Django项目接入Redis
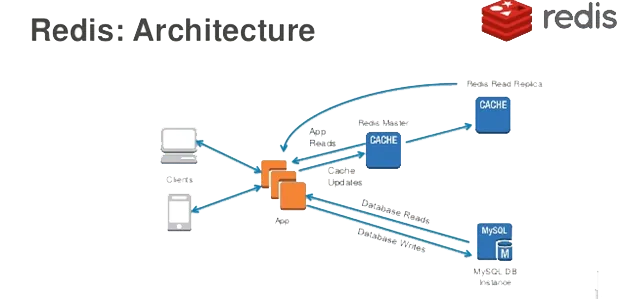
在之前的课程中,我们已介绍过 Redis 的安装与基本使用,此处不再赘述。若要在 Django 项目中集成 Redis,推荐使用第三方库 django-redis,该库依赖于底层的 redis 库,对 Redis 的各类操作进行了封装,便于在 Django 环境中调用。
首先,通过 pip 安装 django-redis:
pip install django-redis
接着,在 Django 的配置文件中更新缓存相关设置:
CACHES = {'default': {# 指定通过django-redis接入Redis服务'BACKEND': 'django_redis.cache.RedisCache',# Redis服务器的URL'LOCATION': ['redis://1.2.3.4:6379/0', ],# Redis中键的前缀(解决命名冲突)'KEY_PREFIX': 'vote',# 其他的配置选项'OPTIONS': {'CLIENT_CLASS': 'django_redis.client.DefaultClient',# 连接池(预置若干备用的Redis连接)参数'CONNECTION_POOL_KWARGS': {# 最大连接数'max_connections': 512, },# 连接Redis的用户口令'PASSWORD': 'foobared', } },}
完成上述配置后,Django 项目即可成功对接 Redis。接下来,我们将修改业务代码,为获取学科数据的接口添加缓存支持。
为视图提供缓存服务
声明式缓存
所谓声明式缓存,是指在不改动原有业务逻辑的前提下,借助 Python 装饰器为视图函数自动注入缓存能力。对于基于函数的视图(FBV),可按如下方式实现:
from django.views.decorators.cache import cache_page@api_view(('GET', ))@cache_page(timeout=86400, cache='default')defshow_subjects(request):"""获取学科数据""" queryset = Subject.objects.all() data = SubjectSerializer(queryset, many=True).datareturn Response({'code': 20000, 'subjects': data})
上述代码利用 Django 内置的 cache_page 装饰器,将视图函数的返回结果(即 HTTP 响应对象)缓存起来。虽然该装饰器最初设计用于缓存 HTML 页面,但对于返回 JSON 数据的 API 视图同样适用——本质上是缓存了序列化后的 JSON 内容。其中,timeout 参数指定缓存有效期(单位:秒),cache 参数则指明使用哪一组缓存配置(此处为 default,对应配置文件中定义的默认缓存)。缓存数据会以字节串形式存储于 Redis(Redis 的字符串类型支持字节数据),序列化与反序列化过程由 django-redis 自动处理,默认采用 pickle 方式。首次请求时,系统会查询数据库并将结果写入缓存;后续请求若缓存未过期,则直接返回缓存内容,不再访问数据库。可通过 Django Debug Toolbar 或数据库日志验证:首次调用会触发 SQL 查询,而后续调用则不会。对于基于类的视图(CBV),由于 cache_page 是函数装饰器,不能直接作用于类,需借助 method_decorator 将其应用到特定方法上:
from django.utils.decorators import method_decoratorfrom django.views.decorators.cache import cache_page@method_decorator(decorator=cache_page(timeout=86400, cache='default'), name='get')classSubjectView(ListAPIView):"""获取学科数据的视图类""" queryset = Subject.objects.all() serializer_class = SubjectSerializer
注意:method_decorator 是 Django 提供的桥梁,用于将函数装饰器适配到类方法上。
编程式缓存
与声明式缓存不同,编程式缓存要求开发者显式编写缓存读写逻辑。虽然代码量略增,但其灵活性更高,在实际项目中更为常见。以下示例移除了 cache_page 装饰器,转而通过 django-redis 提供的 get_redis_connection 函数直接操作 Redis:
