OpenClaw 三周超越linux登顶github,Claude携手微软增势超越OpenAI,杨立坤携手谢赛宁拿下10亿美元seed round打造AMI Labs押注世界模型
- 2026-07-04 00:49:50

或许我们热爱 AI,
正是因为它总在变化,总在翻涌,总有新的东西把旧的判断推翻。
它永远动荡,永远新鲜,永远不会一成不变。
而这种鲜活本身,就足够让人兴奋。

hey 吾友😊,欢迎来到由JoinAI|卓印智能算法团队出品的:「太阳底下AI有新鲜事儿」周刊。
我们将以「AI构建者」独有的技术视角和克制,为你精心筛选出每周Top 3:论文、项目与动态,这里不关心热点流量的幻觉,只追踪真正值得关注的技术与趋势,这里不会只宣扬AI的好,同样也会揭露AI的问题。
全文字数:13033|阅读时长:5-7分钟|推荐阅读方式:收听
[本周导读]
🔬 前沿论文
Moonshot AI|Attention Residuals:把残差连接从“固定加法”改写成“跨层注意力读取”
这篇最值得注意的地方,不是又给 Transformer 加了什么局部技巧,而是它回头重审了一个大家几乎默认不动的基础结构:残差连接。过去模型在 token 维度上已经高度动态化了,但在深度维度上,层间信息传递仍然是近乎固定的累加。Attention Residuals 的关键突破,就是把这种固定残差升级成可学习的跨层 attention,让当前层能够按输入动态读取历史层表示。 更重要的是,它不是只停留在“概念很美”的阶段,而是进一步做出了可扩展的 Block AttnRes,真正接进了 48B 级 Kimi Linear,并完成了超大规模预训练。这篇论文真正释放出的信号是:Transformer 下一轮值得被重写的基础模块,可能不是 token attention,而是 residual 本身。
清华 & Galbot|LATENT:用不完美人类动作数据,教会人形机器人打网球
人形机器人最难的往往不是静态动作,而是高速、连续、全身协调的动态技能。LATENT 的价值,就在于它没有执着于“必须先拿到完美 mocap 数据”,而是证明了:哪怕只有碎片化、并不完整的人类网球动作先验,也依然能学出很强的真实技能。 它的思路很有代表性:先把不完美动作蒸馏成可用的 latent skill prior,再让高层策略去做纠偏和组合。这种路线非常现实,因为真实世界的大多数高动态任务,本来就拿不到完整、干净、可直接模仿的数据。LATENT 不是单纯展示“机器人会打球”这么简单,而是在回答一个更重要的问题:当高质量示范数据天然稀缺时,具身智能到底该怎么学。
OpenClaw-RL|把 agent 的真实使用过程,重新定义成训练数据流
OpenClaw-RL 最重要的,不是“又一个 agent 强化学习框架”,而是它抓住了一个很多系统一直在浪费的东西:next-state feedback。用户纠错、工具报错、GUI 变化、测试失败,这些过去通常只是被塞回上下文里继续对话,但并没有真正进入训练闭环。 这篇工作的价值,在于把这些异构反馈统一建模成在线学习信号:既有“你做得好不好”的评估性奖励,也有“你应该怎么改”的方向性监督。换句话说,它在推动 agent 从“部署后静态使用”走向“部署中持续进化”。这可能不是终点方案,但它很像是把 agent 真正做成活系统所必须补上的一块拼图。
MetaClaw|让 agent 在真实对话里边服务、边积累经验、边慢速进化
MetaClaw 的吸引力,在于它把“训练”和“使用”这两件事尽量接到了一起。前端用 OpenAI-compatible proxy 接住对话和工具调用,后端把会话自动总结成经验,再逐步转成 skills、reward 和权重更新。用户表面上只是正常在用 agent,系统底层却在持续长技能、长记忆、长能力。 这个方向真正有想象力的地方,是它不再把 agent 看成一次性部署的软件,而更像一个会随着使用逐步变强的系统。它现在当然还受限于 reward 质量、总结质量和训练稳定性,但产品方向已经很清楚了:个人 agent 的竞争,未来很可能不只是“第一次有多聪明”,而是“越用会不会越懂你”。
CLI-Anything|把传统软件批量改造成 agent 可调用接口的通用施工框架
很多 agent 落不了地,并不是因为模型不够强,而是因为大量旧软件根本没有 agent-native 接口。CLI-Anything 的价值,就在于它试图把“给软件做 agent 化改造”这件事做成一条流水线,而不是一堆手工插件。 它真正值得关注的点,不是能不能给某一个软件生成 CLI,而是它在尝试建立一种更通用的中间层:把历史软件世界重新包装成 LLM 可理解、可调用、可组合的接口层。这个方向一旦成熟,影响的就不只是 OpenClaw 生态,而会是更广义的软件 agent 化基础设施。
Fish S2 Pro|开源语音模型开始从“能说话”走向“可控、低延迟、可部署”
S2 Pro 值得看的,不是“又一个 TTS 模型”,而是它把细粒度控制、流式推理和多语言覆盖一起做进了一个相对完整的开源底座里。尤其是文本中直接插入自然语言控制标签这一点,很适合角色语音、内容生产和互动式语音场景。 这背后的信号很明确:开源语音这条线正在从“demo 型模型”往“能被拼进产品栈”的基础组件演进。对开发者来说,这比单纯刷一两个音质 benchmark 更重要,因为真正有价值的不是一段好听样音,而是一个可控、可接、可二次开发的生产级底座。
Anthropic|Claude 正在从强模型,变成企业工作系统里的能力层
这一轮 Claude 最值得注意的,不是某一个单点功能,而是它同时在三个层级向工作流渗透:工程治理层、多文件知识协作层,以及长上下文成本层。无论是多智能体代码审查、Excel / PowerPoint 的跨文件上下文,还是 1M token 长上下文取消溢价,本质上都在服务同一个方向:让 Claude 更深地嵌进真实企业系统。 这说明 Anthropic 的竞争重点,已经不只是“模型够不够强”,而是“能不能成为企业流程里最难替换的那一层能力”。在企业软件世界里,真正有壁垒的从来不只是模型本身,而是它被放进了多少实际流程里。
OpenClaw|从“养龙虾”热潮走向基础设施化,agent 生态开始长出标准层
OpenClaw 这一周真正重要的,不是继续涨星,而是目录站、benchmark、技能市场、一键封装、大厂本地化几乎同时出现。这意味着它已经不再只是一个爆款开源仓库,而是在被组织成一套可比较、可分发、可接入的 agent 基础设施。 当一个开源项目同时开始拥有榜单、目录、工具层、部署层和平台封装,它的性质就变了。它不再只是“社区很热闹”,而是开始具备某种事实上的标准层地位。热闹当然还在,但更值得盯住的,是谁会借它定义下一代 agent 生态的分发规则、接口规范和安全边界。
AMI Labs|世界模型路线,正在从学术主张变成高规格资本叙事
LeCun 的 AMI Labs 拿下超大种子轮融资,这条新闻真正重要的,并不是融资数字本身,而是它说明“后 LLM 路线”已经不再只是演讲里的替代愿景,而是被正式装进了顶级公司和资本配置里。再叠加此前 World Labs 的连续融资,可以明显看到:世界模型路线正在被持续、系统性地押注。 更关键的是,这条路线已经开始分化。一边是偏 spatial intelligence / 3D 世界生成,一边是更明确强调抽象预测、记忆、规划与真实世界理解。也就是说,世界模型不再只是一个模糊口号,而开始变成多个足够有分量的产业方向。对整个行业来说,这意味着主流 LLM 路线之外,真正有组织形态、研究班底和资本耐心的替代叙事,已经开始成形了。

