本文章仅用于信息安全防御技术分享学习,请勿利用文章内的相关技术从事任何非法测试,由于传播、利用本公众号所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关,请严格遵循法律法规。如有侵权可联系本人删除,本文可自行转载,但转载需要在清晰的地方标明出处及作者。
每篇一言
向前看,轻舟已过万重山。我是沫颜,未来的路我来陪你走
前言
在Python Web安全和代码执行漏洞利用中,Unicode变体字符绕过(常说的"斜体字符绕过")是一种常见且隐蔽的技巧,很多安全爱好者或开发人员会对其感到困惑:明明过滤了关键词,为什么恶意代码还能执行?看似不一样的字符,为什么Python能识别成同一个呢?在挖掘SRC、红蓝攻防中python代码执行都会经常遇到,有需要的可以收藏以后遇到使用。今天正好有时间,我将用通俗的语言讲清原理,搭配可直接上手的实战案例,再附上简单有效的防御方法,帮助各位理解、应用并防范这类绕过技巧 。在挖掘企业src、CNVD证书等企业系统中,绕过一般就是高危严重!每个企业src给的赏金不一样,一般在几千到几万元不等(文末可获取Unicode变体字符大全文档收藏)
。在挖掘企业src、CNVD证书等企业系统中,绕过一般就是高危严重!每个企业src给的赏金不一样,一般在几千到几万元不等(文末可获取Unicode变体字符大全文档收藏)
一、什么是Unicode变体字符?
我们平时使用的字母a、b、c,数字1、2、3,在Unicode编码中属于基础字符;而在数学排版、特殊排版场景中,存在一批视觉上与基础字符高度相似(如斜体、粗体、全角),但拥有独立编码的字符,这类字符被称为Unicode变体字符。
直观示例:
普通小写字母:a b c t
数学斜体小写字母:𝑎 𝑏 𝑐 ᵗ
全角数字:1 2 3
这些字符视觉相似,但编码完全不同,例如普通t的编码为U+0074,斜体t(ᵗ)的编码为U+1D57,全角1的编码为U+FF11。Unicode变体字符绕过的核心,就是利用这类字符的Unicode规范化特性,实现WAF关键词过滤、代码检测的绕过。
二、核心原理:Unicode的4种规范化形式
Python能将prinᵗ()识别为print(),关键在于Unicode规范化——Unicode标准为了让"视觉一致、语义相同"的字符在程序中被统一识别,定义了4种规范化处理方式,其中NFKD/NFKC是绕过技巧的核心。
4种规范化形式详解:
1. NFD(分解规范形式)
将"合体字"拆分为"基础字+标记",例如带重音的é(U+00E9),会被拆分为普通e(U+0065)+ 重音标记◌́(U+0301),相当于将一个字符拆分为两个组成部分。
2. NFC(合成规范形式)
与NFD相反,将拆分后的"基础字+标记"重新合成一个字符,例如将e+◌́重新合成é。这是日常电脑、网页最常用的规范化形式,核心是用最少的编码表示一个字符。
3. NFKD(兼容分解形式)
绕过核心之一:不仅会执行NFD的拆分操作,还会将视觉不同、语义相同的变体字符,直接拆分为对应的基础字符,例如:
连字ffi → f+f+i
带圈数字① → 1
全角A → 半角A
斜体ᵗ → 普通t
4. NFKC(兼容合成形式)
绕过核心之二:先执行NFKD的全拆分操作,再将可合成的基础字符重新拼接,最终得到与基础字符完全一致的结果,例如:斜体prinᵗ → NFKD拆分为p+r+i+n+t → NFKC直接得到print。
关键结论:Python在执行函数、识别变量名时,会对字符进行NFKD/NFKC规范化处理,因此变体字符会被自动转换为对应的基础字符;而若WAF(网站防火墙)仅做简单的关键词匹配(如仅检测print、os),不进行规范化处理,就会被变体字符"欺骗",从而实现绕过。
三、实战案例:可直接运行的代码演示
以下案例代码均可在Python3环境中直接运行,从基础的代码执行绕回到实际业务场景绕过,逐步展示Unicode变体字符的应用方式。
案例1:基础函数执行绕过——prinᵗ替换print
通过斜体t(ᵗ)替换普通t,构造payload,观察Python的规范化处理效果:
# 导入Unicode处理模块import unicodedata# 用斜体tᵗ替换普通t,构造payloadpayload = "prinᵗ(\"我被执行了!\")"# 打印规范化后的结果print("NFKC规范化后:", unicodedata.normalize('NFKC', payload))# 执行payloadexec(payload)
运行结果:
NFKC规范化后: print("我被执行了!")我被执行了!

