1. 装饰器这种“包装”的思想在很多场景下都非常有用,例如:
2. 装饰器基础:理解“包装”的过程
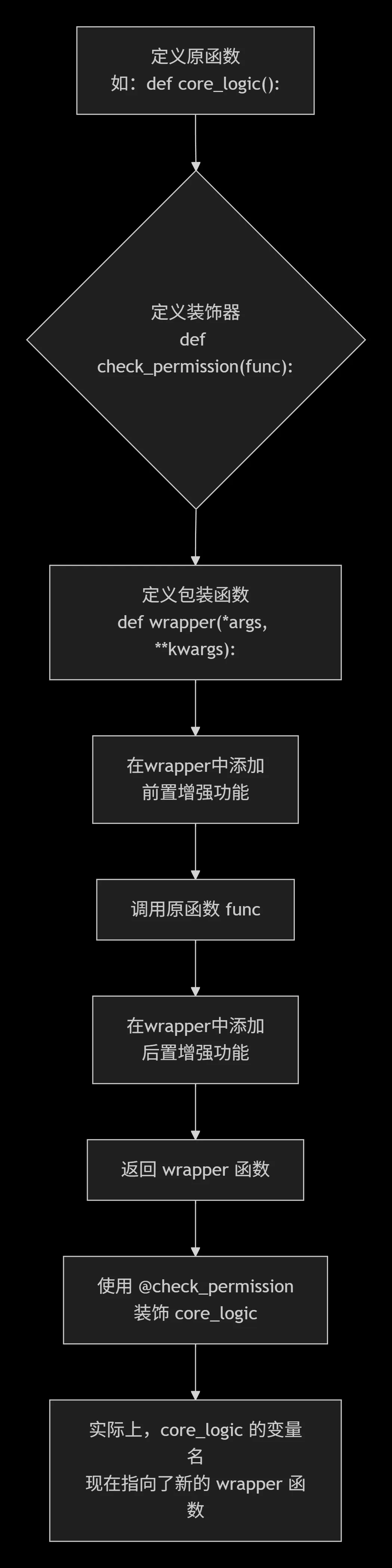
装饰器的核心语法使用 @ 符号,这其实是一种语法糖。它的工作流程可以用下图表示:
下面是一个具体的例子,创建一个用于权限检查的装饰器。
🎯语法要点:
def decorator(func)::装饰器本身是一个函数,接收被装饰的函数 func 作为参数。
def wrapper(*args, **kwargs)::在装饰器内部定义一个包装函数,它接收任意形式的参数(*args 和 **kwargs),以便能应用到任何函数上。
return wrapper:装饰器返回这个包装函数。
@decorator:语法糖,等价于 func = decorator(func)。
🌅示例:权限检查装饰器
假设有一个核心业务函数,需要确保用户有管理员权限才能执行。
def require_admin(func): """装饰器:模拟检查用户是否为管理员""" def wrapper(user, *args, **kwargs): if user.get('role') == 'admin': print("权限验证通过,执行核心操作...") # 调用原函数,并传递参数 result = func(user, *args, **kwargs) print("核心操作执行完毕,记录日志...") return result else: print(f"权限验证失败:用户 {user.get('name')} 不是管理员,无法执行操作。") return None return wrapper使用装饰器:@require_admindef delete_database(user, db_name): """模拟删除数据库的危险操作""" print(f"正在删除数据库:{db_name}...") return f"数据库 {db_name} 已被成功删除。"测试:admin_user = {'name': 'Alice', 'role': 'admin'}normal_user = {'name': 'Bob', 'role': 'guest'}print("--- 尝试用管理员账号操作 ---")result1 = delete_database(admin_user, "用户数据")print(f"结果:{result1}\n")print("--- 尝试用普通用户操作 ---")result2 = delete_database(normal_user, "用户数据")print(f"结果:{result2}")
输出结果:
--- 尝试用管理员账号操作 ---权限验证通过,执行核心操作...正在删除数据库:用户数据...核心操作执行完毕,记录日志...结果:数据库 用户数据 已被成功删除。--- 尝试用普通用户操作 ---权限验证失败:用户 Bob 不是管理员,无法执行操作。结果:None
3. 带参数的装饰器:更灵活的配置
有时希望装饰器本身能够接受参数,以实现不同的行为。这时就需要在装饰器外面再“套一层”,形成一个装饰器工厂。
🌲语法要点:
def decorator_factory(arg)::最外层函数接收装饰器的参数。
它内部返回一个实际的装饰器 def actual_decorator(func):。
最内层的 wrapper 函数仍然接收被装饰函数的参数。
⏳示例:带重试次数的装饰器
创建一个装饰器,当函数执行失败(抛出异常)时,可以自动重试指定次数。
def retry(max_attempts): """装饰器工厂:允许指定最大重试次数""" def decorator(func): def wrapper(*args, **kwargs): for attempt in range(1, max_attempts + 1): try: print(f"尝试第 {attempt} 次执行函数 {func.__name__}...") result = func(*args, **kwargs) return result # 执行成功,返回结果 except Exception as e: print(f"第 {attempt} 次执行失败,错误:{e}") if attempt == max_attempts: print("已达到最大重试次数,放弃执行。") raise # 重新抛出最后一次异常 else: print("准备重试...") return None # 实际上不会执行到这里 return wrapper return decorator使用装饰器,设定最大重试3次:@retry(max_attempts=3)def unstable_network_request(url): """模拟一个不稳定网络请求,随机失败""" import random print(f"正在请求:{url}") if random.choice([True, False]): # 模拟50%的失败率 raise ConnectionError("网络连接超时") return "请求成功,收到数据。"测试:if __name__ == "__main__": # 运行多次来观察重试效果 for i in range(2): print(f"\n--- 第 {i+1} 次调用 ---") try: result = unstable_network_request("http://api.example.com/data") print(f"最终结果:{result}") except ConnectionError: print("最终捕获到异常:所有重试都失败了。")
可能的输出结果(由于包含随机性,结果会变化):
