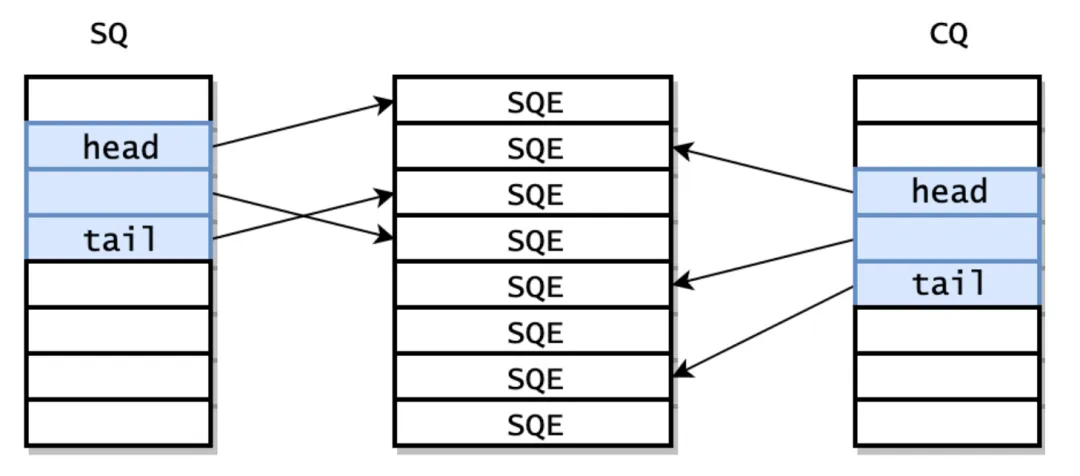
小编今天这篇文章给大家分享一下,工作中用到的一个高性能异步 I/O 模型: io_uring。小编个人认为这是用到的最强的异步 I/O~既然 io_uring 这么优秀,就让小编带你来学习一下其先进思想吧!在 Linux 系统中,I/O 性能一直是系统和应用性能优化的重要环节。传统的异步 I/O(如 epoll、aio)存在一些瓶颈和复杂性,而 Linux 内核从 5.1 版本开始引入了 io_uring,为高性能异步 I/O 提供了全新方案。往下看哈~io_uring 是 Linux 内核提供的一个 高性能、低延迟的异步 IO 框架。它的设计目标是:传统的异步 IO 每次提交 IO 请求都需要一次系统调用 (io_submit) 或多次切换用户/内核态,而 io_uring 可以通过共享环形缓冲区(ring buffer)批量提交和获取 IO 请求。内核与用户空间共享内存环形队列,使多线程高并发环境下的 IO 更高效。核心思想:通过内核和用户空间共享环形队列(submission queue或completion queue,简称SQ或CQ)减少系统调用开销,同时提供异步 IO 功能。io_uring 的核心是两个环形队列(SQ/CQ)+ 一个提交队列入口(SQE)数组,所有 I/O 操作都围绕这三个组件完成:1. 提交队列(Submission Queue,SQ)用户态向内核提交 I/O 任务(如读文件、写网络)的 “任务队列”,用户态将待执行的 I/O 操作描述符(SQE)放入该队列,内核从队列中取任务执行。- 环形队列(循环数组),用 head/tail 指针标记队列的读写位置(用户态只更新 tail,内核更新 head);
- 队列元素是「提交队列项(Submission Queue Entry,SQE)」,每个 SQE 描述一个具体的 I/O 操作(如操作类型、文件描述符、数据缓冲区地址、偏移量等);
- 共享内存实现:队列位于用户态与内核态共享的内存区域,无需系统调用即可向队列写入任务(仅需内存操作)。
2. 完成队列(Completion Queue,CQ)内核将已完成的 I/O 任务结果回写给用户态的 “结果队列”,用户态从该队列读取任务执行状态(成功 / 失败、实际读写字节数等)。- 同样是环形队列,用 head/tail 指针标记(内核更新 tail,用户态更新 head);
- 队列元素是「完成队列项(Completion Queue Entry,CQE)」,每个 CQE 对应一个已完成的 SQE,包含操作结果(错误码、返回值)、SQE 的标识(user_data)等;
- 支持批量通知:内核可批量将多个完成的任务结果写入队列,减少用户态轮询开销。
3. SQE 数组(Submission Queue Entry Array)作用:存储所有待提交的 SQE 结构体,是 SQ 队列的 “数据池”——SQ 队列中实际存储的是 SQE 在数组中的索引,而非 SQE 本身,减少队列数据移动开销。 | |
|---|
opcode | 操作类型(如 IORING_OP_READ 读文件、IORING_OP_WRITE 写文件、IORING_OP_ACCEPT 接受连接等) |
fd | |
addr | 用户态数据缓冲区地址(读操作:内核写入数据的地址;写操作:用户态待写入数据的地址) |
len | |
off | |
user_data | 用户自定义标识(用于关联 SQE 和 CQE,比如标记任务 ID) |
flags | 操作标志(如 IOSQE_IO_LINK 链式操作、IOSQE_ASYNC 强制异步) |
4. io_uring 核心工作流程(以文件读操作为例)- 初始化:调用 io_uring_queue_init() 创建 io_uring 实例,内核分配共享内存,初始化 SQ/CQ 队列和 SQE 数组;
- 获取空闲 SQE:调用 io_uring_get_sqe() 从 SQE 数组中获取一个空闲的 SQE;
- 填充 SQE:设置 SQE 的 opcode=IORING_OP_READ、fd(目标文件)、addr(用户态缓冲区)、len(读取长度)、off(文件偏移)、user_data(自定义标识);
- 提交 SQE 到 SQ 队列:调用 io_uring_submit() 提交任务(本质是更新 SQ 队列的 tail 指针,通知内核有新任务);
