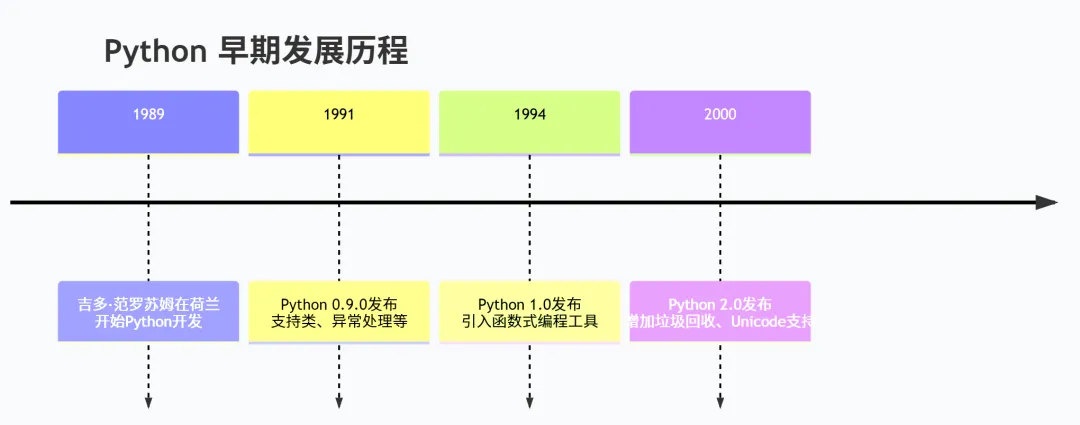
一、Python 发展历史与重要里程碑
1. 诞生与早期发展(1989-2000)
关键人物:吉多·范罗苏姆(Guido van Rossum)
2. Python 2.x 时代(2000-2008)
# Python 2.x 时代代表性语法print"Hello World"# 2.x的print语句x = 5/2# 结果为2(整数除法)
重要特性:
2001年:Python 2.2 - 类型统一,新式类
2004年:Python 2.4 - 装饰器语法@
2006年:Python 2.5 - with语句,条件表达式
2008年:Python 2.6 - 为向Python 3过渡准备
3. Python 3.x 革命(2008-现在)
# Python 3.x 重大变化print("Hello World") # 变为函数x = 5/2# 结果为2.5(真除法)text = "中文"# 默认Unicode支持版本演进关键节点:
| 版本 | 发布时间 | 重要特性 |
|---|
| Python 3.0 | 2008年 | 打破向后兼容性,Unicode为核心 |
| Python 3.5 | 2015年 | async/await异步编程 |
| Python 3.6 | 2016年 | f-string格式化字符串 |
| Python 3.8 | 2019年 | 海象运算符:= |
| Python 3.9 | 2020年 | 字典合并运算符| |
| Python 3.10 | 2021年 | 模式匹配match/case |
| Python 3.11 | 2022年 | 性能大幅提升(10-60%) |
二、Python 设计哲学与技术特点
1. 核心设计原则(Python之禅)
import this# 输出Python之禅:"""优美胜于丑陋明了胜于晦涩简单胜于复杂..."""
