一、问题的由来
朋友每天要处理上百张手机截图——提取单号、姓名、成绩、日期……再手动填进Excel。复制粘贴一整天,效率低、易出错,人还累。这类图片往往拍摄不规范、清晰度不高,传统OCR识别准确率堪忧。有没有更省力的办法?因此,我想编写一个批量处理工具,实现批量化操作,自动提取指定信息,然后可以转到Excel 里。
二、问题的分析
这个问题与提取发票信息有点儿像,不过发票一般都是pdf格式,而且很清晰,这是图片,一般都是手机拍摄的,不仅不规则,有时还不太清晰,所以要准确提取难度有点儿大。我想了一下,提供了两套解决的思路。
1. 用智能体的方法
我们进入豆包,在左侧菜单栏中,点击【更多】,找到【AI智能体】,再点击右上角的【创建智能体】
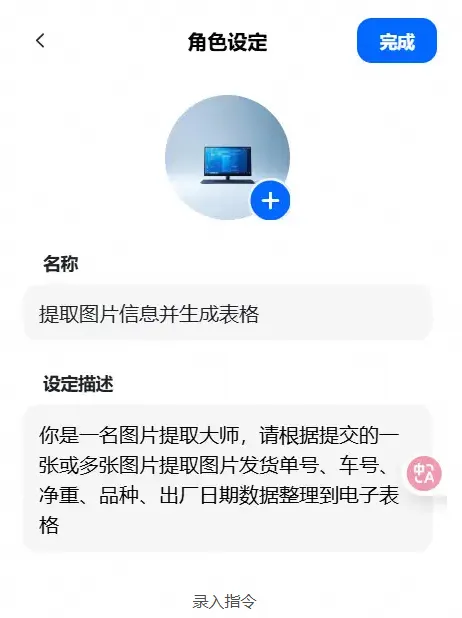
然后,在设定描述中输入相关指令,并为这个智能体设计一个名称,可以通过AI一键生成。
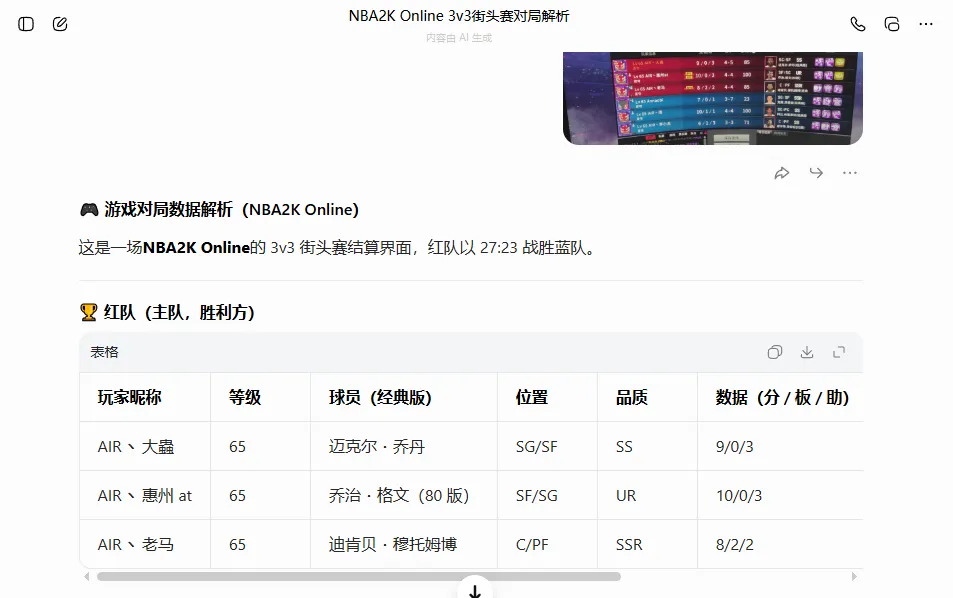
完成智能体编写后,提交豆包审核,审核通过后,我们就可以通过提交图片来实现相关信息的提交了。不过这种方法,一次只能提交一张图片,效果如下所示:
但这种方法的好处是可以在手机上提交识别,速度还挺快的,准确率也很好,而且操作免费。
2. Python编程法
另一种方法有点儿复杂,但可以实现批量操作,无人职守就可以完成提取图片信息的任务,但是就得消耗豆包API的额度,不过貌似价格不是很高。在编程前,可以去申请一个豆包api ,申请地址是:
火山引擎-你的AI云www.volcengine.com/
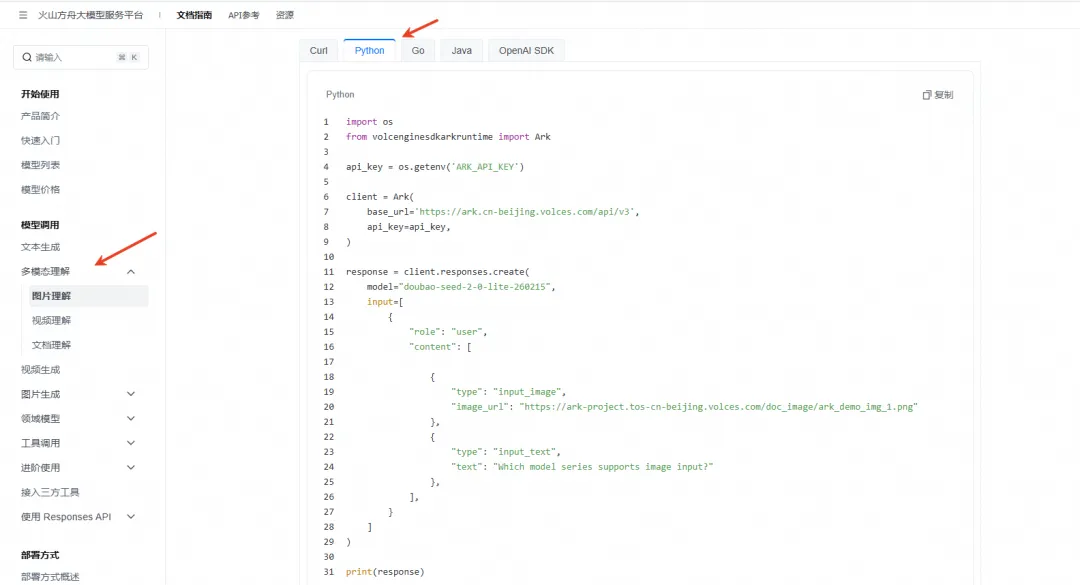
申请完之后,在控制台找到多模态 处理的AI样例代码如下:
import osfrom openai import OpenAI# 初始化客户端client = OpenAI( base_url="https://ark.cn-beijing.volces.com/api/v3", api_key="<API_KEY>" # 这里修改了一下,直接为变量赋值,输入你的API_KEY即可)response = client.chat.completions.create( model="doubao-seed-1-8-251228", #豆包的多模态处理模型。 