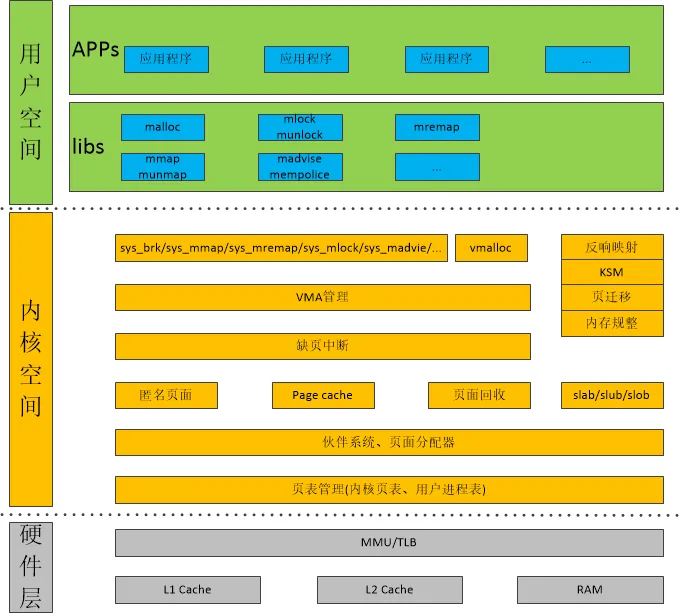
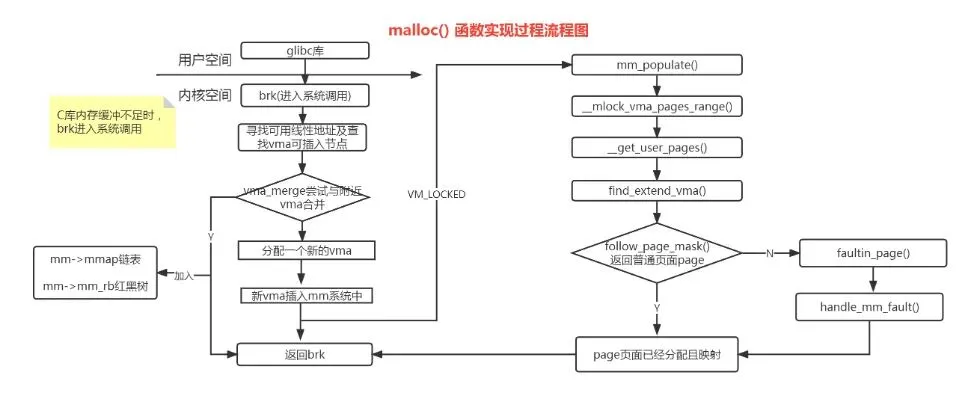
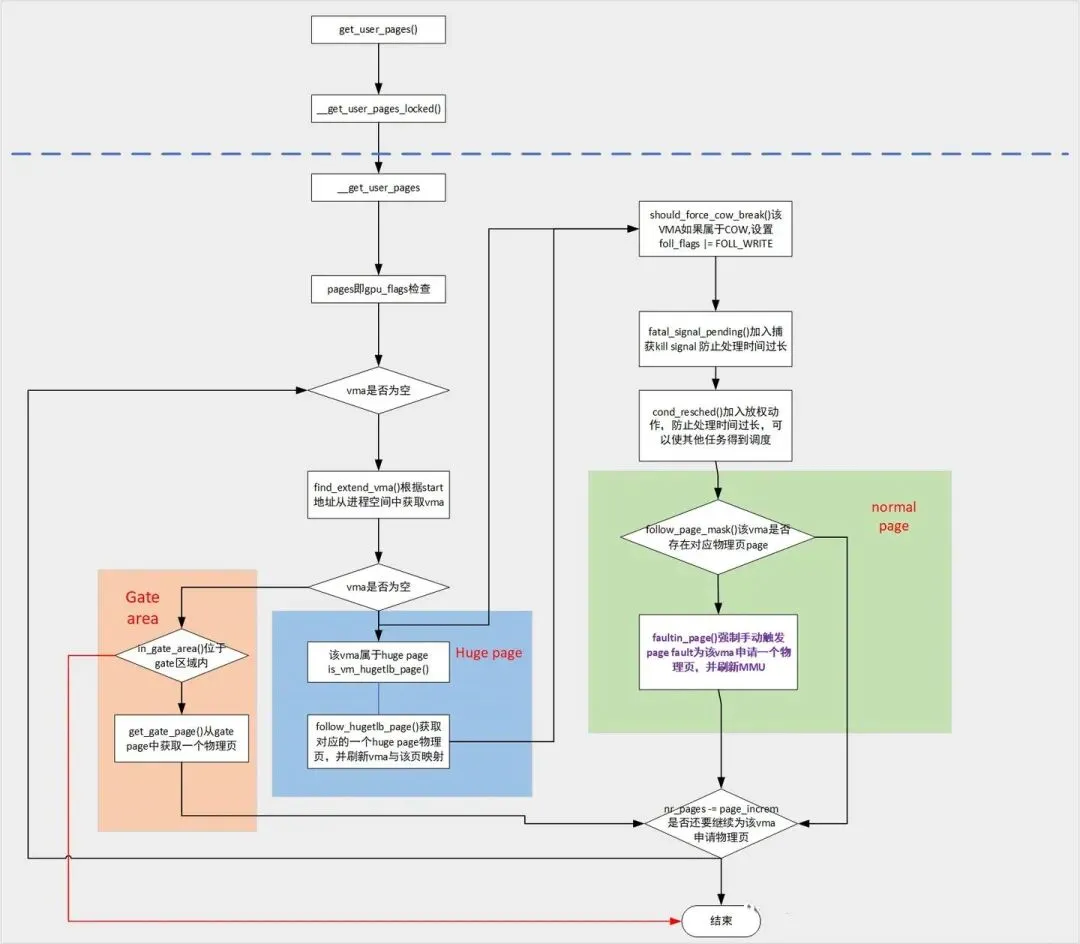
malloc()函数是C函数库封装的一个核心函数,对应的系统调用是brk()。
一、brk实现
要了解brk的实现首先需要知道进程用户空间的划分,以及struct mm_struct结构体中代码段、数据段、堆相关参数。
然后brk也是基于VMA,找到合适的虚拟地址空间,创建新的VMA并插入VMA红黑树和链表中。
首先看看mm_struct中代码段、数据段相关参数,和Linux内存管理框架图结合看。
由于栈向低地址空间增长,堆向高地址空间增长,所以栈的起始地址start_stack和堆的结束地址brk会改变。在栈和堆之间是
struct mm_struct {... unsigned long start_code, end_code, start_data, end_data;-----代码段从start_code到end_code;数据段从start_code到end_code。 unsigned long start_brk, brk, start_stack;--------------------堆从start_brk开始,brk表示堆的结束地址;栈从start_stack开始。 unsigned long arg_start, arg_end, env_start, env_end;---------表示参数列表和环境变量的起始和结束地址,这两个区域都位于栈的最高区域。...}
malloc是libc实现的接口,主要通过sys_brk这个系统调用分配内存。
SYSCALL_DEFINE1(brk, unsigned long, brk){ unsigned long retval; unsigned long newbrk, oldbrk; struct mm_struct *mm = current->mm; unsigned long min_brk; bool populate; down_write(&mm->mmap_sem);#ifdef CONFIG_COMPAT_BRK /* * CONFIG_COMPAT_BRK can still be overridden by setting * randomize_va_space to 2, which will still cause mm->start_brk * to be arbitrarily shifted */ if (current->brk_randomized) min_brk = mm->start_brk; else min_brk = mm->end_data;---------------确定堆空间的起始地址min_brk#else min_brk = mm->start_brk;#endif if (brk < min_brk)-----------------------brk地址不合法,在数据段 goto out; /* * Check against rlimit here. If this check is done later after the test * of oldbrk with newbrk then it can escape the test and let the data * segment grow beyond its set limit the in case where the limit is * not page aligned -Ram Gupta */ if (check_data_rlimit(rlimit(RLIMIT_DATA), brk, mm->start_brk, mm->end_data, mm->start_data))---------------如果RLIMIT_DATA不是RLIM_INFINITY,需要保证数据段加上brk区域不超过RLIMIT_DATA。 goto out; newbrk = PAGE_ALIGN(brk); oldbrk = PAGE_ALIGN(mm->brk);------------------------------页对齐 if (oldbrk == newbrk) goto set_brk; /* Always allow shrinking brk. */ if (brk <= mm->brk) { if (!do_munmap(mm, newbrk, oldbrk-newbrk))-------------如果brk变小,说明brk区在缩小,do_munmap来释放这一部分内存。 goto set_brk; goto out; } /* Check against existing mmap mappings. */ if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE))---查找一块VMA包含start_addr的VMA,说明老边界开始的地址空间已经在使用了,就不需要再寻找了。 goto out; /* Ok, looks good - let it rip. */ if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)---------------申请虚拟地址空间 goto out;set_brk: mm->brk = brk; populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0;---判断flags中是否有VM_LOCKED,通常由mlockall设置。 up_write(&mm->mmap_sem); if (populate) mm_populate(oldbrk, newbrk - oldbrk);-------------------------立即分配物理页面 return brk;out: retval = mm->brk; up_write(&mm->mmap_sem); return retval;}
do_brk仅进行匿名映射,申请从addr开始len大小的虚拟地址空间。
do_brk首先判断虚拟地址空间是否足够,然后查找VMA插入点,并判断是否能够进行VMA合并。如果找不到VMA插入点,则新建一个VMA,并更新到mm->mmap中。