怎么做:
遇到长文档、长视频、长流程任务时,先别一次性全丢给模型。更稳的做法是:先按阶段拆开,逐段处理;再保留两类记忆——一类记全局目标和关键结论,一类记最近几步的局部细节。 也就是:分块处理 + 全局记忆 + 局部窗口。
为什么好用:
LoGeR 的启发是,长任务不能只靠拉长上下文窗口,还要靠 chunk 化处理 + 混合记忆,同时保住全局一致性和局部精度。 对普通用户来说,重点就是:长任务先拆再串,比一口气全喂进去更稳。


推荐指数: 🌟🌟🌟🌟🌟
一句话导读:
Attention Residuals 把固定残差累加升级为“跨层注意力读取”,让每一层都能按当前输入动态选择历史层信息,从而缓解 PreNorm Transformer 中随深度加深而不断加重的表示稀释问题。
⚽️ 推荐理由:这篇工作的价值在于,它盯上的不是注意力、MoE 或上下文长度,而是一个几乎所有大模型都默认接受的基础结构:残差连接本身。标准 PreNorm 残差会把所有历史层输出用固定权重一路相加,层数一深,隐藏状态幅度就不断累积,早期层信息被埋没,后面层为了“发出声音”只能学更大的输出。Attention Residuals 的思路很直接:把这种固定加法改成沿“深度维度”的 softmax attention,让当前层从历史各层里动态挑选有用表示。更关键的是,作者没有停留在概念层,而是进一步提出可扩展的 Block AttnRes,把跨层访问压缩到 block 级别,让它真正接进 48B 级 Kimi Linear,并完成 1.4T token 预训练。这不是小修小补,而是在重写 Transformer 的基础信息流机制。
固定残差长期未被重审: 现代 LLM 在序列维度已经用可学习注意力和专家路由做动态选择,但在“深度维度”上,层间信息聚合依然是固定 unit weight 的残差相加,几乎没有选择机制。
PreNorm 会带来稀释问题: 在 PreNorm 结构中,隐藏状态幅度会随层数近似线性增长,导致单层输出相对贡献被不断稀释,早层信息难以被后层有选择地重新调用。
现有改进仍受递归范式限制: 无论是缩放残差、Highway 还是多流递归,本质上都仍让每层只能看到上一个聚合状态,而不能直接访问所有历史层输出。
跨层注意力替代固定累加: Full AttnRes 让每一层对所有先前层输出做 softmax attention,用可学习伪查询向量决定读哪些层、读多少,从“固定累加”变成“内容相关的深度检索”。
Block 版本解决工程开销: 为了避免全量跨层 attention 带来的显存与跨 stage 通信开销,论文提出 Block AttnRes,把多层压成 block 表示,再只对 block 级历史做 attention,把复杂度从 O(Ld) 降到 O(Nd)。
训练动态与下游结果都更好: 在 scaling law、1.4T token 预训练和多项 benchmark 上,AttnRes 都优于基线;同时它还让输出幅度在深度上更受控、梯度分布更均匀,直接缓解了 PreNorm dilution。
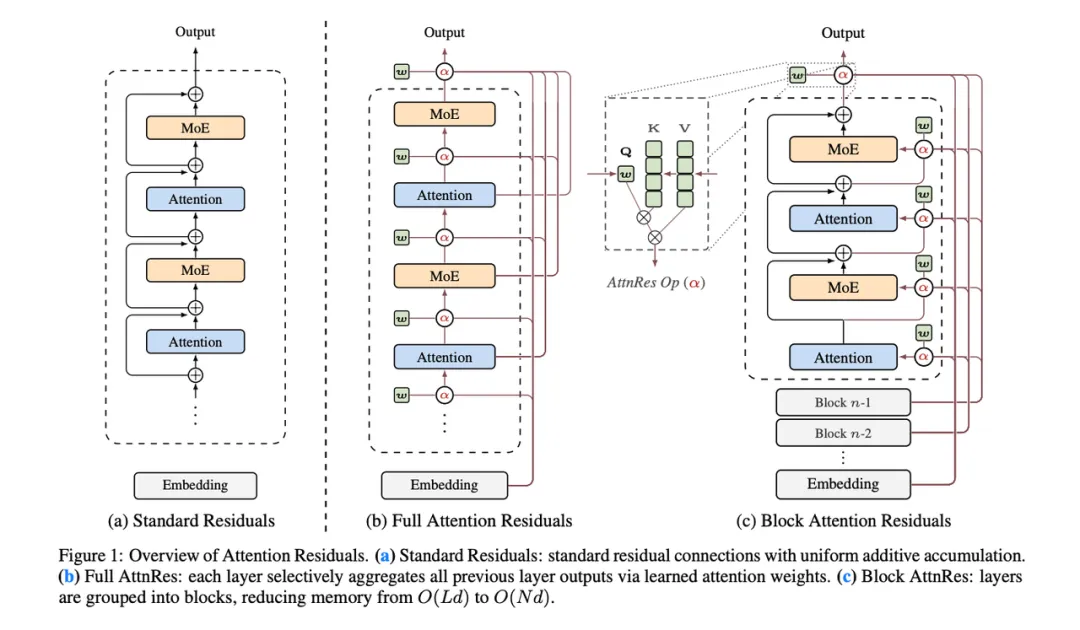
Attention Residuals 最有意思的地方,在于它把一个很强的直觉真正写成了可训练、可扩展的结构:注意力不仅能沿 token 维工作,也可以“旋转 90 度”沿深度维工作,从而自然概括残差连接。 传统 residual 本质上是在 layer 维度做固定权重的信息累加,而 AttnRes 则把这种固定聚合升级为可学习的 depth-wise attention,让当前层能够动态选择该读取哪些历史层、读取多少。换句话说,残差连接可以被理解成一种退化版的跨层注意力。这个视角非常强,因为它把 ResNet、Highway、mHC 等结构统一进了“深度维信息混合”框架里,也说明 Transformer 下一个值得重写的基础模块,可能不是 token attention,而是 residual 本身。论文真正的价值,不只是效果提升,而是把“固定残差”升级成了“动态跨层路由”。

