Conda环境、变量类型、字符串操作、条件循环,一文搞定第2章 Python 编程基础速成
本章目标:搭建 Python 开发环境,掌握核心语法、数据结构、函数与类、第三方库使用,以及 Jupyter Notebook 的操作技巧。本章面向零基础读者,已有 Python 基础的读者可跳过直接进入第 3 章。2.1 Python 环境安装与配置
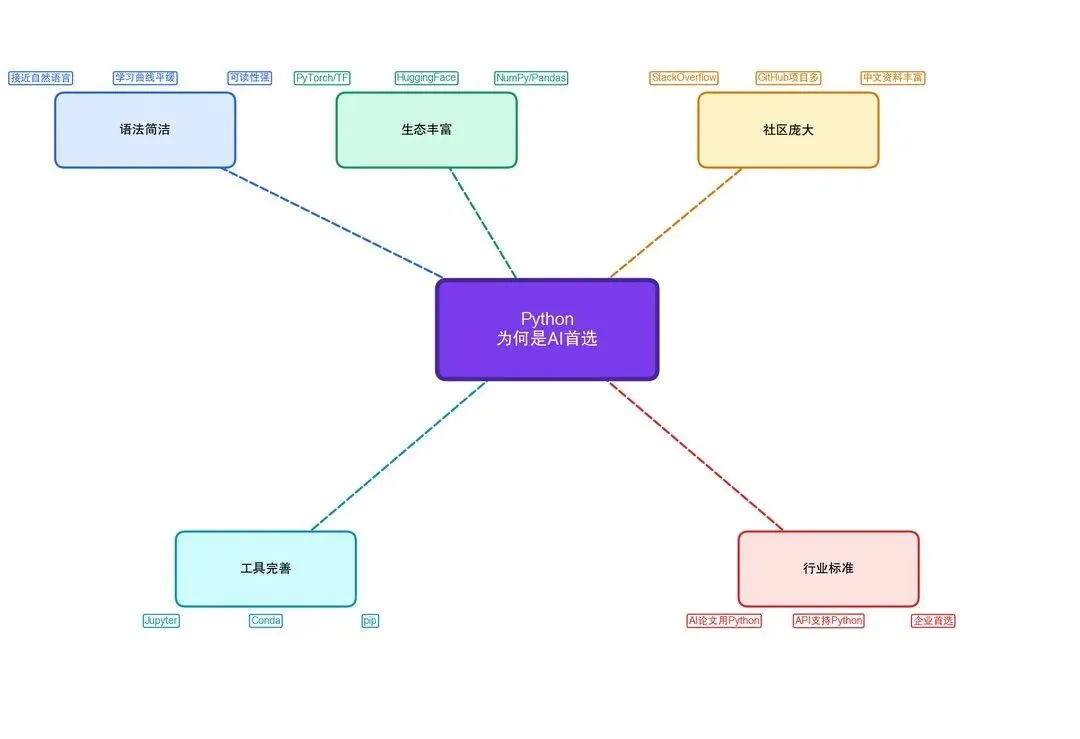
2.1.1 为什么选择 Python
在 AI 开发领域,Python 占据了绝对主导地位。原因如下:
图2-1
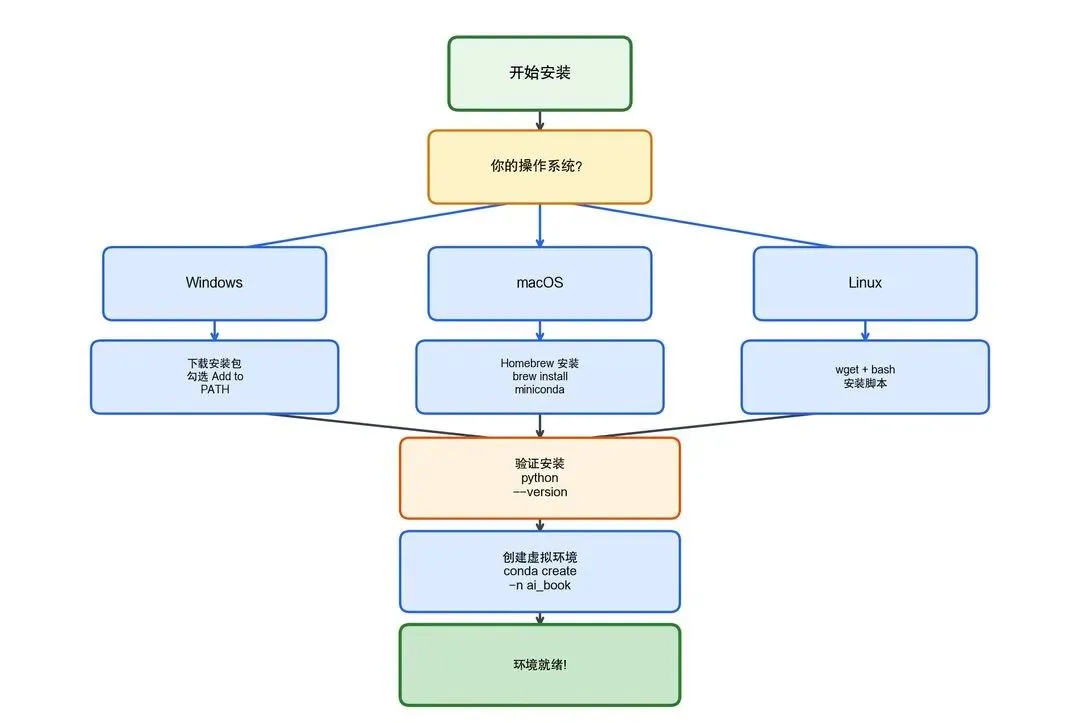
2.1.2 安装流程
推荐使用 Miniconda(轻量版 Anaconda),它自带 Python 和包管理工具 conda:
图2-2
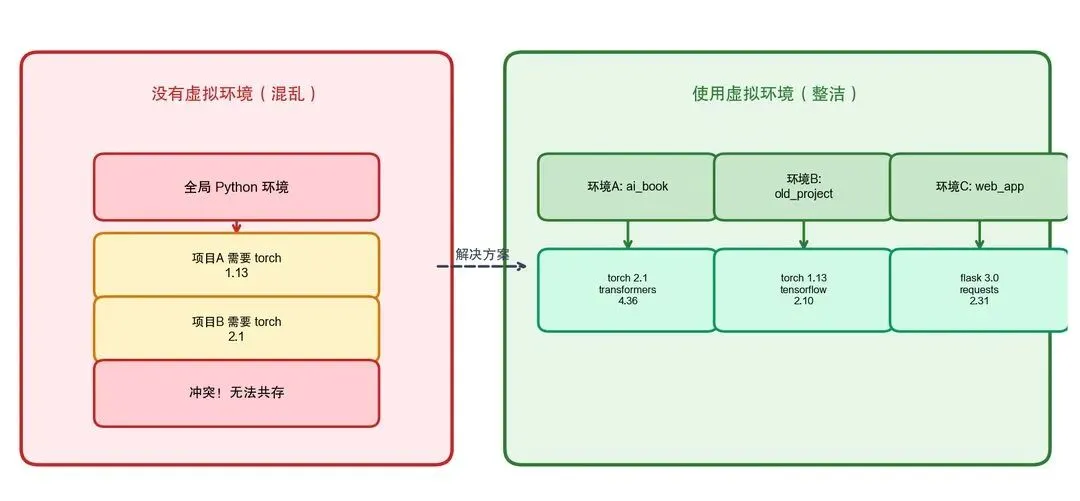
2.1.3 虚拟环境:为什么要隔离
虚拟环境就像给每个项目分配一个独立的"工具箱",避免不同项目之间的依赖冲突:
图2-3
常用命令速查:
# 第2章/bash
# 创建环境
conda create -n ai_book python=3.11
# 激活环境
conda activate ai_book
# 退出环境
conda deactivate
# 查看所有环境
conda env list
# 删除环境
conda env remove -n ai_book
