图解 Linux 内存管理:虚拟内存、malloc、缺页中断,一次搞懂
- 2026-06-23 01:10:48
作者:小康,C/C++编程博主
关键词:虚拟内存、物理内存、缺页中断、malloc、内存布局、写时复制
前言
上一篇我们聊了文件系统,提到了 Page Cache 占用内存、内核管理页(Page)。
不少读者留言问:
"内存到底是怎么管理的?为什么 32 位系统每个进程有 4GB 地址空间,但机器只有 2GB 内存?malloc 申请的内存什么时候才真正分配?"
这篇,我们把这些问题一次性讲清楚。
一、先从一个"骗局"说起
你新建一个 C++ 程序,malloc(1GB) 申请 1 GB 内存,在只有 512MB 内存的机器上——居然成功了。
void *p = malloc(1024 * 1024 * 1024); // 1GBif (p) printf("申请成功!\n"); // 真的会打印这句这不是 bug,这是 Linux 内存管理的核心机制在起作用:虚拟内存。
二、虚拟内存:每个进程都有自己的"假地址空间"
Linux 给每个进程都提供一个独立的、连续的地址空间幻觉——这就是虚拟地址空间。
在 64 位系统上,每个进程的虚拟地址空间理论上有 128TB(实际可用约 128TB 用户空间)。但这只是"地址",不是真实内存。虚拟地址必须经过 MMU(内存管理单元)翻译,才能对应到真实的物理内存页。
这张图展示了虚拟地址空间的完整布局:
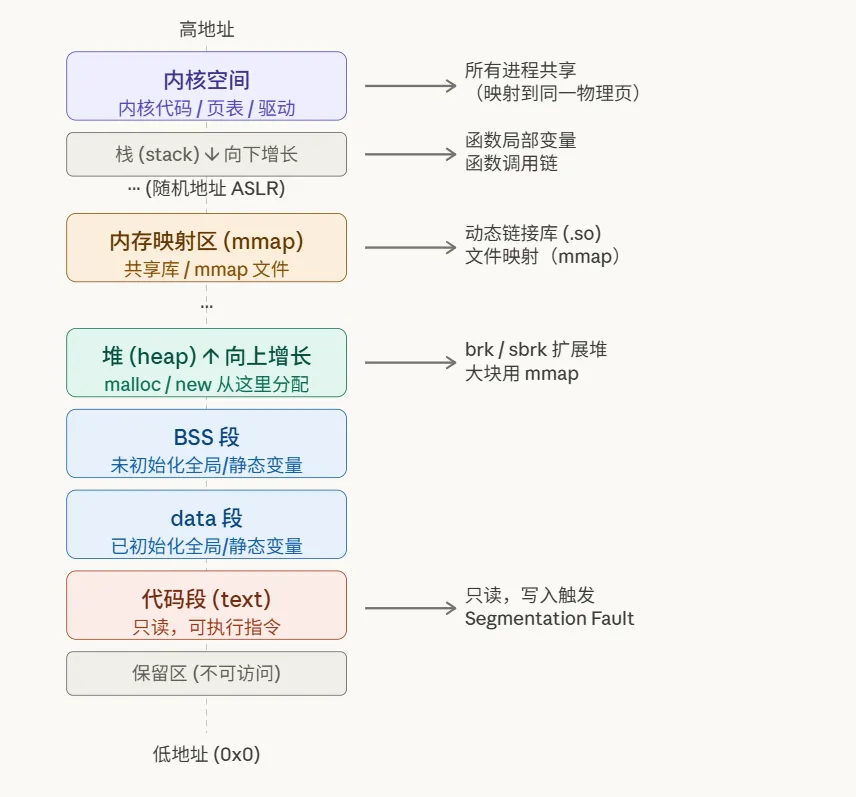
进程的虚拟地址空间从低到高依次是:保留区、代码段、数据段、堆、内存映射区、栈,最上面是内核空间。每个区域都有各自的用途和权限。
进程的虚拟地址空间从低到高:
保留区(0x0 附近):不可访问,空指针解引用会崩溃在这里 代码段(text):只读可执行,存放程序指令 data 段:已初始化的全局/静态变量 BSS 段:未初始化的全局/静态变量(运行时清零) 堆(heap):向上增长, malloc/new从这里分配内存映射区(mmap):共享库、文件映射、大块 malloc 栈(stack):向下增长,函数局部变量、调用链 内核空间:所有进程共享,映射内核代码和数据
三、虚拟地址到物理地址:MMU 和页表