/* * this is really a simplified "do_mmap". it only handles * anonymous maps. eventually we may be able to do some * brk-specific accounting here. */staticunsignedlongdo_brk(unsignedlong addr, unsignedlong len){ struct mm_struct *mm = current->mm; struct vm_area_struct *vma, *prev; unsigned long flags; struct rb_node **rb_link, *rb_parent; pgoff_t pgoff = addr >> PAGE_SHIFT; int error; len = PAGE_ALIGN(len); if (!len) return addr; flags = VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags; error = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED);---------------------------判断虚拟地址空间是否有足够的空间,这部分代码是跟体系结构紧耦合的。 if (error & ~PAGE_MASK) return error; error = mlock_future_check(mm, mm->def_flags, len); if (error) return error; /* * mm->mmap_sem is required to protect against another thread * changing the mappings in case we sleep. */ verify_mm_writelocked(mm); /* * Clear old maps. this also does some error checking for us */ munmap_back: if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) {----------循环遍历用户进程红黑树中的VMA,然后根据addr来查找合适的插入点 if (do_munmap(mm, addr, len)) return -ENOMEM; goto munmap_back; } /* Check against address space limits *after* clearing old maps... */ if (!may_expand_vm(mm, len >> PAGE_SHIFT)) return -ENOMEM; if (mm->map_count > sysctl_max_map_count) return -ENOMEM; if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT)) return -ENOMEM; /* Can we just expand an old private anonymous mapping? */ vma = vma_merge(mm, prev, addr, addr + len, flags,------------------------------去找有没有可能合并addr附近的VMA。 NULL, NULL, pgoff, NULL); if (vma) goto out; /* * create a vma struct for an anonymous mapping */ vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);----------------------------如果没办法合并,只能新创建一个VMA,VMA地址空间是[addr, addr+len]。 if (!vma) { vm_unacct_memory(len >> PAGE_SHIFT); return -ENOMEM; } INIT_LIST_HEAD(&vma->anon_vma_chain); vma->vm_mm = mm; vma->vm_start = addr; vma->vm_end = addr + len; vma->vm_pgoff = pgoff; vma->vm_flags = flags; vma->vm_page_prot = vm_get_page_prot(flags); vma_link(mm, vma, prev, rb_link, rb_parent);------------------------------------将新创建的VMA加入到mm->mmap链表和红黑树中。out: perf_event_mmap(vma); mm->total_vm += len >> PAGE_SHIFT; if (flags & VM_LOCKED) mm->locked_vm += (len >> PAGE_SHIFT); vma->vm_flags |= VM_SOFTDIRTY; return addr;}
从arch_pick_mmap_layout中可知,current->mm->get_ummapped_area对应的是arch_get_unmapped_area_topdown。
所以get_unmapped_area指向arch_get_unmapped_area_topdown