defshow_subjects(request):"""获取学科数据""" redis_cli = get_redis_connection()# 先尝试从缓存中获取学科数据 data = redis_cli.get('vote:polls:subjects')if data:# 如果获取到学科数据就进行反序列化操作 data = json.loads(data)else:# 如果缓存中没有获取到学科数据就查询数据库 queryset = Subject.objects.all() data = SubjectSerializer(queryset, many=True).data# 将查到的学科数据序列化后放到缓存中 redis_cli.set('vote:polls:subjects', json.dumps(data), ex=86400)return Response({'code': 20000, 'subjects': data})
值得一提的是,Django 还提供了全局变量 cache和caches用于简化缓存操作:cache默认指向default缓存,而caches['xxx']可访问指定名称的缓存实例。通过cache.get()和cache.set()即可完成基本读写,但功能较为有限。此外,get_redis_connection返回的是原生 Redis 客户端,具备执行任意命令的能力(包括FLUSHDB、SHUTDOWN等高危操作)。因此,在生产环境中,建议对django-redis 进一步封装,仅暴露项目所需的缓存接口,以降低误操作风险。这种封装还能为实现“Read Through”和“Write Through”等高级缓存模式奠定基础(下文将详细介绍)。
缓存相关问题
缓存数据的更新
使用缓存时,必须解决的核心问题是:当底层数据发生变化,如何同步更新缓存? 常见策略主要有以下三种:
- 1. Cache Aside Pattern(旁路缓存模式)
- 2. Read/Write Through Pattern(读写穿透模式)
- 3. Write Behind Caching Pattern(写回缓存模式)
第一种是最常用的方式:更新数据时,先修改数据库,再删除对应的缓存项。注意,不能先更新缓存再更新数据库,也不宜先删缓存再改数据库——在高并发场景下,这两种顺序均可能导致脏读。尽管“先更新 DB 再删缓存”在极端情况下仍存在一致性窗口,但其出错概率极低,已被大量项目采用。该模式的缺点是业务代码需同时维护数据库与缓存两套逻辑,较为繁琐。
第二种则将缓存与数据库的交互逻辑封装在统一的数据访问层中。其中:
- • Read Through:当缓存失效时,由缓存层自动从数据库加载数据并填充缓存,对上层透明;
- • Write Through:写操作时,若缓存命中则同时更新缓存与数据库(同步);若未命中,则仅更新数据库。
若对 django-redis 进行二次封装,便可实现上述模式,虽初期投入较大,但长期来看可大幅提升系统健壮性与可维护性。
第三种模式在写入时仅更新缓存,由后台异步批量刷入数据库。这种方式极大提升了写性能,但牺牲了强一致性,适用于对实时性要求不高的场景。其实现复杂度较高,需追踪变更记录并调度持久化任务。
缓存穿透
缓存本用于减轻数据库压力,但若恶意用户频繁请求缓存中不存在的数据(即“空查”),所有请求将直接打到数据库,造成类似 DDoS 的效果,称为缓存穿透。应对方案有两种:
- • 缓存空值:当查询结果为空时,仍将空结果(如
null)写入缓存,并设置较短的过期时间(如 1~5 分钟),防止重复穿透; - • 布隆过滤器(Bloom Filter):在缓存前增加一层过滤,快速判断某 key 是否可能存在,若不存在则直接拒绝请求,避免无效查询。
缓存击穿
当某个热点 key 在缓存中过期的瞬间,恰逢大量并发请求同时到达,这些请求均无法命中缓存,进而全部穿透至数据库,可能瞬间压垮后端,此现象称为缓存击穿。常见解决方案是引入互斥锁(Mutex)。例如,在 Redis 中使用 SETNX 命令尝试获取锁:只有成功获取锁的请求才允许查询数据库并回填缓存,其余请求则短暂休眠后重试读取缓存。伪代码如下:
data = redis_cli.get(key)whilenot data:if redis_cli.setnx('mutex', 'x'): redis.expire('mutex', timeout) data = db.query(...) redis.set(key, data) redis.delete('mutex')else: time.sleep(0.1) data = redis_cli.get(key)
该机制可有效避免同一时刻多个线程同时重建缓存。
缓存雪崩
若大量缓存 key 被设置为相同的过期时间,它们可能在同一时刻集体失效,导致所有请求瞬间涌向数据库,引发系统崩溃,即缓存雪崩。缓解策略包括:
- • 随机过期时间:在基础过期时间上叠加一个随机偏移(如 ±5 分钟),使 key 失效时间分散;
- • 多级缓存架构:部署多层缓存(如本地缓存 + Redis),各级缓存采用不同过期策略,即使某一级失效,其他层级仍可提供兜底服务,避免全量请求直达数据库。