--- 第 1 次调用 ---尝试第 1 次执行函数 unstable_network_request...正在请求:http://api.example.com/data第 1 次执行失败,错误:网络连接超时准备重试...尝试第 2 次执行函数 unstable_network_request...正在请求:http://api.example.com/data最终结果:请求成功,收到数据。--- 第 2 次调用 ---尝试第 1 次执行函数 unstable_network_request...正在请求:http://api.example.com/data第 1 次执行失败,错误:网络连接超时准备重试...尝试第 2 次执行函数 unstable_network_request...正在请求:http://api.example.com/data第 2 次执行失败,错误:网络连接超时准备重试...尝试第 3 次执行函数 unstable_network_request...正在请求:http://api.example.com/data第 3 次执行失败,错误:网络连接超时已达到最大重试次数,放弃执行。最终捕获到异常:所有重试都失败了。
4. 类装饰器:修改类的行为
装饰器不仅可以装饰函数,也可以装饰类。类装饰器接收一个类,并返回一个修改后的新类。
🏙️语法要点:
📱示例:为类添加属性和方法
我们创建一个装饰器,它可以自动为类添加一个 created_at 属性和一个 get_info 方法。
import timedef add_tracking_info(cls): """类装饰器:为类添加创建时间和信息获取方法""" # 为类添加一个新属性 cls.created_at = time.strftime("%Y-%m-%d %H:%M:%S") # 为类添加一个新方法 def get_info(self): return f"{self.__class__.__name__} 实例,创建于 {self.created_at},数据:{self.__dict__}" cls.get_info = get_info return cls # 返回修改后的类# 使用类装饰器@add_tracking_infoclass Product: def __init__(self, name, price): self.name = name self.price = price# 测试p1 = Product("笔记本电脑", 9999)print(p1.get_info())print(f"类的 created_at 属性:{Product.created_at}")p2 = Product("无线鼠标", 199)print(p2.get_info())
输出结果:
Product 实例,创建于 2024-05-21 10:30:45,数据:{'name': '笔记本电脑', 'price': 9999}类的 created_at 属性:2024-05-21 10:30:45Product 实例,创建于 2024-05-21 10:30:45,数据:{'name': '无线鼠标', 'price': 199}
注意:created_at 是类的属性,所有实例共享,因此值相同。如果要记录每个实例的创建时间,可以在 __init__ 中设置。
5. Python内置装饰器
Python自带了一些非常实用的装饰器,常用于面向对象编程。
| | |
| 将类中的方法定义为静态方法,可以通过类名直接调用,不需要传递self或cls参数。 | class MathUtils:@staticmethoddef add(x, y): return x + yMathUtils.add(1, 2) |
|
|
|
| 将类中的方法定义为类方法,第一个参数是类本身(cls),常用于定义工厂方法。 | class Person:@classmethoddef from_birth_year(cls, name, year):return cls(name, datetime.now().year - year) |
|
|
|
| 将一个方法转换成属性,调用时无需加括号。可以配合@<属性名>.setter和@<属性名>.deleter定义设置和删除行为,实现可控的属性访问。 | class Circle:@propertydef area(self):return 3.14 * self.radius ** 2 |
|
|
|
6. 多个装饰器的堆叠:由内而外的“包装”
可以将多个装饰器叠加在一个函数或类上。它们的执行顺序是从下往上(从靠近函数的装饰器开始)应用,但执行包装函数内的代码时,顺序会反过来。
🚀语法要点:
@decorator2
def func(): pass
💡示例:组合日志和计时功能
import timedef log_call(func): """装饰器:记录函数调用""" def wrapper(*args, **kwargs): print(f"[日志] 准备调用函数 {func.__name__}...") result = func(*args, **kwargs) print(f"[日志] 函数 {func.__name__} 调用结束") return result return wrapperdef timer(func): """装饰器:计算函数执行时间""" def wrapper(*args, **kwargs): start = time.time() result = func(*args, **kwargs) end = time.time() print(f"[计时] {func.__name__} 执行耗时: {end - start:.4f} 秒") return result return wrapper# 堆叠装饰器:先应用 @timer,再应用 @log_call# 等价于 process_data = log_call(timer(process_data))@log_call@timerdef process_data(size): """模拟数据处理""" print(f"正在处理 {size} 条数据...") time.sleep(0.5) # 模拟耗时 return f"处理完成 {size} 条"# 测试result = process_data(1000)print(f"返回值:{result}")
输出结果:
[日志] 准备调用函数 wrapper... # 来自外层装饰器 log_call 的前置动作正在处理 1000 条数据... # 实际函数执行[计时] process_data 执行耗时: 0.5002 秒 # 来自内层装饰器 timer 的后置动作[日志] 函数 wrapper 调用结束 # 来自外层装饰器 log_call 的后置动作返回值:处理完成 1000 条
可以看到,装饰器的应用顺序是从下到上,但执行增强功能的顺序是从上到下(像剥洋葱一样)。