推荐指数: 🌟🌟🌟🌟🌟
一句话导读:
LATENT 提出一种“从不完美人类网球动作片段中学习”的框架,让人形机器人在保留自然运动风格的同时,学会稳定回击高速来球,并在真实世界实现多人连续对打
⚽️ 推荐理由:这篇论文最有意思的地方,不是单纯让机器人“会打网球”,而是证明了即使没有完整、精确、可直接模仿的人类网球数据,也能学出很强的人形体育技能。作者并没有去采集完整比赛级 mocap,而是只收集前后手击球、横移、交叉步等 primitive motion fragments,再通过 LATENT 把这些“不精确、不完整”的动作先蒸馏成可用的 latent action space,再让高层策略去做“纠正 + 组合”。这极大降低了数据采集门槛,也更符合现实中很多高动态任务的数据条件。更重要的是,它不是停留在仿真里,而是部署到 Unitree G1 上,真实实现与人类稳定多拍对拉,来球峰值速度还能超过 15 m/s,说明这套路线对未来人形体育、动态操作和高机动技能学习都很有参考价值。
完整网球数据难采: 网球涉及大范围跑动、多拍连续交互,以及极短时间内的精细击球接触,导致通过遥操作或完整动作捕捉来收集高质量 humanoid tennis 数据几乎不可行。
人类动作先验仍有价值: 虽然采集不到完整比赛动作,但前后手挥拍、横移、交叉步这类 primitive skills 相对容易采集,这些碎片仍然包含了有用的人类运动先验。
高动态技能更难迁移: 人形机器人不仅要学会击球,还要解决高速来球、全身协调、动作自然性以及 sim-to-real transfer 等一整套问题,远比静态 manipulation 更难。
不完美数据也能学: LATENT 不依赖完整比赛动作序列,而是从五小时 primitive motion fragments 中学习,数据只覆盖常见网球基础技能,大幅降低采集成本。
纠正+组合 latent 技能:方法先训练 motion tracker,再蒸馏出可纠正的 latent action space;高层策略一边调用 latent primitive,一边直接修正持拍手腕动作,以弥补击球精度不足。
LAB抑制动作空间被滥用: 作者提出 Latent Action Barrier,用基于 Mahalanobis 距离的方式限制高层策略偏离 prior 的范围,避免 RL 训练中为了完成任务而产生抖动、不自然、低质量动作。

LATENT 的真正突破,在于它回答了一个很现实的问题:当高质量人形动作数据根本拿不到时,怎么仍然学出强技能?它没有执着于“完美 imitation”,而是转向“先拿到足够好的 primitive prior,再允许策略在任务中纠偏和重组”。这种思路非常适合体育、动态 locomotion、甚至很多真实工业任务,因为现实数据往往天然就是碎片化和不完美的。从结果看,LATENT 在仿真里相对 PPO、AMP、ASE、PULSE 都明显更强,真实机上也显著优于去掉 dynamics randomization 或 observation noise 的版本,说明其方法链条是闭环成立的。当然,它仍依赖 mocap 和外部光学系统,离真正“自主感知 + 自主对打”的通用人形网球选手还有距离,但已经是非常扎实的一步。

