初始化数据节,存放未初始化或初始化为 0 的全局 / 静态变量(可读可写,不占用磁盘空间);.rodata:只读数据节,存放字符串常量、const 变量(只读);.symtab
- 节头表(Section Header Table):描述所有节(Section)的信息(名称、类型、大小、位置),面向编译链接阶段(链接器使用),所有 ELF 文件都包含;
4.3 段(segment)与节(section)的关系节是 “逻辑划分”(面向编译链接),段是 “内存映射划分”(面向加载运行)—— 操作系统加载时,会将属性相同的多个节合并为一个段(如.text和.rodata都是只读,合并为一个段),核心目的:1,减少内存页面碎片(内存管理基本单位是4KB,合并后减少页面占用)2,便于权限管理(如代码段设为“只读可执行”,数据段设为“可读可写”)对多个section进行合并的时候,合并原则会放在Program Header Table中通过readelf -S xxx:可以把Section Header Table里的内容读出来通过readelf -l(小写L) xxx:可以把Program Header Table里的内容读出来我们可以发现,一个可执行程序是由一个个的数据section构成,当需要链接时,形成新的Section Header Table,同时填充一下Program Header Table这个表。把哪些可以合并的数据结记录下来。
- 编译:每个源文件(.c)经gcc -c生成 ELF 格式的.o 文件,每个.o 包含自己的.text、.data、.bss 等节;
- 链接:链接器(ld)将多个.o 文件(含程序自身.o 和库的.o)的同名节合并
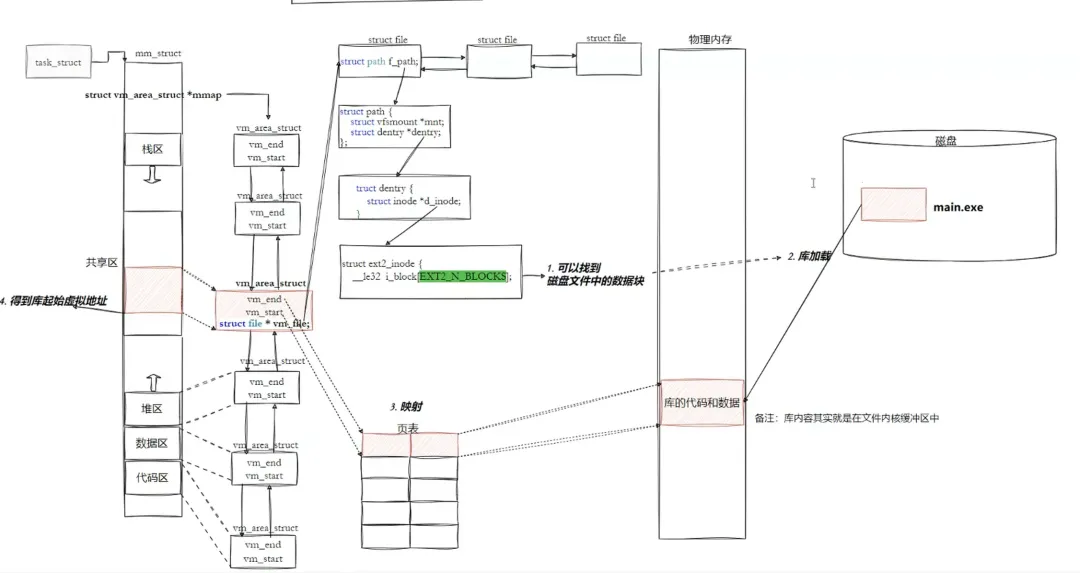
(如所有.o 的.text 合并为一个.text),同时解决跨文件符号引用(如A.B 的函数,用 B.o 的函数地址修正 A.o 的引用),最终生成 ELF 格式的可 执行程序可执行程序(ELF)存储在磁盘上,运行时操作系统将其加载到内存,步骤如下:- 创建进程:操作系统为程序创建task_struct和虚拟地址空间(mm_struct)
- 映射段到虚拟地址空间:根据程序头表,将ELF的段映射到进程虚拟地址空间,并设置权限
- 启动执行:将CPU的EIP设置为ELF头中的"程序入口地址"(_start,非main),CPU开始执行指令
虚拟地址不仅仅是操作系统内,进程看待内存的方式。
其实基于平坦模式的,从全0到全F的,对磁盘上的可执行程序编址,其实就是虚拟地址。
在平坦模式给可执行程序编址,习惯称为逻辑地址,在Linux系统里,一旦加载到内存了,用的地址已经是虚拟地址了。
- 一个 ELF 程序,在没有被加载到内存的时候,有没有地址呢?