解读:构造的payload为prinᵗ(),Python经过NFKC规范化后,自动转换为print(),最终成功执行;若WAF仅检测print字符串,则无法识别prinᵗ。
案例2:WAF关键词过滤绕过——绕过os关键词检测
实际开发中,多数WAF会过滤os、system、eval等危险关键词,利用Unicode变体字符+NFKC规范化可轻松绕过:
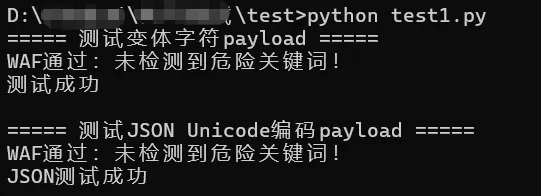
import unicodedataimport json# 模拟WAF:简单检测字符串中是否有"os"def waf(check_str): if "os" in check_str: print("WAF拦截:检测到危险关键词os!") return True print("WAF通过:未检测到危险关键词!") return False# 构造payload:用变体字符𝓸𝓼替换ospayload1 = "__import__('𝓸𝓼').system('echo 测试成功')"# 构造payload2:用Unicode编码\u006F\u0073替换os(JSON场景常用)payload2 = '{"cmd": "__import__(\'\\u006F\\u0073\').system(\'echo JSON测试成功\')"}'# 测试payload1print("===== 测试变体字符payload =====")if not waf(payload1): exec(unicodedata.normalize('NFKC', payload1))# 测试payload2(JSON场景)print("\n===== 测试JSON Unicode编码payload =====")if not waf(payload2): cmd = json.loads(payload2)["cmd"] exec(cmd)
运行结果:
===== 测试变体字符payload =====WAF通过:未检测到危险关键词!测试成功===== 测试JSON Unicode编码payload =====WAF通过:未检测到危险关键词!JSON测试成功
解读:WAF仅简单匹配os关键词,而payload中使用的是变体字符𝓸𝓼、Unicode编码\u006F\u0073,因此WAF判定无危险并放行;Python执行前,经过NFKC规范化或JSON解析,变体字符、Unicode编码均转换为os,最终成功执行系统命令。该案例贴近实际Web场景,多数接口接收JSON参数时,若仅做简单关键词过滤,易被此类方式绕过。
案例3:字符串长度限制绕过——单字符替换多字符
部分业务会限制参数字符长度(如长度≤8方可执行函数),利用NFKC特性,可用1个Unicode变体字符代替多个基础字符,突破长度限制:
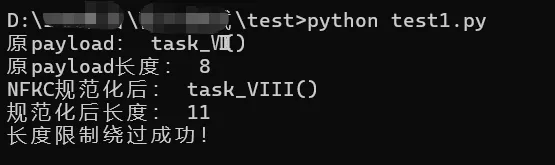
import unicodedata# 定义一个函数:task_VIII(VIII是罗马数字8,占4个字符)def task_VIII(): print("长度限制绕过成功!")# 构造payload:用罗马数字Ⅷ(1个字符)代替VIII(4个字符)payload = "task_Ⅷ()"# 打印原payload和长度print("原payload:", payload)print("原payload长度:", len(payload)) # 结果是8,符合长度限制# 打印NFKC规范化后的payload和长度norm_payload = unicodedata.normalize('NFKC', payload)print("NFKC规范化后:", norm_payload)print("规范化后长度:", len(norm_payload)) # 结果是11,实际执行的是task_VIII()# 执行payloadif len(payload)<= 8: exec(payload)
运行结果:
原payload: task_Ⅷ()原payload长度: 8NFKC规范化后: task_VIII()规范化后长度: 11长度限制绕过成功!