推荐指数: 🌟🌟🌟🌟🌟
一句话导读:
OpenClaw-RL 提出一种统一的在线 agent 强化学习框架,把用户回复、工具输出、GUI/终端状态变化等“下一状态信号”直接转成可训练监督,让 agent 在被使用的过程中持续自我优化。
⚽️ 推荐理由:这篇论文最有意思的点,是它抓住了一个很多 agent 系统都在浪费的资源:每一次交互后的 next-state,本身就是免费反馈。用户追问、纠错、工具报错、测试结果、GUI 变化,这些过去大多只被当作上下文继续喂给模型,却没有真正变成在线学习信号。OpenClaw-RL 的贡献,是把这些异构反馈统一建模成两类监督:一类是“你做得好不好”的 evaluative signal,用 PRM 转成标量奖励;另一类是“你应该怎么改”的 directive signal,用 Hindsight-Guided OPD 提取成 token-level 方向性监督。更关键的是,它不是单一环境里的 RL,而是想打通 personal conversation、terminal、GUI、SWE、tool-call 五类 agent 场景,让同一套基础设施支持“边服务边学习”。这对个人 agent 和通用 agent 都很有启发性。
交互反馈长期被浪费: 大多数 agent 系统在每次动作之后,都会收到用户回复、工具结果、测试 verdict 或界面变化,但这些信息通常只被当作后续上下文,而没有变成在线训练信号。
现有 agent RL 场景割裂: 终端 agent、GUI agent、SWE agent、tool-call agent 和 personal assistant 往往各有各的训练管线,缺少一个统一框架去处理异构环境中的强化学习。
标量奖励信息不够丰富: 传统 RL 更擅长利用“对/错”式奖励,但很多真实反馈其实包含更细的纠错方向,例如“你应该先检查文件再编辑”,这类信息如果只压成一个分数会损失大量监督价值。
统一 next-state 学习范式:OpenClaw-RL 把用户回复、工具输出、GUI 状态变化、SWE 测试结果等都视作 next-state signal,并认为这些信号可以在同一训练循环里共同优化同一个策略。
二元奖励 + OPD 联合训练: 框架同时支持 Binary RL 和 Hindsight-Guided OPD,前者把下一状态转成 process reward,后者从反馈中抽取 textual hints,再构造 teacher context,为 student 提供 token-level 方向性优势监督。
异步解耦基础设施:系统将 policy serving、environment hosting、PRM judging 和 policy training 四部分完全异步解耦,实现服务不中断、训练不中断、评估不中断,支持 personal agent 和 general agent 并行扩展。
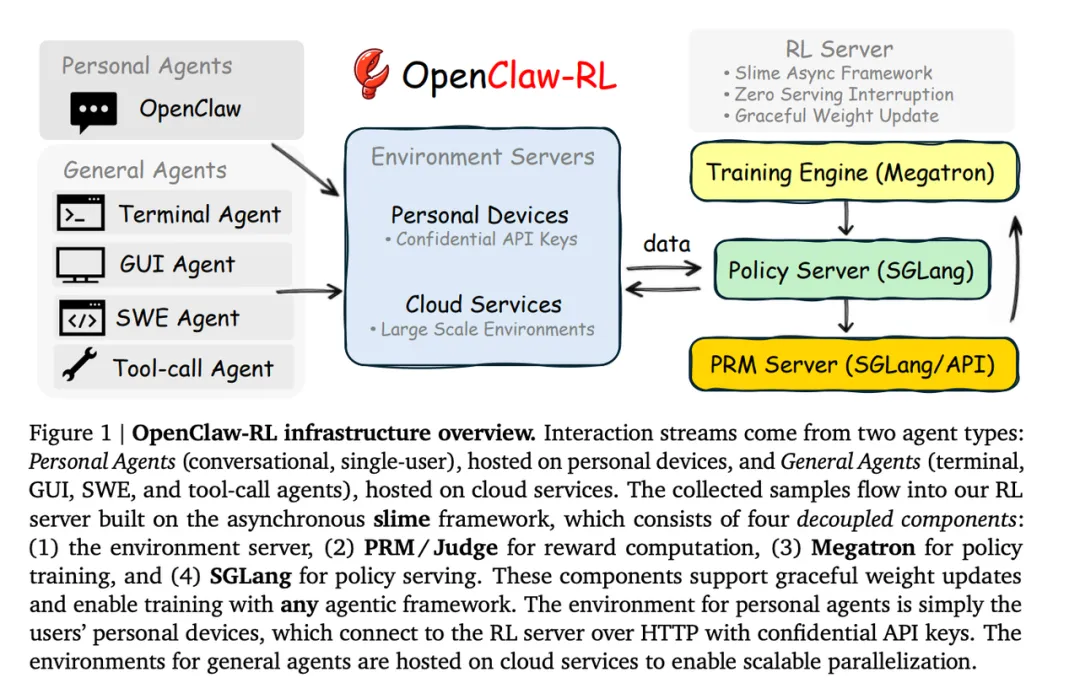
OpenClaw-RL 的真正价值,在于它把“agent 使用过程”本身重新定义成训练数据流,而不是部署后的静态消费过程。这个视角非常强,因为现实世界里最丰富、最持续、最便宜的监督,往往就来自用户和环境的即时反应。相比只做离线轨迹蒸馏或单一环境 RL,这篇工作更像是在补 agent 学习闭环里的最后一块拼图:如何在真实使用中持续更新策略。它最亮眼的地方不是某个单一算法,而是把 Binary RL、OPD、PRM 和异步 infra 组合成一个完整系统,并且同时覆盖 personal 与 general agents。不过,它的上限也依赖 judge 质量、hint 抽取质量以及在线训练稳定性,一旦反馈噪声很大,错误监督也可能被放大。即便如此,这仍然是 agent 走向“持续在线进化”的一个非常关键方向。



