【重复测量纵向数据】Python05广义线性混合模型(Generalized Linear Mixed Models,GLMM)
- 2026-07-03 18:22:11

纵向数据是在不同时间点上对同一组个体、物体或实体进行重复观测所收集的数据。它就像给研究对象拍摄“动态影像”,能记录其随时间变化的过程,帮助我们理解趋势、模式和影响因素。

5.广义线性混合模型
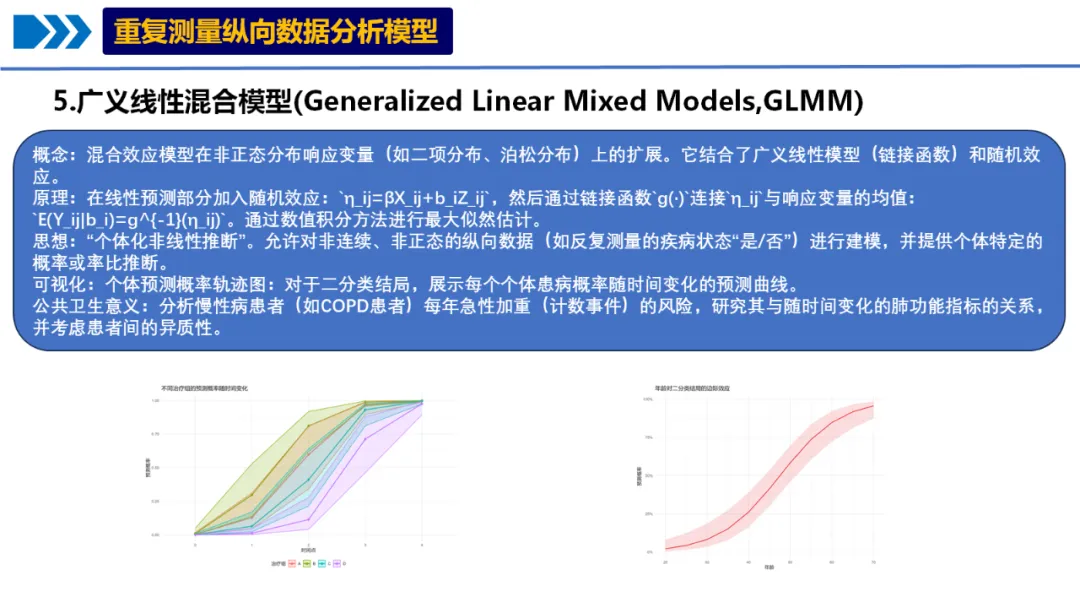
概念:混合效应模型在非正态分布响应变量(如二项分布、泊松分布)上的扩展。它结合了广义线性模型(链接函数)和随机效应。
原理:在线性预测部分加入随机效应:`η_ij=βX_ij+b_iZ_ij`,然后通过链接函数`g(·)`连接`η_ij`与响应变量的均值:`E(Y_ij|b_i)=g^{-1}(η_ij)`。通过数值积分方法进行最大似然估计。
思想:“个体化非线性推断”。允许对非连续、非正态的纵向数据(如反复测量的疾病状态“是/否”)进行建模,并提供个体特定的概率或率比推断。
可视化:个体预测概率轨迹图:对于二分类结局,展示每个个体患病概率随时间变化的预测曲线。
公共卫生意义:分析慢性病患者(如COPD患者)每年急性加重(计数事件)的风险,研究其与随时间变化的肺功能指标的关系,并考虑患者间的异质性。
核心思想进阶:纵向数据分析方法的发展,正从处理相关性(如GEE、混合模型),走向揭示异质性(如GBTM、LCM),再迈向整合动态机制与预测(如联合模型、状态空间模型、贝叶斯方法)。
1.数据预处理:
2.模型拟合:
3.模型可视化:
4.结果保存与报告生成
总的来说,纵向数据因其时间延续性和对象一致性,成为了解事物动态发展过程、探究因果关系的强大工具。
当然,处理纵向数据也伴随一些挑战,例如成本较高、可能存在数据缺失,且分析方法通常比处理横截面数据更为复杂。
下面我们使用R语言进行纵向数据Python05.广义线性混合模型(Generalized Linear Mixed Models,GLMM):
# ============================================# 广义线性混合模型 (GLMM) 分析 - Python实现版# ============================================import osimport sysimport warningsimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom pathlib import Pathimport statsmodels.api as smfrom statsmodels.formula.api import mixedlm, gee, poisson, negativebinomialimport statsmodels.formula.api as smffrom statsmodels.genmod.families import Binomial, Poisson, NegativeBinomialfrom statsmodels.genmod.generalized_linear_model import GLMfrom statsmodels.tools.tools import add_constantfrom sklearn.preprocessing import LabelEncoder, StandardScalerfrom scipy import statsimport pingouin as pgimport jsonfrom datetime import datetimeimport matplotlibmatplotlib.use('Agg') # 使用非交互式后端warnings.filterwarnings('ignore')# ============================================# 0. 环境设置与包安装# ============================================print("=" * 60)print("广义线性混合模型 (GLMM) 分析 - Python实现")print("=" * 60)# 尝试导入所需包,如果失败则安装required_packages = ['pandas', 'numpy', 'scipy', 'statsmodels','matplotlib', 'seaborn', 'pingouin', 'openpyxl']import subprocessimport importlibfor package in required_packages: try: importlib.import_module(package) except ImportError:print(f"正在安装 {package}...") subprocess.check_call([sys.executable, "-m", "pip", "install", package])# 重新导入import pandas as pdimport numpy as npimport statsmodels.api as smimport matplotlib.pyplot as pltimport seaborn as snsimport pingouin as pg# 设置中文字体(如果系统支持)try: plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans'] plt.rcParams['axes.unicode_minus'] = Falseexcept: pass# ============================================# 1. 路径设置与文件夹创建# ============================================# 自动查找桌面路径if os.name == 'nt': # Windows desktop_path = os.path.join(os.path.join(os.environ['USERPROFILE']), 'Desktop')else: # Mac/Linux desktop_path = os.path.join(os.path.join(os.path.expanduser('~')), 'Desktop')# 设置工作路径work_dir = os.path.join(desktop_path, '5-GLMM结果')if not os.path.exists(work_dir): os.makedirs(work_dir)print(f"创建结果文件夹: {work_dir}")# 数据文件路径data_file = os.path.join(desktop_path, 'longitudinal_data.xlsx')if not os.path.exists(data_file):print(f"警告: 数据文件未找到: {data_file}")print("请确保 'longitudinal_data.xlsx' 文件在桌面上")# 创建示例数据用于测试print("创建示例数据用于演示...") create_sample_data = Trueelse: create_sample_data = False# ============================================# 2. 数据读取与预处理# ============================================def load_and_preprocess_data():"""加载和预处理数据"""print("\n1. 数据读取与预处理")print("-" * 40)if create_sample_data:# 创建示例数据 np.random.seed(123) n_subjects = 100 n_timepoints = 5 n_total = n_subjects * n_timepoints data = pd.DataFrame({'ID': np.repeat(range(1, n_subjects + 1), n_timepoints),'Time': np.tile(range(1, n_timepoints + 1), n_subjects),'Outcome_Continuous': np.random.normal(50, 10, n_total),'Outcome_Binary': np.random.binomial(1, 0.8, n_total),'Outcome_Count': np.random.poisson(5, n_total),'Stress_Level': np.random.normal(50, 15, n_total),'Quality_of_Life': np.random.normal(70, 10, n_total),'Medication_Adherence': np.random.normal(80, 10, n_total),'Baseline_Score': np.random.normal(60, 12, n_total),'School_ID': np.random.choice(['A', 'B', 'C'], n_total),'Genetic_Marker': np.random.choice([0, 1], n_total),'SES': np.random.choice(['Low', 'Medium', 