Linux性能排查神器:top系列工具终极指南(工程师必备)
- 2026-07-04 06:49:41
很多工程师都有过这样的线上事故:
凌晨两点报警。
服务器 CPU 100%。接口超时。用户疯狂投诉。
你 SSH 上去,输入第一个命令:
top屏幕开始滚动,但你却不知道该看什么。
这是很多工程师都会经历的阶段。
真正的高手并不是会用 top,而是掌握一整套 Linux Top 系列性能排查工具链:
top —— 系统状态入口htop —— 进程交互分析iotop —— 磁盘 IO 排查iftop —— 网络流量定位atop —— 历史性能回放btop —— 现代终端监控神器
如果你能熟练掌握这 6 个工具,基本可以做到:
30 秒判断系统瓶颈3 分钟找到异常进程10 分钟给出解决方案这篇文章会系统讲清楚:
六大 Top 工具安装
每个工具的核心能力
真实线上排查方法
一套工程师常用的排查流程
读完你会拥有一套 完整的 Linux 性能排查武器库。
一、Linux 性能问题的本质
绝大多数 Linux 性能问题,本质只和 四种资源有关:
┌───────────────┐│ CPU │└───────┬───────┘│┌───────────┼───────────┐│ │ ││ Memory Disk│ │ │└───────────┼───────────┘│Network
也就是说:
系统慢 = CPU + 内存 + 磁盘 + 网络Top 系列工具其实就是对这四种资源的监控体系。
理解这一点,你就掌握了 Linux 性能分析的 核心模型。
二、top:所有性能排查的入口
Linux 几乎所有系统都自带 top。
启动:
top典型界面:
top - 13:46:24 up 2 days, 22:31, 2 users, load average: 0.63, 0.80, 0.89Tasks: 190 total, 1 running, 189 sleeping, 0 stopped, 0 zombie%Cpu(s): 11.1 us, 12.4 sy, 0.0 ni, 75.8 id, 0.2 wa, 0.0 hi, 0.5 si, 0.0 stMiB Mem : 3783.7 total, 295.6 free, 1306.2 used, 2369.9 buff/cacheMiB Swap: 0.0 total, 0.0 free, 0.0 used. 2477.5 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND48333 root 20 0 1660716 419656 75148 S 26.2 10.8 8,55 kube-apiserver48380 root 20 0 1435184 189292 88556 S 22.0 4.9 7,15 cilium-agent1113 root 20 0 2340800 103468 59464 S 16.7 2.7 8,48 kubelet2269 root 20 0 11.2g 105924 53132 S 13.1 2.7 6,28 etcd46206 root 20 0 1377984 133840 63416 S 7.2 3.5 161:06.43 kube-controller46249 root 20 0 1291668 70900 46200 S 3.9 1.8 81:45.80 kube-scheduler851 root 20 0 3651988 72992 38744 S 2.0 1.9 139:35.53 containerd77375 bgzxz 20 0 7868 5280 3232 R 1.3 0.1 0:00.23 top
top 的核心信息
CPU 状态
%Cpu(s): 11.1 us, 12.4 sy, 0.0 ni, 75.8 id, 0.2 wa, 0.0 hi, 0.5 si, 0.0 st解释:
us 用户态 CPUsy 内核态 CPUwa IO 等待id 空闲 CPU
经验判断:
wa > 30% → 磁盘 IO 瓶颈us 很高 → 计算密集sy 很高 → 系统调用密集
进程列表
关键字段:
PID 进程ID%CPU CPU使用率%MEM 内存占用RES 常驻内存
