Ridge回归实战:从理论到Python实现(附完整代码)
- 2026-06-29 03:15:01

社团活动日
2
0
2
6
Happy Time
在机器学习中,线性回归是最基础且应用广泛的模型之一。但当特征之间存在多重共线性或特征维度较高时,普通最小二乘法(OLS)的系数估计会变得不稳定,导致模型泛化能力下降。Ridge回归通过引入L2正则化,能够有效缓解这些问题。本文将带你从理论到实践,用Python实现Ridge回归,并解读每一步的代码逻辑。
案例数据获取:私信“anlidta”免费获取。
学术帮帮社团
导航

一、Ridge回归理论简介
普通线性回归的问题
普通线性回归的目标是最小化残差平方和:
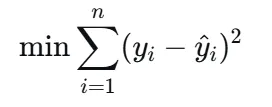
当特征之间存在高度相关性(多重共线性)时,系数估计的方差会变得很大,导致模型对训练数据过拟合,在新数据上表现不佳。
Ridge回归的改进
Ridge回归在损失函数中加入L2正则化项(即系数的平方和),惩罚过大的系数:
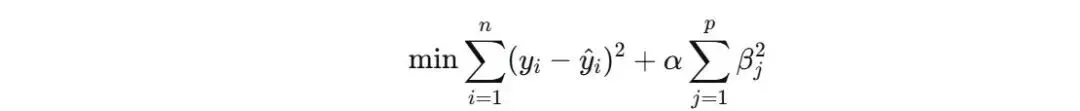
其中:
α 是正则化强度参数,控制惩罚力度。α=0 时退化为普通线性回归;α 越大,系数越趋近于0,模型越简单。
L2正则化会使系数收缩,但不会像L1正则化(Lasso)那样将系数压缩为0,因此Ridge通常保留所有特征。
通过引入正则化,Ridge能够在偏差和方差之间取得平衡,提高模型的泛化能力。

二、完整代码实现与解析
# 0 导库import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_split, cross_val_score, GridSearchCVfrom sklearn.linear_model import Ridgefrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_scoreimport warningswarnings.filterwarnings('ignore')# 设置中文字体和负号显示plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = False# 1. 数据加载和准备df = pd.read_stata(r'D:\360MoveData\Users\Desktop\anli.dta')print(f"原始数据: {df.shape[0]}行 × {df.shape[1]}列")print(f"数据前5行:\n", df.head())print(f"\n数据基本信息:")print(df.info())print(f"\n描述性统计:")print(df.describe())# 2. 定义研究变量dependent_var = 'y' # 因变量independent_vars = ['x', 'hhi', 'lev', 'liqui', 'invt', 'roe', 'lnSale', 'lnage']# 3. 数据预处理:检查缺失值并处理print("\n缺失值检查:")print(df[independent_vars + [dependent_var]].isnull().sum())# 删除包含缺失值的行(也可用填充,此处简单删除)df_clean = df[independent_vars + [dependent_var]].dropna()print(f"删除缺失值后数据形状: {df_clean.shape}")# 4. 准备特征矩阵X和目标向量yX = df_clean[independent_vars]y = df_clean[dependent_var]# 5. 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)print(f"\n训练集样本数: {X_train.shape[0]}, 测试集样本数: {X_test.shape[0]}")# 6. 特征标准化(Ridge对特征尺度敏感)scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# 7. 使用网格搜索选择最佳正则化参数alpha# 定义要搜索的alpha值范围alphas = np.logspace(-3, 3, 50) # 从0.001到1000,共50个值# 创建Ridge模型ridge = Ridge()# 使用交叉验证网格搜索param_grid = {'alpha': alphas}grid_search = GridSearchCV(ridge, param_grid, cv=5, scoring='r2', n_jobs=-1)grid_search.fit(X_train_scaled, y_train)# 输出最佳参数和对应分数print(f"\n最佳alpha值: {grid_search.best_params_['alpha']:.4f}")print(f"交叉验证最佳R²: {grid_search.best_score_:.4f}")# 使用最佳模型进行预测best_ridge = grid_search.best_estimator_y_pred = best_ridge.predict(X_test_scaled)# 8. 模型评估mse = mean_squared_error(y_test, y_pred)mae = mean_absolute_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)rmse = np.sqrt(mse)print("\n=== 测试集评估指标 ===")print(f"均方误差 (MSE): {mse:.4f}")print(f"均方根误差 (RMSE): {rmse:.4f}")print(f"平均绝对误差 (MAE): {mae:.4f}")print(f"决定系数 (R²): {r2:.4f}")# 9. 特征重要性(Ridge系数)coefficients = pd.Series(best_ridge.coef_, index=independent_vars)print("\n特征系数:")print(coefficients.sort_values(ascending=False))# 10. 可视化:预测值与真实值对比plt.figure(figsize=(8, 6))plt.scatter(y_test, y_pred, alpha=0.6)plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2)plt.xlabel('真实值')plt.ylabel('预测值')plt.title('Ridge回归:真实值 vs 预测值')plt.tight_layout()plt.show()