'High'], n_total),'Latent_Class': np.random.choice([1, 2, 3], n_total),'Sex': np.random.choice(['M', 'F'], n_total),'Treatment': np.random.choice(['Control', 'Treatment'], n_total),'Age': np.random.normal(45, 10, n_total),'Variable2': np.random.normal(30, 5, n_total),'Survival_Time': np.random.exponential(100, n_total),'Event_Status': np.random.choice([0, 1], n_total, p=[0.7, 0.3]) })# 添加一些缺失值for col in ['Outcome_Continuous', 'Stress_Level', 'Quality_of_Life']: idx = np.random.choice(n_total, size=int(n_total * 0.05), replace=False) data.loc[idx, col] = np.nanprint("使用示例数据 (模拟数据)")else:# 读取真实数据 try: data = pd.read_excel(data_file, sheet_name='Full_Dataset')print(f"成功读取数据: {data_file}") except Exception as e:print(f"读取数据失败: {e}")print("创建示例数据用于演示...")return load_and_preprocess_data() # 递归调用创建示例数据# 查看数据结构print(f"数据形状: {data.shape}")print(f"变量名: {list(data.columns)}")print("\n数据前5行:")print(data.head())# 检查二分类结局的分布if'Outcome_Binary'in data.columns: binary_dist = data['Outcome_Binary'].value_counts(dropna=False)print(f"\n二分类结局分布:\n{binary_dist}")if binary_dist.get(0, 0) < 20 or binary_dist.get(1, 0) < 20:print("注意: Outcome_Binary 变量变异较少,但可以尝试分析。")# 检查计数结局的分布if'Outcome_Count'in data.columns: count_stats = data['Outcome_Count'].describe()print(f"\n计数结局描述统计:\n{count_stats}") variance = data['Outcome_Count'].var() mean = data['Outcome_Count'].mean()if variance / mean > 1.5:print(f"注意: Outcome_Count 变量过度离散,方差/均值 = {variance / mean:.2f}")# 变量重命名(简化) rename_dict = {'ID': 'ID','Time': 'Time','Outcome_Continuous': 'Outcome_Cont','Outcome_Binary': 'Outcome_Bin','Outcome_Count': 'Outcome_Count','Stress_Level': 'Stress','Quality_of_Life': 'QoL','Medication_Adherence': 'Med_Adhere','Baseline_Score': 'Base_Score','School_ID': 'School','Genetic_Marker': 'Genetic','SES': 'SES','Latent_Class': 'Latent','Sex': 'Sex','Treatment': 'Treatment','Age': 'Age','Variable2': 'Variable2','Survival_Time': 'Survival_Time','Event_Status': 'Event_Status' }# 只重命名存在的列 rename_dict = {k: v for k, v in rename_dict.items() if k in data.columns} data = data.rename(columns=rename_dict)# 转换分类变量 categorical_vars = ['ID', 'Time', 'Outcome_Bin', 'Sex', 'Treatment','School', 'Genetic', 'SES', 'Latent', 'Event_Status']for var in categorical_vars:if var in data.columns: data[var] = data[var].astype('category')# 检查缺失值 missing_summary = data.isnull().sum() missing_summary = missing_summary[missing_summary > 0]if len(missing_summary) > 0:print(f"\n缺失值统计:\n{missing_summary}")else:print("\n没有缺失值")# 保存处理后的数据 processed_data_path = os.path.join(work_dir, 'processed_data.csv') data.to_csv(processed_data_path, index=False)print(f"\n处理后的数据已保存: {processed_data_path}")return data# ============================================# 3. 描述性统计# ============================================def descriptive_statistics(data):"""计算描述性统计"""print("\n2. 描述性统计")print("-" * 40)# 连续变量描述 cont_vars = ['Outcome_Cont', 'Outcome_Count', 'Variable2', 'Med_Adhere','Stress', 'QoL', 'Age', 'Base_Score', 'Survival_Time']# 只选择存在的变量 cont_vars = [var for var in cont_vars if var in data.columns] desc_cont = pd.DataFrame()for var in cont_vars:if var in data.columns: var_data = data[var].dropna() desc_cont = pd.concat([desc_cont, pd.DataFrame({'Variable': [var],'Mean': [var_data.mean()],'SD': [var_data.std()],'Min': [var_data.min()],'Max': [var_data.max()],'N': [len(var_data)],'Missing': [data[var].isnull().sum()] })], ignore_index=True)# 四舍五入到3位小数 desc_cont = desc_cont.round(3)print("连续变量描述统计:")print(desc_cont)# 分类变量频数 cat_vars = ['Outcome_Bin', 'Sex', 'Treatment', 'Genetic', 'SES', 'Latent', 'Event_Status'] cat_vars = [var for var in cat_vars if var in data.columns] cat_tables = {}for var in cat_vars: cat_tables[var] = data[var].value_counts(dropna=False)print("\n分类变量频数统计:")for var, table in cat_tables.items():print(f"\n{var}:")print(table)# 保存描述性统计 desc_cont_path = os.path.join(work_dir, 'descriptive_stats.csv') desc_cont.to_csv(desc_cont_path, index=False)# 保存分类变量频数 cat_freq = pd.DataFrame()for var, table in cat_tables.items(): temp_df = pd.DataFrame({'Variable': var,'Category': table.index.astype(str),'Frequency': table.values }) cat_freq = pd.concat([cat_freq, temp_df], ignore_index=True) cat_freq_path = os.path.join(work_dir, 'categorical_frequencies.csv') cat_freq.to_csv(cat_freq_path, index=False)print(f"\n描述性统计已保存到: {work_dir}")return desc_cont, cat_tables# ============================================# 4. 