解读:业务限制参数长度≤8,用罗马数字Ⅷ(1个字符)替换VIII(4个字符),使payload长度刚好为8,通过检测;Python执行时,Ⅷ被NFKC规范化为VIII,最终成功执行task_VIII()。该方式实战中可用字符有限,但提示我们:不可仅做表面的长度限制,需对执行内容进行规范化处理。
案例4:类方法名的隐蔽绕过——变体字符与基础字符的方法名冲突
Python的类方法名同样会进行NFKC规范化,因此可用变体字符定义方法名,实现隐蔽调用,甚至覆盖原有方法:
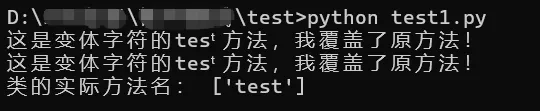
class Test: # 普通方法名test def test(self): print("这是普通的test方法") # 变体方法名tesᵗ(斜体t) def tesᵗ(self): print("这是变体字符的tesᵗ方法,我覆盖了原方法!")# 实例化类t = Test()# 调用普通test方法t.test()# 调用变体tesᵗ方法t.tesᵗ()# 查看类的所有方法名(排除内置方法)methods = [name for name in dir(Test) if not name.startswith('__')]print("类的实际方法名:", methods)
运行结果:
这是变体字符的tesᵗ方法,我覆盖了原方法!这是变体字符的tesᵗ方法,我覆盖了原方法!类的实际方法名: ['test']
解读:Python认为tesᵗ和test是同一个方法名,因此后定义的tesᵗ会覆盖先定义的test;无论调用t.test()还是t.tesᵗ(),执行的均为tesᵗ方法。这提示我们,代码审计时,不可仅关注表面的方法名,还需排查是否存在变体字符的隐蔽定义。
四、实用技巧:Unicode变体字符获取渠道
无需记忆字符编码,以下3个免费网站可直接获取变体字符,覆盖字母、数字、下划线等常用字符,满足实战需求:
Exotic Text:https://exotictext.com/zh-cn/italic/ (专门生成斜体、粗体、花体字符,操作便捷)
Compart Unicode:https://www.compart.com/en/unicode/ (可查询所有Unicode字符的编码和变体,精准查找目标字符)
ShapeCatcher:https://shapecatcher.com/ (按字符形状搜索,例如绘制t,即可找到所有视觉相似的t变体字符)
提示:不同环境(如Flask、Bottle框架)对变体字符的支持存在差异,例如Bottle框架因URL编码问题,仅%aa(a)、%ba(o)等少数变体字符可用,实际使用时需进行环境测试。
五、防御方法:可落地的安全防护策略
Unicode变体字符绕过的防御核心的是:所有用户输入的内容,在检测、执行前,先进行统一的Unicode规范化处理(NFKC),再开展关键词过滤、长度检测、代码执行等操作。以下是3种可落地的防御方法,覆盖从基础到进阶的各类场景:
方法1:基础防御——执行/检测前进行NFKC规范化
这是最核心、最有效的防御方式,无论何种场景,先对输入内容进行规范化处理,可彻底杜绝变体字符绕过:
import unicodedata# 定义规范化函数:所有输入先过一遍NFKCdef normalize_input(s): return unicodedata.normalize('NFKC', s)# 模拟用户输入的变体字符payloaduser_input = "prinᵗ(1) or __import__('𝓸𝓼').system('whoami')"# 先规范化norm_input = normalize_input(user_input)print("规范化后的输入:", norm_input)# 再做关键词过滤if "print" in norm_input or "os" in norm_input: print("检测到危险内容,拦截!")else: exec(norm_input)
效果:用户输入的prinᵗ、𝓸𝓼会被规范化为print、os,直接被关键词过滤拦截,无法执行恶意代码。
方法2:WAF/过滤优化——升级过滤逻辑
多数WAF的漏洞在于仅匹配原始字符串,未进行规范化处理,需优化过滤逻辑:
方法3:业务场景防御——拒绝直接执行用户输入
从根源上解决代码执行漏洞,是开发人员需遵守的核心原则:
禁止直接用exec/eval执行用户输入的内容,若必须执行,需进行严格的白名单校验(如仅允许执行指定函数,禁止包含系统命令、导入语句);
对JSON、URL参数等用户输入,先解析、规范化,再进行检测,例如JSON解析前先执行NFKC规范化;
字符串长度限制需基于规范化后的内容,而非原始输入。
六、核心知识点总结
Unicode变体字符(斜体、粗体、全角等)编码不同,但语义相同,Python会对其进行NFKC/NFKD规范化处理;
绕过的本质是WAF仅检测原始字符串,而Python执行前会对字符进行规范化,两者处理逻辑不一致;
防御的核心是统一规范化:所有用户输入,先进行NFKC规范化,再开展检测、执行操作;
最安全的防护方式是拒绝直接执行用户输入,从根源上避免代码执行漏洞。
七、总结
Unicode变体字符绕过看似复杂,实则核心是利用Unicode规范化与WAF简单匹配的逻辑差异。掌握其原理后,无论是安全审计中的漏洞挖掘,还是开发中的安全防护,都能快速找到关键突破点。
对于安全爱好者而言,这是基础的漏洞利用技巧,结合SSTI模板注入、代码执行漏洞等实际场景,可发挥重要作用;对于开发人员而言,只需坚守"先规范化、再处理"的原则,即可有效防范此类绕过攻击。
最后提醒:本文内容仅用于学习和安全审计,禁止用于非法攻击,网络安全的核心是防御,而非攻击。
参考:https://xz.aliyun.com/news/91607
点个关注不迷路~后面继续给大家更新企业SRC中拿赏金的实战渗透技巧
回复关键字【20260316】获取文档