上一篇里我测试了使用提示词生成一张ai的图片,我们把自己想要的图片用文字描述清楚,提交后台大模型,模型根据我们的描述(提示词)给我们动态生成一张图片
本篇继续图片生成
我们还有一种需求,就是根据图片生成图片,简单理解就是图片编辑了,上传原始图片给模型,并提出我们要调整的内容(提示词),大数据根据原图和提示词给我们生成一张图片
这几天测试了两种常用场景:人像风格重绘、图片编辑,其实还有很多(图片背景生成、画面扩展等),我们一个一个来看
1、人像风格重绘
千问人像风格重绘用的是wanx-style-repaint-v1模型,支持:复古漫画、3D童话、二次元、小清新、未来科技、国画古风、将军百战等风格
我们直接贴代码哈,看看是怎么实现的
A、将本地图片转换成Base64编码
原始图片上传大数据的一种实现方法
先将图片转换成Base64编码,后边以参数形式传给模型
# 格式为 data:{MIME_type};base64,{base64_data}
def encode_file(file_path):
mime_type, _ = mimetypes.guess_type(file_path)
if not mime_type or not mime_type.startswith("image/"):
raise ValueError("不支持或无法识别的图像格式")
with open(file_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{mime_type};base64,{encoded_string}"
B、异步提交风格重绘任务
def getimgtrans(file_path):
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/image-generation/generation"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"X-DashScope-Async": "enable" # 异步调用
}
image_url=encode_file(file_path)
body = {
"model": "wanx-style-repaint-v1",
"input": {
#"image_url": "https://vigen-video.oss-cn-shanghai.aliyuncs.com/demo_image/image_demo_input.png",
"image_url": image_url,
"style_index": 3 # 默认:小清新,0=复古漫画, 1=3D童话, 2=二次元, 3=小清新, 4=未来科技等
}
}
response = requests.post(url, headers=headers, json=body)
if response.status_code == HTTPStatus.OK:
task_id = response.json().get('output', {}).get('task_id')
print(f"任务提交成功,任务ID为: {task_id}")
return task_id
else:
print(f"任务提交失败,状态码: {response.status_code}, 响应: {response.text}")
return None
C、查询重绘任务,并反馈结果url
def query_task_result(task_id):
if not task_id:
return
url = f"https://dashscope.aliyuncs.com/api/v1/tasks/{task_id}"
headers = {"Authorization": f"Bearer {api_key}"}
print("开始查询任务状态...")
while True:
response = requests.get(url, headers=headers)
if response.status_code != HTTPStatus.OK:
print(f"查询失败,状态码: {response.status_code}, 响应: {response.text}")
break
response_data = response.json()
task_status = response_data.get('output', {}).get('task_status')
if task_status == 'SUCCEEDED':
print("任务成功完成!")
results = response_data.get('output', {}).get('results', [])
for i, result in enumerate(results):
print(f"生成图片_{i + 1} URL: {result.get('url')}")
break
elif task_status == 'FAILED':
print(f"任务失败。错误信息: {response_data}")
break
else:
print(f"任务正在处理中,当前状态: {task_status}...")
time.sleep(5) # 等待5秒后再次查询
这里我做的是传原始图片过去,即只输入一个参数。后边也可以改造一下,加上图片"风格"的交互
人像风格重绘是一个异步任务,将图片传给大模型后,大模型会反馈一个任务id,客户端定期去查询任务的运行情况,在模型处理完成后,提取结果图片的url地址打印出来
2、图片编辑
这里需要输入2个参数:原始图片及提示词“你想要把图片转换成什么”
图片编辑用的是这个模型:qwen-image-2.0-pro,一次可以提交最多6张图片
我们也是将本地图片转换成Base64编码,再以参数形式传给模型
def imgpromptedit(prompt,v_impdir):
image_url=encode_file(v_impdir)
messages = [{"role": "user","content": [{"image": image_url},{"text": prompt}]}]
print('----同步调用,请等待任务执行----')
response = MultiModalConversation.call(
api_key=api_key,
model="qwen-image-2.0-pro",
messages=messages,
stream=False,
n=1,
watermark=False,
negative_prompt=" ",
prompt_extend=True,
size="1024*1536",
)
if response.status_code == 200:
# 如需查看完整响应,请取消下行注释
# print(json.dumps(response, ensure_ascii=False))
rt_str='根据您的提示'+prompt+'",我们生成如下地址图片,请自行下载:\n'
for i, content in enumerate(response.output.choices[0].message.content):
print(f"输出图像{i+1}的URL:{content['image']}")
else:
print(f"HTTP返回码:{response.status_code}")
print(f"错误码:{response.code}")
print(f"错误信息:{response.message}")
图片编辑是一个同步任务,提交提示词和原始素材后,要一直等大模型反馈,并将模型处理好的图片地址打印出来
另外就是调度的main函数改造,这里就不贴出来了,大家如果有需要可以后台找我拿
我们看看运行结果吧....