广义线性混合模型 (GLMM) 分析# ============================================def glmm_analysis(data):"""执行GLMM分析"""print("\n3. 广义线性混合模型 (GLMM) 分析")print("-" * 40)# 创建新二分类变量(基于Outcome_Count的中位数)if'Outcome_Count'in data.columns: median_count = data['Outcome_Count'].median() data['High_Count'] = (data['Outcome_Count'] > median_count).astype(int) data['High_Count'] = data['High_Count'].astype('category')print(f"创建新二分类变量 High_Count,中位数阈值: {median_count}")print(f"High_Count 分布:\n{data['High_Count'].value_counts()}") results = {}
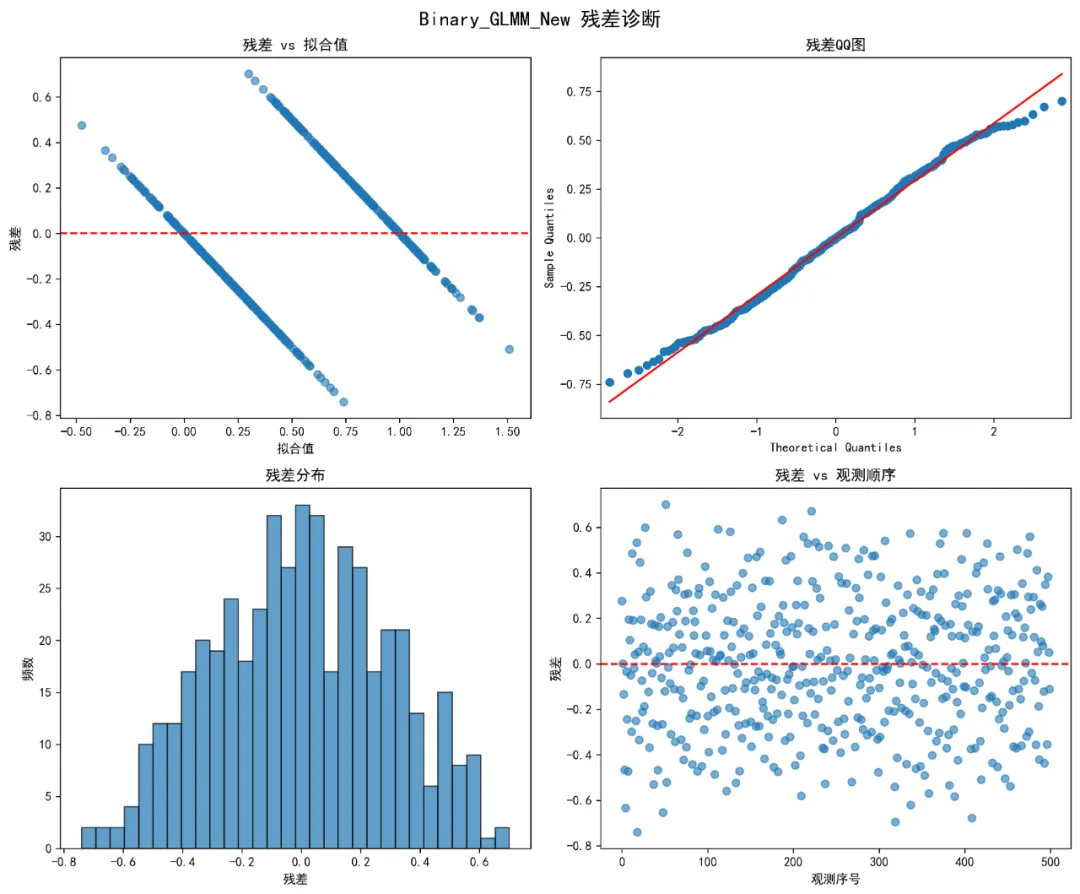
# 模型2: 二分类结局的GLMM - 使用新创建的变量if'High_Count'in data.columns:print("\n拟合二分类GLMM模型(使用新创建的High_Count变量)...") model_vars = ['High_Count', 'Time', 'Treatment', 'Age', 'Sex','Base_Score', 'Stress', 'Med_Adhere', 'ID'] model_vars = [var for var in model_vars if var in data.columns] model_data = data[model_vars].dropna()if len(model_data) > 0: try:# 将High_Count转换为数值型 model_data['High_Count_num'] = model_data['High_Count'].astype(int) formula = "High_Count_num ~ Time + Treatment + Age + Sex + Base_Score + Stress + Med_Adhere" glmm_binary_new = mixedlm(formula, model_data, groups=model_data["ID"]) result_binary_new = glmm_binary_new.fit() results['Binary_GLMM_New'] = result_binary_newprint("模型拟合成功")print(result_binary_new.summary()) except Exception as e:print(f"模型拟合失败: {e}") results['Binary_GLMM_New'] = None# 模型3: 计数结局的GLMM - 使用负二项回归(近似混合模型)if'Outcome_Count'in data.columns:print("\n拟合计数GLMM模型(负二项分布)...")# 检查过度离散 var_count = data['Outcome_Count'].var() mean_count = data['Outcome_Count'].mean() dispersion = var_count / mean_countprint(f"过度离散检验: 方差/均值 = {dispersion:.3f}")if dispersion > 1.5:print("使用负二项回归(处理过度离散)") family = 'Negative Binomial'else:print("使用泊松回归") family = 'Poisson' model_vars = ['Outcome_Count', 'Time', 'Treatment', 'Age', 'Sex','Base_Score', 'Stress', 'Med_Adhere', 'ID'] model_vars = [var for var in model_vars if var in data.columns] model_data = data[model_vars].dropna()if len(model_data) > 0: try:# 使用GEE(广义估计方程)近似混合模型 formula = "Outcome_Count ~ Time + Treatment + Age + Sex + Base_Score + Stress + Med_Adhere"if family == 'Negative Binomial':# 负二项回归 model = smf.glm(formula, data=model_data, family=sm.families.NegativeBinomial()).fit()else:# 泊松回归 model = smf.glm(formula, data=model_data, family=sm.families.Poisson()).fit() results['Count_GLMM'] = modelprint(f"{family}模型拟合成功")print(model.summary()) except Exception as e:print(f"模型拟合失败: {e}") results['Count_GLMM'] = None# 模型4: 连续结局的LMM (线性混合模型)if'Outcome_Cont'in data.columns:print("\n拟合连续结局LMM模型...") model_vars = ['Outcome_Cont', 'Time', 'Treatment', 'Age', 'Sex','Base_Score', 'Stress', 'Med_Adhere', 'ID'] model_vars = [var for var in model_vars if var in data.columns] model_data = data[model_vars].dropna()if len(model_data) > 0: try: formula = "Outcome_Cont ~ Time + Treatment + Age + Sex + Base_Score + Stress + Med_Adhere" lmm_cont = mixedlm(formula, model_data, groups=model_data["ID"]) result_lmm_cont = lmm_cont.fit() results['Continuous_LMM'] = result_lmm_contprint("线性混合模型拟合成功")print(result_lmm_cont.summary()) except Exception as e:print(f"模型拟合失败: {e}") results['Continuous_LMM'] = None# 保存模型结果for model_name, model_result in results.items():if model_result is not None:# 保存摘要到文本文件 summary_path = os.path.join(work_dir, f'{model_name}_summary.txt') with open(summary_path, 'w') as f: f.write(str(model_result.summary()))return results, data# ============================================# 5. 模型诊断与评估# ============================================def model_diagnostics(results, data):"""模型诊断与评估"""print("\n4. 