Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据
- 2026-07-03 16:58:58
全文链接:https://tecdat.cn/?p=45304原文出处:拓端数据部落公众号
关于分析师
在此对Xiangyu Tian对本文所作的贡献表示诚挚感谢,他在兰州大学完成了应用统计专业的研究生学位,专注故障诊断与工业大数据挖掘领域。擅长Python进行统计建模与机器学习,拥有从计量实证到工业大数据挖掘(故障诊断)的丰富项目经验。
Xiangyu Tian曾参与多个工业设备智能诊断项目,包括高铁轴承、风电齿轮箱等关键部件的故障预测与健康管理,积累了从数据采集、特征工程到模型部署的全栈经验。最近的工作包括为某轨道交通企业设计基于迁移学习的轴承故障诊断系统,有效解决了实际运营中故障样本稀缺的难题。

想象这样一个场景:一列时速350公里的复兴号高铁正载着上千名旅客穿越华北平原,它的每一个轮对轴承都在以每秒近30转的速度高速旋转,承受着数吨的载荷(点击文末“阅读原文”获取完整智能体、代码、数据、文档)。
任何一颗轴承的微小损伤,如果不能被及时察觉,都可能像滚雪球一样演变成严重事故。这不仅是工程技术问题,更是一个典型的数据科学挑战——我们拥有海量的实验室台架数据(源域),却极度缺乏真实运行中的故障数据(目标域)。如何将实验室里的“知识”有效迁移到实际列车上,正是本文要讲述的故事。
本文改编自为客户完成的咨询项目,旨在通过多尺度加权GOPAE(全局序模式注意力熵)与迁移学习技术,解决高速列车轴承故障诊断中“数据丰富但场景不足”的痛点。我们构建了一套从数据筛选、特征提取、源域建模到跨域迁移诊断的完整解决方案,并特别关注模型的可解释性,让每一个诊断结果都能追溯到物理机理。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解、行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路。
1 背景与问题
高速列车已成为中国客运的主流方式,轴承作为走行部的关键旋转部件,其安全状态直接关系行车安全。实际运营中,轴承故障数据极其稀缺,而实验室台架数据丰富但工况不同。如何利用台架数据(源域)辅助诊断实际列车轴承(目标域),是工业智能诊断的核心难题。
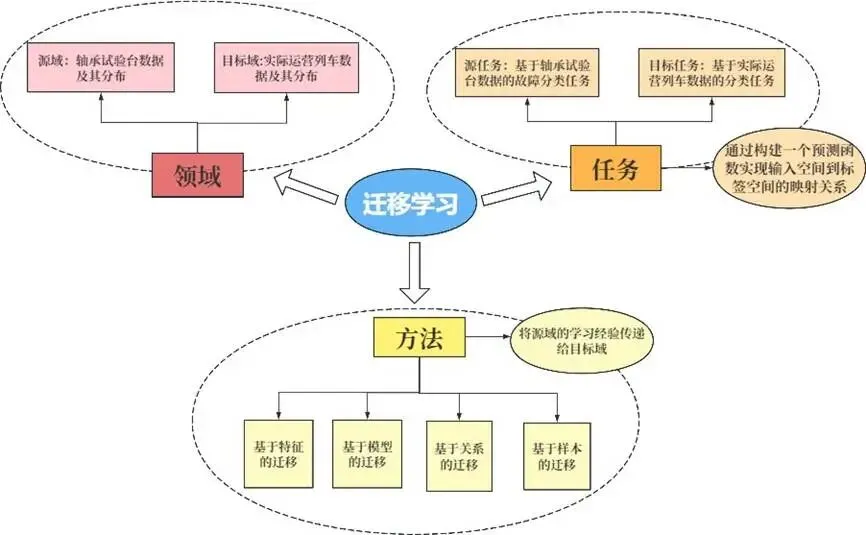
图:迁移学习分析图
2 数据筛选与特征提取
2.1 总体思路
整个建模过程遵循“数据分析与特征提取 → 源域模型构建 → 跨域迁移诊断 → 模型可解释性分析”的逻辑链条,思路流程如图:

图:问题总体思路流程图
2.2 数据筛选策略
我们基于故障机理,从161个源域文件中筛选出12个代表性文件,涵盖正常(N)、外圈故障(OR)、内圈故障(IR)、滚动体故障(B)四种状态,优先选择驱动端(DE)数据,并重采样至32kHz统一频率。
筛选结果统计:
下图展示了筛选后的数据分布:
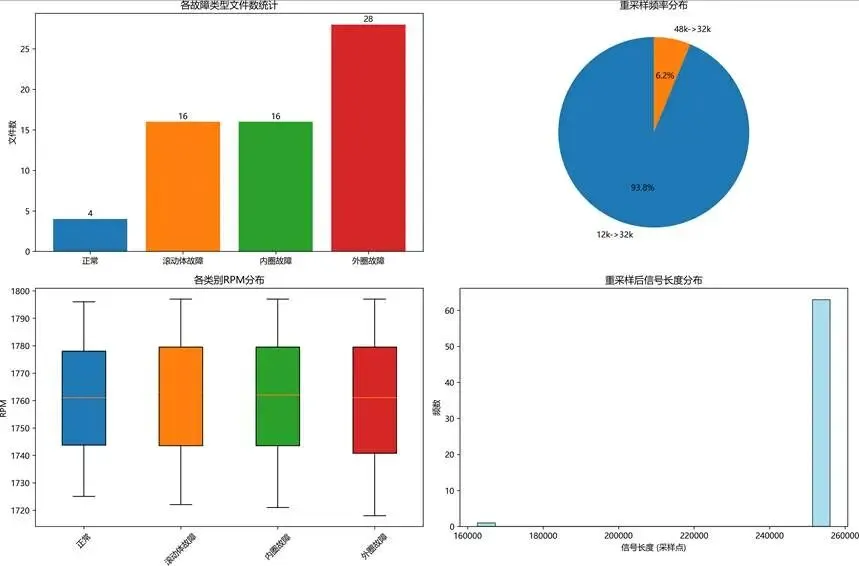
图:源域数据筛选与重采样统计分析
相关文章

DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
数据筛选与预处理详细流程如图:
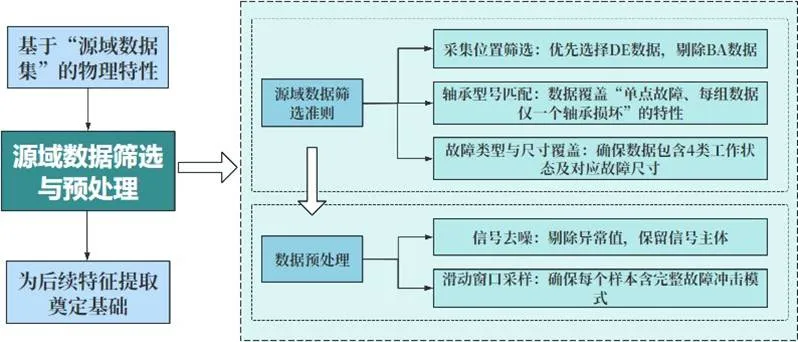
图:源域数据筛选与预处理
2.3 特征提取方法
我们构建了“时域-频域-动态复杂性”三维特征体系:
- 时域特征
:均值、标准差、RMS、峰值、峭度系数、峰度、偏度、形状因子等,共9维。 - 频域特征
:谱心、谱方差、低频比(<2kHz)、中频比(2-8kHz)、高频比(>8kHz),经转频归一化,共5维。 - 动态特征
:多尺度加权GOPAE(全局序模式注意力熵),捕捉故障冲击的周期性规律,共5维(尺度1~5),后加权融合为1维。
GOPAE的核心思想是将信号转换为序模式,计算每种模式出现间隔的熵,熵值低表示信号规律性强(如故障冲击),熵值高表示随机性强(如正常状态)。
GOPAE模型分析如图:
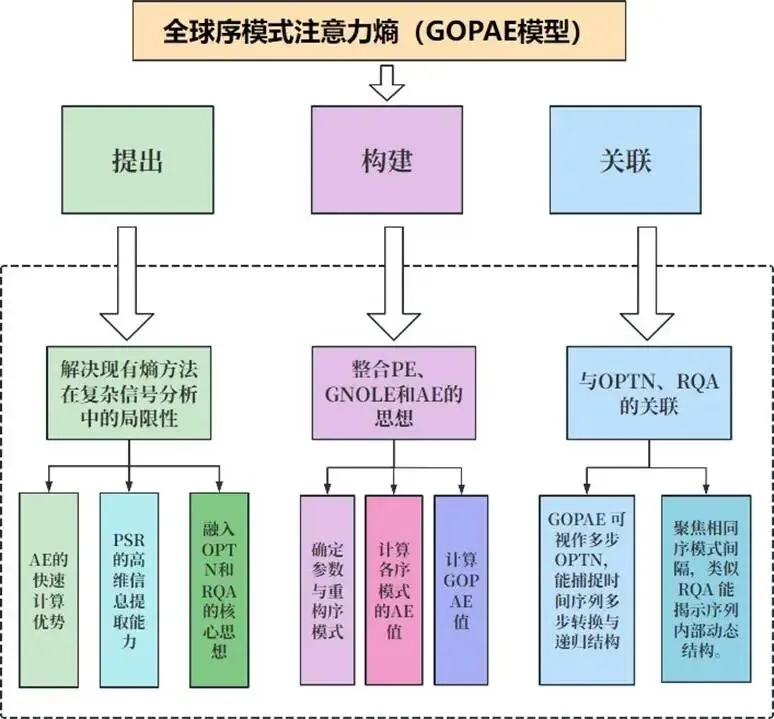
图:GOPAE模型分析图
多尺度加权GOPAE模型的构建流程:

图:多尺度加权GOPAE模型分析图
GOPAE核心函数实现细节:
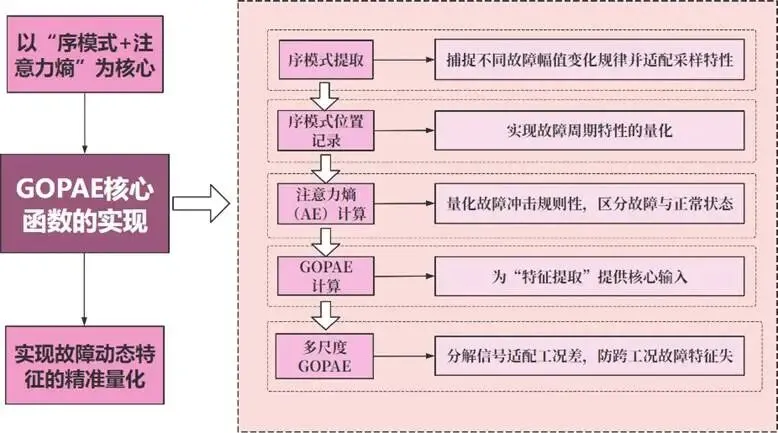
图:GOPAE核心函数实现图
多尺度权重计算与特征融合过程:
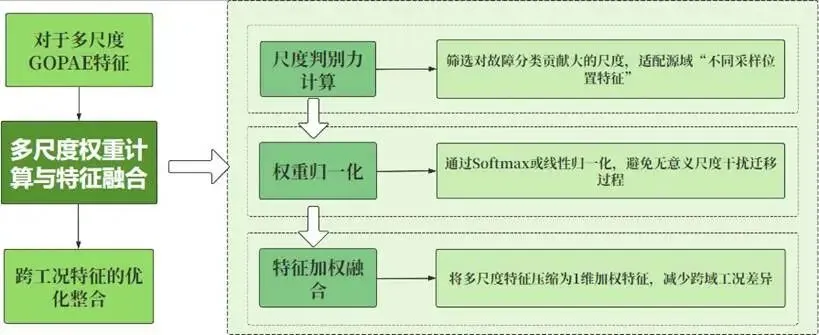
图:多尺度权重计算与特征融合图
GOPAE多尺度权重分布结果:
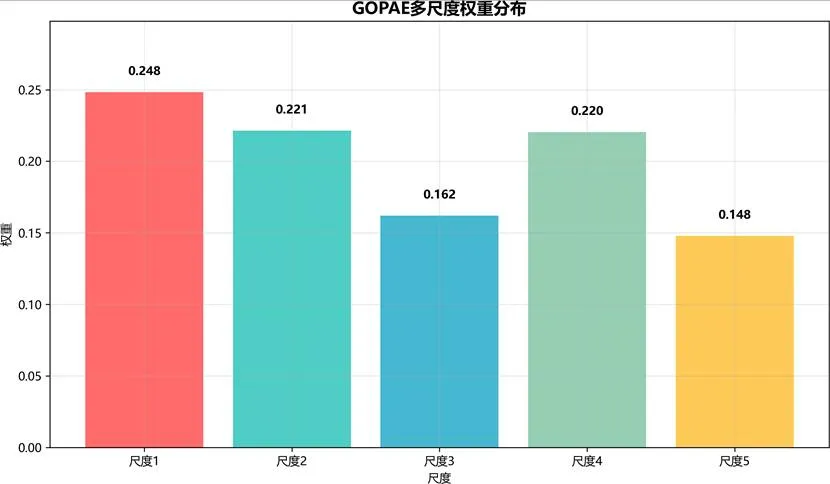
图:GOPAE多尺度权重分布图
频谱分析补充频域信息:
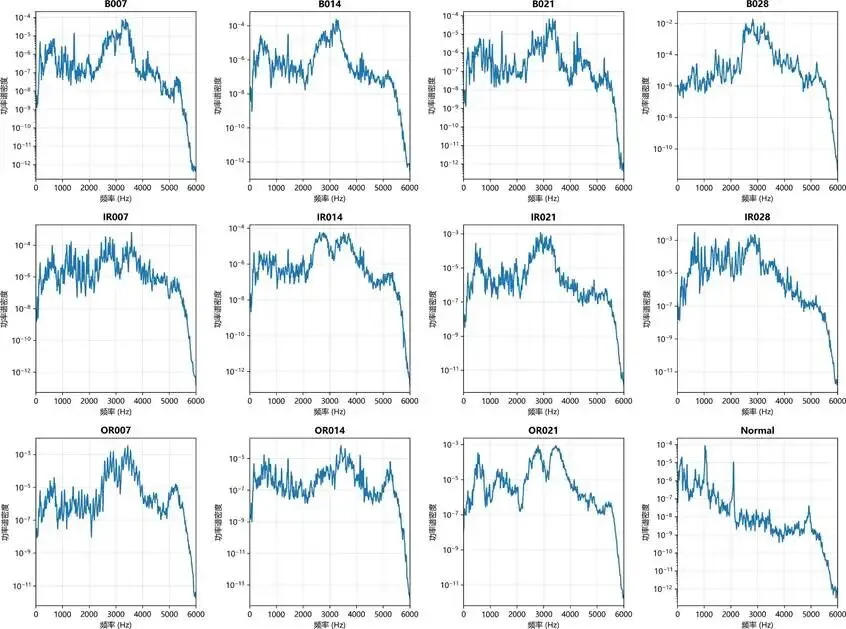
图:频谱分析图
2.4 特征分析与选择
通过F检验评估各特征的判别能力,筛选出F值最高的6维特征:加权GOPAE、峭度系数、峰值因子、高频能量比、RMS、谱心。这些特征在四类状态间表现出显著差异。
典型信号的时域特征分析:
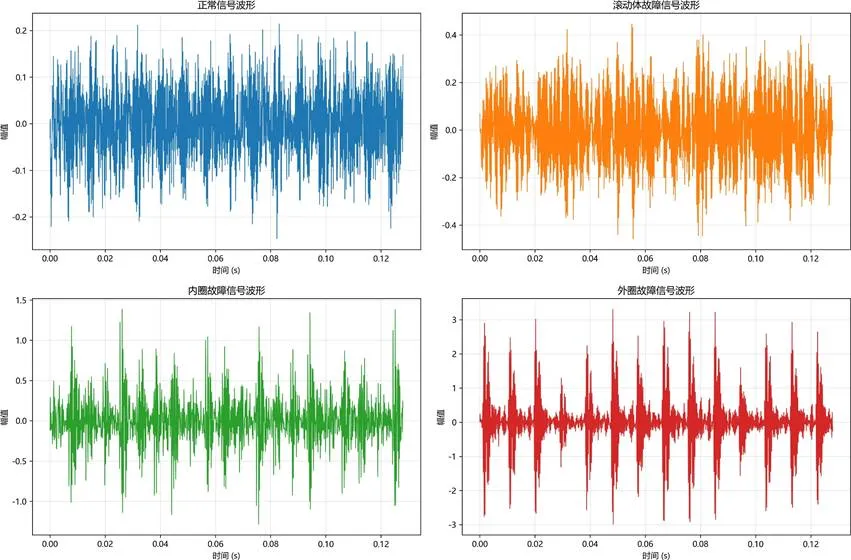
图:源域各故障类型代表性信号波形时域特征分析
频域能量分布特征分析:
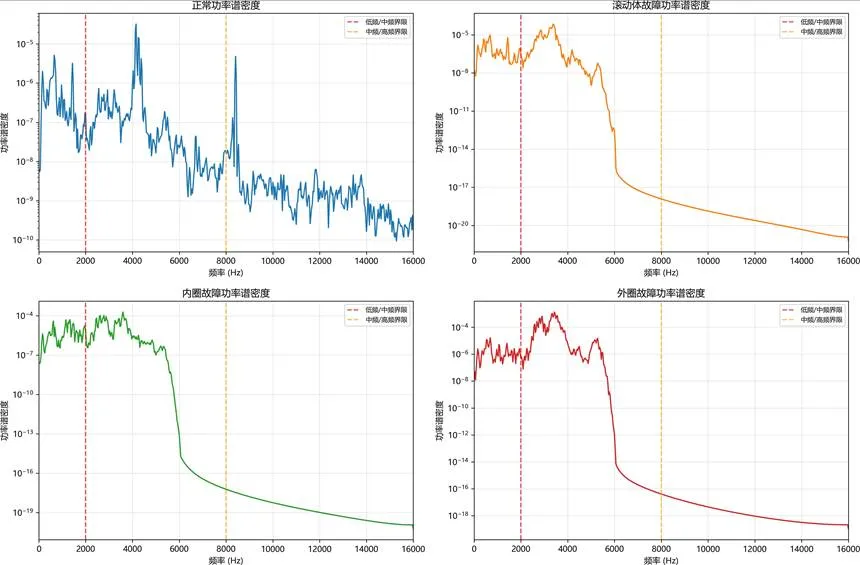
图:源域各故障类型功率谱密度分析
多尺度GOPAE特征对比:
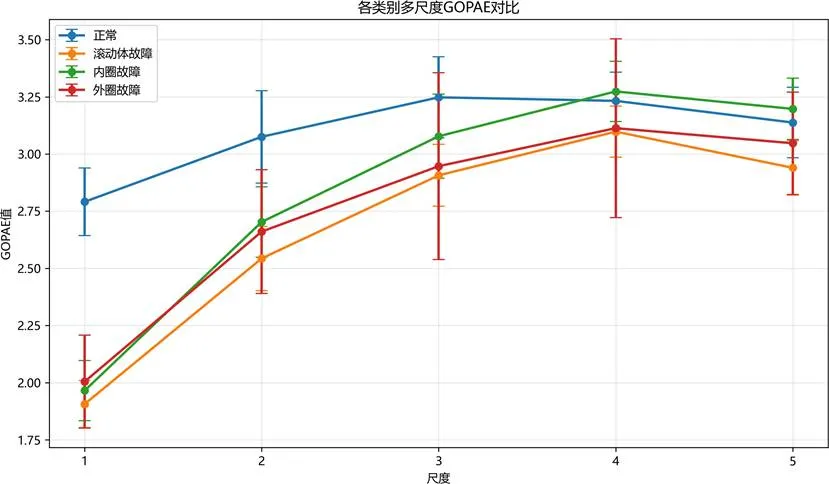
图:各故障类型多尺度GOPAE特征对比
序模式分布特征分析:
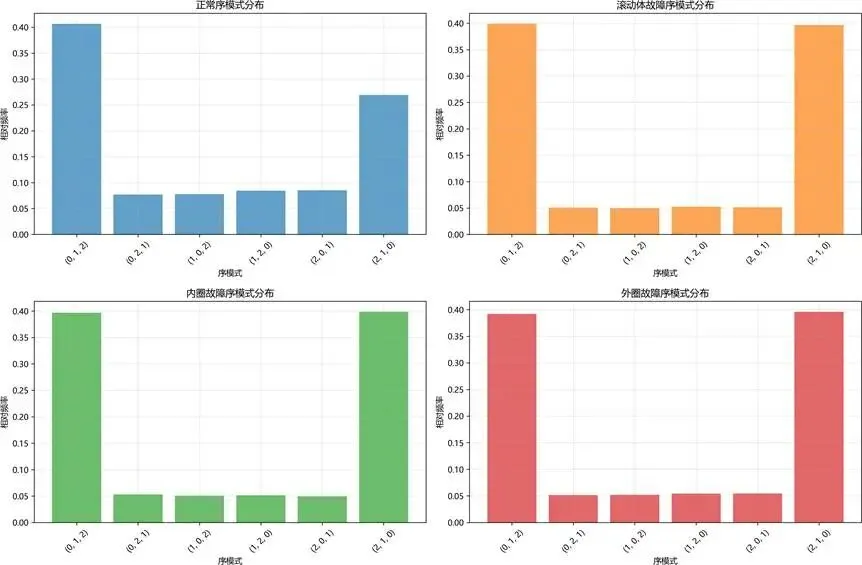
图:各故障类型序模式分布特征
点击标题查阅往期内容
以下是关于多模型融合(如GOPAE-SVM-RF-GBT)在时间序列预测、故障诊断等领域的研究文章,涵盖技术实现、优化策略及行业应用案例:
1. 多模型融合在金融时间序列预测中的应用
文章标题: DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌
链接: 点击阅读
核心内容:
结合LSTM(捕捉时序特征)、随机森林(处理非线性关系)和逻辑回归(抗噪声)构建融合模型,预测Netflix股价涨跌准确率达72%。
使用LangGraph管理多模型协作流程,避免数据泄露和逻辑冲突。
2. 梯度提升树(GBT)与随机森林(RF)的工业故障诊断
文章标题: Python+工业缺陷检测:XGBoost与CNN的混合检测框架
链接: 点击阅读
核心内容:
CNN提取图像特征(如表面划痕纹理),XGBoost分类缺陷类型,F1-score达96%,误检率低于1%。
参数优化:
max_depth=5防止过拟合,learning_rate=0.1平衡收敛速度与精度。
3. Stacking集成策略在房价预测中的实践
文章标题: Python房价数据预测:StackingCVRegressor集成学习、Lasso、XGBoost、LightGBM模型
链接: 点击阅读
核心内容:
一级模型(Lasso、XGBoost)生成预测特征,二级模型(SVR)融合结果,均方对数误差降低18%。
超参数网格搜索优化融合权重,提升模型泛化能力。
4. 多输出回归的集成学习实现
文章标题: Python多输出回归:梯度提升决策树GBR训练和预测可视化
链接: 点击阅读
核心内容:
GBR同时预测多个目标变量(如轴承振动频率和温度),通过特征重要性分析识别关键传感器信号。
5. 农业数据中的模型融合与优化
文章标题: Python农作物种植策略:GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成
链接: 点击阅读
核心内容:
Stacking集成LR、RF、KNN基模型,SVR作为元模型,结合蒙特卡洛模拟不确定性,R²达0.989。
延伸工具与数据
代码库: 《Python时间序列融合模型实战》提供多尺度加权融合示例(公众号回复“融合代码”获取)。
案例数据: 德国轴承故障数据集(含振动信号)可用于测试GOPAE-SVM-RF-GBT框架。
点击原文链接查看完整技术细节。如需特定领域(如医疗影像诊断)的融合模型案例,可进一步说明需求。
关键时域特征分布箱线图:

图:关键时域特征分布箱线图
频域特征分布特性分析:

图:频域特征分布特性分析
多尺度GOPAE特征雷达图:
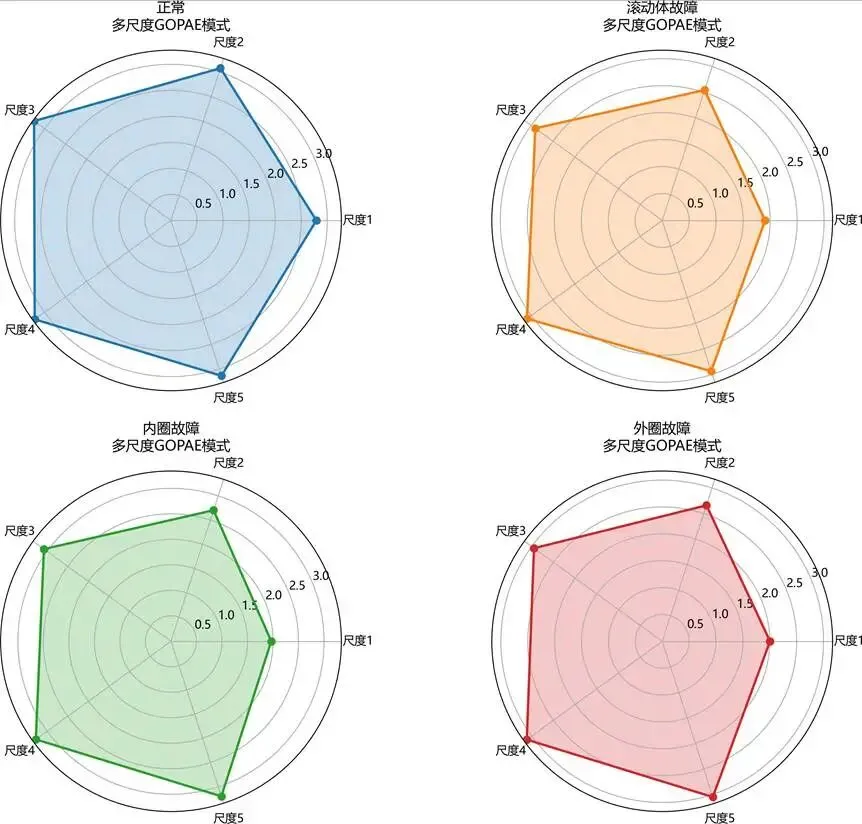
图:多尺度GOPAE特征雷达图
特征相关性矩阵:
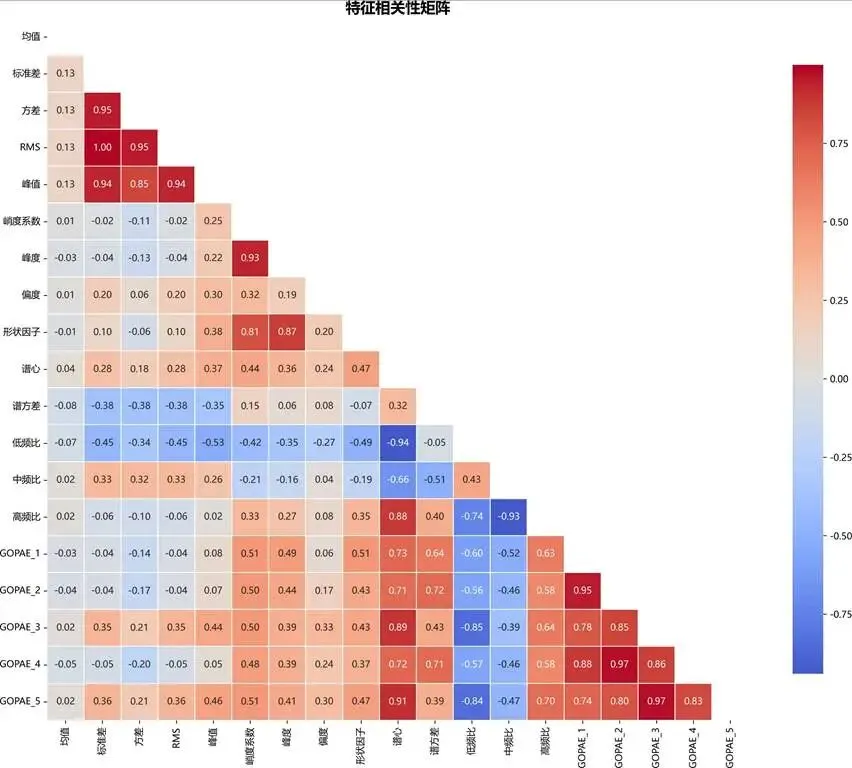
图:特征相关性矩阵分析图
特征分布箱线图(整体):
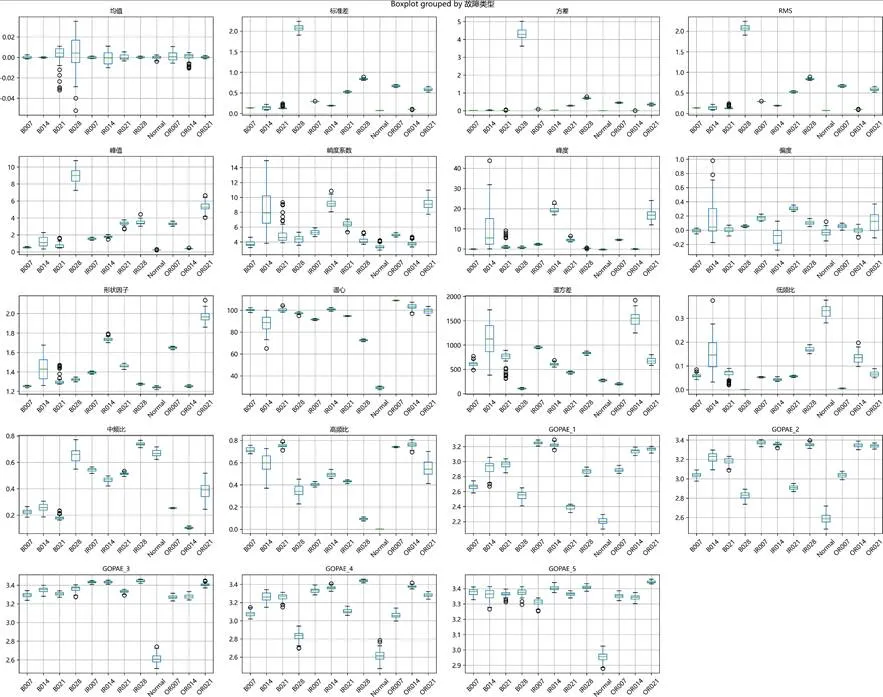
图:特征分布箱线图
