一、学前花絮
随着我们对于python学习的深入,我们已经能够编写很多的程序了,无论是循环结构还是判断语句,再有面向对象以及数据处理pandas等。但当我们实际应用的时候,会发现能输出结果只是其中的一个小目标,好的程序一定要在时间、空间上进行优化。时间可以认为是执行效率高、运行速度快,而空间可以认为是节省内存、存储。
这也就是本文所提到的算法,我们下面予以详细说明。
二、用Python编程示例算法的时间、空间复杂度。
2.1 算法是什么?
算法是解决特定问题的一系列清晰指令。就像烹饪菜谱一样,它告诉计算机“如何做”才能得到想要的结果。但不同的“菜谱”(算法)效率天差地别。
核心特征:
l有明确输入和输出
l步骤有限且确定
l能在有限时间内完成
l每个操作都可行
# 简单算法示例:计算1到n的和 
|
2.2 为什么需要复杂度分析?
比如你要在电话簿中找一个人:
方法1:从第一页开始一页页翻(顺序查找)
方法2:从中间翻开,根据名字决定往前或往后翻(二分查找)
当电话簿有1000页时,方法1最多翻1000次,方法2最多翻10次!这就是算法效率的差距。
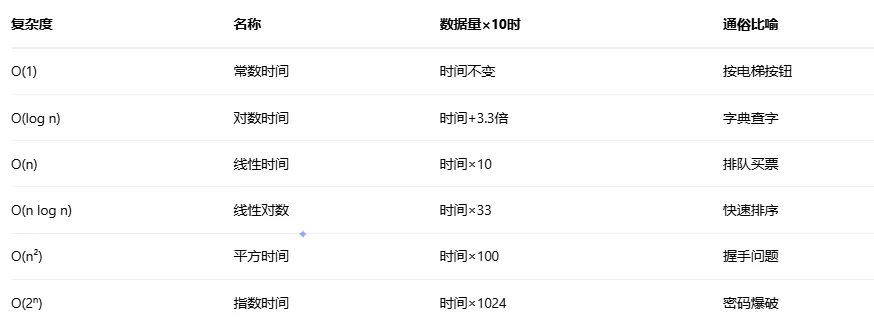
2.3 时间复杂度:算法的“速度表”
时间复杂度衡量算法执行时间随数据规模增长的变化趋势。用大O表示法描述。
常见时间复杂度对比:
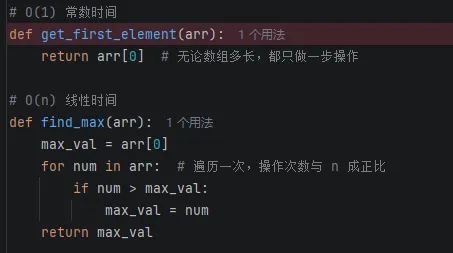