- 进程
mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从哪里来的?
答案:
- 一个 ELF 程序,在没有被加载到内存的时候,本来就有地址,当代计算机工作的时候,都采用 "平坦模式" 进行工作。所以也要求 ELF 对自己的代码和数据进行统一编址,下面是
objdump -S反汇编之后的代码。
最左侧的就是 ELF 的虚拟地址,其实,严格意义上应该叫做逻辑地址(起始地址 + 偏移量),但是我们认为起始地址是 0。也就是说,其实虚拟地址在我们的程序还没有加载到内存的时候,就已经把可执行程序进行统一编址了。
- 进程
mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从哪里来的?从 ELF 各个segment,每个segment有自己的起始地址和自己的长度,用来初始化内核结构中的[start, end]等范围数据,另外再用详细地址,填充页表。
当我们加载程序时,操作系统会读取Program Header Table中的字段,用可执行程序的虚拟地址,用来初始化mm_struct,vm_area_struct
所以:虚拟地址机制,不光 OS 要支持,编译器也要支持。
现在我们形成对应的可执行,由多个section,多个.o文件合并的,合并是在干什么?
是把多个section进行合并之后,对可执行程序进行统一编址!
有了统一的地址之后,再去修改之前.o里面的call,把call对应的全0,改成真实的地址。
