很多 Python 开发者第一次遇到乱码问题时,往往会陷入“编码地狱”:UTF-8、GBK、ASCII 反复切换,却始终搞不清本质。
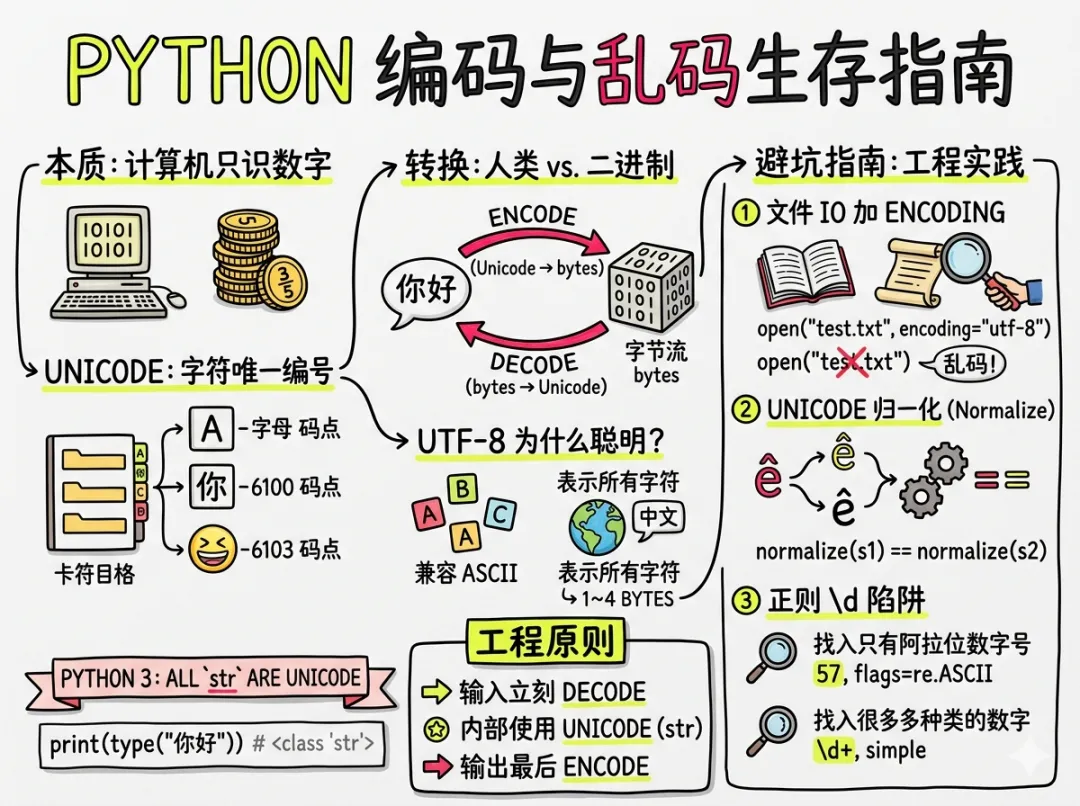
其实,这一切的核心只有一句话:计算机处理文本,本质上是在处理数字。
Unicode 的出现,就是为了给世界上每一个字符分配一个唯一的编号(称为“码点”)。比如字母 A、汉字“你”、甚至一个 emoji,都对应一个唯一的整数。
在 Python 3 里,这件事已经被彻底简化了。所有的 str,本质上就是一串 Unicode 字符序列,而不是字节。
s = "你好 Python"
print(type(s)) # <class 'str'>
但问题来了:计算机最终存储和传输的,永远是 字节(bytes)。
这就引出了编码(encode)和解码(decode)。
你可以把这个过程理解为两种世界的转换:
text = "你好"
data = text.encode("utf-8") # Unicode -> bytes
print(data)
text2 = data.decode("utf-8") # bytes -> Unicode
print(text2)
这一步,是所有乱码问题的根源。
再往深一点理解,你会发现 UTF-8 之所以成为主流,是因为它“聪明”。
它对 ASCII 完全兼容,同时又可以用 1~4 个字节表示任意 Unicode 字符。([Python documentation][1])
这意味着:英文不会变大,中文也能表示,而且跨平台稳定。
这也是为什么 Python 默认使用 UTF-8。
很多人写代码时忽略了一件很关键的事情:文件 IO 是编码问题的高发区。
最常见的错误就是:
with open("test.txt") as f:
content = f.read()
这段代码在不同系统上,可能会直接报错或者乱码。
更严谨的写法是:
with open("test.txt", encoding="utf-8") as f:
content = f.read()
原因很简单:文件里是字节,你必须告诉 Python 用什么方式解码。([Python documentation][2])
再说一个更隐蔽的问题:字符串比较。
有些字符,看起来一样,但实际上并不一样。
s1 = "ê"
s2 = "e\u0302"
print(s1 == s2) # False
这是因为 Unicode 允许“组合字符”。同一个视觉字符,可能由多个码点组成。
解决方案是:归一化(normalize)
import unicodedata
def normalize(s):
return unicodedata.normalize("NFC", s)
print(normalize(s1) == normalize(s2)) # True
这在做搜索、比较、去重时非常关键。([Python documentation][1])
还有一个容易被忽视的点:正则表达式在 Unicode 下的行为是不同的。
import re
s = "数字 ٥٧ 和 57"
print(re.findall(r"\d+", s))
你可能以为只会匹配 57,但实际上还会匹配阿拉伯数字。
因为在 Unicode 模式下,\d 表示“所有数字字符”,而不是 [0-9]。([Python documentation][1])
如果你只想匹配 ASCII,需要显式指定:
re.findall(r"\d+", s, flags=re.ASCII)
最后,把整件事收敛成一个工程实践原则,你以后基本不会再乱码:
第一,程序内部一律使用 Unicode(str)
第二,所有输入立刻 decode
第三,所有输出最后 encode
这也是很多高级开发者常说的一句话:
尽早解码,尽晚编码
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