2. 技术特点对比分析
| 特性 | Python | Java | JavaScript | C++ |
|---|
| 类型系统 | 动态强类型 | 静态强类型 | 动态弱类型 | 静态强类型 |
| 执行方式 | 解释型 | 编译+解释 | 解释型/JIT | 编译型 |
| 语法简洁性 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐ |
| 学习曲线 | 平缓 | 陡峭 | 中等 | 陡峭 |
| 性能 | 中等 | 高 | 中等 | 极高 |
| 生态丰富度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
3. Python 核心技术优势
# 1. 动态类型系统x = 10# 整数x = "hello"# 字符串 - 动态类型# 2. 鸭子类型class Duck:def quack(self): print("Quack!")class Person:def quack(self): print("I'm quacking!")def make_quack(obj):obj.quack() # 不关心类型,只关心行为# 3. 丰富的内置数据结构list_data = [1, 2, 3] # 列表dict_data = {"key": "value"} # 字典set_data = {1, 2, 3} # 集合tuple_data = (1, 2, 3) # 元组三、Python 应用场景深度分析
1. Web开发领域
# Flask 轻量级Web框架示例from flask import Flaskapp = Flask(__name__)@app.route('/')def hello():return 'Hello, World!'if __name__ == '__main__':app.run()# Django 全功能框架特性"""- ORM数据库抽象层- 自动化管理后台- 强大的模板引擎- 内置安全防护"""市场占有率:
2. 数据科学与机器学习
# 典型数据科学工作流import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifier# 数据加载与处理data = pd.read_csv('dataset.csv')X_train, X_test, y_train, y_test = train_test_split(X, y)# 模型训练model = RandomForestClassifier()model.fit(X_train, y_train)# 深度学习示例(PyTorch)import torchimport torch.nn as nnclass NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.layers = nn.Sequential(nn.Linear(784, 128),nn.ReLU(),nn.Linear(128, 10) )生态系统:
数据处理:Pandas, NumPy
可视化:Matplotlib, Seaborn, Plotly
机器学习:Scikit-learn, XGBoost
深度学习:TensorFlow, PyTorch, Keras
大数据:PySpark, Dask
3. 自动化与脚本编程
# 系统管理自动化import osimport shutilimport subprocessdef backup_files(source_dir, backup_dir):"""自动化备份脚本"""if not os.path.exists(backup_dir):os.makedirs(backup_dir)for file in os.listdir(source_dir):if file.endswith('.log'):shutil.copy2(os.path.join(source_dir, file),os.path.join(backup_dir, f"{file}.backup") )# 网络自动化import requestsdef monitor_website(url):response = requests.get(url)return response.status_code == 2004. 科学计算与工程应用
# 科学计算示例import numpy as npfrom scipy import integrateimport sympy as sp# 数值积分result, error = integrate.quad(lambda x: np.sin(x), 0, np.pi)# 符号计算x = sp.Symbol('x')derivative = sp.diff(sp.sin(x), x)# 工程仿真import matplotlib.pyplot as pltt = np.linspace(0, 10, 1000)signal = np.sin(2*np.pi*5*t) # 5Hz正弦波plt.plot(t, signal)plt.show()四、市场需求与就业前景分析
1. 全球市场需求趋势
薪资水平分析(2023年数据):
| 职位类别 | 初级薪资 | 中级薪资 | 高级薪资 |
|---|
| Python Web开发 | 15-25万/年 | 25-40万/年 | 40-70万/年 |