🦄 推荐理由:MetaClaw 最吸引人的地方,是它把“和 agent 的每次真实对话”都变成学习信号,而不是把训练和使用割裂开。它的核心产品思路很清晰:前面用一个 OpenAI-compatible proxy 接住 OpenClaw 的所有请求,在线注入相关 skills;后面把会话自动总结、积累成经验,再通过 RL 或 teacher distillation 做慢速权重更新。这样用户平时只是正常聊天、提需求、跑工具,但系统会在后台持续“长技能、长经验、长权重”。更重要的是,它不要求你自建 GPU 集群,README 直接强调可接 Kimi、Qwen、Claude、MiniMax、OpenAI、Gemini 等 API,训练后端则接 Tinker 或 MinT,部署门槛明显低很多。对于想做“会越用越懂你”的个人 agent 或通用 agent,这个方向非常有想象力

MetaClaw 的完成度其实比很多“Agent 会进化”口号型项目高不少,主要体现在四点。第一,模式分层明确:skills_only、rl、madmax 三种模式覆盖从轻量技能注入到完整异步进化,用户可按成本和风险逐步启用。第二,异步架构清楚:serving、reward、training 解耦,避免训练打断在线服务。第三,调度设计很产品化:README 里明确写到慢速 RL 更新可以只在睡眠、空闲或 Google Calendar 会议时间运行,这很像真正面向日常使用的 agent 运维逻辑。第四,一键化做得不错:metaclaw setup + metaclaw start 两条命令就能起系统,降低了尝鲜门槛。当然,它现在的真实上限仍取决于 reward 质量、skill summary 质量和云端 LoRA 训练的稳定性;但就产品方向看,它已经不只是“AutoResearch for agents”,而是一个更接近在线进化型 agent OS 的雏形。


链接:https://github.com/HKUDS/CLI-Anything
🦄 推荐理由:CLI-Anything 的核心吸引力在于,它不是再做一个“给某个软件写插件”的小工具,而是试图把这件事抽象成一条可复制流水线:用一条命令,把任意现有软件改造成 agent 可调用的 CLI 接口。项目首页把目标写得很明确——“Making ALL Software Agent-Native”,并强调可面向 OpenClaw、nanobot、Cursor、Claude Code 等平台使用;其生成流程也不是只吐出几个命令,而是覆盖分析、设计、实现、测试、文档和发布等完整 7 个阶段。README 里还给出了 GIMP、Blender、LibreOffice、Zoom 等多类软件的 harness 或插件支持,说明它的野心不是单点适配,而是想成为“软件 agent 化”的通用施工框架。这个方向对 Agent 生态很重要,因为真正限制 agent 落地的,往往不是模型本身,而是老软件没有 agent-native 接口。

CLI-Anything 最强的地方在于“工程闭环完整”和“平台兼容意识强”。第一,它不是只生成命令封装,而是明确包含 JSON 输出、REPL、undo/redo、测试规划、测试实现和安装发布,这意味着它想交付的是“可上线、可维护的 CLI 产品层”,而不只是 demo。第二,它把平台接入做成多入口形态:README 明确列出 Claude Code、OpenClaw、OpenCode、Codex、Qodercli 等支持方向,还持续通过社区更新补 Windows 兼容、OpenClaw 支持和新的应用 harness,说明它很重视真实使用链路。第三,它选择 CLI 作为 agent 接口,是一个很聪明的产品判断:结构化、可组合、自描述、天然适合 LLM。它的潜在难点在于,不同软件内部 API 质量差异极大,自动生成 CLI 的上限会受目标软件可脚本化程度影响;但如果这条流水线继续成熟,它很可能会成为“软件 agent 化基础设施”而不是单个仓库项目。


链接:https://huggingface.co/fishaudio/s2-pro
🦄 推荐理由:fishaudio/s2-pro 值得关注,核心不是“又一个 TTS 模型”,而是它把细粒度可控性、流式低延迟和多语言覆盖放进了同一个产品定位里。模型卡显示,它支持 80 多种语言,并强调可在文本中直接插入自然语言风格标签进行控制,例如停顿、强调、耳语、情绪和音量变化等,这种“inline control”比传统只调几个固定参数更适合做内容生产、角色配音和互动式语音应用。架构上它采用 Dual-AR:4B 的 Slow AR 负责主语义码本,400M 的 Fast AR 补足剩余残差码本,既兼顾音质也考虑推理效率。官方还同时提供模型权重、微调代码和基于 SGLang 的流式推理引擎,说明它更偏“可部署的语音底座”而不是单点 demo。
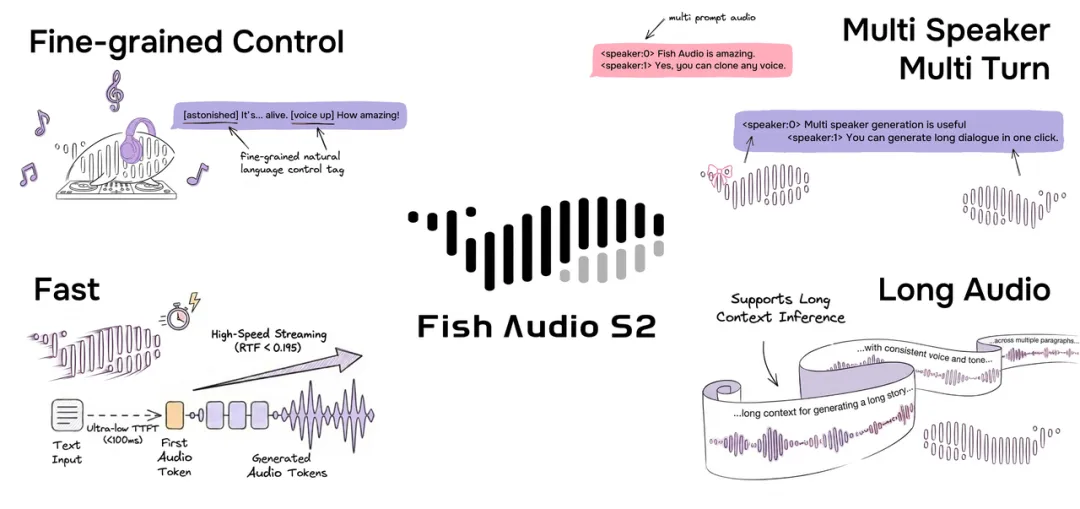
从产品功能角度看,S2 Pro 的亮点主要有四个。第一,控制粒度很细,支持把自然语言控制直接写进文本,且模型卡声称可识别 15,000+ 唯一标签表达,这对剧情配音、播客、情绪化 TTS 很有吸引力。第二,流式能力明确,官方给出单张 H200 上约 100ms 首音时间、RTF 0.195 的指标,说明它不是只追求离线效果,也在面向实时交互。第三,多语言覆盖广,模型页写明支持 80+ 语言,适合跨语种内容场景。第四,开发者友好,发布内容不仅有权重,还有微调代码和推理引擎。它的不足也很直接:采用研究许可,免费范围限研究与非商用,商业化需要单独授权;另外,真正的落地体验还取决于不同语言上的稳定性是否均衡。整体看,它更像一个“高可控、可部署、偏生产级”的开源语音生成底座。