静态链接是链接器将 “程序.o 文件” 和 “静态库.o 文件” 合并为可执行程序的过程,核心是 “节合并” 和 “地址重定位”。程序中调用的跨文件函数 / 变量,在单个.o 中是 “未定义符号”(UND),链接器的核心工作就是解决这些符号的引用。例如:hello.c 调用 code.c 的 run () 函数,编译后 hello.o 的符号表中 run () 是 UND,code.o 的符号表中 run () 是已定义(DEF),链接器会:- 合并hello.o和code.o的.text,.data等节
- 用code.o中run()的地址,修正hello.o中call run()的跳转地址(地址重定位)
- 对printf等系统库函数,从C标准静态库(libc.a)中找到对应的.o文件,合并到可执行程序
objdump -d hello.o > hello.s //反汇编hello.o,查看calll指令地址(未链接时为0)readelf -s hello.o //查看hello.o的符号表,确认run()时UNDgcc hello.o code.o -o main //链接生成的可执行程序objdump -d main //反汇编main,查看call run()的地址已经修正
我们可以看到这里的 call 指令,它们分别对应之前调用的 printf 和 run 函数,但是你会发现他们的跳转地址都被设成了 0。那这是为什么呢?
其实就是在编译 hello.c 的时候,编译器是完全不知道 printf 和 run 函数的存在的,比如他们位于内存的哪个区块,代码长什么样都是不知道的。因此,编译器只能将这两个函数的跳转地址暂时设为 0。
这个地址会在哪个时候被修正?链接的时候!为了让链接器将来在链接时能够正确定位到这些被修正的地址,在代码块 (.data) 中还存在一个重定位表,这张表将来在链接的时候,就会根据表里记录的地址将其修正。