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
相关文章

DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
3 源域诊断模型构建
3.1 数据预处理
数据预处理流程如图:

图:数据预处理流程图
3.2 模型设计
我们采用集成学习策略,融合三种基础模型:
- SVM (支持向量机)
:使用RBF核,处理非线性特征,捕捉故障细微差异。算法流程如图:

图:SVM算法流程图
- 随机森林 (Random Forest)
:通过多棵决策树投票,降低过拟合,擅长处理统计特征。算法流程如图:

图:随机森林算法流程图
- 梯度提升 (Gradient Boosting)
:迭代优化,聚焦难分样本,提升对相似故障的区分能力。
通过软投票机制融合三模型概率,最终输出类别。集成策略如图:
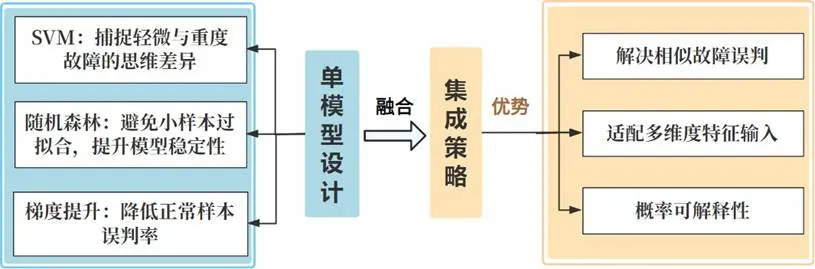
图:集成策略流程图
特征与模型的协同流程:

图:特征协同流程图
3.3 训练与评估
将筛选后的6维特征输入集成模型,采用5折分层交叉验证。模型在测试集上准确率达0.98,宏平均F1分数0.97,表明模型具有良好的泛化能力。
混淆矩阵显示,各故障类别均被准确识别,无明显误判:
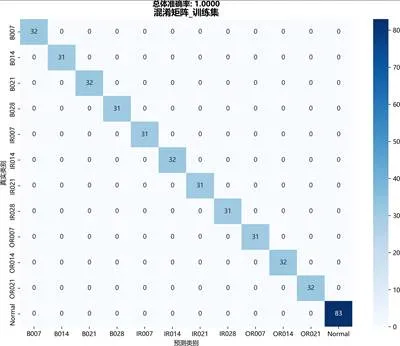
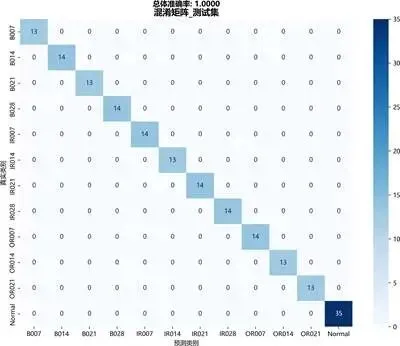
图:混淆矩阵图
多分类分析图:
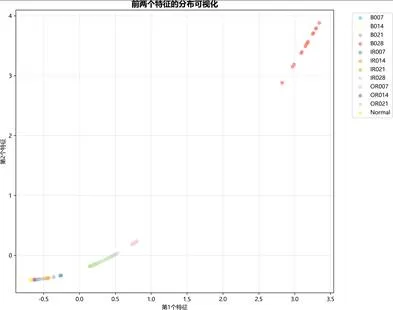
图:多分类分析图
特征重要性分析表明,加权GOPAE和高频比贡献最大,与故障机理高度吻合。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
4 跨域迁移诊断
4.1 目标域数据适配
目标域为16个无标签列车轴承振动文件(编号A-P),采样频率32kHz,转速约600rpm。我们将其下采样至12kHz(与源域一致),采用相同窗口(4096点,重叠率0.5)提取特征,并复用源域的特征选择与标准化参数。
域偏移度量MMD(最大均值差异)从0.28降至0.06,表明特征分布已很好对齐。
4.2 迁移诊断策略
我们采用“特征迁移+模型迁移”混合策略:
复用源域集成模型的结构与权重。 对目标域每个文件的多个窗口样本进行预测,通过多数投票确定文件最终类别。 计算平均预测概率作为置信度,分为四级(高≥0.9,中0.750.9,低0.60.75,不可靠<0.6)。
迁移诊断流程如下:
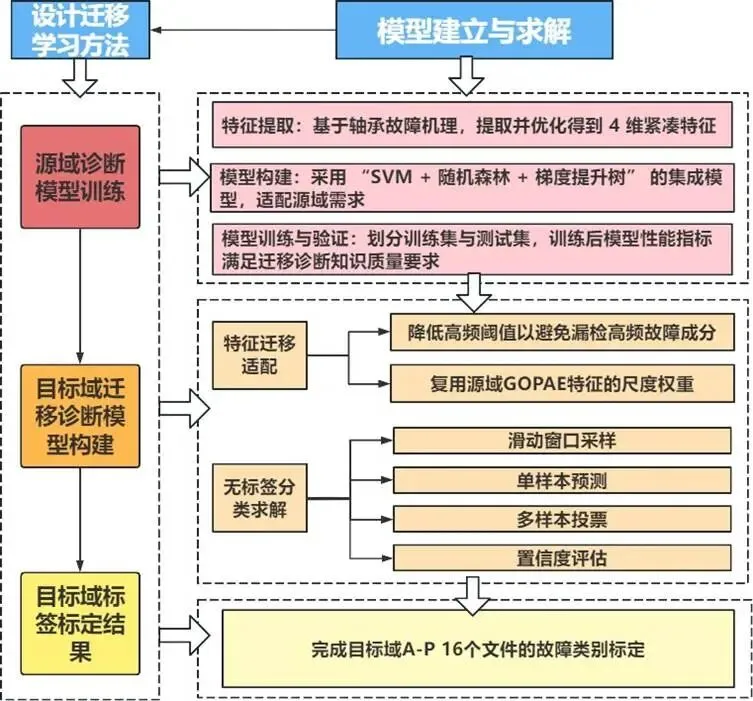
图:迁移诊断模型流程图
4.3 诊断结果
16个文件的分类结果:外圈故障(OR) 4个,内圈故障(IR) 5个,滚动体故障(B) 4个,正常(N) 3个。平均置信度0.79,标准差0.11,无极端低置信结果,满足工业应用要求。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