unsignedlongarch_get_unmapped_area_topdown(struct file *filp, constunsignedlong addr0, const unsigned long len, const unsigned long pgoff, const unsigned long flags){... info.flags = VM_UNMAPPED_AREA_TOPDOWN; info.length = len; info.low_limit = FIRST_USER_ADDRESS; info.high_limit = mm->mmap_base; info.align_mask = do_align ? (PAGE_MASK & (SHMLBA - 1)) : 0; info.align_offset = pgoff << PAGE_SHIFT; addr = vm_unmapped_area(&info); /* * A failed mmap() very likely causes application failure, * so fall back to the bottom-up function here. This scenario * can happen with large stack limits and large mmap() * allocations. */ if (addr & ~PAGE_MASK) { VM_BUG_ON(addr != -ENOMEM); info.flags = 0; info.low_limit = mm->mmap_base; info.high_limit = TASK_SIZE; addr = vm_unmapped_area(&info); } return addr;}
二、VM_LOCK情况
当指定VM_LOCK标志位时,表示需要马上为这块进程虚拟地址空间分配物理页面并建立映射关系。
mm_populate调用__mm_populate来分配页面,同时ignore_erros。
/* * __mm_populate - populate and/or mlock pages within a range of address space. * * This is used to implement mlock() and the MAP_POPULATE / MAP_LOCKED mmap * flags. VMAs must be already marked with the desired vm_flags, and * mmap_sem must not be held. */int __mm_populate(unsigned long start, unsigned long len, int ignore_errors){ struct mm_struct *mm = current->mm; unsigned long end, nstart, nend; struct vm_area_struct *vma = NULL; int locked = 0; long ret = 0; VM_BUG_ON(start & ~PAGE_MASK); VM_BUG_ON(len != PAGE_ALIGN(len)); end = start + len; for (nstart = start; nstart < end; nstart = nend) {----------------------------以start为起始地址,先通过find_vma()查找VMA。 /* * We want to fault in pages for [nstart; end) address range. * Find first corresponding VMA. */ if (!locked) { locked = 1; down_read(&mm->mmap_sem); vma = find_vma(mm, nstart); } else if (nstart >= vma->vm_end) vma = vma->vm_next; if (!vma || vma->vm_start >= end) break; /* * Set [nstart; nend) to intersection of desired address * range with the first VMA. Also, skip undesirable VMA types. */ nend = min(end, vma->vm_end); if (vma->vm_flags & (VM_IO | VM_PFNMAP)) continue; if (nstart < vma->vm_start) nstart = vma->vm_start; /* * Now fault in a range of pages. __mlock_vma_pages_range() * double checks the vma flags, so that it won't mlock pages * if the vma was already munlocked. */ ret = __mlock_vma_pages_range(vma, nstart, nend, &locked);------------------为vma分配物理内存 if (ret < 0) { if (ignore_errors) { ret = 0; continue; /* continue at next VMA */ } ret = __mlock_posix_error_return(ret); break; } nend = nstart + ret * PAGE_SIZE; ret = 0; } if (locked) up_read(&mm->mmap_sem); return ret; /* 0 or negative error code */}
__mlock_vma_pages_range为vma指定虚拟地址空间的物理页面:
/** * __mlock_vma_pages_range() - mlock a range of pages in the vma. * @vma: target vma * @start: start address * @end: end address * @nonblocking: * * This takes care of making the pages present too. * * return 0 on success, negative error code on error. * * vma->vm_mm->mmap_sem must be held. * * If @nonblocking is NULL, it may be held for read or write and will * be