虚拟地址空间是"假的",CPU 真正访问内存时,必须把虚拟地址翻译成物理地址。这个翻译工作由硬件 MMU(Memory Management Unit) 完成,翻译的依据是内核维护的页表(Page Table)。
Linux 以 4KB 为一页(Page) 为单位管理内存。虚拟地址被分成几段索引,逐级查页表,最终得到物理地址:
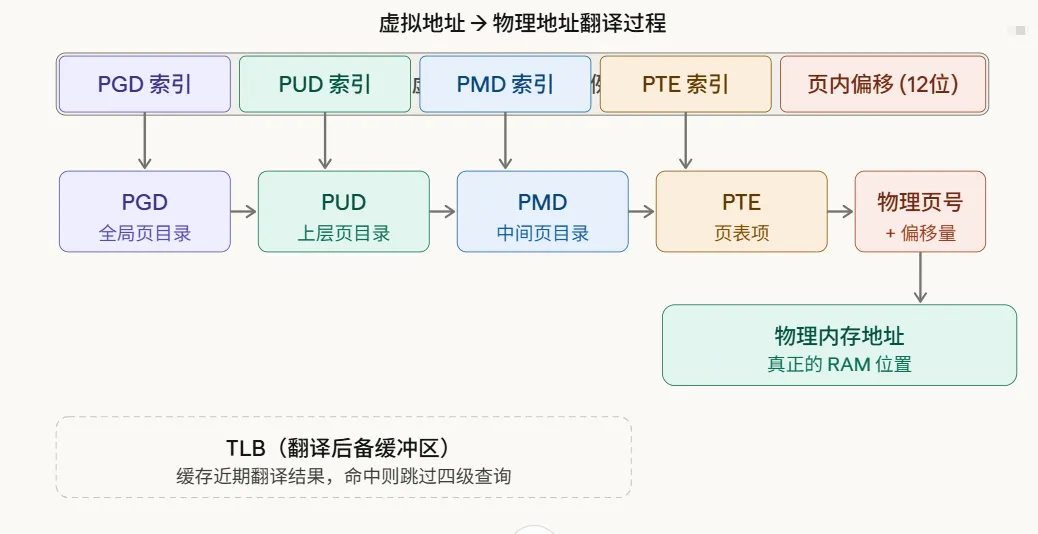
Linux x86-64 采用四级页表(PGD → PUD → PMD → PTE),每次地址翻译最多需要四次内存访问。为了提速,CPU 里有一个 TLB(Translation Lookaside Buffer) 缓存最近的翻译结果,命中时直接得到物理地址,完全跳过四级查询。
四、缺页中断:内存是"用时才分配"的
现在回到文章开头的问题——malloc(1GB) 为什么能在 512MB 的机器上"成功"?
答案是:malloc 成功只是在虚拟地址空间里预留了一段地址范围,并没有立刻分配物理内存。物理内存在你真正访问那个地址时,才会被分配。
这套机制叫缺页中断(Page Fault),是 Linux 内存管理最精妙的设计。
char *p = malloc(1024 * 1024 * 1024); // 只分配虚拟地址,物理页未分配p[0] = 'A'; // 第一次写入:触发缺页中断!内核才真正分配物理页p[1] = 'B'; // 这个物理页已存在,直接写入缺页中断的完整流程如下:
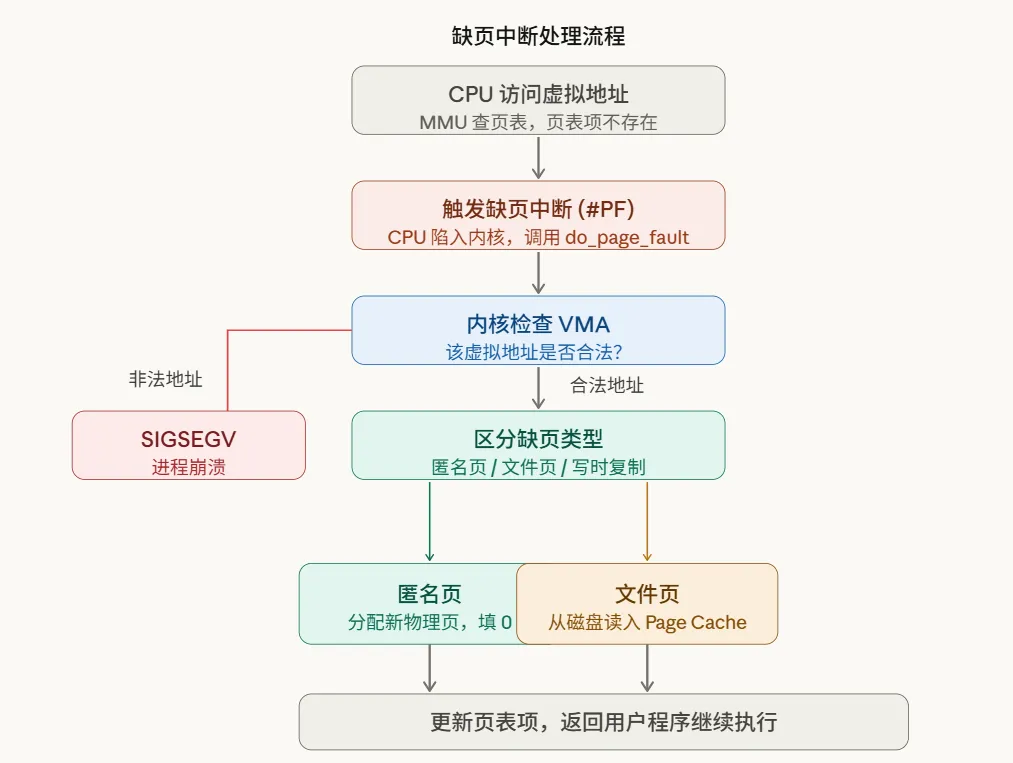
缺页中断有三种典型场景:
匿名页缺页: malloc后第一次访问,内核分配新物理页,清零后映射文件页缺页: mmap映射文件后第一次访问,内核从磁盘读数据到 Page Cache写时复制(COW)缺页: fork()后子进程写父进程的页,内核复制一份新物理页
五、fork() 与写时复制:最优雅的懒惰
fork() 创建子进程时,子进程理论上要复制父进程的全部内存——如果父进程有 1GB 数据,难道每次 fork() 都要拷贝 1GB?
Linux 用写时复制(Copy-On-Write,COW) 解决这个问题:
fork() 之后,父子进程共享同一批物理页,页表项都被标记为只读。谁第一个尝试写入,才触发缺页中断,内核此时复制一份新物理页给写的那方。没有写操作,物理页永远不复制。