三、结果展示
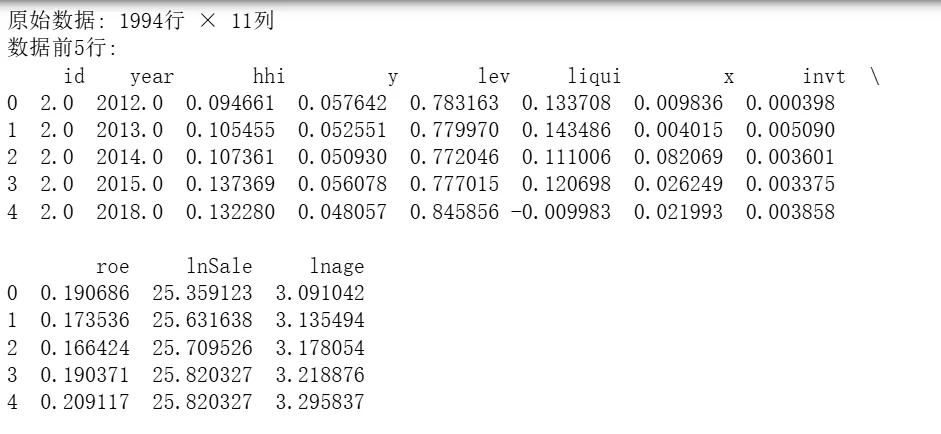

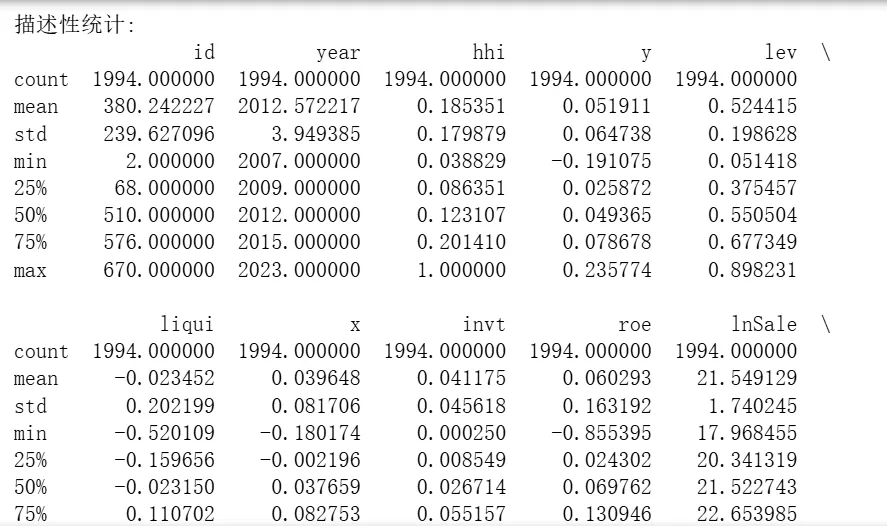


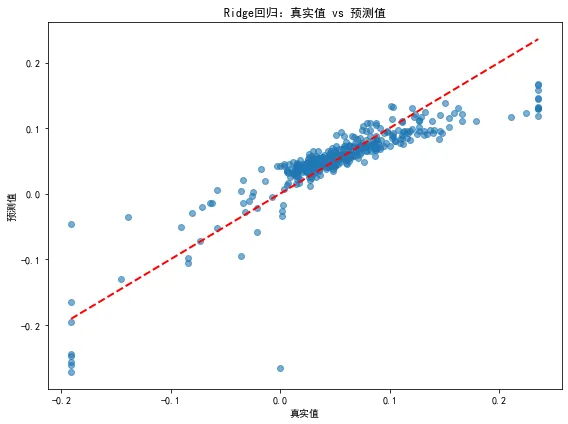

四、结束语
Ridge回归通过L2正则化有效处理多重共线性,防止过拟合。本文展示了完整的Python实现流程:数据预处理、标准化、网格搜索调参、模型评估与可视化。读者可根据自身数据调整变量和参数,灵活应用。
扩展思考
当特征非常多时,可尝试Lasso回归(L1正则化)进行特征选择。
结合L1和L2的Elastic Net往往表现更优。
可使用learning_curve绘制学习曲线,诊断模型偏差-方差问题。
希望这篇教程能帮助你掌握Ridge回归的实践方法,在数据分析项目中灵活运用!
欢迎关注我们!
系列教程回顾
学小帮No.18|机器学习——梯度提升回归树(GBRT)因果推断,让误差指引发现之路
学小帮No.17|机器学习因果推断4——基于Lasso的解决方案
学小帮No.16|机器学习因果推断3——支持向量机,用超平面看清因果边界
2026国自然提交前必看 | 全流程自查细节,一次通过不返工!
请在微信客户端打开