# 安装包
pip install numpy pandas
conda install pytorch torchvision -c pytorch
2.2 Python 基础语法快速入门
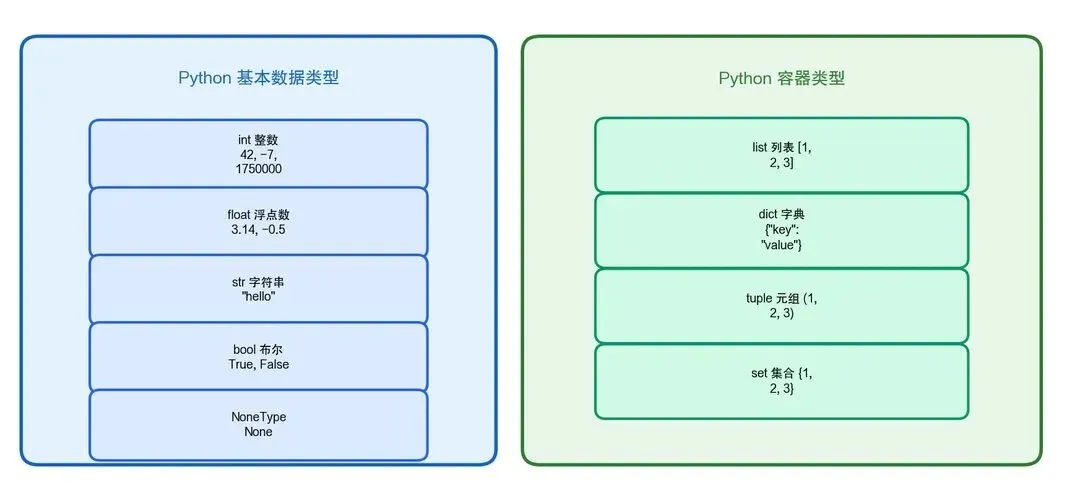
2.2.1 变量与数据类型
Python 是动态类型语言,变量不需要声明类型:
# 第2章/python
# 基本数据类型
name = "AI大模型" # str(字符串)
version = 4.0 # float(浮点数)
parameters = 175000000000 # int(整数)
is_open_source = True # bool(布尔值)
nothing = None # NoneType(空值)
# 查看类型
print(type(name)) # <class 'str'>
print(type(parameters)) # <class 'int'>
图2-4
2.2.2 字符串操作(AI 开发常用)
在大模型开发中,字符串操作是最频繁的操作之一(构造 Prompt、解析回复等):
# 第2章/python
# 字符串基本操作
text = "Hello, AI World!"
print(text.lower()) # hello, ai world!
print(text.upper()) # HELLO, AI WORLD!