| 数据科学家 | 20-30万/年 | 30-50万/年 | 50-100万/年 |
| 机器学习工程师 | 25-35万/年 | 35-60万/年 | 60-120万/年 |
| 自动化测试 | 12-20万/年 | 20-30万/年 | 30-50万/年 |
2. 行业分布需求
# 各行业Python应用热度分析industry_demand = {"互联网科技": {"热度": 95, "主要应用": ["Web开发", "大数据", "AI"]},"金融科技": {"热度": 90, "主要应用": ["量化交易", "风险分析", "区块链"]},"医疗健康": {"热度": 85, "主要应用": ["生物信息", "医疗影像", "药物研发"]},"工业制造": {"热度": 80, "主要应用": ["工业自动化", "质量控制", "预测维护"]},"教育科研": {"热度": 88, "主要应用": ["科学计算", "数据分析", "教学工具"]}}3. 技能要求矩阵
| 技能领域 | 必备技能 | 加分技能 | 未来趋势 |
|---|
| Web开发 | Flask/Django, RESTful API | 微服务, 容器化, GraphQL | 云原生, Serverless |
| 数据科学 | Pandas, NumPy, 数据可视化 | 大数据平台, 数据管道 | 实时计算, 边缘计算 |
| AI/ML | Scikit-learn, 深度学习框架 | MLOps, 模型部署 | 自动机器学习, 可解释AI |
| 自动化 | 脚本编写, 系统管理 | RPA, 工作流自动化 | 智能自动化, 认知计算 |
五、未来发展趋势与前景
1. 技术发展方向
# 未来Python技术栈预测future_tech_stack = {"性能优化": ["PyPy JIT编译器","Numba加速计算", "Cython混合编程","Python 3.11+ 持续性能提升" ],"并发编程": ["asyncio异步生态成熟","多进程分布式计算","GPU/TPU异构计算" ],"AI集成": ["AI辅助编程工具","自动代码生成","智能调试系统" ],"跨平台": ["WebAssembly支持","移动端优化","边缘设备部署" ]}2. 新兴应用领域
3. 生态系统演进预测
2024-2028年关键发展:
性能革命:Python 3.14+ 预期比Python 3.10快2倍
类型系统成熟:静态类型检查成为大型项目标配
AI原生开发:AI驱动的开发环境普及
WebAssembly支持:Python在浏览器端广泛应用
量子计算桥梁:成为量子经典混合编程首选语言
4. 面临的挑战与应对
| 挑战 | 现状 | 解决方案 | 进展 |
|---|
| 性能问题 | 解释型语言固有瓶颈 | JIT编译、类型注解、C扩展 | PyPy, Numba, Cython |
| 移动端支持 | 相对薄弱 | BeeWare, Kivy框架 | 逐步完善 |
| 并发模型 | GIL限制 | asyncio, 多进程, 无GIL版本 | Python 3.12改进GIL |
| 包管理混乱 | pip, conda, poetry并存 | PEP标准统一 | uv等新工具出现 |
六、学习与发展建议
1. 学习路径规划
# 阶段性学习路线learning_path = {"阶段1: 基础入门(1-3个月)": ["基本语法与数据结构","函数与面向对象编程", "文件操作与异常处理","常用标准库使用" ],"阶段2: 专业方向(3-6个月)": {"Web开发": ["Flask/Django", "数据库", "REST API"],"数据科学": ["Pandas/NumPy", "数据可视化", "统计分析"],"自动化运维": ["系统管理", "网络编程", "任务调度"] },"阶段3: 高级进阶(6-12个月)": ["性能优化与调试","设计模式与架构","并发编程","开源项目贡献" ],"阶段4: 专家水平(1-2年)": ["源码阅读与理解","框架开发","技术领导力","社区影响力建设" ]}2. 职业发展建议
短期(1年内):
深耕一个专业方向(Web/数据/AI)
建立完整的项目作品集
参与开源项目,积累GitHub贡献
中期(1-3年):
长期(3-5年):
成为技术专家或架构师
参与技术标准制定
建立个人技术品牌
七、总结:Python的未来前景
1. 持续的领导地位
TIOBE指数:长期保持前3名
GitHub语言排名:连续多年第一
招聘需求:年均增长15-20%
2. 不可替代的优势
# Python的护城河competitive_advantages = {"教育入口": "全球80%的大学计算机入门课程使用Python","科研基础": "成为科学计算的默认选择","AI生态": "机器学习框架几乎全部基于Python","社区活力": "全球最大的编程语言社区之一","企业采纳": "谷歌、Meta、NASA、Netflix等巨头深度使用"}3. 未来预测
到2030年,Python将:
继续保持AI和数据科学领域的主导地位
在性能方面接近静态语言水平
成为量子编程的重要接口语言
在基础教育中进一步巩固地位
诞生更多千亿级Python技术公司
Python的成功证明了一个真理:简洁性、可读性和强大的社区生态比单纯的技术性能更能决定一种编程语言的长期生命力。对于开发者而言,投资Python技能不仅是学习一门语言,更是加入一个持续创新、充满机遇的技术生态系统。