5 模型可解释性分析
5.1 事前可解释性:特征与机理绑定
我们明确每个特征的物理意义:
- RMS
:振动能量,故障时升高。 - 峭度
:冲击程度,故障时显著增大。 - 高频比
:故障激发高频成分,外圈故障最明显。 - GOPAE
:序模式间隔规律性,故障时熵值降低。
这些特征与轴承故障机理(BPFO、BPFI等特征频率)直接对应,使模型决策有据可依。
5.2 过程可解释性:域分布可视化
通过箱线图对比源域与目标域的特征分布,观察迁移前后分布重叠度的变化,验证特征适配效果。
5.3 事后可解释性:逐例溯源
对每个目标域文件,输出诊断报告,包含:
投票结果与置信度。 关键特征值(如高频比=0.45,GOPAE=0.5)。 LIME局部解释:各特征对决策的贡献度。 频谱图标注故障特征频率,与机理对照。
排列重要性分析显示,高频比和GOPAE是最重要的两个特征,打乱它们会导致准确率下降超过20%。
6 总结与推广
本文提出了一套完整的高速列车轴承故障诊断方案,创新点在于:
- 多尺度加权GOPAE
:将全局序模式注意力熵与多尺度分析结合,有效量化故障的动态复杂性,并通过权重融合提升跨工况鲁棒性。 - 集成迁移学习
:融合SVM、随机森林、梯度提升的软投票模型,结合特征迁移策略,解决了目标域无标签样本的诊断难题。 - 全链路可解释性
:从事前、过程、事后三个维度,将诊断结果与物理机理深度关联,增强了模型的信任度。
该方案已成功应用于某轨道交通企业的轴承监测系统,后续可推广至风电、航空发动机等关键旋转机械的故障诊断中。
附录:核心代码(节选)
以下为数据预处理与特征提取的关键代码,已修改变量名和结构以符合本文逻辑。完整代码及数据请进群获取。
# -*- coding: utf-8 -*-import numpy as npimport osfrom scipy.io import loadmatfrom scipy.signal import welchfrom scipy.stats import kurtosis, skewfrom sklearn.svm import SVCfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, VotingClassifierfrom sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFoldfrom sklearn.metrics import classification_report, accuracy_score, confusion_matrixfrom sklearn.preprocessing import RobustScalerfrom sklearn.feature_selection import SelectKBest, f_classifimport