所以链接其实就是将编译之后的所有目标文件联通用到的一些静态库运行时库组合,瓶装成一个独立的可执行文件。其中就包括我们之前提到的地址修正,当所有模块组合在一起之后,链接器会根据我们的.o文件或者静态库中的重定位表找到那些需要被重定位的函数,全局变量,从而修正它们的地址。这起始就是静态链接的过程(在形成可执行程序之后,代码和程序已经有地址了)
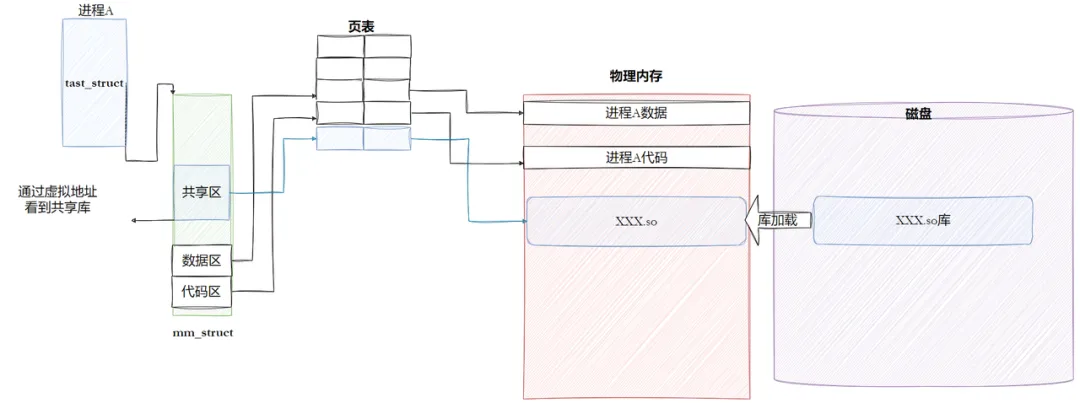
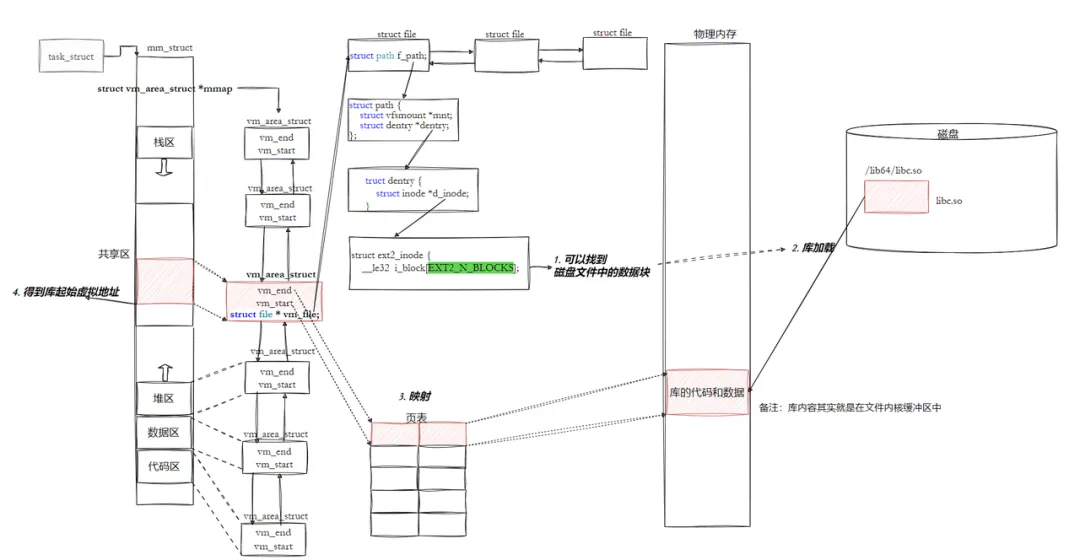
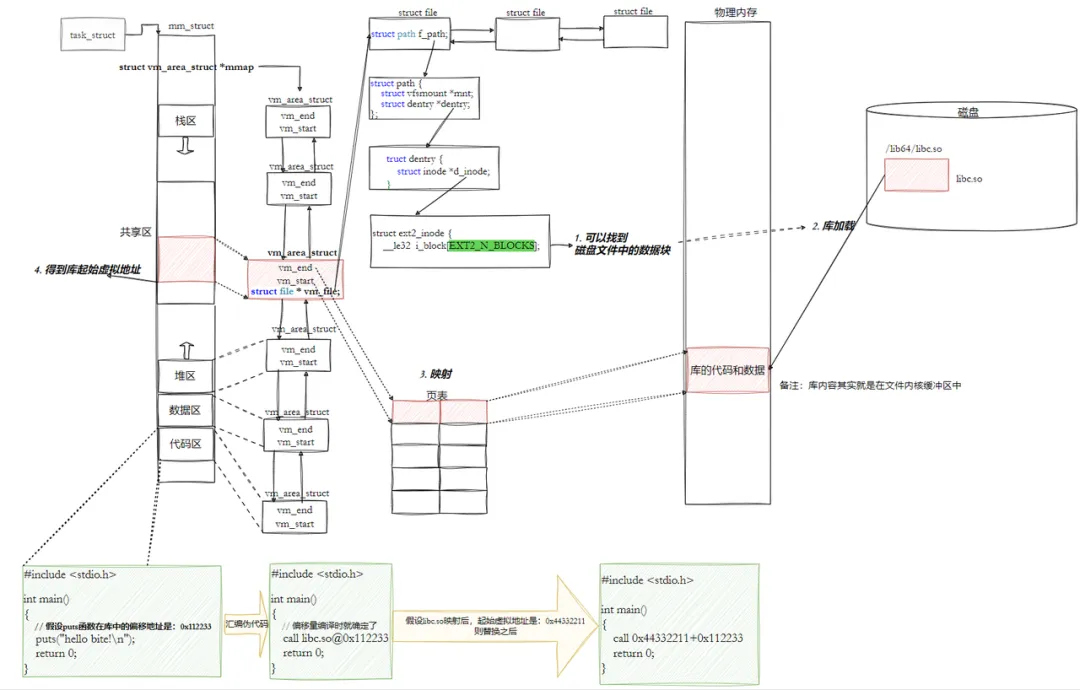
动态链接将链接过程推迟到程序运行时,核心是 “共享库代码 + 动态地址重定位”,实现多程序共享库资源。库也是ELF,也有自己对应的虚拟地址和物理地址。把库映射到当前进程的地址空间上。代码在调用库方法时,只需要从自己的代码区跳转到共享区,然后再返回,就完成了库函数的调用。
库函数调用:
1,被进程看到:动态库映射到进程的地址空间
2,被进程调用:在进程的地址空间中进行跳转。
- 程序启动时,动态链接器(ld-linux.so)加载程序依赖的动态库到内存
- 动态库加载地址不固定,操作系统根据地址空间使用情况动态分配;
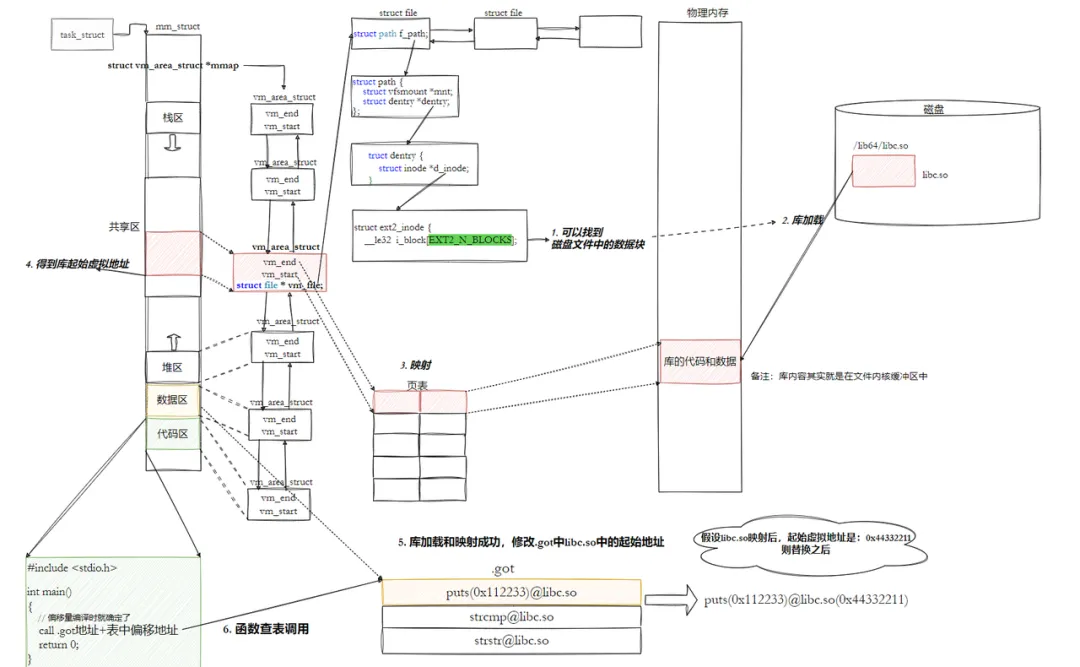
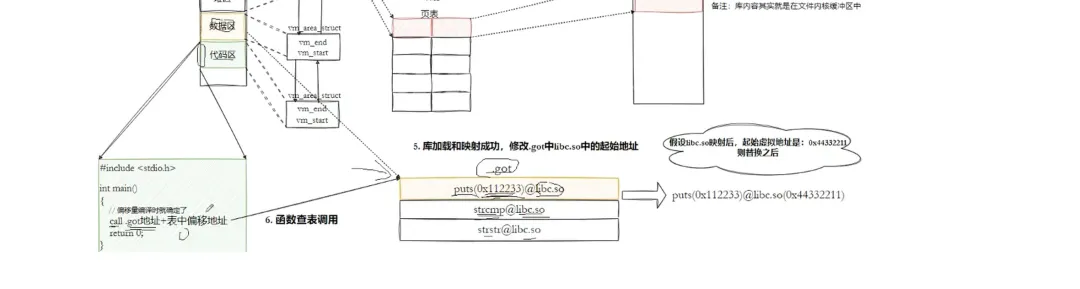
- 通过 “全局偏移表(GOT)” 和 “过程链接表(PLT)” 完成地址重定位,修正程序中对库函数的引用;
- 程序调用库函数时,通过 GOT 表找到库函数的真实地址,完成跳转。
动态链接实际上将链接的整个过程推迟到了程序加载的时候。比如我们去运行一个程序,操作系统会首先将程序的数据代码连同它用到的一系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,操作系统会根据当前地址空间的使用情况为它们动态分配一段内存。