messages=[ { "role": "user", "content": [ { "type": "image_url", "image_url": { "https://ark-project.tos-cn-beijing.volces.com/doc_image/ark_demo_img_1.png" }, }, {"type": "text", "text": "提取图片中的文字信息,其它不要显示。"}, ], } ],)# 提取content内容content = response.choices[0].message.contentprint("提取的内容:")print(content)
需要安装的依赖包:
1、 安装火山引擎方舟 SDK
pip install 'volcengine-python-sdk[ark]'
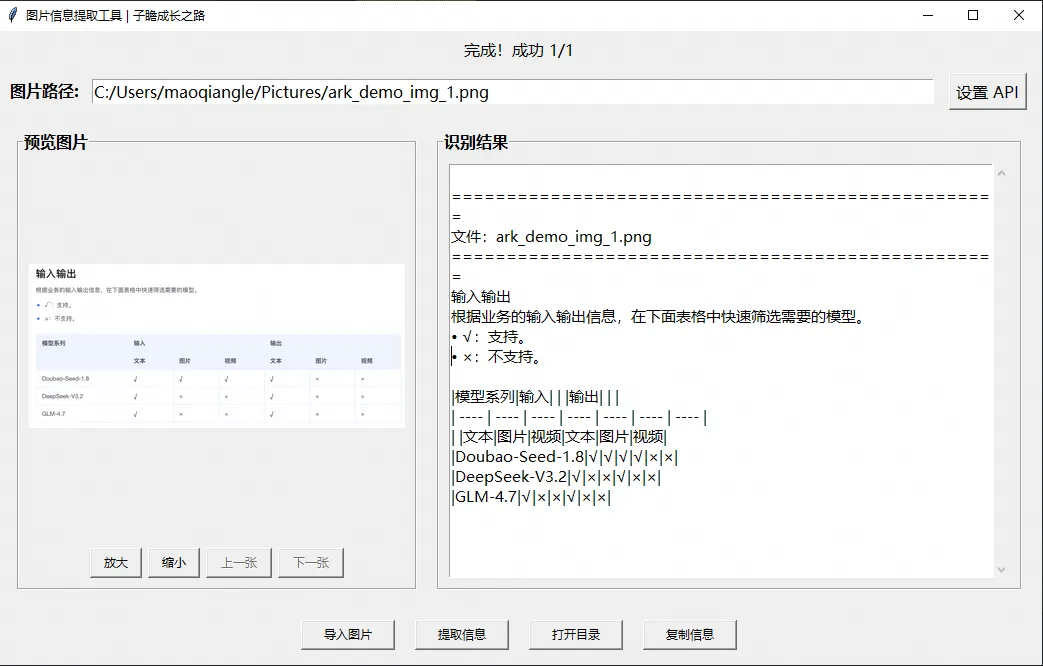
根据上面的样例代码,我们借助Python中的Tkinter 框架,编写了一款图片信息提取工具,实现包括图片的导入、预览、信息提取、复制等功能,基本的样式如下:
2.验证安装
智能识别 + 界面友好提取结果清晰展示在界面右侧,字段用制表位对齐,一键复制即可粘贴到Excel,格式整齐不混乱。
稳定预览体验修复了图片放大后按钮变形、预览框尺寸跳动等问题,并用 LabelFrame 分区设
计,让信息提取区与图片预览区一目了然,操作更直观。
API 智能管理启动时自动检测本地是否已配置豆包 API Key:
- 若已配置 → 显示“API 已加载”,无需重复操作
结果可追溯所有提取记录自动保存至本地,点击【打开目录】即可查看历史数据,不怕丢失。
部分代码展示:
def image_to_base64(self,image_path): # 获取图片文件的MIME类型 ext = os.path.splitext(image_path)[1].lower() mime_type = f"image/{ext[1:]}" if ext in ['.jpg', '.jpeg', '.png', '.gif'] else "image/jpeg" with open(image_path, "rb") as image_file: # 读取文件内容并进行Base64编码 base64_data = base64.b64encode(image_file.read()).decode('utf-8') # 返回完整的data URI格式 return