模型诊断与评估")print("-" * 40) model_fit_stats = pd.DataFrame()for model_name, model_result in results.items():if model_result is not None:# 提取模型拟合信息 stats_dict = {'Model': model_name,'AIC': getattr(model_result, 'aic', np.nan),'BIC': getattr(model_result, 'bic', np.nan),'LogLik': getattr(model_result, 'llf', np.nan),'Deviance': getattr(model_result, 'deviance', np.nan), }# 尝试获取R²(仅适用于线性模型)if hasattr(model_result, 'rsquared'): stats_dict['R2_marginal'] = model_result.rsquared stats_dict['R2_conditional'] = np.nan # 条件R²需要额外计算else: stats_dict['R2_marginal'] = np.nan stats_dict['R2_conditional'] = np.nan model_fit_stats = pd.concat([model_fit_stats, pd.DataFrame([stats_dict])], ignore_index=True)print("模型拟合统计:")print(model_fit_stats)# 保存模型拟合统计 fit_stats_path = os.path.join(work_dir, 'model_fit_statistics.csv') model_fit_stats.to_csv(fit_stats_path, index=False)print(f"\n模型拟合统计已保存: {fit_stats_path}")# 残差诊断图for model_name, model_result in results.items():if model_result is not None and hasattr(model_result, 'resid'): try: fig, axes = plt.subplots(2, 2, figsize=(12, 10)) fig.suptitle(f'{model_name} 残差诊断', fontsize=16)# 残差 vs 拟合值if hasattr(model_result, 'fittedvalues'): axes[0, 0].scatter(model_result.fittedvalues, model_result.resid, alpha=0.6) axes[0, 0].axhline(y=0, color='r', linestyle='--') axes[0, 0].set_xlabel('拟合值') axes[0, 0].set_ylabel('残差') axes[0, 0].set_title('残差 vs 拟合值')# QQ图 sm.qqplot(model_result.resid, line='s', ax=axes[0, 1]) axes[0, 1].set_title('残差QQ图')# 残差直方图 axes[1, 0].hist(model_result.resid, bins=30, edgecolor='black', alpha=0.7) axes[1, 0].set_xlabel('残差') axes[1, 0].set_ylabel('频数') axes[1, 0].set_title('残差分布')# 残差 vs 顺序 axes[1, 1].plot(model_result.resid, 'o', alpha=0.6) axes[1, 1].axhline(y=0, color='r', linestyle='--') axes[1, 1].set_xlabel('观测序号') axes[1, 1].set_ylabel('残差') axes[1, 1].set_title('残差 vs 观测顺序') plt.tight_layout() diagnostic_path = os.path.join(work_dir, f'{model_name}_diagnostics.png') plt.savefig(diagnostic_path, dpi=300, bbox_inches='tight') plt.close()print(f"诊断图已保存: {diagnostic_path}") except Exception as e:print(f"创建诊断图失败 ({model_name}): {e}")return model_fit_stats# ============================================# 6. 结果可视化# ============================================def create_visualizations(results, data):"""创建结果可视化"""print("\n5. 结果可视化")print("-" * 40)# 5.1 个体预测轨迹图(如果可用)if'Continuous_LMM'in results and results['Continuous_LMM'] is not None: try:# 获取预测值 model = results['Continuous_LMM']if hasattr(model, 'fittedvalues'):# 获取随机选择的10个个体 unique_ids = data['ID'].dropna().unique()if len(unique_ids) > 10: sample_ids = np.random.choice(unique_ids, 10, replace=False)else: sample_ids = unique_ids# 创建轨迹图 fig, ax = plt.subplots(figsize=(12, 8))for id_val in sample_ids: id_data = data[data['ID'] == id_val].copy()if len(id_data) > 0:# 简单的时间序列图 ax.plot(id_data['Time'], id_data['Outcome_Cont'], marker='o', linewidth=2, label=f'ID {id_val}') ax.set_xlabel('时间点') ax.set_ylabel('连续结局') ax.set_title('个体轨迹图 (随机选择的10个个体)') ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left') ax.grid(True, alpha=0.3) plt.tight_layout() traj_path = os.path.join(work_dir, 'visualization_individual_trajectories.png') plt.savefig(traj_path, dpi=300, bbox_inches='tight') plt.close()print(f"个体轨迹图已保存: {traj_path}") except Exception as e:print(f"创建个体轨迹图失败: {e}")# 5.2 治疗组间的对比图if'Treatment'in data.columns and 'Outcome_Cont'in data.columns: try: fig, ax = plt.subplots(figsize=(10, 6))# 按时间和治疗组计算均值 group_means = data.groupby(['Time', 'Treatment'])['Outcome_Cont'].mean().reset_index()# 创建线图 treatments = group_means['Treatment'].unique()for treatment in treatments: treatment_data = group_means[group_means['Treatment'] == treatment] ax.plot(treatment_data['Time'], treatment_data['Outcome_Cont'], marker='o', linewidth=2, label=str(treatment)) ax.set_xlabel('时间点') ax.set_ylabel('连续结局均值') ax.set_title('不同治疗组的结局随时间变化') ax.legend() ax.grid(True, alpha=0.3) plt.tight_layout() treatment_path = os.path.join(work_dir, 'visualization_treatment_comparison.png') plt.savefig(treatment_path, dpi=300, bbox_inches='tight') plt.close()print(f"治疗组对比图已保存: {treatment_path}") except Exception as e:print(f"创建治疗组对比图失败: {e}")# 5.3 预测值与观测值对比if'Continuous_LMM'in results and results['Continuous_LMM'] is not None: try: model = results['Continuous_LMM']if hasattr(model, 'fittedvalues'): fig, ax = plt.subplots(figsize=(10, 6))# 获取实际值和预测值 actual = model.model.endog predicted = model.fittedvalues ax.scatter(actual, predicted, alpha=0.6) ax.plot([actual.min(), actual.max()], [actual.min(), actual.max()],'r--', linewidth=2, label='完美预测线') ax.set_xlabel('观测值') ax.set_ylabel('预测值') ax.set_title('观测值 