unperturbed. * * If @nonblocking is non-NULL, it must held for read only and may be * released. If it's released, *@nonblocking will be set to 0. */long __mlock_vma_pages_range(struct vm_area_struct *vma, unsigned long start, unsigned long end, int *nonblocking){ struct mm_struct *mm = vma->vm_mm; unsigned long nr_pages = (end - start) / PAGE_SIZE; int gup_flags; VM_BUG_ON(start & ~PAGE_MASK); VM_BUG_ON(end & ~PAGE_MASK); VM_BUG_ON_VMA(start < vma->vm_start, vma); VM_BUG_ON_VMA(end > vma->vm_end, vma); VM_BUG_ON_MM(!rwsem_is_locked(&mm->mmap_sem), mm);------------------------一些错误判断 gup_flags = FOLL_TOUCH | FOLL_MLOCK; /* * We want to touch writable mappings with a write fault in order * to break COW, except for shared mappings because these don't COW * and we would not want to dirty them for nothing. */ if ((vma->vm_flags & (VM_WRITE | VM_SHARED)) == VM_WRITE) gup_flags |= FOLL_WRITE; /* * We want mlock to succeed for regions that have any permissions * other than PROT_NONE. */ if (vma->vm_flags & (VM_READ | VM_WRITE | VM_EXEC)) gup_flags |= FOLL_FORCE; /* * We made sure addr is within a VMA, so the following will * not result in a stack expansion that recurses back here. */ return __get_user_pages(current, mm, start, nr_pages, gup_flags,----------为进程地址空间分配物理内存并且建立映射关系。 NULL, NULL, nonblocking);}
gup_flags的分配掩码如下:
#define FOLL_WRITE 0x01 /* check pte is writable */#define FOLL_TOUCH 0x02 /* mark page accessed */---------------------------------标记为可访问#define FOLL_GET 0x04 /* do get_page on page */#define FOLL_DUMP 0x08 /* give error on hole if it would be zero */#define FOLL_FORCE 0x10 /* get_user_pages read/write w/o permission */#define FOLL_NOWAIT 0x20 /* if a disk transfer is needed, start the IO * and return without waiting upon it */#define FOLL_MLOCK 0x40 /* mark page as mlocked */-------------------------------标记为mlocked#define FOLL_SPLIT 0x80 /* don't return transhuge pages, split them */#define FOLL_HWPOISON 0x100 /* check page is hwpoisoned */#define FOLL_NUMA 0x200 /* force NUMA hinting page fault */#define FOLL_MIGRATION 0x400 /* wait for page to replace migration entry */#define FOLL_TRIED 0x800 /* a retry, previous pass started an IO */
__get_user_pages是很重要的内存分配函数,用于为用户空间分配物理内存。
/** * __get_user_pages() - pin user pages in memory * @tsk: task_struct of target task * @mm: mm_struct of target mm * @start: starting user address * @nr_pages: number of pages from start to pin * @gup_flags: flags modifying pin behaviour * @pages: array that receives pointers to the pages pinned. * Should be at least nr_pages long. Or NULL, if caller * only intends to ensure the pages are faulted in. * @vmas: array of pointers to vmas corresponding to each page. * Or NULL if the caller does not require them. * @nonblocking: whether