print(text.split(", ")) # ['Hello', 'AI World!']
print(text.replace("AI", "Large Model")) # Hello, Large Model World!
print(len(text)) # 16
# f-string 格式化(最推荐的方式)
model_name = "GPT-4"
score = 95.5
prompt = f"请用 {model_name} 回答,置信度 {score:.1f}%"
print(prompt) # 请用 GPT-4 回答,置信度 95.5%
# 多行字符串(常用于构造 Prompt)
system_prompt = """你是一个专业的AI助手。
请遵循以下规则:
1. 回答要准确
2. 语言要简洁
3. 必要时给出示例"""
2.2.3 条件判断与循环
# 第2章/python
# if-elif-else 条件判断
temperature = 0.7
if temperature < 0.3:
style = "严谨保守"
elif temperature < 0.8:
style = "平衡适中"
else:
style = "创意随机"
print(f"temperature={temperature}, 风格: {style}")
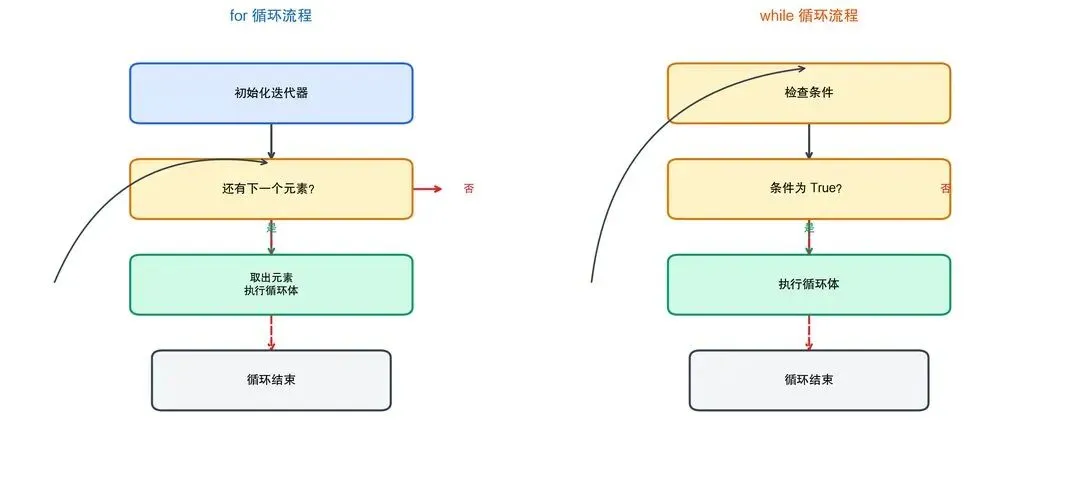