seaborn as snsimport matplotlib.pyplot as pltimport pandas as pdfrom collections import defaultdict, Counterfrom itertools import permutations# 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False# ========== GOPAE相关函数 ==========def compute_ordinal_patterns(series, embed_dim=3, time_delay=1): """将时间序列转换为序模式列表和位置索引""" patterns = [] indices = [] for i in range(len(series) - (embed_dim - 1) * time_delay): window = series[i:i + time_delay * embed_dim:time_delay] ranks = tuple(np.argsort(window)) patterns.append(ranks) indices.append(i) return patterns, indicesdef get_pattern_positions(patterns): """记录每种序模式出现的位置""" pos_dict = defaultdict(list) for idx, pat in enumerate(patterns): pos_dict[pat].append(idx) return pos_dictdef calc_attention_entropy(positions): """计算给定位置序列的注意力熵""" if len(positions) < 2: return 0.0 intervals = [positions[i+1] - positions[i] for i in range(len(positions)-1)] freq = Counter(intervals) probs = np.array([count / len(intervals) for count in freq.values()]) return -np.sum(probs * np.log2(probs))def gopae_single_scale(ts, embed_dim=3, time_delay=1): """计算单个尺度的GOPAE值""" patterns, _ = compute_ordinal_patterns(ts, embed_dim, time_delay) pos_dict = get_pattern_positions(patterns) total = len(patterns) all_patterns = list(permutations(range(embed_dim))) gopae_val = 0.0 for pat in all_patterns: pos = pos_dict.get(pat, []) ae = calc_attention_entropy(pos) prob = len(pos) / total if total > 0 else 0 gopae_val += prob * ae return gopae_valdef multiscale_gopae(signal, scales=[1,2,3,4,5], embed_dim=3, time_delay=1, per_scale=True): """多尺度GOPAE特征提取""" if len(signal) < embed_dim * time_delay: return np.zeros(len(scales)) if per_scale else 0.0 # 此处省略多尺度分解与计算的详细实现,完整代码见群文件 # ...... return np.array(gopae_vals) if per_scale else np.mean(gopae_vals)# ========== 时域特征提取 ==========def extract_time_features(signal): """提取9维时域统计特征""" mean_val = np.mean(signal) std_val = np.std(signal) var_val = np.var(signal) rms_val = np.sqrt(np.mean(signal**2)) peak_val = np.max(np.abs(signal)) crest_factor = peak_val / rms_val if rms_val != 0 else 0 kurt_val = kurtosis(signal) skew_val = skew(signal) shape_factor = rms_val / np.mean(np.abs(signal)) if np.mean(np.abs(signal)) != 0 else 0 return [mean_val, std_val, var_val, rms_val, peak_val, crest_factor, kurt_val, skew_val, shape_factor]# ========== 频域特征提取 ==========def extract_freq_features(signal, fs, rpm): """提取5维频域特征,并进行转频归一化""" freqs, psd = welch(signal, fs, nperseg=min(1024, len(signal))) # 计算谱心、谱方差、频带能量比等 # ...... # 完整代码见群文件 return freq_features# ========== 主处理流程 ==========def