f"data:{mime_type};base64,{base64_data}" def chat_doubao(self,local_image_path): # 初始化客户端 client = OpenAI( base_url="https://ark.cn-beijing.volces.com/api/v3", api_key="<YOUR API KEY>" # 这里要输入自己的API ) try: # 转换本地图片为Base64编码 image_data = self.image_to_base64(local_image_path) # 调用API处理图片 response = client.chat.completions.create( model="doubao-seed-1-8-251228", messages=[ { "role": "user", "content": [ { "type": "image_url", "image_url": { "url": image_data # 使用Base64编码的本地图片数据 }, }, {"type": "text", "text": self.get_order()}, ], } ] )
上面程序中,为了实现本地图片的读取,我们通过image_to_base64这个函数进行图像信息的转化,如果不转化,我们就得从网址里获取,有可能需要网络存储桶,不仅不方便,也会延迟速度。
三、学后总结
AI 正在让多模态处理变得简单随着人工智能能力持续提升,图片、音频、视频等非结构化数据的识别与理解越来越精准。结合 Python 的批量处理优势,我们能高效完成特定信息的提取与结构化保存——比如从截图中自动抓取单号、成绩等字段。
工具可灵活扩展,一器多用只需修改指令文件(如 order.txt),即可切换任务场景:
本质上,这是一个“提示词驱动”的智能提取框架——换指令,就换功能。
四、结语:
两种使用场景,自由选择:
- 临时处理几张图?用豆包 App 内的 AI 智能体(免费、手机可用)
- 每天上百张截图?用这个桌面工具 + 豆包 API,批量处理、无人值守、效率翻倍
觉得这期有帮助?点个赞、加个关注!私信 “批量提取工具”,源码马上发你~你的支持,是我更新的最大动力!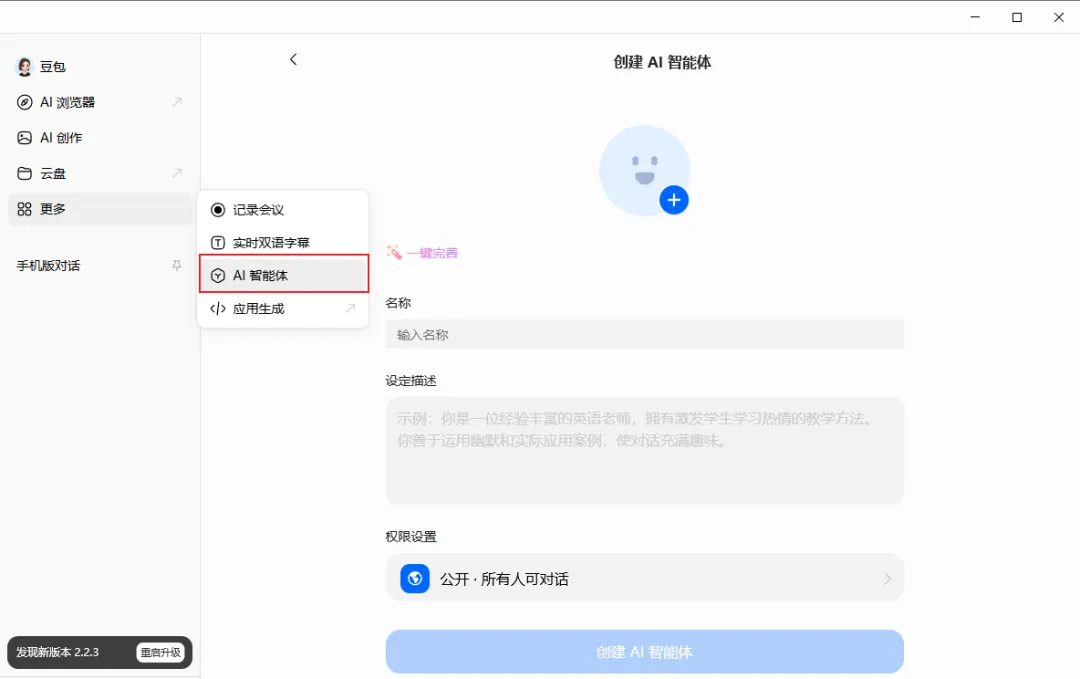
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