# for 循环
models = ["GPT-4", "Claude", "文心一言", "通义千问"]
for i, model in enumerate(models):
print(f" {i+1}. {model}")
# while 循环
count = 0
while count < 3:
print(f"第 {count+1} 次重试...")
count += 1
# 列表推导式(Pythonic 的写法)
scores = [85, 92, 78, 96, 88]
high_scores = [s for s in scores if s >= 90]
print(high_scores) # [92, 96]
图2-5
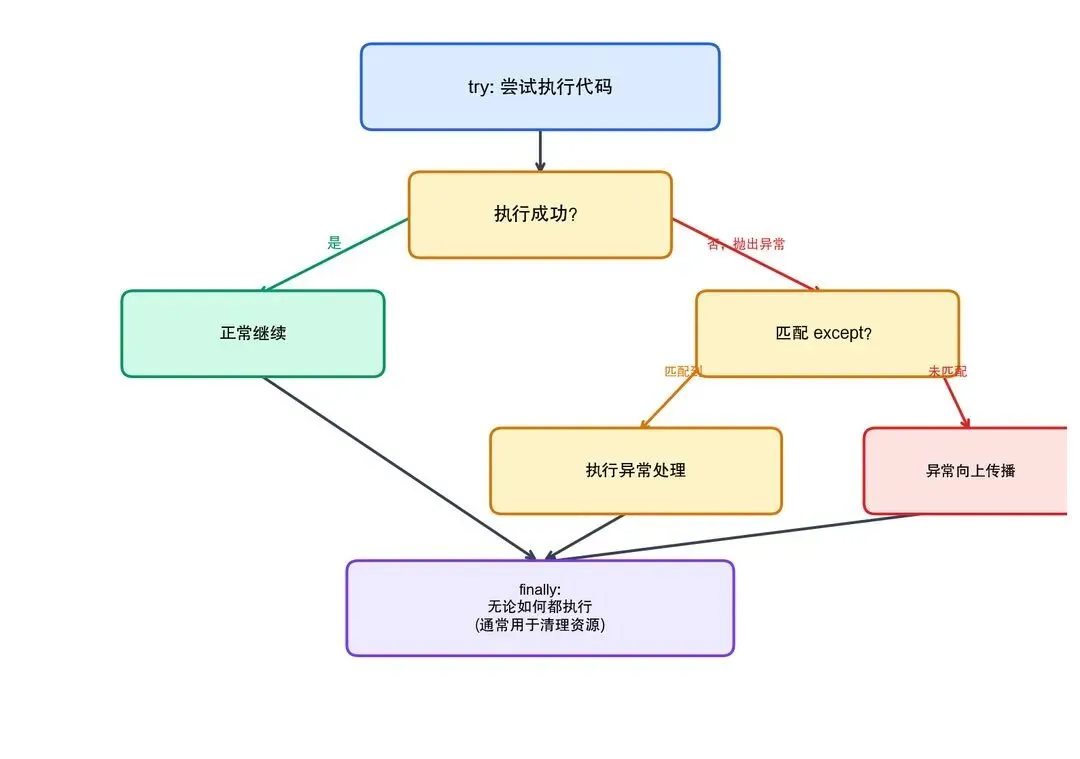
2.2.4 异常处理
在调用 API 时,异常处理至关重要(网络超时、API 限流等都很常见):
# 第2章/python
import time
def safe_api_call(prompt, max_retries=3):
"""带重试机制的 API 调用"""
for attempt in range(max_retries):
try:
# 模拟 API 调用
result = call_model_api(prompt)
return result
except ConnectionError:
print(f"网络错误,第 {attempt+1} 次重试...")