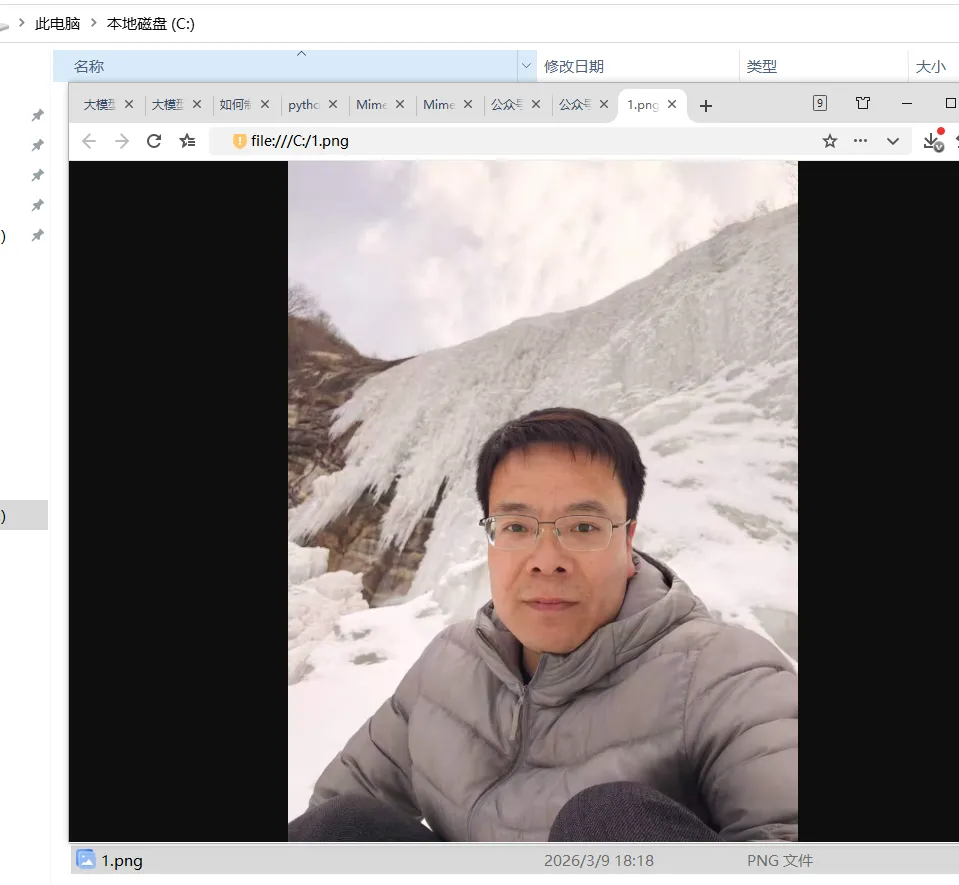
原始图片就选我微信图像了(请不要喷太狠哈...谢谢!)
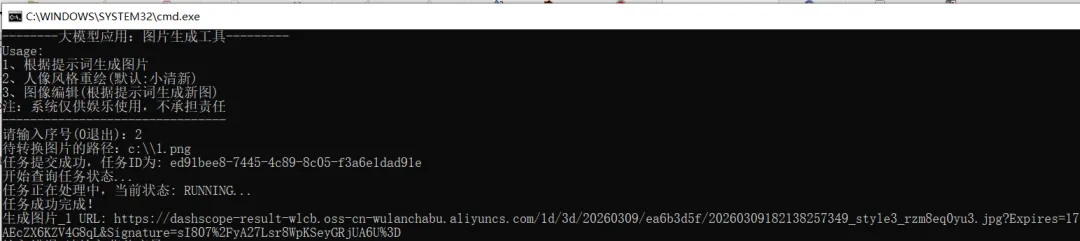
I、人像风格重绘测试
重绘的地址:https://dashscope-result-wlcb.oss-cn-wulanchabu.aliyuncs.com/1d/3d/20260309/ea6b3d5f/20260309182138257349_style3_rzm8eq0yu3.jpg?Expires=1773138103&OSSAccessKeyId=LTAI5tQZd8AEcZX6KZV4G8qL&Signature=sI807%2FyA27Lsr8WpKSeyGRjUA6U%3D
打开如下:
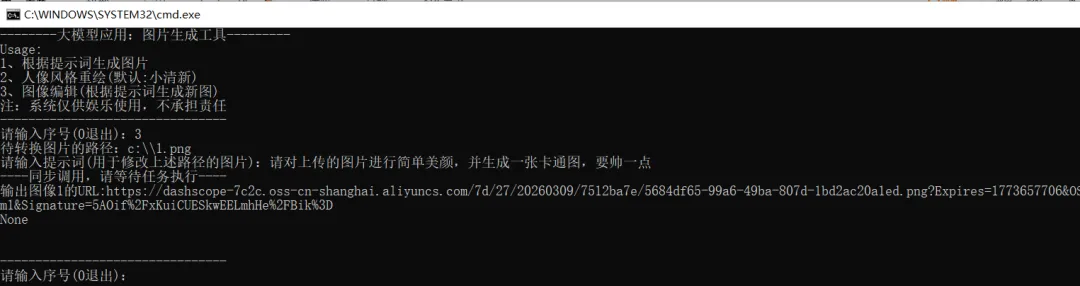
II、图像编辑测试
大数据处理完成反馈的图像地址:https://dashscope-7c2c.oss-cn-shanghai.aliyuncs.com/7d/27/20260309/7512ba7e/5684df65-99a6-49ba-807d-1bd2ac20a1ed.png?Expires=1773657706&OSSAccessKeyId=LTAI5tPxpiCM2hjmWrFXrym1&Signature=5AOif%2FxKuiCUESkwEELmhHe%2FBik%3D
打开如下:
ok,就这些了...下班了,撤了
有需要看代码的小伙伴,后台私聊哈