从代码审查到 Office 协作,再到长上下文成本下探,Anthropic 的重点已不再只是“模型更强”,而是让 Claude 更深地嵌入真实工作流。
若说你之前对 Claude 的理解依然偏向于一台高性能模型/编程机器的话,那么这一轮更新释放给你的信号已经非常明确:Anthropic 正在把它推进为 企业工作系统中的基础能力层。
一边,Claude Code 引入多智能体代码审查,把 AI 从“写代码”推进到“管代码”,另一边,微软发布 Copilot Cowork,并被多家媒体指向与 Claude 的更深整合,说明 Claude 正在进入更大的办公与企业软件体系,与此同时,Claude for Excel / PowerPoint 的跨文件上下文与 Skills,以及 Claude 4.6 取消长文本溢价,也都在同步降低它进入复杂工作流的门槛。
Claude 现阶段的竞争重点似乎悄然偏向于“如何最佳全面入侵工作流”。
🧩 相关重要信息
Anthropic 已正式发布Claude Code 的多智能体代码审查系统。官方表示,这套系统会在每次 PR 上自动调度一组 agents,结合完整代码库上下文并行寻找缺陷,面向 Team 与 Enterprise 用户提供研究预览。根据 Anthropic 公布的数据,部署后获得实质性审查意见的 PR 比例从约 16% 提升至 54%,而单次审查平均成本约为 15–25 美元。
微软也已发布Copilot Cowork,并确认其进入有限客户研究预览。微软官方将其描述为一种可在后台持续推进多步任务的工作方式,并计划通过 Frontier 计划扩大测试。虽然微软官方博客并未直接写明“由 Claude 驱动”,但包括《金融时报》在内的多家媒体都指出,微软正把 Anthropic Claude 纳入 Copilot 更广的模型体系中。
在知识工作侧,Claude for Excel 和 PowerPoint 也迎来更新。根据 VentureBeat 等媒体报道,新版支持 跨文件共享上下文,可在一个会话中同时理解和操作多个工作簿与幻灯片,并通过 Skills 把复杂业务流程保存成可复用操作。
同时,Anthropic 也已确认 Claude Opus 4.6 与 Sonnet 4.6 的 1M token 上下文能力进入更广泛可用阶段,并取消此前长文本的额外溢价,统一采用标准计费。
⚙️ 核心解读
这一轮 Claude 的变化,最值得注意的不是单一功能,而是它正在同时向三个层级渗透。
第一层,是工程治理层。
Claude Code 的多智能体代码审查说明,Anthropic 已不满足于让 AI 帮开发者“写点东西”,而是开始让 AI 进入真正的工程流程——做 review、找风险、参与治理。
第二层,是企业协作层。
无论是微软 Copilot Cowork 的推出,还是 Claude for Excel / PowerPoint 的跨文件上下文和 Skills,都指向同一个方向:Claude 正在从一个问答式模型,变成一个可以介入 Excel、PPT、会议准备、文档处理等具体知识工作的协作者。
第三层,是成本与门槛层。
取消 1M 上下文溢价的意义非常大。它意味着长上下文不再只是“高价实验能力”,而开始成为复杂工作负载中的默认能力。
把这三层放在一起看,Claude 的战略重点已经很清楚: 不是单纯追求“最强模型”标签,而是努力成为 企业工作流里最难被替代的那一层能力。
🧭 行业影响分析
简单说说
Claude 正从高性能模型,向企业工作系统中的基础能力层推进。
多智能体代码审查意味着 Anthropic 开始进入工程治理,而不只是 coding 辅助。
与微软办公体系的结合,以及 Excel / PPT 更新,显示 Claude 正更深地嵌入知识工作软件。
取消长文本溢价,则显著降低了复杂工作流采用 Claude 的成本门槛。(很好,终于干了件人事啊!)
展开说说
如果把这条新闻放进更大的行业结构里看,它其实和 OpenAI 的路径形成了很清晰的对照。
OpenAI 更像是在做一套“默认入口 + 专业工作台 + agent 生态”的产品栈,重点是让不同用户层级都留在 ChatGPT 体系里。 Anthropic 的走法则更聚焦:不急着做最大众的入口,而是持续把 Claude 往 高价值、低容错、强协作 的工作场景里推进。
这也是为什么这轮更新看上去分散,实际却非常一致:
代码审查、Office 协作、跨文件上下文、Skills、长上下文降价——它们共同服务的都是一件事:
让 Claude 不只是一个聪明的模型,而是一个能真正被放进工作系统里的能力层。
在企业软件语境里,最有价值的并不一定是“最强模型”,而是 最容易进入现有流程、最容易复用、最不容易被替换 的模型。Claude 现在明显在朝这个方向走。