time.sleep(2 ** attempt) # 指数退避
except TimeoutError:
print("请求超时,正在重试...")
except Exception as e:
print(f"未知错误: {e}")
raise # 未知错误直接抛出
raise Exception(f"重试 {max_retries} 次后仍然失败")
图2-6
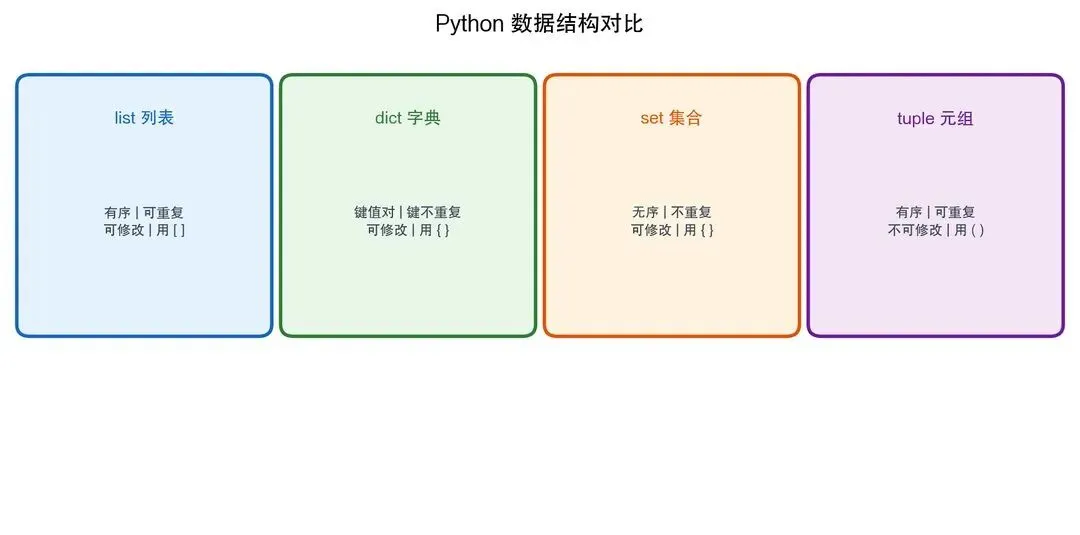
2.3 常用数据结构:列表、字典、集合
2.3.1 数据结构对比一览
图2-7
表2-1
2.3.2 列表(List)——最常用的数据结构
# 第2章/python
# 创建列表
models = ["GPT-4", "Claude", "LLaMA", "Qwen"]
scores = [92.5, 91.0, 85.5, 88.0]