waiting for disk IO or mmap_sem contention * * Returns number of pages pinned. This may be fewer than the number * requested. If nr_pages is 0 or negative, returns 0. If no pages * were pinned, returns -errno. Each page returned must be released * with a put_page() call when it is finished with. vmas will only * remain valid while mmap_sem is held. * * Must be called with mmap_sem held. It may be released. See below. * * __get_user_pages walks a process's page tables and takes a reference to * each struct page that each user address corresponds to at a given * instant. That is, it takes the page that would be accessed if a user * thread accesses the given user virtual address at that instant. * * This does not guarantee that the page exists in the user mappings when * __get_user_pages returns, and there may even be a completely different * page there in some cases (eg. if mmapped pagecache has been invalidated * and subsequently re faulted). However it does guarantee that the page * won't be freed completely. And mostly callers simply care that the page * contains data that was valid *at some point in time*. Typically, an IO * or similar operation cannot guarantee anything stronger anyway because * locks can't be held over the syscall boundary. * * If @gup_flags & FOLL_WRITE == 0, the page must not be written to. If * the page is written to, set_page_dirty (or set_page_dirty_lock, as * appropriate) must be called after the page is finished with, and * before put_page is called. * * If @nonblocking != NULL, __get_user_pages will not wait for disk IO * or mmap_sem contention, and if waiting is needed to pin all pages, * *@nonblocking will be set to 0. Further, if @gup_flags does not * include FOLL_NOWAIT, the mmap_sem will be released via up_read() in * this case. * * A caller using such a combination of @nonblocking and @gup_flags * must therefore hold the mmap_sem for reading only, and recognize * when it's been released. Otherwise, it must be held for either * reading or writing and will not be released. * * In most cases, get_user_pages or get_user_pages_fast should be used * instead of __get_user_pages. __get_user_pages should be used only if * you need some special @gup_flags. */long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm, unsigned long start, unsigned long nr_pages, unsigned int gup_flags, struct page **pages, struct vm_area_struct **vmas, int *nonblocking){ long i = 0; unsigned int page_mask; struct vm_area_struct *vma = NULL; if (!nr_pages) return 0; VM_BUG_ON(!!pages != !!(gup_flags & FOLL_GET)); /* * If FOLL_FORCE is set then do not force a full fault as the hinting * fault information is unrelated to the reference behaviour of a task * using the address space */ if (!