一周之内,评测、目录、技能市场、一键部署与大厂封装同时出现。OpenClaw 不再只是一个爆款开源项目,而正在被组织成一套可比较、可分发、可接入的 agent 基础设施。
如果说上周我们判断,OpenClaw 的爆发已经不只是一次开源项目出圈,而是在把 AI Agent 从概念验证推向生态化、入口化与标准化阶段,那么这一周的新信息几乎给出了连续验证。
一面,OpenClaw 自身进入高频迭代,版本更新开始明显转向长期部署、安全修复与生态扩展,同时,PinchBench 这类 benchmark 开始给出榜单,OpenClaw Directory 这类目录站与腾讯 SkillHub 这类技能平台相继出现,更重要的是,腾讯、智谱、小米等中国厂商已经不再停留在围观层面,而是在直接做本地化封装、技能分发与端侧入口接入。
这意味着,OpenClaw 正在从“养龙虾”的社区热潮,走向真正的基础设施化阶段。
🧩 相关重要信息
OpenClaw 近期在 GitHub 上继续快速增长,目前公开星标已突破 30 万,并连续发布多个新版本,进入非常明显的高频迭代节奏。GitHub Releases 显示,3 月中旬版本更新不仅包含功能增强,也集中修复了高危安全问题,并开始围绕 provider-plugin、Kubernetes starter、sessions_yield 等能力做长期部署准备。
与此同时,第三方目录站 OpenClaw Directory 已上线,首页按 Deployers、Hosting、Plugins、Skills、AI Agent Teams 等类别组织工具,当前目录中收录工具数已达 43 个。
在评测层,PinchBench 已经开始作为 OpenClaw 生态中的一个重要 benchmark 出现。它以标准化 coding / agent 任务对不同模型进行横向比较。当前公开榜单中,Gemini 3 Flash Preview 领跑,而 MiniMax、Kimi 等中国模型也进入前列。
中国厂商的动作则更加直接。腾讯已推出面向 OpenClaw 生态的WorkBuddy和 SkillHub,后者提供面向中文场景与国内节点优化的技能市场能力;智谱也上线了面向 OpenClaw 场景的一键封装版本 AutoClaw(澳龙);小米此前已启动 miclaw小范围封测,把 system-level agent 的入口争夺推进到手机端。
⚙️ 核心解读
这一周 OpenClaw 真正值得关注的,不是“又更火了”,而是它开始同时具备了三种过去没有同时出现的属性。
第一,是生态化被验证。
上周我们提到,围绕 OpenClaw 很快会出现“卖铲子”的工具层与服务层。现在这种判断已经在被验证:目录站开始聚合工具,一键部署、浏览器沙箱、本地运行、托管服务等形态都在快速出现。OpenClaw 不再只是一个仓库,而是正在长出自己的分发结构。
第二,是标准化正在发生。
PinchBench 的出现意味着,OpenClaw 生态开始从“热度讨论”转向“可比较、可评测、可排序”。一旦 benchmark 出现,模型、部署方式和 agent 表现就不再只是社交媒体上的体验分享,而会变成更接近工程选型的问题。
第三,是大厂下场让它进入共识层。
腾讯的 WorkBuddy / SkillHub、智谱的 AutoClaw、小米的 miclaw,说明 OpenClaw 已经从海外开源现象,进入了中国大厂公开吸收、封装和本地化的阶段。
这里最重要的不是“谁复制了谁”,而是:当大厂开始下场时,OpenClaw 已经不再只是项目,而是在被承认成一种值得争夺的产品形态。
🧭 行业影响分析
简单说说
OpenClaw 正在从爆款项目走向生态标准化阶段。
目录站、benchmark、技能市场、一键封装等基础设施同时出现,验证了其生态化趋势。
中国大厂下场意味着 OpenClaw 已进入本地化入口与产品化争夺阶段。
展开说说
在上期的内容里我们判断过,OpenClaw 的爆发不只是一次开源项目出圈,而是 AI Agent 正从概念验证走向生态化、入口化和标准化的早期信号。本周的新变化,几乎都在朝同一个方向收敛。
评测榜单说明它开始被拿来做工程选型;
目录站与技能平台说明“工具层”和“卖铲子”的生意正在长出来;
大厂本地化封装则说明它已经进入更正式的产品与入口竞争。
这其实非常关键。因为一旦一个开源项目同时具备:
可比较的 benchmark
可聚合的工具分发层
可接入的大厂支持
可部署的本地化方案
它就不再只是“现象级项目”,而是开始具备一种 事实上的标准层 地位。
这也让我们上周提到的另一个判断变得更迫切: 当 Agent 生态真正进入规模化阶段,标准化与治理问题会比能力本身更快到来。腾讯 SkillHub 引发的技能镜像争议、OpenClaw 持续修补的安全漏洞、以及不同平台对本地/云端接入方式的重新设计,都说明这件事已经不只是“谁更酷”,而是“谁来定义生态规则”。
换句话说,OpenClaw 在过去一周的变化和迭代,或许正在清晰的印证一个划时代变化的事实:
它正在从“养龙虾”的流行文化,变成一套正在被市场、平台与大厂共同接住的基础设施。