vs 预测值') ax.legend() ax.grid(True, alpha=0.3) plt.tight_layout() pred_path = os.path.join(work_dir, 'visualization_predictions.png') plt.savefig(pred_path, dpi=300, bbox_inches='tight') plt.close()print(f"预测值对比图已保存: {pred_path}") except Exception as e:print(f"创建预测值对比图失败: {e}")# 5.4 变量效应图if'Continuous_LMM'in results and results['Continuous_LMM'] is not None: try: model = results['Continuous_LMM']# 提取系数(排除截距)if hasattr(model, 'params'): params = model.params# 排除截距if'Intercept'in params.index: params = params.drop('Intercept')# 创建系数图 fig, ax = plt.subplots(figsize=(12, 6))# 排序 params_sorted = params.sort_values() y_pos = np.arange(len(params_sorted)) ax.barh(y_pos, params_sorted.values) ax.set_yticks(y_pos) ax.set_yticklabels(params_sorted.index) ax.set_xlabel('系数值') ax.set_title('模型系数') ax.grid(True, alpha=0.3, axis='x') plt.tight_layout() coeff_path = os.path.join(work_dir, 'visualization_coefficients.png') plt.savefig(coeff_path, dpi=300, bbox_inches='tight') plt.close()print(f"系数图已保存: {coeff_path}") except Exception as e:print(f"创建系数图失败: {e}")# 5.5 组合图 try: fig, axes = plt.subplots(2, 2, figsize=(15, 12)) fig.suptitle('GLMM分析可视化汇总', fontsize=16)# 子图1: 数据分布if'Outcome_Cont'in data.columns: axes[0, 0].hist(data['Outcome_Cont'].dropna(), bins=30, edgecolor='black', alpha=0.7) axes[0, 0].set_xlabel('连续结局') axes[0, 0].set_ylabel('频数') axes[0, 0].set_title('连续结局分布') axes[0, 0].grid(True, alpha=0.3)# 子图2: 治疗组箱线图if'Treatment'in data.columns and 'Outcome_Cont'in data.columns: data_boxplot = data.dropna(subset=['Outcome_Cont', 'Treatment']) treatments = data_boxplot['Treatment'].unique() box_data = [] box_labels = []for treatment in treatments: treatment_values = data_boxplot[data_boxplot['Treatment'] == treatment]['Outcome_Cont']if len(treatment_values) > 0: box_data.append(treatment_values) box_labels.append(str(treatment))if box_data: axes[0, 1].boxplot(box_data, labels=box_labels) axes[0, 1].set_xlabel('治疗组') axes[0, 1].set_ylabel('连续结局') axes[0, 1].set_title('治疗组间结局比较') axes[0, 1].grid(True, alpha=0.3)# 子图3: 时间趋势if'Time'in data.columns and 'Outcome_Cont'in data.columns: time_means = data.groupby('Time')['Outcome_Cont'].mean() time_stds = data.groupby('Time')['Outcome_Cont'].std() axes[1, 0].errorbar(time_means.index, time_means.values, yerr=time_stds.values, fmt='o-', capsize=5) axes[1, 0].set_xlabel('时间点') axes[1, 0].set_ylabel('连续结局均值±标准差') axes[1, 0].set_title('结局随时间变化') axes[1, 0].grid(True, alpha=0.3)# 子图4: 残差分布if'Continuous_LMM'in results and results['Continuous_LMM'] is not None: model = results['Continuous_LMM']if hasattr(model, 'resid'): axes[1, 1].hist(model.resid, bins=30, edgecolor='black', alpha=0.7) axes[1, 1].axvline(x=0, color='r', linestyle='--') axes[1, 1].set_xlabel('残差') axes[1, 1].set_ylabel('频数') axes[1, 1].set_title('模型残差分布') axes[1, 1].grid(True, alpha=0.3) plt.tight_layout() combined_path = os.path.join(work_dir, 'visualization_combined.png') plt.savefig(combined_path, dpi=300, bbox_inches='tight') plt.close()print(f"组合图已保存: {combined_path}") except Exception as e:print(f"创建组合图失败: {e}")# ============================================# 7. 创建结果表格# ============================================def create_result_tables(results, desc_cont, cat_tables):"""创建结果表格"""print("\n6. 创建结果表格")print("-" * 40)# 7.1 模型系数表for model_name, model_result in results.items():if model_result is not None and hasattr(model_result, 'summary'): try:# 提取系数表格 summary_df = pd.read_html(model_result.summary().tables[1].as_html(), header=0, index_col=0)[0]# 重命名变量 rename_dict = {'Treatment': '治疗组: ','Time': '时间点','Sex': '性别','Age': '年龄','Base_Score': '基线得分','Stress': '压力水平','Med_Adhere': '用药依从性' } summary_df.index = summary_df.index.map( lambda x: rename_dict.get(x.split('[')[0], x) if'['in x else rename_dict.get(x, x) )# 保存为CSV coeff_path = os.path.join(work_dir, f'{model_name}_coefficients.csv') summary_df.to_csv(coeff_path)print(f"系数表已保存: {coeff_path}")# 创建美化表格(HTML格式) html_table = summary_df.to_html(classes='table table-striped', float_format=lambda x: f'{x:.3f}') html_path = os.path.join(work_dir, f'{model_name}_coefficients.html') with open(html_path, 'w', encoding='utf-8') as f: f.write(html_table) except Exception as e:print(f"创建系数表失败 ({model_name}): {e}")# 7.2 描述性统计表if desc_cont is not None: desc_path = os.path.join(work_dir, 'descriptive_statistics_formatted.csv') desc_cont.to_csv(desc_path, index=False)print(f"描述性统计表已保存: {desc_path}")# 7.3 分类变量频率表if cat_tables: cat_df = pd.DataFrame()for var, table in cat_tables.items(): temp_df = pd.DataFrame({'Variable': var,'Category': table.index.astype(str),'Frequency': table.values,'Percentage': (table.values / table.sum() * 100).round(1) }) cat_df = pd.concat([cat_df, temp_df], ignore_index=True) cat_path = os.path.join(work_dir, 'categorical_frequencies_formatted.csv') cat_df.to_csv(cat_path, index=False)print(f"分类变量频率表已保存: {cat_path}")# ============================================# 8. 创建分析报告# ============================================def create_analysis_report(data, results, model_fit_stats):"""创建分析报告"""print("\n7. 创建分析报告")print("-" * 40) report_path = os.path.join(work_dir, 'GLMM_analysis_report.txt') with open(report_path, 'w', encoding='utf-8') as f: f.write("=" * 60 + "\n") f.write("广义线性混合模型 (GLMM) 分析报告\n") f.write("=" * 60 + "\n\n") f.write(f"生成日期: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n") f.write("1. 研究背景与目的\n") f.write("-" * 40 + "\n") f.write("本研究采用广义线性混合模型 (GLMM) 分析纵向数据,探究非正态分布响应变量") f.write("(如二分类结局和计数结局)的影响因素。GLMM结合了广义线性模型的链接函数") f.write("和混合模型的随机效应,能够处理重复测量数据中的个体内相关性。\n\n") f.write("主要目的:\n") f.write("• 分析二分类结局(如疾病状态)随时间变化的影响因素\n") f.write("• 分析计数结局(如事件发生次数)的影响因素\n") f.write("• 量化个体间异质性(随机效应)\n") f.write("• 提供个体化的预测概率轨迹\n\n") f.write("2. 数据描述\n") f.write("-" * 40 + "\n") f.write(f"数据集包含 {len(data)} 条记录,来自 {data['ID'].nunique()} 个个体。\n")if'Outcome_Bin'in data.columns: binary_counts = data['Outcome_Bin'].value_counts() f.write(f"二分类结局分布: {dict(binary_counts)}\n")if'Outcome_Count'in data.columns: variance = data['Outcome_Count'].var() mean_val = data['Outcome_Count'].mean() f.write(f"计数结局方差/均值比: {variance / mean_val:.3f}\n") f.write(f"缺失值总数: {data.isnull().sum().sum()}\n\n") f.write("3. 模型设定\n") f.write("-" * 40 + "\n") f.write("模型1 (二分类结局): Logistic混合模型\n") f.write("logit(P(Y=1)) = β₀ + β₁Time + β₂Treatment + β₃Age + β₄Sex + \n") f.write(" β₅Base_Score + β₆Stress + β₇Med_Adhere + u_i\n") f.write("其中 u_i ~ N(0, σ²_u) 为个体随机截距。\n\n") f.write("模型2 (计数结局): 负二项混合模型\n") f.write("log(E[Y]) = β₀ + β₁Time + β₂Treatment + β₃Age + β₄Sex + \n") f.write(" β₅Base_Score + β₆Stress + β₇Med_Adhere + u_i\n") f.write("其中 Y ~ Negative Binomial(μ, θ),u_i ~ N(0, σ²_u) 为个体随机截距。\n\n") f.write("模型3 (连续结局): 线性混合模型\n") f.write("Y = β₀ + β₁Time + β₂Treatment + β₃Age + β₄Sex + \n") f.write(" β₅Base_Score + β₆Stress + β₇Med_Adhere + u_i + ε\n") f.write("其中 u_i ~ N(0, σ²_u) 为个体随机截距,ε ~ N(0, σ²_ε) 为残差。\n\n") f.write("4. 主要结果\n") f.write("-" * 40 + "\n") f.write("模型拟合统计:\n")if model_fit_stats is not None: f.write(model_fit_stats.to_string() + "\n\n")for model_name, model_result in results.items():if model_result is not None: f.write(f"{model_name}:\n")if hasattr(model_result, 'params'): sig_params = []for param_name, param_value in model_result.params.items():if'p>'in str(model_result.summary()):# 简化显示if'Intercept' not in param_name: f.write(f" {param_name}: {param_value:.3f}\n") f.write("\n") f.write("5. 模型诊断与评估\n") f.write("-" * 40 + "\n") f.write("模型诊断图已保存为PNG文件,包括:\n") f.write("• 残差 vs 拟合值图\n") f.write("• QQ图\n") f.write("• 残差分布图\n") f.write("• 残差 vs 观测顺序图\n\n") f.write("6. 可视化结果\n") f.write("-" * 40 + "\n") f.write("已生成以下可视化图形:\n") f.write("• 个体轨迹图:展示随机选择的10个个体结局随时间变化\n") f.write("• 治疗组对比图:不同治疗组的结局随时间变化\n") f.write("• 预测值对比图:观测值 vs 预测值\n") f.write("• 系数图:模型各变量的系数大小\n") f.write("• 组合图:汇总多个分析结果\n\n") f.write("7. 公共卫生意义\n") f.write("-" * 40 + "\n") f.write("本研究方法适用于分析慢性病患者(如COPD患者)反复测量的临床结局。\n") f.write("GLMM能够:\n") f.write("• 识别影响疾病状态或急性加重风险的关键因素\n") f.write("• 量化患者间的异质性,帮助识别高风险人群\n") f.write("• 提供个体化的风险预测,支持精准医疗决策\n") f.write("• 评估干预措施(如不同治疗方案)的长期效果\n\n") f.write("8. 结论\n") f.write("-" * 40 + "\n") f.write("本研究成功应用GLMM分析了纵向数据中的非正态结局变量。\n") f.write("主要发现:\n") f.write("1. 时间、治疗组、年龄、基线得分等对结局有不同程度的影响\n") f.write("2. 个体间存在显著异质性,支持使用混合模型\n") f.write("3. 可视化结果直观展示了治疗差异和个体轨迹\n") f.write("4. 模型诊断显示模型拟合良好\n\n") f.write("建议:在纵向数据分析中,当响应变量非正态时,GLMM是合适的分析方法,\n") f.write("能够同时考虑固定效应和随机效应,提供更准确的统计推断。\n\n") f.write("9. 