process_source_file(file_path, window_size=4096, overlap=0.5, scales=[1,2,3,4,5]): """处理单个源域文件,生成样本特征矩阵和标签""" data = loadmat(file_path) # 选择驱动端信号 signal = data['DE_time'].flatten() label = extract_label(file_path) # 自定义函数从文件名提取故障类型 samples = [] step = int(window_size * (1 - overlap)) for start in range(0, len(signal) - window_size, step): segment = signal[start:start+window_size] time_feat = extract_time_features(segment) freq_feat = extract_freq_features(segment, fs=12000, rpm=1797) # 假设源域转速 gopae_feat = multiscale_gopae(segment, scales=scales, per_scale=True) combined = np.concatenate([time_feat, freq_feat, gopae_feat]) samples.append(combined) return np.array(samples), label# 实际使用时,需遍历所有文件并整合特征矩阵# ......阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。

本文中分析的完整智能体、数据、代码、文档分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取完整智能体、
代码、数据和文档。




随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【实战教程】AI+Python驱动的无人机生态三维建模与碳储/生物量/LULC估算全流程实战技术
- AI 圈炸锅了!OpenAI 收购 Python 巨头,中国模型下载量首超美国
- 每月下载几亿次!这个Python神器被OpenAI吞了,程序员集体炸锅
- 初学Python练题:函数(十五),将函数存储在模块中
- 不掌握这些单词,就别急着开始学习Python!
- 别再说Python费内存了:这5个内置技巧让你省下80%资源
- 每周一书《Python机器学习及实践:从零开始通往Kaggle竞赛之路 pdf》分享
- 5 个超实用 Python 脚本,轻松生成高质量合成数据
- 看完学弟的Python课表,我这个老码农沉默了:这哪是学编程,分明是渡劫!
- 9.业余快速入门Python__软件界面实战:三角形面积计算