intmain(){char *buf = malloc(4096);strcpy(buf, "hello");pid_t pid = fork(); // fork 后父子共享物理页,只读if (pid == 0) { buf[0] = 'H'; // 子进程写入 → 触发 COW → 子进程获得独立副本 }// 父进程的 buf 依然是 "hello",不受影响}这就是为什么 fork() 极其快速——不管父进程有多少内存,fork() 本身的耗时几乎是恒定的。
六、malloc 的真相:不只是向内核要内存
很多人以为 malloc 就是直接调系统调用向内核要内存。其实不是。
malloc 是 C 标准库(glibc)提供的,它在内核和用户程序之间做了一层内存池管理:
首次 malloc:调用brk()或mmap()向内核申请一大块内存后续 malloc:从已申请的内存池里切割,不需要再进内核free:把内存还给 glibc 的内存池,不一定还给内核内存池空闲块过多时:glibc 才调用 brk()或munmap()还给内核
用户程序 glibc (ptmalloc) 内核 │ │ │ ├── malloc(64B) ────────► │ 从内存池切一块 │ │ │ 池空了? ──brk(+128KB)──► │ │ │ ◄── 映射新虚拟内存 ──────┤ ├── free(p) ────────► │ 放回内存池 │ │ │ 池太大? ──brk(-64KB)───► │ 还给内核这也是内存泄漏难以察觉的原因:free 后内存可能仍在 glibc 的池里,进程占用的 RSS 不会立刻下降,但业务逻辑上已经"泄漏"了。
七、内存大小那些概念:VSZ、RSS、PSS 傻傻分不清?
top 命令里看到的内存数字,很多人搞不清楚:
VIRT RES SHR2.1g 156m 42mVIRT(VSZ):虚拟内存大小,包含所有映射的虚拟地址空间,通常远大于实际使用 RES(RSS):常驻内存大小,实际占用的物理内存(含共享库) SHR:与其他进程共享的物理页(主要是共享库 .so)
实际内存占用 ≈ RSS - SHR(进程独占的物理内存)VIRT 很大不用慌,内存实际使用情况看 RSS - SHR。
八、内存回收:内核什么时候把内存要回去?