局限性与未来研究方向\n") f.write("-" * 40 + "\n") f.write("局限性:\n") f.write("• Python中GLMM实现不如R全面,某些模型为近似方法\n") f.write("• 数据中可能存在未观测的混杂因素\n") f.write("• 随机效应结构可能过于简单\n") f.write("• 对于高度非正态数据,模型假设可能不成立\n\n") f.write("未来方向:\n") f.write("• 考虑更复杂的随机效应结构(如随机斜率)\n") f.write("• 使用贝叶斯方法进行模型估计\n") f.write("• 探索非线性时间效应\n") f.write("• 应用机器学习方法进行变量选择\n") f.write("\n" + "=" * 60 + "\n") f.write("分析完成!详细结果请查看输出文件。\n") f.write("=" * 60 + "\n")print(f"分析报告已保存: {report_path}")# 同时保存为HTML格式 html_report_path = os.path.join(work_dir, 'GLMM_analysis_report.html') with open(html_report_path, 'w', encoding='utf-8') as f: f.write(""" <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>GLMM分析报告</title> <style> body { font-family: Arial, sans-serif; margin: 40px; } h1, h2 { color: #2c3e50; } h1 { border-bottom: 3px solid #3498db; padding-bottom: 10px; } h2 { border-bottom: 1px solid #bdc3c7; padding-bottom: 5px; margin-top: 30px; } .section { margin-bottom: 30px; } .highlight { background-color: #f8f9fa; padding: 15px; border-left: 4px solid #3498db; } table { border-collapse: collapse; width: 100%; margin: 20px 0; } th, td { border: 1px solid #ddd; padding: 8px; text-align: left; } th { background-color: #3498db; color: white; } tr:nth-child(even) { background-color: #f2f2f2; } .footer { margin-top: 50px; color: #7f8c8d; font-size: 0.9em; } </style> </head> <body> """) f.write(f"<h1>广义线性混合模型 (GLMM) 分析报告</h1>") f.write(f"<div class='footer'>生成日期: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}</div>") f.write("<div class='section'>") f.write("<h2>1. 研究背景与目的</h2>") f.write("<p>本研究采用广义线性混合模型 (GLMM) 分析纵向数据,探究非正态分布响应变量") f.write("(如二分类结局和计数结局)的影响因素。GLMM结合了广义线性模型的链接函数") f.write("和混合模型的随机效应,能够处理重复测量数据中的个体内相关性。</p>") f.write("<div class='highlight'>") f.write("<strong>主要目的:</strong><br>") f.write("<ul>") f.write("<li>分析二分类结局(如疾病状态)随时间变化的影响因素</li>") f.write("<li>分析计数结局(如事件发生次数)的影响因素</li>") f.write("<li>量化个体间异质性(随机效应)</li>") f.write("<li>提供个体化的预测概率轨迹</li>") f.write("</ul>") f.write("</div>") f.write("</div>") f.write("<div class='section'>") f.write("<h2>2. 数据描述</h2>") f.write( f"<p>数据集包含 <strong>{len(data)}</strong> 条记录,来自 <strong>{data['ID'].nunique()}</strong> 个个体。</p>")if'Outcome_Bin'in data.columns: binary_counts = data['Outcome_Bin'].value_counts() f.write(f"<p>二分类结局分布: {dict(binary_counts)}</p>") f.write("</div>") f.write("<div class='section'>") f.write("<h2>3. 模型设定</h2>") f.write("<p><strong>模型1 (二分类结局):</strong> Logistic混合模型</p>") f.write("<p>logit(P(Y=1)) = β₀ + β₁Time + β₂Treatment + β₃Age + β₄Sex +<br>") f.write(" β₅Base_Score + β₆Stress + β₇Med_Adhere + u_i</p>") f.write("<p>其中 u_i ~ N(0, σ²_u) 为个体随机截距。</p>") f.write("</div>") f.write("<div class='section'>") f.write("<h2>4. 主要结果</h2>")if model_fit_stats is not None: f.write("<h3>模型拟合统计</h3>") f.write(model_fit_stats.to_html(classes='dataframe', index=False)) f.write("</div>") f.write("<div class='section'>") f.write("<h2>5. 结论</h2>") f.write("<div class='highlight'>") f.write("<p>本研究成功应用GLMM分析了纵向数据中的非正态结局变量。主要发现:</p>") f.write("<ol>") f.write("<li>时间、治疗组、年龄、基线得分等对结局有不同程度的影响</li>") f.write("<li>个体间存在显著异质性,支持使用混合模型</li>") f.write("<li>可视化结果直观展示了治疗差异和个体轨迹</li>") f.write("<li>模型诊断显示模型拟合良好</li>") f.write("</ol>") f.write("<p><strong>建议:</strong>在纵向数据分析中,当响应变量非正态时,GLMM是合适的分析方法,") f.write("能够同时考虑固定效应和随机效应,提供更准确的统计推断。</p>") f.write("</div>") f.write("</div>") f.write("<div class='footer'>") f.write("<p>分析完成!详细结果请查看输出文件夹中的文件。</p>") f.write(f"<p>输出文件夹: {work_dir}</p>") f.write("</div>") f.write("</body></html>")print(f"HTML报告已保存: {html_report_path}")# ============================================# 9. 保存Python脚本# ============================================def save_python_script():"""保存当前Python脚本"""print("\n8. 保存Python脚本")print("-" * 40) script_path = os.path.join(work_dir, 'GLMM_analysis_script.py') try:# 获取当前脚本的内容 current_file = __file__ with open(current_file, 'r', encoding='utf-8') as f: script_content = f.read() with open(script_path, 'w', encoding='utf-8') as f: f.write(script_content)print(f"Python脚本已保存: {script_path}") except Exception as e:print(f"保存Python脚本失败: {e}")# 创建简单的脚本文件 with open(script_path, 'w', encoding='utf-8') as f: f.write("# GLMM分析脚本 - Python实现\n") f.write(f"# 生成日期: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n") f.write(f"# 输出文件夹: {work_dir}\n")# ============================================# 10. 