- 内核执行任务:内核从 SQ 队列取出 SQE,执行读文件操作,将数据写入用户态缓冲区;
- 内核写入 CQE:操作完成后,内核创建对应的 CQE(包含结果、user_data),写入 CQ 队列,更新 CQ 队列的 tail 指针;
- 用户态获取结果:调用 io_uring_wait_cqe()/io_uring_peek_cqe() 从 CQ 队列读取 CQE,判断操作是否成功,处理数据;
- 释放 CQE:调用 io_uring_cqe_seen() 更新 CQ 队列的 head 指针,标记该 CQE 已处理。
#include<liburing.h>structio_uring ring;io_uring_queue_init(QUEUE_DEPTH, &ring, 0);
- io_uring_queue_init 会创建 SQ 和 CQ 并映射到用户空间。
- liburing 是官方推荐的用户态封装库,更易使用。
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);io_uring_prep_read(sqe, fd, buffer, size, offset);io_uring_submit(&ring);
- io_uring_get_sqe:获取一个 submission queue entry。
- io_uring_prep_read/write:准备具体 IO 请求。
struct io_uring_cqe *cqe;io_uring_wait_cqe(&ring, &cqe);int res = cqe->res;io_uring_cqe_seen(&ring, cqe);
- io_uring_wait_cqe:阻塞等待完成事件。
- io_uring_cqe_seen:告诉内核该事件已处理。
- io_uring_peek_cqe:非阻塞检查 CQ。
- io_uring_register_buffers:注册固定内存缓冲区,减少内存拷贝。
- io_uring_register_files:注册文件描述符,减少重复查表开销。
处理成千上万并发 socket,替代 epoll + read/write。结合 IORING_OP_TIMEOUT 支持异步定时操作。⚡ 实际案例:Facebook 的 Seastar 框架在 Linux 上使用 io_uring 构建高性能网络服务,每秒处理百万级请求。#include<liburing.h>#include<fcntl.h>#include<stdio.h>#include<unistd.h>#include<stdlib.h>#define QUEUE_DEPTH 32#define BUF_SIZE 4096intmain(){ struct io_uring ring; io_uring_queue_init(QUEUE_DEPTH, &ring, 0); int fd = open("test.txt", O_RDONLY); if (fd < 0) return 1; char *buffer = malloc(BUF_SIZE); struct io_uring_sqe *sqe = io_uring_get_sqe(&ring); io_uring_prep_read(sqe, fd, buffer, BUF_SIZE, 0); io_uring_submit(&ring); struct io_uring_cqe *cqe; io_uring_wait_cqe(&ring, &cqe); printf("Read %d bytes\n", cqe->res); io_uring_cqe_seen(&ring, cqe); free(buffer); close(fd); io_uring_queue_exit(&ring); return 0;}
初始化 ring → 获取 SQE → 准备读操作 → 提交 → 等待完成 → 处理结果。io_uring 是 Linux 异步 IO 的现代化解决方案,特点:丰富接口:支持文件、网络、定时器等多种 IO 类型。可优化空间大:固定缓冲区、注册文件、批量提交、多线程分离。相比传统 epoll + read/write,io_uring 在高并发、大 IO 场景下性能优势明显,正逐步成为 Linux 高性能服务器和数据库的首选 IO 框架。