(gup_flags & FOLL_FORCE)) gup_flags |= FOLL_NUMA; do { struct page *page; unsigned int foll_flags = gup_flags; unsigned int page_increm; /* first iteration or cross vma bound */ if (!vma || start >= vma->vm_end) { vma = find_extend_vma(mm, start);------------------------------查找VMA,如果vma->vm_start大于查找地址start,那么它会尝试去扩增vma,吧vma->vm_start边界扩大到start中。 if (!vma && in_gate_area(mm, start)) { int ret; ret = get_gate_page(mm, start & PAGE_MASK gup_flags, &vma, pages ? &pages[i] : NULL); if (ret) return i ? : ret; page_mask = 0; goto next_page; } if (!vma || check_vma_flags(vma, gup_flags)) return i ? : -EFAULT; if (is_vm_hugetlb_page(vma)) { i = follow_hugetlb_page(mm, vma, pages, vmas, &start, &nr_pages, i, gup_flags); continue; } }retry: /* * If we have a pending SIGKILL, don't keep faulting pages and * potentially allocating memory. */ if (unlikely(fatal_signal_pending(current)))-----------------------如果收到一个SIGKILL信号,不需要继续内存分配,直接退出。 return i ? i : -ERESTARTSYS; cond_resched();----------------------------------------------------判断当前进程是否需要被调度。 page = follow_page_mask(vma, start, foll_flags, &page_mask);-------查看vma中的虚拟地址是否已经分配了物理内存。 if (!page) { int ret; ret = faultin_page(tsk, vma, start, &foll_flags, nonblocking); switch (ret) { case 0: goto retry; case -EFAULT: case -ENOMEM: case -EHWPOISON: return i ? i : ret; case -EBUSY: return i; case -ENOENT: goto next_page; } BUG(); } if (IS_ERR(page)) return i ? i : PTR_ERR(page); if (pages) {-------------------------------------------------------flush页面对应的cache pages[i] = page; flush_anon_page(vma, page, start); flush_dcache_page(page); page_mask = 0; }next_page: if (vmas) { vmas[i] = vma; page_mask = 0; } page_increm = 1 + (~(start >> PAGE_SHIFT) & page_mask); if (page_increm > nr_pages) page_increm = nr_pages; i += page_increm; start += page_increm * PAGE_SIZE; nr_pages -= page_increm; } while (nr_pages); return i;}
vm_normal_page根据pte来返回normal paging页面的struct page结构。
一些特殊映射的页面是不会返回struct page结构的,这些页面不希望被参与到内存管理的一些活动中,如页面回收、页迁移和KSM等。
内核尝试用pte_mkspecial()宏来设置PTE_SPECIAL软件定义的比特位,主要用途有:
vm_normal_page()函数把page页面分为两阵营,一个是normal page,另一个是special page。
normal page通常指正常mapping的页面,例如匿名页面、page cache和共享内存页面等。
special page通常指不正常mapping的页面,这些页面不希望参与内存管理的回收或者合并功能,比如:
VM_IO:为IO设备映射
VM_PFN_MAP:纯PFN映射
VM_MIXEDMAP:固定映射
三、malloc函数流程图
四、C库中malloc/free的实例
C库中的malloc和free对应的系统调用有brk/mmap和munmap。
brk在堆区申请内存,mmap在堆和栈之间申请内存。
针对不同大小的malloc和free情况下,堆的增长和收缩,或者mmap区的使用,下面一个例子很好的作了解释。
情况一、malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:
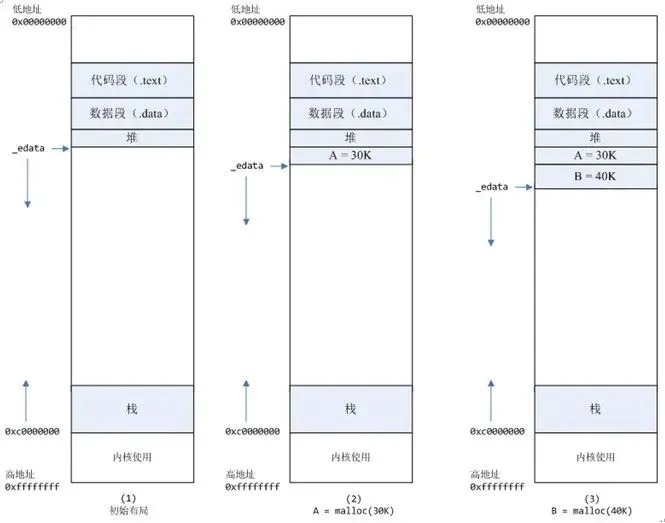
1、进程启动的时候,其(虚拟)内存空间的初始布局如图所示。
其中,mmap内存映射文件是在堆和栈的中间(例如libc-2.2.93.so,其它数据文件等),为了简单起见,省略了内存映射文件。
_edata指针(glibc里面定义)指向数据段的最高地址。
2、进程调用A=malloc(30K)以后,内存空间:
malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。
你可能会问:只要把_edata+30K就完成内存分配了?