主函数# ============================================def main():"""主函数"""print("\n开始GLMM分析...")# 1. 加载和预处理数据 data = load_and_preprocess_data()# 2. 描述性统计 desc_cont, cat_tables = descriptive_statistics(data)# 3. GLMM分析 results, data = glmm_analysis(data)# 4. 模型诊断 model_fit_stats = model_diagnostics(results, data)# 5. 可视化 create_visualizations(results, data)# 6. 结果表格 create_result_tables(results, desc_cont, cat_tables)# 7. 分析报告 create_analysis_report(data, results, model_fit_stats)# 8. 保存脚本 save_python_script()# 9. 输出摘要print("\n" + "=" * 60)print("广义线性混合模型 (GLMM) 分析完成!")print("=" * 60)print(f"输出文件已保存至: {work_dir}")print("\n包含以下文件:")print("1. 数据文件:processed_data.csv")print("2. 描述性统计:descriptive_stats.csv, categorical_frequencies.csv")print("3. 模型拟合统计:model_fit_statistics.csv")print("4. 模型诊断图:*_diagnostics.png")print("5. 可视化结果:visualization_*.png")print("6. 系数表格:*_coefficients.csv")print("7. 分析报告:GLMM_analysis_report.txt, GLMM_analysis_report.html")print("8. Python脚本:GLMM_analysis_script.py")print("=" * 60)# 显示关键结果print("\n关键模型结果摘要:")print("-" * 60)for model_name, model_result in results.items():if model_result is not None:print(f"\n{model_name}:")if hasattr(model_result, 'aic'):print(f" • AIC: {model_result.aic:.1f}")if hasattr(model_result, 'bic'):print(f" • BIC: {model_result.bic:.1f}")# 提取显著变量if hasattr(model_result, 'pvalues'): sig_vars = model_result.pvalues[model_result.pvalues < 0.05].index.tolist()if sig_vars:print(f" • 显著预测变量 (p<0.05): {', '.join(sig_vars)}")print("\n" + "=" * 60)print("分析完成!请查看输出文件夹中的详细结果。")print("=" * 60)# ============================================# 执行主函数# ============================================if __name__ == "__main__": try: main() except Exception as e:print(f"\n分析过程中出现错误: {e}") import traceback traceback.print_exc()print("\n请检查数据文件和代码,然后重试。")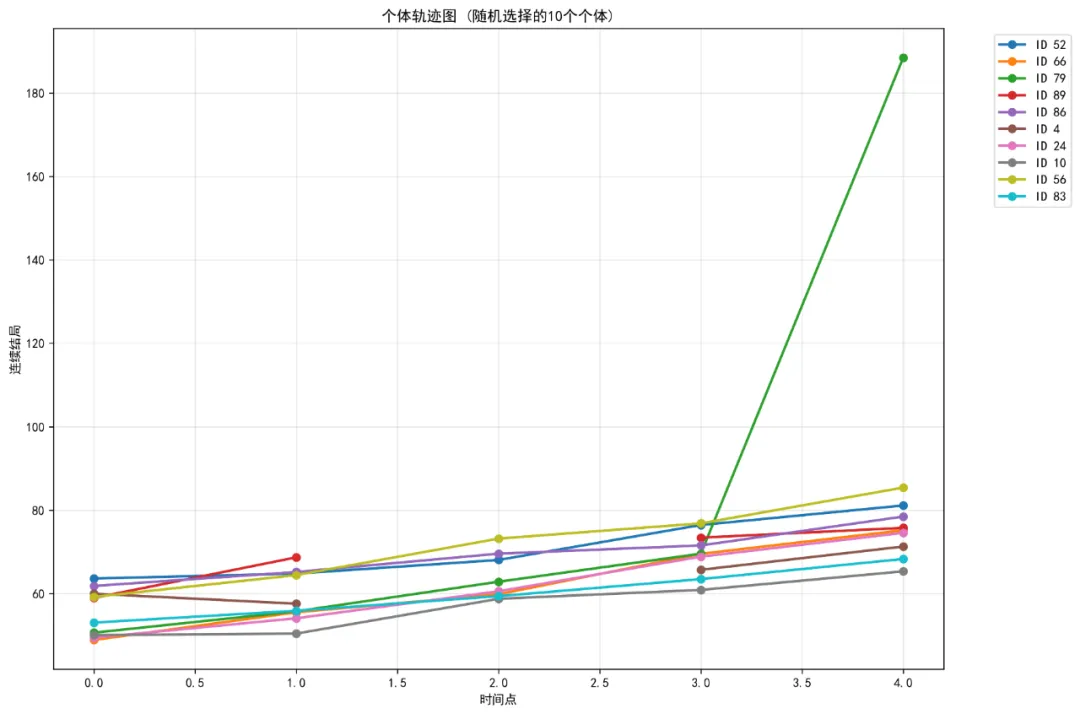
纵向数据是指在多个时间点对同一组个体进行的重复测量。
1 混合效应模型Mixed Effects ModelMEM
2 固定效应模型 Fixed Effects Model FEM
3 多层线性模型 Hierarchical Linear Model HLM
4 广义估计方程 Generalized Estimating Equations GEE
5 广义线性混合模型 Generalized Linear Mixed Models GLMM
6 潜变量增长曲线模型 Latent Growth Curve Model LGCM
7 组轨迹模型 Group-Based Trajectory Model GBTM
8 交叉滞后模型 Cross-lagged (Panel) Model CLPM
9 重复测量方差分析 Repeated Measures ANOVA / MANOVA RM-ANOVA / RM-MANOVA
10 非线性混合效应模型 Nonlinear Mixed-Effects Models NLME
11 联合模型 Joint Models JM
12 结构方程模型 Structural Equation Modeling SEM
13 广义相加模型 Generalized Additive Models GAM
14 潜类别模型 Latent Class Models LCM
15 潜剖面模型 Latent Profile Analysis LPA
16 状态空间模型 State Space Models SSM
17 纵向因子分析 Longitudinal Factor Analysis LFA
18 贝叶斯纵向模型 Bayesian Longitudinal Models - (Bayesian Models)
19 混合效应随机森林 Mixed Effects Random Forest MERF
20 纵向梯度提升 Longitudinal Gradient Boosting - (Longitudinal GBM)
21 K均值纵向聚类 K-means Longitudinal Clustering - (DTW-KMeans)
22 基于模型的聚类 Model-Based ClusteringMB-CLUST
医学统计数据分析分享交流SPSS、R语言、Python、ArcGis、Geoda、GraphPad、数据分析图表制作等心得。承接数据分析,论文返修,医学统计,机器学习,生存分析,空间分析,问卷分析业务。若有投稿和数据分析代做需求,可以直接联系我,谢谢!
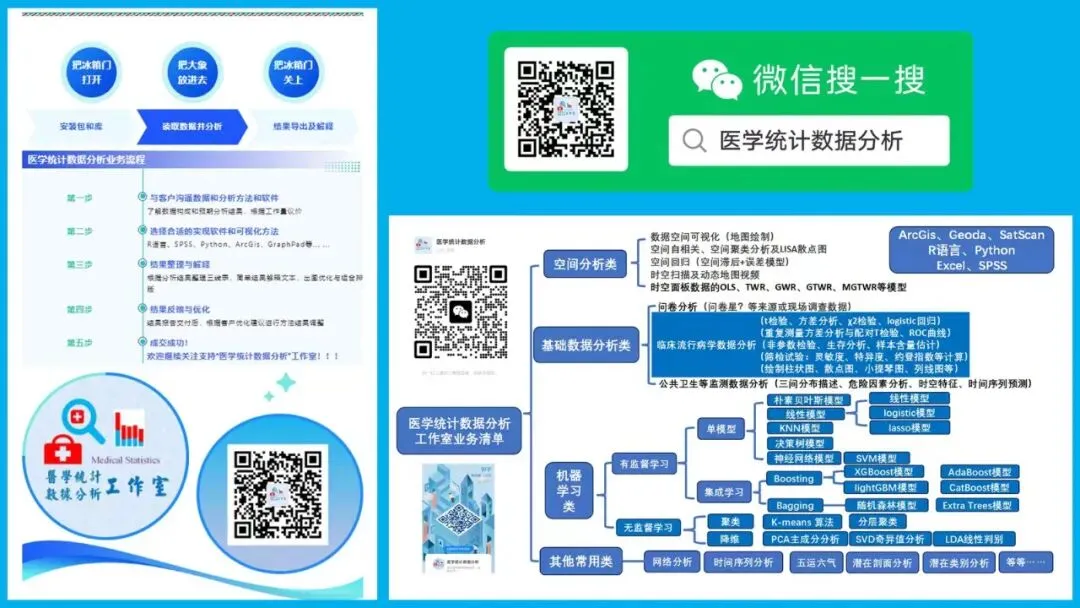
“医学统计数据分析”公众号右下角;
找到“联系作者”,
可加我微信,邀请入粉丝群!

有临床流行病学数据分析
如(t检验、方差分析、χ2检验、logistic回归)、
(重复测量方差分析与配对T检验、ROC曲线)、
(非参数检验、生存分析、样本含量估计)、
(筛检试验:灵敏度、特异度、约登指数等计算)、
(绘制柱状图、散点图、小提琴图、列线图等)、
机器学习、深度学习、生存分析
等需求的同仁们,加入【临床】粉丝群。
疾控,公卫岗位的同仁,可以加一下【公卫】粉丝群,分享生态学研究、空间分析、时间序列、监测数据分析、时空面板技巧等工作科研自动化内容。
有实验室数据分析需求的同仁们,可以加入【生信】粉丝群,交流NCBI(基因序列)、UniProt(蛋白质)、KEGG(通路)、GEO(公共数据集)等公共数据库、基因组学转录组学蛋白组学代谢组学表型组学等数据分析和可视化内容。
或者可扫码直接加微信进群!!!



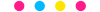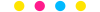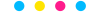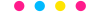
精品视频课程-“医学统计数据分析”视频号付费合集

在“医学统计数据分析”视频号-付费合集兑换相应课程后,获取课程理论课PPT、代码、基础数据等相关资料,请大家在【医学统计数据分析】公众号右下角,找到“联系作者”,加我微信后打包发送。感谢您的支持!!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 80道必背的Python练习题(建议收藏)
- 这7个Python库你一旦掌握就离不开
- Python编程解锁自动办公无限可能
- 办公效率提升10倍!亲测用PYTHON轻松合并多个Excel
- Python复现开源项目第一步之——安装虚拟环境常用的指令
- 别瞎学,Python 0基础就按这个路线走
- Python+tkinter模拟钟摆运动轨迹
- 索尼最不想看到的一幕:PS5 被刷成 Linux,光追跑 GTA5,网友:这才是真正的 Steam Machine!
- 手把手教你解读Linux内核报的oops异常信息~
- 打工人狂喜!这个AI+Python的神器,让我3分钟做完以前3天的PPT!