继李飞飞的 World Labs 之后,Yann LeCun 也把“后 LLM 路线”做成了一家顶级配置的新公司。区别不在于谁先谁后,而在于这条路线正在从学术主张,走向资本与组织的正面竞争。
如果说本期前两条新闻分别对应的是 企业工作系统 与 开源 agent 生态的加速成形,那么 Yann LeCun 新公司的出现,则把视角拉到了更长远的一层:
当主流模型公司还在争夺入口、工作流和生态时,另一条更底层的替代路线,正在被资本连续高规格押注。
LeCun 创办的 AMI Labs(Advanced Machine Intelligence)近日宣布完成 10.3 亿美元种子轮融资,投前估值约 35 亿美元。
而就在几周前,李飞飞创办的 World Labs也刚刚宣布完成 10 亿美元融资,继续推进其“spatial intelligence / world models”方向。
这意味着,“世界模型”已经不再只是论文与演讲中的替代性愿景,而开始以连续的资本事件和公司组织形式,进入主流竞争视野。
🧩 相关重要信息
AMI Labs 由 Yann LeCun 创办并担任核心领导角色,公司 CEO 为前 Nabla 联合创始人Alexandre LeBrun,团队分布在巴黎、纽约、蒙特利尔和新加坡。
AMI 的核心目标是构建基于 JEPA(Joint Embedding Predictive Architecture) 的世界模型:不是逐像素生成未来,而是在抽象表示空间中做预测、记忆与推演。LeCun 一直认为,单纯依赖文本或像素预测的主流 generative AI 路线,并不适合真正走向现实世界理解、规划与自主智能。
在团队层面,谢赛宁(Saining Xie) 已加入 AMI 并担任首席科学官。其个人主页也已更新为 AMI Labs CSO。
AMI 官方和多家媒体都提到,其首个合作伙伴为医疗 AI 公司 Nabla,更长远的应用方向包括工业控制、机器人、可穿戴设备、医疗等高可靠性场景。
另一方面,World Labs 的路线则更聚焦于 spatial intelligence / 3D world generation,即让系统能够从文本或图像中生成和理解三维环境,并服务于创作、AR/VR、机器人等方向。其 2024 年已完成 2.3 亿美元融资并估值过十亿美元,2026 年 2 月又完成 10 亿美元新一轮融资。
⚙️ 核心解读
这条新闻真正重要的,不是“融资很多”,而是:
世界模型路线正在被连续、大规模地资本化,而且开始分化出不同技术方向。
如果说 World Labs 代表的是一种更偏 空间智能 / 3D 世界生成 的路线,那么 AMI Labs 则更明确地把自己放在主流 LLM 路线的对面:它强调真实世界理解、抽象预测、记忆、规划和可控性,而不是继续沿着语言模型规模化路径往前推。
所以,AMI Labs 的特别之处不在于它是“第一家”世界模型公司——这显然不成立,World Labs 已经是一个明确先例——而在于:
它把这条路线更直接、更鲜明地推到了“后 LLM 替代方案”的位置。
换句话说:
World Labs证明了:世界模型 / spatial intelligence 已经足以获得顶级资本支持
AMI Labs 则进一步说明:这条路线不只是应用补充,而可能被组织成对主流范式的正面对抗
这使得“世界模型”开始从一个模糊的概念,变成两种不同但都足够有分量的产业叙事。
🧭 行业影响分析
简单说说
世界模型路线已连续获得高规格资本押注,不再只是学术愿景。
World Labs 与 AMI Labs 说明,这条路线正在分化为“空间智能”与“后 LLM 世界理解”两类不同方向。
谢赛宁加入 AMI,也让这条路线不仅有思想旗帜,还有强研究与工程执行能力。
展开说说
过去,杨老师一直是主流大模型路线最有影响力的批评者之一。他反复强调,语言模型可以很强,但不等于真正理解世界;如果 AI 想进入机器人、工业控制、可穿戴设备、医疗等场景,单纯依赖 token 预测远远不够。
在AI圈,他似乎一直是一个争议和名声几乎一样洪亮的标杆人物,作为「世界模型」的先驱提出者,也同时作为反当下LLM路径的第一人,反对他的声音虽然时常诟病其“只会叫叫”但只要不是真蠢,也绝对从来不会轻视任何一次杨老师及其团队的工作发布。当杨老师离开meta的时候,又有不少质疑甚至嘲笑的声音来diss杨老师终究是只会搞搞科研,不适合企业。
但是现在,这种“反对主流路线”的思想,不再只是演讲和论文中的立场,而被装进了一家:
资金充足
团队完整
角色分工明确
有首批应用方向
有资本长期下注的公司里。
还有大神谢赛宁的加盟,似乎又传递出了硅谷科技圈的一种久违的浪漫,即资本依然可以支持在前沿科技上的理想主义尝试,但其背后,应该也未必能离开World Labs的先行尝试。
大家心里其中都清楚,但凡执着于世界模型路线的公司中有一家拿出真正落地的工作,那今天主流模型公司争夺的入口、工作流与生态,很可能就只是某个更大范式转移之前的阶段性最优解。
从这个角度看,AMI Labs 的意义不是“第一次”,而是:
世界模型路线,已经进入需要被认真当作产业竞争来看的阶段。

1.1 https://x.com/Kimi_Moonshot/status/2033378587878072424
1.2 https://arxiv.org/abs/2603.12686
1.3 https://arxiv.org/abs/2603.10165
2.1 https://github.com/aiming-lab/MetaClaw
2.2 https://github.com/HKUDS/CLI-Anything
2.3 https://huggingface.co/fishaudio/s2-pro
3.1.1 https://claude.com/blog/code-review
3.1.2 https://www.microsoft.com/en-us/microsoft-365/blog/2026/03/09/copilot-cowork-a-new-way-of-getting-work-done
3.2.1 https://github.com/openclaw/openclaw
3.2.2. https://pinchbench.com/
3.3 https://amilabs.xyz/