物理内存不够用时,内核的 kswapd 进程开始回收内存:
干净的文件页(clean page):直接丢弃(反正磁盘上有原始数据,需要时重新读) 脏的文件页(dirty page):先刷回磁盘,再丢弃 匿名页(anonymous page):写入 swap 分区,腾出物理内存
内存压力极大时,还会触发 OOM Killer,内核强行选一个进程杀掉:
# 系统日志里看到这个就是 OOM 了kernel: Out of memory: Kill process 1234 (myapp) score 900 or sacrifice childOOM Killer 按照"最该死"的分数(oom_score)选目标:内存占用大、运行时间短的进程最容易被杀。可以通过调整 oom_score_adj 保护重要进程。
九、高频面试题精析
Q:32 位系统每个进程有 4GB 虚拟空间,但物理内存只有 2GB,能运行多少个进程?
理论上可以运行很多个,因为每个进程的虚拟地址空间是独立的,物理页按需分配(缺页时才分配)。多个进程的代码段、共享库还可以映射到同一物理页,大量节省内存。
Q:malloc(0) 返回什么?
C 标准规定返回一个非 NULL 的唯一指针(可以被 free),但指向的内存大小为 0,不可解引用。glibc 的实现确实会返回一个合法指针。
Q:free 之后内存会立刻归还给操作系统吗?
不会。glibc 的 free 把内存放回内存池,只有当内存池空闲块超过阈值,glibc 才调 sbrk() 或 munmap() 还给内核。这也是为什么用 Valgrind 检测内存泄漏时,程序退出前必须 free 所有内存,否则无法区分"泄漏"还是"在 glibc 池里"。
Q:为什么栈溢出(stack overflow)会直接崩溃,而不是触发缺页中断分配新内存?
内核在栈底预留了一个不可访问的保护页(guard page)。栈溢出时访问保护页,触发缺页中断,内核检查 VMA 后发现是非法访问,直接发送 SIGSEGV。
结语
Linux 内存管理的核心思路,其实是几个"懒惰"哲学的叠加:
虚拟内存:先分地址,物理内存用时再说 缺页中断:访问才分配,按需加载 写时复制:fork 不复制,写时才复制 glibc 内存池:批量向内核要,批量给用户用
这几个机制组合在一起,让 Linux 在有限内存上高效运行数百个进程,同时保持进程间隔离。
理解了这些,你才能真正读懂内存泄漏检测器的原理,才能理解为什么高性能程序要用内存池,才能在面试里把"内存管理"这道题讲到面试官心服口服。
下篇预告:Linux 进程与线程深度解析:fork()、exec()、线程实现原理与写时复制全解析
📌 还在打基础?从这里出发
如果你读完这篇还觉得 C、C++、Linux 有些陌生,别急——我也开设了三门入门课程,从零带你打好地基,快速上手项目实战:
C 语言快速入门 :大一啃完谭浩强的书,还是不会写代码?我花1个月做了套'12天速成'的C语言课 C++ 快速入门 :12天,从C++小白到独立做项目!我把3年踩坑经验浓缩成了这门课 Linux 编程快速入门 :为什么你学了半年 Linux 编程,还是写不出一个像样的程序?
感兴趣可以了解一下。
🚀 基础扎实了?来做 C++ 工业级项目
| 线程池 | |
| 高性能日志库 MiniSpdlog | |
| 高性能内存池 | |
| 多线程下载工具 | |
| MySQL 连接池 | |
| 内存泄漏检测器 | |
| ReactorX | |
| 无锁栈 | |
| 工业级智能指针(shared_ptr) | |
| 高性能网络库 NetCore | |
| 高性能异步日志库 ZephyrLog | |
| 死锁检测工具 | |
| 高性能 HTTP 服务器 | |
| 协程库 CoroForge | |
| 高性能 HTTP 压测工具 | |
| Redis 核心模块实战 |
每个项目都是真实可用的工程代码,不是教学玩具。
详情点击 C++ 项目合集课程链接:为什么同样是"学过C++",有人面试碾压,有人开口就怂?差距在这18个C++硬核项目
对C++项目实战课程感兴趣的朋友,可以扫下方二维码添加小康微信(或微信搜索:jkfwdkf ) 备注「 项目实战 」

觉得有收获,点赞、推荐和转发支持下哦~ 🙏
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python第一课 | 邂逅 Python,解锁编程世界的金钥匙
- 数学可以用Python 画图的方式教,一切数学都是图形
- 《码上仿真:Abaqus Python API》Vol.5 NormalBehavior 硬接触与软接触的“敲代码”秘籍
- OpenAI 买下了 Python 的包管理器,Anthropic 让 AI 住进了聊天软件
- OpenAI突然出手!收购Python最强基建,AI编程大战升级
- 14个Python自动化脚本|实战干货,拿来就用
- 零基础学Python:教Python说话
- uv 开发团队被OpenAI收编!Python 工具链命运几何
- PHP-SQL注入代码审计
- 照着学就行!14步自学Python超详细流程