常用操作:
三、htop:更好用的 top
很多工程师登录服务器第一件事就是:
htop因为体验完全碾压 top。
安装
Ubuntusudo apt install htopCentOSsudo yum install epel-releasesudo yum install htop
htop 界面
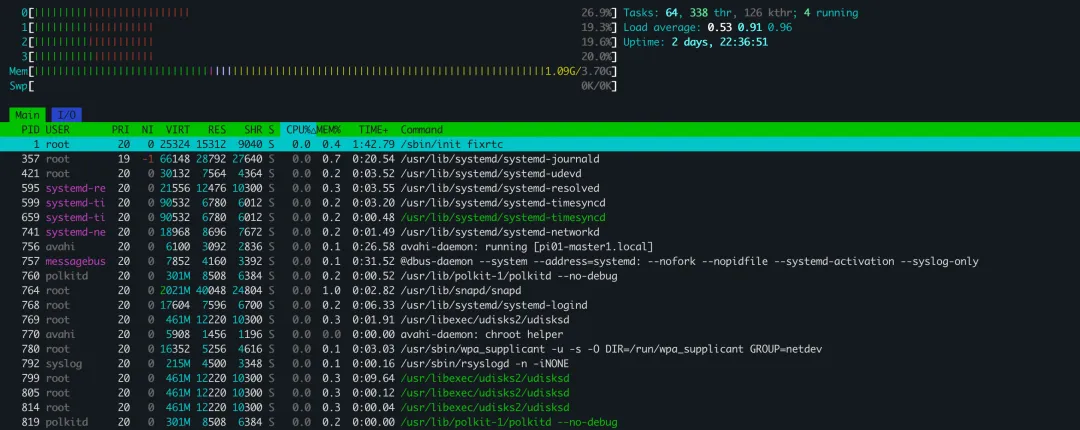
优势:
彩色 UI鼠标支持交互排序进程树查看进程树
按:
F5展示:
systemd├─docker│ ├─containerd│ └─java│ └─worker-thread
对于 Java、容器排查非常有价值。
四、iotop:磁盘 IO 排查神器
当服务器出现这种情况:
CPU不高Load很高系统卡顿十有八九是 磁盘 IO 问题。
这时就需要:
iotop安装
sudo apt install iotop运行:
sudo iotopiotop 界面
Total DISK READ: 0.00 B/s | Total DISK WRITE: 24.74 K/sCurrent DISK READ: 0.00 B/s | Current DISK WRITE: 24.74 K/sTID PRIO USER DISK READ DISK WRITE> COMMAND2269 be/4 root 0.00 B/s 12.37 K/s etcd --advertise-client-urls=https://192.168.123.100:2379 --cert-file=/etc/kuber~d/ca.crt --snapshot-count=10000 --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt72649 be/4 root 0.00 B/s 12.37 K/s etcd --advertise-client-urls=https://192.168.123.100:2379 --cert-file=/etc/kuber~d/ca.crt --snapshot-count=10000 --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt1 be/4 root 0.00 B/s 0.00 B/s init fixrtc2 be/4 root 0.00 B/s 0.00 B/s [kthreadd]3 be/4 root 0.00 B/s 0.00 B/s [pool_workqueue_release]4 be/0 root 0.00 B/s 0.00 B/s [kworker/R-rcu_gp]5 be/0 root 0.00 B/s 0.00 B/s [kworker/R-sync_wq]6 be/0 root 0.00 B/s 0.00 B/s [kworker/R-slub_flushwq]7 be/0 root 0.00 B/s 0.00 B/s [kworker/R-netns]12 be/0 root 0.00 B/s 0.00 B/s [kworker/R-mm_percpu_wq]13 be/4 root 0.00 B/s 0.00 B/s [rcu_tasks_kthread]14 be/4 root 0.00 B/s 0.00 B/s [rcu_tasks_rude_kthread]15 be/4 root 0.00 B/s 0.00 B/s [rcu_tasks_trace_kthread]
一眼就能看到:
哪个进程在疯狂读磁盘哪个进程在疯狂写磁盘五、iftop:网络流量分析神器
如果服务器突然:
带宽打满接口变慢最快的排查方式:
iftop安装
sudo apt install iftop运行:
sudo iftop -i eth0界面
192.168.1.10 => 10.0.0.5 20Mb192.168.1.10 <= 8.8.8.8 5Mb
含义:
=> 出站流量<= 入站流量
可以迅速定位:
哪个IP在吃带宽哪个服务在传数据分析每个进程网络使用:nethogs
六、atop:线上事故复盘神器
top 和 htop 有一个致命问题:
只能看当前状态如果服务器 凌晨出问题怎么办?