当动态库被加载到内存以后,一旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。
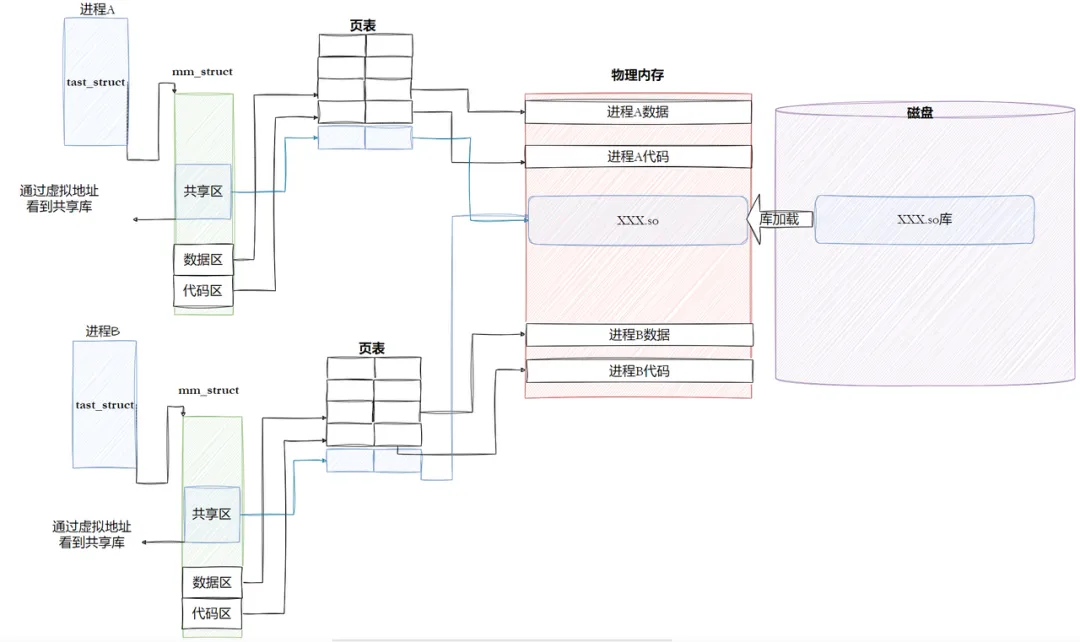
动态库需支持"加载到任意内存地址都能正常运行",核心时PIC——库中的代码采用相对编址,不依赖绝对地址,配合GOT表实现地址无关7.3 进程间共享动态库的原理
多个进程使用同一个动态库时,物理内存中只需一份库代码副本,核心是 “写时复制(Copy-On-Write)”:
- 库代码段(.text)是只读的,多个进程共享同一份物理内存;
- 库数据段(.data)是可写的,进程修改数据时,操作系统会为该进程复制一份数据副本,不影响其他进程。
注意:
- 动态库也是一个文件,要访问也是要被先加载,要加载也是要被打开的。
- 让我们的进程找到动态库的本质:也是文件操作,不过我们访问库函数,通过虚拟地址进行跳转访问的,所以需要把动态库映射到进程的地址空间中。
注意:
- 库已经被我们映射到了当前进程的地址空间中
- 库的虚拟起始地址我们也已经知道了
- 库中每一个方法的偏移量地址我们也知道
- 所有访问库中任意方法,只需要知道库的起始虚拟地址 + 方法偏移量即可定位库中的方法
- 而且:整个调用过程,是从代码区跳转到共享区,调用完毕再返回到代码区,整个过程完全在进程地址空间中进行的。
GOT是ELF文件中.data节的一片区域,存储库函数的真实地址,特点:2,程序编译时,GOT表初始化为PLT表中的桩代码地址3,第一次调用库函数时,桩代码触发动态链接器解析库函数地址,更新 GOT 表项;4,后续调用库函数时,直接通过 GOT 表找到真实地址,无需重复解析(延迟绑定,提升效率)。