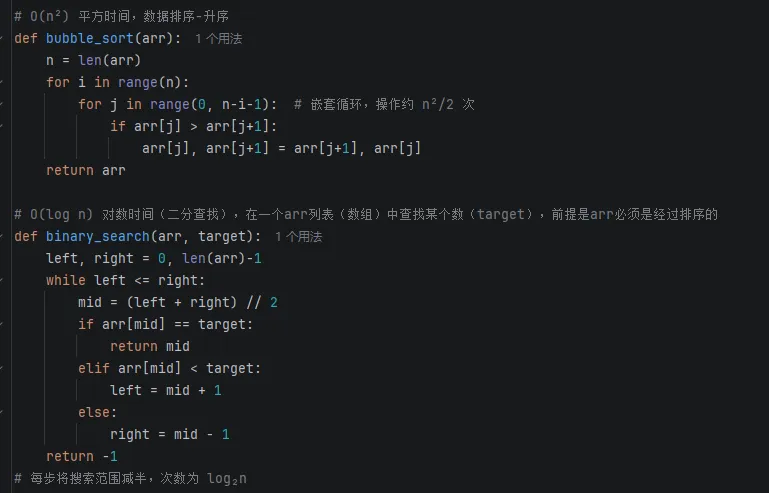
Python代码示例:
对以上时间复杂度函数的调用:
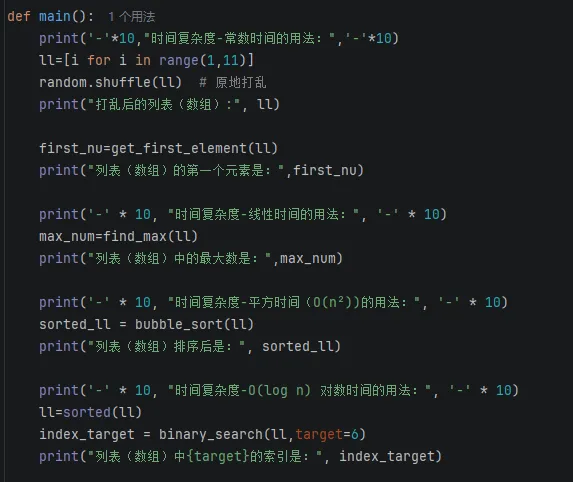
输出结果如下:
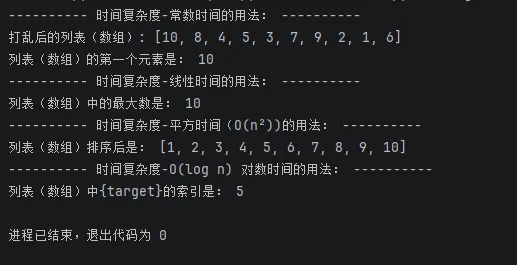
2.4 空间复杂度:算法的“内存账单”
空间复杂度衡量算法占用内存随数据规模的变化。
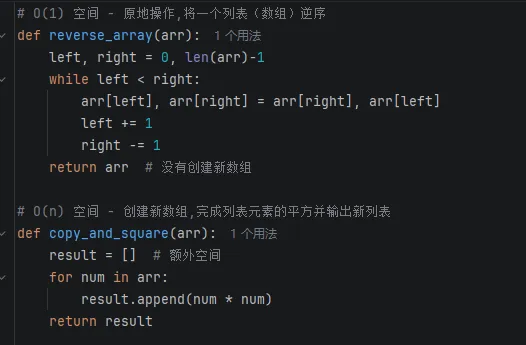
调用以上函数:
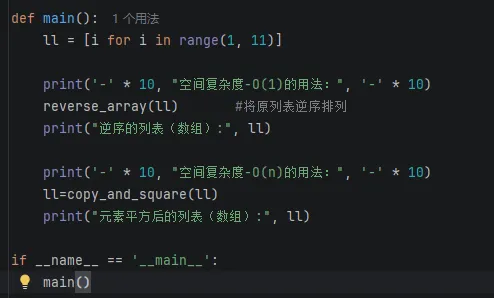
输出结果:
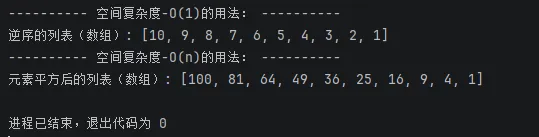
2.5 如何选择算法?实战指南
基本原则:
l数据量小 → 简单最重要
l数据量大 → 效率最关键
l内存紧张 → 优先省空间
l实时系统 → 必须保证速度
决策矩阵:
以上矩阵的意义很明确,如果数据量小,用O(n²)也是可以的。但当数据量很大的时候,要做优化, O(n) 更好。
2.6 复杂度分析并优化实战
以上代码的复杂度,因为i每次翻倍,循环次数约log₂n次。其实对数的含义,可以这么理解:
上面的例子:count 约等于以2为底n的对数,也就是log₂n。这个函数实际上计算的是:"用2的幂次逼近n,需要几次幂才能超过n"。
2.7为什么算法中常用对数?