# 基本操作
models.append("DeepSeek") # 添加元素
models.insert(0, "Gemini") # 在指定位置插入
removed = models.pop() # 移除并返回最后一个
models.sort() # 排序
# 切片操作(非常重要!)
first_three = models[:3] # 前3个
last_two = models[-2:] # 后2个
every_other = models[::2] # 每隔一个取
# 列表推导式 —— Python 最优雅的特性之一
# 场景:批量构造 Prompt
questions = ["什么是AI", "什么是大模型", "什么是Transformer"]
prompts = [f"请用100字回答:{q}" for q in questions]
# 带条件的列表推导式
# 场景:筛选高分模型
model_scores = [("GPT-4", 92.5), ("LLaMA", 85.5), ("Claude", 91.0)]
top_models = [name for name, score in model_scores if score >= 90]
# ['GPT-4', 'Claude']
2.3.3 字典(Dict)——AI 开发的核心数据结构
字典在 AI 开发中无处不在:API 请求参数、配置文件、JSON 数据解析都离不开它。
# 第2章/python
# 创建字典
model_config = {
"model": "deepseek-chat",
"temperature": 0.7,
"max_tokens": 1000,
"top_p": 0.9,
"messages": [
{"role": "system", "content": "你是AI助手"},
{"role": "user", "content": "你好"}
]
}
# 访问
print(model_config["model"]) # deepseek-chat
print(model_config.get("stream", False)) # False(键不存在时返回默认值)
# 修改
model_config["temperature"] = 0.5
model_config["stream"] = True # 新增键值对
# 遍历
for key, value in model_config.items():
print(f" {key}: {value}")
# 字典推导式
scores = {"GPT-4": 92, "Claude": 91, "LLaMA": 85}
normalized = {k: v / 100 for k, v in scores.items()}
# {'GPT-4': 0.92, 'Claude': 0.91, 'LLaMA': 0.85}
# 嵌套字典(JSON 风格,API 开发中极为常见)
api_response = {
"id": "chatcmpl-abc123",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "你好!有什么可以帮你的?"
}
}
],
"usage": {
"prompt_tokens": 10,
"completion_tokens": 15,
"total_tokens": 25
}
}
# 深层访问
answer = api_response["choices"][0]["message"]["content"]
total_cost = api_response["usage"]["total_tokens"]
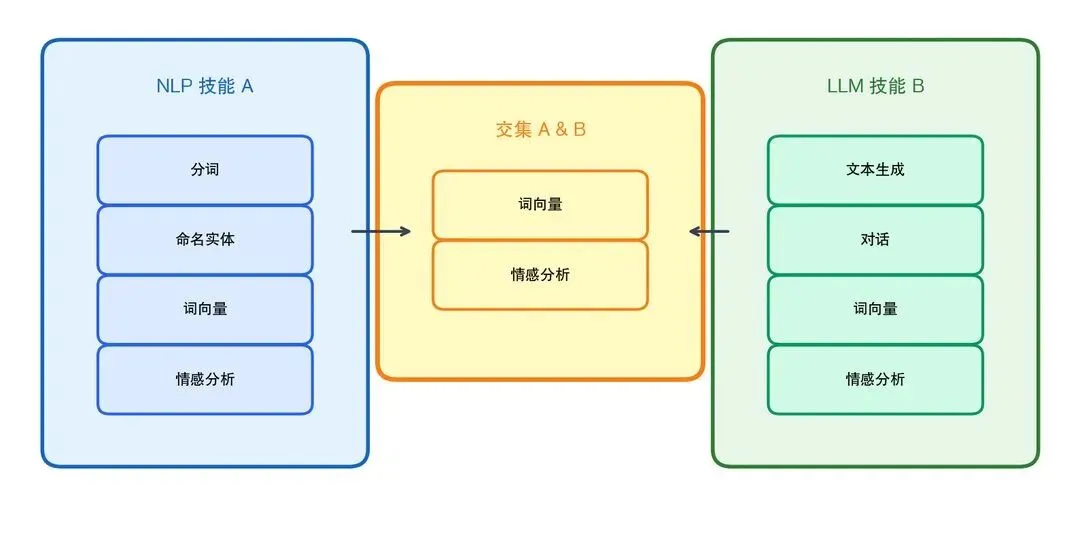
2.3.4 集合(Set)——去重利器
# 第2章/python
# 去重
all_tags = ["AI", "NLP", "AI", "CV", "NLP", "LLM"]
unique_tags = set(all_tags) # {'AI', 'NLP', 'CV', 'LLM'}
# 集合运算
nlp_skills = {"分词", "词向量", "命名实体", "情感分析"}
llm_skills = {"词向量", "文本生成", "对话", "情感分析"}
common = nlp_skills & llm_skills # 交集: {'词向量', '情感分析'}
all_skills = nlp_skills | llm_skills # 并集
only_nlp = nlp_skills - llm_skills # 差集: {'分词', '命名实体'}
图2-8
本文摘自《AI大模型实战:从零基础到项目落地》
觉得有帮助?点个 「在看」 支持一下吧