答案是:
atop安装
sudo apt install atop启动服务:
systemctl enable atopsystemctl start atop
它会定期记录系统状态:
CPUMemoryDiskNetworkProcess日志目录:
/var/log/atop查看历史
例如:
atop -r /var/log/atop/atop_20240301你可以像看录像一样 回放服务器性能状态。
七、btop:终端监控颜值天花板
如果说 htop 是升级版,
那 btop 是下一代监控工具。
安装
sudo snap install btop或者
brew install btop界面
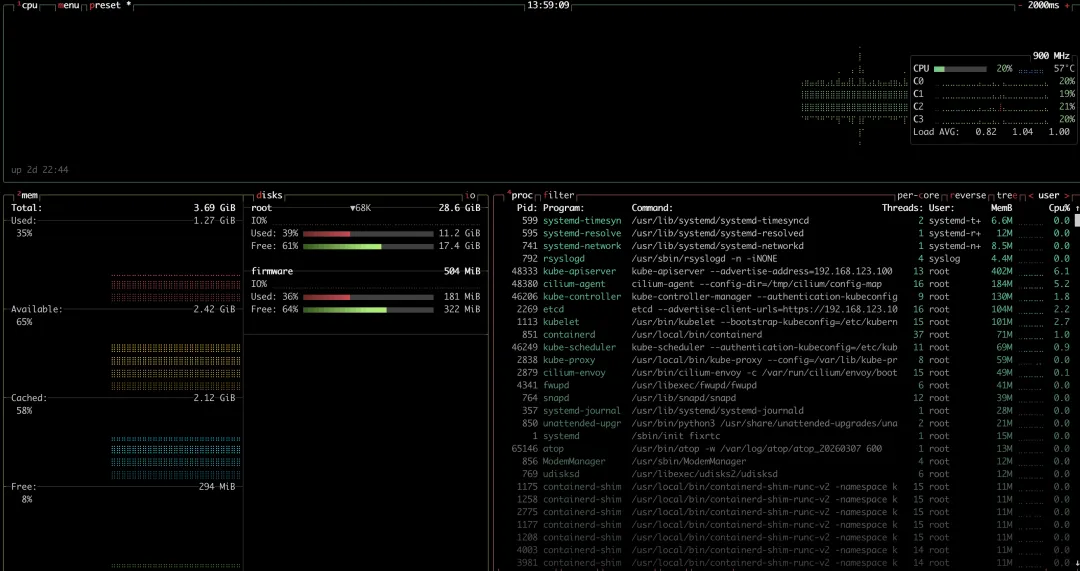
特点:
实时曲线磁盘统计网络监控GPU 支持可以说是 终端监控界的天花板。
八、高手的排查流程
经验丰富的工程师通常按这个顺序排查:
系统变慢│▼top│┌───────┼────────┐▼ ▼ ▼CPU高 IO等待高 网络慢│ │ │htop iotop iftop│ │ │└───────┴────────┘│atop
这套方法可以解决 90% 的线上性能问题。
九、真正的高手会再加两个工具
Top 系列解决的是:
谁在用资源但更深的问题是:
为什么用资源这时通常需要:
perfstrace
完整工具链:
top↓htop↓iotop↓iftop↓atop↓perf↓FlameGraph
结语
Linux 性能排查没有捷径。
但掌握top系列工具,你会获得一项非常关键的能力:
快速理解服务器状态对于后端工程师来说,这是一项必须掌握的基本功。
如果你能做到:
30秒判断瓶颈3分钟定位进程10分钟提出方案你已经超过 80% 的工程师。