在算法中,对数复杂度 O(log n) 通常以2为底,因为计算机是二进制的。
经典场景:二分查找
# 每次比较后,搜索范围减半 # 数组长度n = 8时 # 第1次:范围8 → 4 # 第2次:范围4 → 2 # 第3次:范围2 → 1 # 查找次数 = log₂8 = 3 |
对数增长非常缓慢:
n=8 → log₂8 = 3
n=1024 → log₂1024 = 10
n=1,000,000 → log₂1,000,000 ≈ 20
n=1,000,000,000 → log₂1,000,000,000 ≈ 30
就是说对于上面10亿这个数量级别来说,它以2为底的对数约为30。这也就说明了为什么算法中一旦优化到对数级别,性能提升就是指数级别了。
指数vs对数的关系:
它们是逆运算,就像加法和减法、乘法和除法:
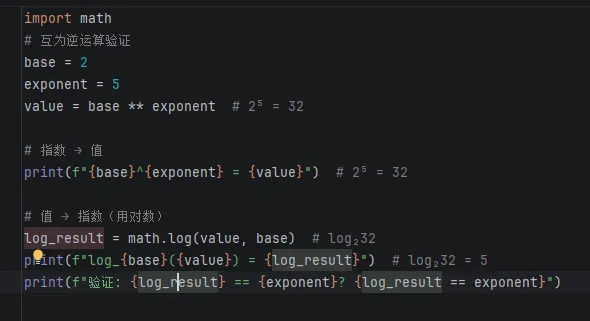 输出结果:
输出结果:
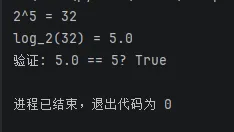
也就是说对于2,它的5次幂是32,而以它为底32的对数是5。这也从另一个角度说很多情况下如果程序之前的算法复杂度是 O(n²) ,我们要想办法把它优化到O(n)或者O(log n)。而后者要更优于前者:
以上是增长趋势对比,很明显O(log n)要比O(n)增长慢很多。
直观代码对比
O(log n) - 二分查找
输出结果:
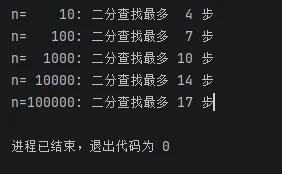
从以上结果看出,用二分查找对于10万这个数量级来说,只用到17步就得到结果。
在大数据处理系统中,经常是亿以上的数量级,比如针对1亿用户查询:
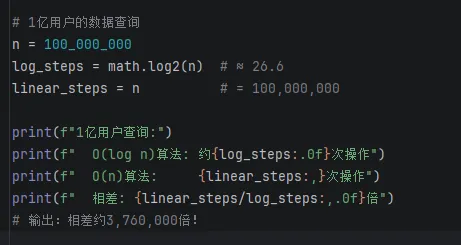
输出结果:

我们再次看到O(log n)算法复杂度要远远小于线性时间的O(n)。
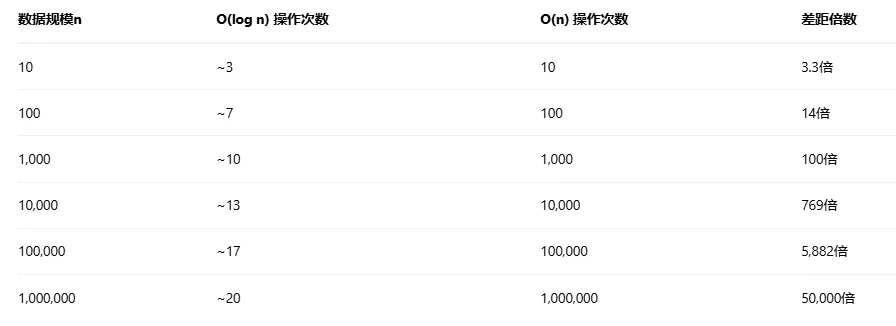
复杂度等级差异
在算法复杂度等级中,它们被明确区分:
三、小结
今天学习的内容有些深入了,探讨算法在编写程序中的应用。对于小数据来说似乎无所谓,但当数据量大之后,我们明显感觉到优秀的算法要比一般的线性、平方算法效率高很多。
特别是对于O(log n) 和 O(n) 的关系,就像高铁和绿皮火车的关系——都是交通工具,但速度不是一个数量级!
对数复杂度是算法设计的黄金标准之一,能在海量数据中保持极高性能,这是线性复杂度无法比拟的。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
