🐍 Python数据分析中的逻辑回归:从原理到代码实现
❝用最通俗的语言,搞懂逻辑回归到底是什么,以及如何用Python轻松上手
📌 一、分类问题,从“是或否”开始
在数据分析中,除了预测房价这样的连续值(线性回归),我们更常遇到的是分类问题:
这类问题,答案只有两个选项,我们称之为二分类问题。而解决这类问题最经典、最常用的模型,就是逻辑回归(Logistic Regression)。
虽然名字里有“回归”,但它本质上是分类模型——专门用来处理“是/否”这种问题。
今天,我们就用Python一步步拆解逻辑回归,让你真正理解它的原理和代码实现。
🤔 二、为什么不能用线性回归?
你可能会想:既然线性回归能预测数值,那把“是”设为1,“否”设为0,直接用线性回归不行吗?
答案是不行,而且会有两个严重问题:
1️⃣ 预测值可能“越界”
线性回归的输出是任意实数,可能是1.5、2.3甚至-0.8,而概率必须在0~1之间。如果模型预测出1.5,怎么解释?——150%的概率?显然不合理。
2️⃣ 对异常点太敏感
线性回归希望最小化误差,一旦有个别极端样本(比如年龄很小却患癌),整个回归直线会被“拉偏”,导致分类效果大打折扣。
所以,我们需要一个能将任何实数压缩到0~1之间的函数——这就是Sigmoid函数的由来。
📈 三、逻辑回归的核心:Sigmoid函数
逻辑回归的核心公式只有一行:
[ p = \frac{1}{1 + e^{-z}} ]
其中:
- ( z = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \dots ) —— 这就是线性回归的那一套组合。
- ( p ) 就是事件发生的概率,取值范围永远在0~1之间。
这个函数的特点是:
- 当 ( z = 0 ) 时,( p = 0.5 ),刚好是分界线。
有了Sigmoid,我们就可以把任意线性组合的输出,映射成一个合理的概率。
🔍 四、换个角度:对数几率(Logit)
把上面的公式稍微变形:
[ \ln\left(\frac{p}{1-p}\right) = z = \beta_0 + \beta_1 x_1 + \dots ]
这里 (\frac{p}{1-p}) 叫做几率(odds)——也就是“发生概率”与“不发生概率”的比值。取对数后就是对数几率(log-odds)。
这个等式告诉我们:逻辑回归其实是在用线性回归去拟合对数几率。这样一来,系数的含义就非常直观了:
- 系数 ( \beta_1 ) 表示:**( x_1 ) 每增加一个单位,对数几率增加多少**。
- 但人们更喜欢用几率比(odds ratio)来解释:( e^{\beta_1} ) 表示 ( x_1 ) 增加一个单位时,几率变为原来的多少倍。
🐍 五、Python实战:用逻辑回归预测癌症风险
光说不练假把式,我们用一份简单的医学数据(来自smoke.csv)来演示逻辑回归的完整流程。
5.1 数据预览
数据包含四个字段:
- cancer:是否患癌(0=未患癌,1=患癌)——这是我们的目标变量
import pandas as pdimport statsmodels.api as sm# 读取数据data = pd.read_csv("smoke.csv")data.head()
5.2 数据预处理:处理分类变量
逻辑回归只能处理数值,所以我们需要把 gender 和 smoking 转换成虚拟变量。
我们用 pd.get_dummies,并设置 drop_first=True 来避免“虚拟变量陷阱”(多重共线性)。
# 生成虚拟变量logistics_data = pd.get_dummies( data, columns=["gender", "smoking"], dtype=int, drop_first=True)logistics_data.head()
- gender_male:1表示男性,0表示女性(女性为基准组)
- smoking_yes:1表示吸烟,0表示不吸烟(不吸烟为基准组)
5.3 划分变量并添加常数项
y = logistics_data['cancer'] # 因变量X = logistics_data.drop('cancer', axis=1) # 自变量# 添加常数项(截距)—— 和线性回归一样,不能少!X = sm.add_constant(X)
为什么又要加一列1?和线性回归同理,这一列1是截距的“占位符”,模型会自己学习出截距的具体数值,代表“基准风险”。
5.4 拟合逻辑回归模型
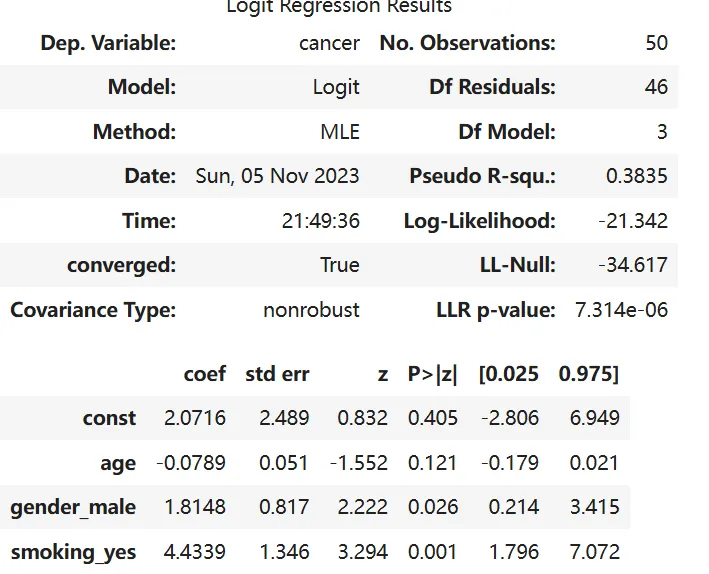
result = sm.Logit(y, X).fit()print(result.summary())
运行后会输出:
Optimization terminated successfully. Current function value: 0.426845 Iterations 7
以及详细的回归结果表格。
📊 六、结果解读:看懂模型输出
6.1 模型整体怎么样?
- Pseudo R-squ. = 0.3835:伪R方,类似于线性回归的R²,这里表示模型比空模型(只含截距)有显著改进。
- LLR p-value = 7.314e-06:远小于0.05,说明模型整体显著,至少有一个变量对癌症有影响。
6.2 哪些变量显著?
- age 的 p 值 = 0.121 > 0.05,不显著。说明在这个样本中,年龄对患癌的影响不明显(可能样本量小,或关系非线性)。
- gender_male 的 p 值 = 0.026 < 0.05,显著。
- smoking_yes 的 p 值 = 0.001 < 0.05,非常显著。
6.3 系数怎么解释?
逻辑回归的系数是对数几率,我们需要转换成几率比(odds ratio)才容易理解。
import numpy as npprint(np.exp(1.8148)) # gender_male 的 odds ratioprint(np.exp(4.4339)) # smoking_yes 的 odds ratio
输出:
6.1484.26
解释:
- 性别:在其他条件相同的情况下,男性患癌的几率是女性的 6.14倍。
- 吸烟:吸烟者患癌的几率是不吸烟者的 84.26倍!这完全符合医学常识,吸烟对肺癌的影响极大。
🧠 七、总结:逻辑回归的三点核心
- 系数的意义通过对数几率转为几率比,告诉我们每个因素对结果的影响程度。
逻辑回归简单、可解释性强,是许多复杂模型(如神经网络)的基础。当你下次遇到“是/否”的问题,不妨先从逻辑回归开始!
💬 互动时间
你在工作中用过逻辑回归吗?有没有遇到过特别显著的变量?欢迎在评论区分享你的案例~如果觉得本文对你有帮助,记得点赞、在看、转发三连支持哦!💖
📚 往期精选
(全文完)