Python中文分词神器jieba|精准拆分文本,数据分析必备!
- 2026-06-27 15:18:42
做过中文文本处理、词云生成、数据分析的小伙伴,肯定都遇到过这个难题📝:中文句子是连续字符,没有空格分隔,计算机根本没法识别单个词汇,之前分享的wordcloud词云库,也必须先分词才能做出干净效果!
这时候,Python界公认的中文分词神器——jieba库就派上用场了!轻量、高效、精准,零基础也能快速上手,不管是做词云、文本挖掘、关键词提取,还是舆情分析,都是绕不开的核心工具✨

🤔 先搞懂:jieba库到底是什么?核心作用是啥?
jieba是Python中最流行、使用率最高的开源中文分词第三方库,专门解决中文文本“断词”难题——把一整段连续的中文句子、文章,精准拆分成一个个有意义的词语,让计算机能读懂中文文本。
它基于词典分词+统计算法,兼顾分词速度和准确率,还支持自定义词汇、关键词提取、词性标注等进阶功能,完全适配日常文本处理需求。
✅ 必用场景全覆盖
☁️ 词云生成:配合wordcloud使用,解决中文乱码、整段显示问题;
📊 文本分析:文章关键词提取、评论情感分析、词频统计;
🔍 数据挖掘:舆情监控、文案清洗、搜索引擎优化;
✂️ 文本预处理:NLP入门、机器学习文本数据处理;
🎯 日常办公:文案拆分、内容汇总、关键词标注。
简单说:只要处理中文文本,jieba就是第一步!没有它,后续的词云、数据分析都没法顺利开展~
📥 第一步:极速安装,一行命令搞定
jieba库安装超简单,无复杂依赖,命令行直接运行pip指令,全程无坑,安装完成导入不报错就成功:
# 常规安装,直接执行pip install jieba# 网速慢/安装失败,用国内镜像源加速pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
💡 小提醒:不管是Windows、Mac还是Linux系统,安装方式完全一致,闭眼操作即可~
⚙️ 核心用法:3种分词模式,适配所有场景
jieba库最核心的功能,就是提供了3种分词模式,应对不同的使用场景,精准度、速度各有侧重,按需选择即可,代码逐行注释,复制就能运行!
📌 1. 精确模式(最常用!默认推荐)
最常用的默认模式,把句子精准拆分成完整词汇,不会产生冗余词汇,适合日常文本处理、词云生成、数据分析,兼顾精准和简洁。
import jieba# 待分词的中文文本text = "Python零基础学习jieba中文分词,配合词云库做可视化超简单"# 精确模式分词,返回列表result = jieba.lcut(text)word_result = " ".join(result)print("精确模式分词结果:")print(result)print("拼接后文本:", word_result)
✅ 输出效果:['Python', '零基础', '学习', 'jieba', '中文', '分词', ',', '配合', '词云', '库', '做', '可视化', '超', '简单']
📌 2. 全模式
把句子中所有能组成词语的内容全部拆分,速度最快,但会产生冗余重复词汇,适合词频扫描,不适合精准分析。
# 全模式分词,cut_all=True开启result_all = jieba.lcut(text, cut_all=True)print("全模式分词结果:")print(result_all)
📌 3. 搜索引擎模式
在精确模式基础上,对长词汇再次拆分,适合搜索引擎、关键词检索场景,拆分更细致,适配检索需求。
# 搜索引擎模式分词result_search = jieba.lcut_for_search(text)print("搜索引擎模式分词结果:")print(result_search)

💡 总结:日常做词云、文本分析,直接用默认精确模式就够了,另外两种模式特殊场景再用~
🎨 进阶花哨用法:解锁jieba高阶玩法
1. 📝 自定义词典:解决特殊词汇分词错误
jieba自带词典有限,遇到人名、品牌名、专业术语、网络热词(如“搭子”“特种兵式旅游”),容易拆分错误,这时候自定义专属词典,想怎么分就怎么分!
# 步骤1:新建txt文件(如user_dict.txt),每行写一个词汇# 示例user_dict.txt内容:# 特种兵式旅游# 搭子# AI大模型# 步骤2:加载自定义词典jieba.load_userdict("user_dict.txt")# 重新分词,特殊词汇会被完整识别text2 = "特种兵式旅游超火,年轻人都爱找搭子"result = jieba.lcut(text2)print(result)# 输出:['特种兵式旅游', '超', '火', ',', '年轻人', '都', '爱', '找', '搭子']

2. 🚫 动态调整词汇:添加/删除词汇
不用新建词典文件,直接在代码里临时添加、删除词汇,适合临时调整,快速便捷:
# 动态添加词汇jieba.add_word("AI大模型")jieba.add_word("职场干货")# 动态删除词汇(强制不拆分)jieba.del_word("数据")# 测试分词text3 = "AI大模型职场干货,数据分析超实用"result3 = jieba.lcut(text3)print(result3)
✅ 输出效果:['AI大模型', '职场干货', ',', '数据分析', '超', '实用']
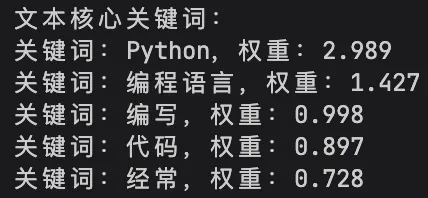
3. 🔑 关键词提取:自动抓取文本核心
不用手动统计,jieba自带关键词提取功能,自动找出文本中最重要的核心词汇,还能标注权重,适合文章摘要、舆情分析:
# 导入关键词提取模块from jieba import analyse# 待分析文本text4 = "我经常使用Python编写代码,Python是我最喜欢的编程语言!"# 提取top5关键词,withWeight=True显示权重keywords = analyse.extract_tags(text4, topK=5, withWeight=True)print("文本核心关键词:")for word, weight in keywords:print(f"关键词:{word},权重:{weight:.3f}")
4. 🏷️ 词性标注:标记词语类型
给每个词汇标注词性(名词、动词、形容词等),方便精细化文本处理,适合NLP入门学习:
# 导入词性标注模块import jieba.posseg as pseg# 词性标注result_pos = pseg.lcut("我爱学习Python编程")print("词性标注结果:")for word, flag in result_pos:print(f"{word}:{flag}")# 标注说明:n-名词,v-动词,eng-英文单词,a-形容词

📋 常用函数速查(收藏备用)
jieba核心函数速记表
- jieba.lcut(text):精确模式分词,返回列表(最常用)
- jieba.lcut(text, cut_all=True):全模式分词
- jieba.lcut_for_search(text):搜索引擎模式分词
- jieba.load_userdict(字典路径):加载自定义词典
- jieba.add_word(词汇):动态添加词汇
- jieba.del_word(词汇):动态删除词汇
- jieba.analyse.extract_tags():关键词提取
- jieba.posseg.lcut():词性标注