事实是这样的,_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,内核才分配A这块内存对应的物理页。
如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3、进程调用B=malloc(40K)以后,内存空间如下图。
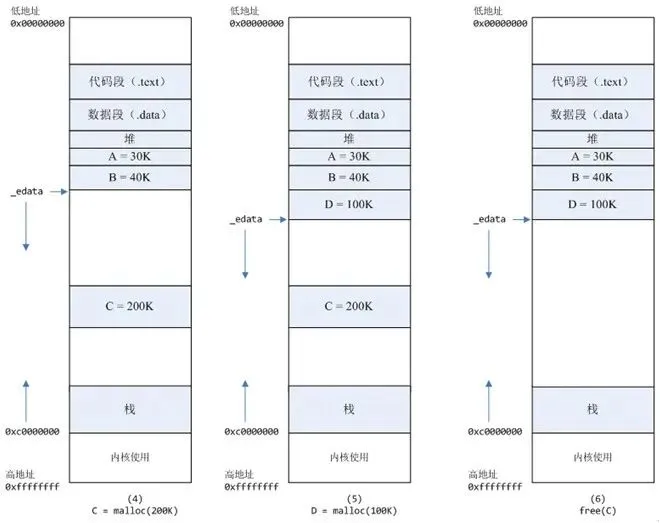
情况二、malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0):
4、进程调用C=malloc(200K)以后,内存空间:
默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。
这样子做主要是因为::
brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5、进程调用D=malloc(100K)以后,内存空间如下图;
6、进程调用free(C)以后,C对应的虚拟内存和物理内存一起释放。
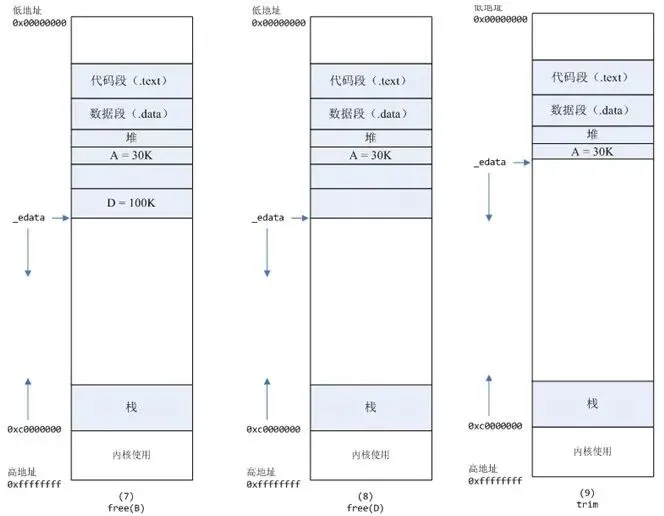
7、进程调用free(B)以后:
B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?
当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。 8、进程调用free(D)以后,如图8所示:
B和D连接起来,变成一块140K的空闲内存。
9、默认情况下:
当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。
在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
经过这几个步骤的演示,可以明确地看出malloc对进程地址空间brk和mmap区产生的影响。