在数据科学和工程应用中,回归预测是最常见也最重要的问题之一。无论是房价预测、销量预估,还是设备剩余寿命预测,回归模型都扮演着核心角色。然而,面对众多算法,如何快速对比、选择最适合的模型,往往让人头疼。
今天,我们为大家带来一套回归预测全家桶,一次性集齐12种经典机器学习模型,助你轻松应对各类回归任务!
12种模型,全面覆盖
本次代码共收录了以下12种算法,涵盖线性模型、树模型、神经网络、集成学习等多个流派:
BP神经网络(Backpropagation Neural Network):经典的深度学习基础模型,擅长捕捉非线性关系。
支持向量机(SVM):通过核技巧将数据映射到高维空间,适用于小样本、非线性回归。
决策树(Decision Tree):直观易懂的树结构模型,可解释性强。
随机森林(Random Forest):基于Bagging的集成方法,抗过拟合能力强。
XGBoost:高效的梯度提升框架,在竞赛和工业界表现优异。
GBDT(Gradient Boosting Decision Tree):梯度提升决策树,逐步优化预测误差。
AdaBoost:自适应提升算法,关注难分样本。
CatBoost:擅长处理类别特征的梯度提升模型,无需繁琐预处理。
线性回归(Linear Regression):最基础的回归模型,快速基准线。
Lasso回归:引入L1正则化,可实现特征选择。
Ridge回归:引入L2正则化,缓解过拟合。
LightGBM(部分扩展版本):基于直方图的梯度提升框架,训练速度快、内存占用低。
为何需要“全家桶”?
在实际项目中,我们往往无法事先判断哪种模型最优。不同的数据分布、样本量、特征类型,都可能使模型表现天差地别。如果逐一编写代码调试,不仅耗时,还容易遗漏关键模型。
这套“全家桶”代码将所有模型封装在同一框架下,只需简单配置,即可一键运行并对比效果,大幅提升建模效率。
代码亮点
统一接口:所有模型均遵循相同风格和接口,方便替换和扩展。
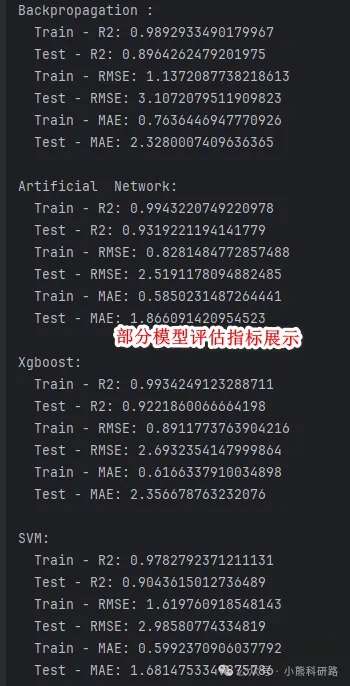
自动化评估:自动计算RMSE、MAE、R²等核心指标,并生成对比表格。
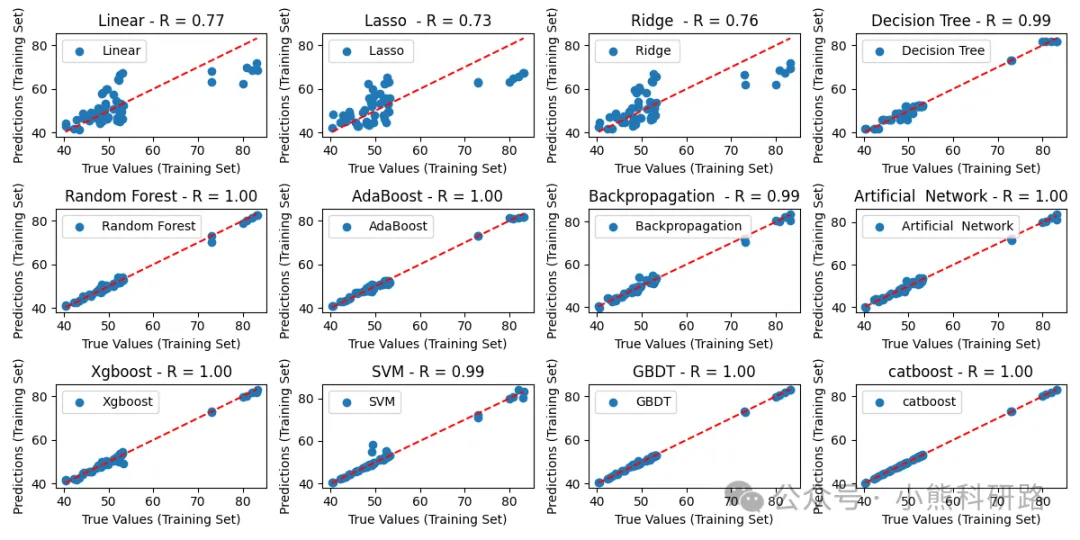
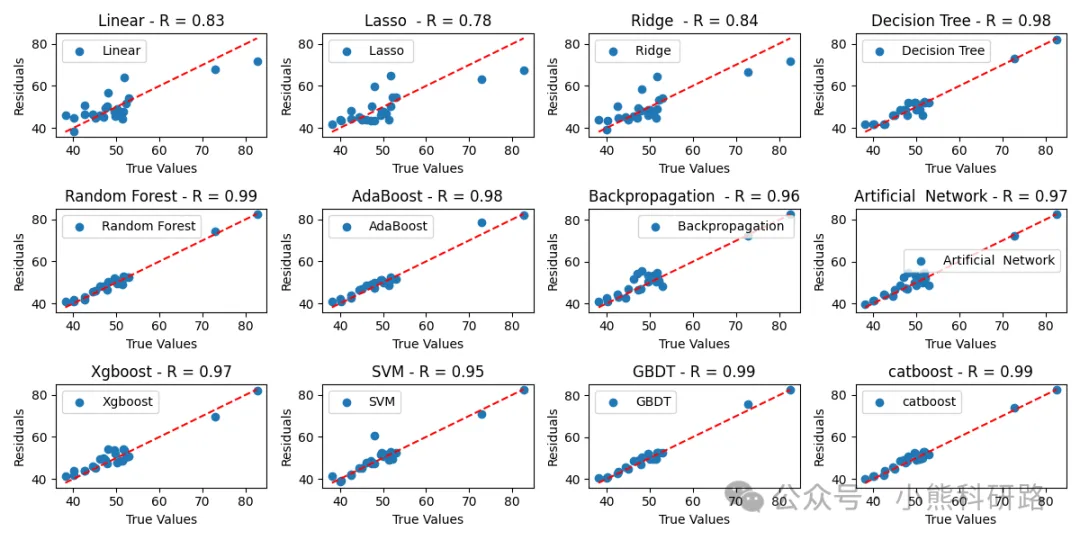
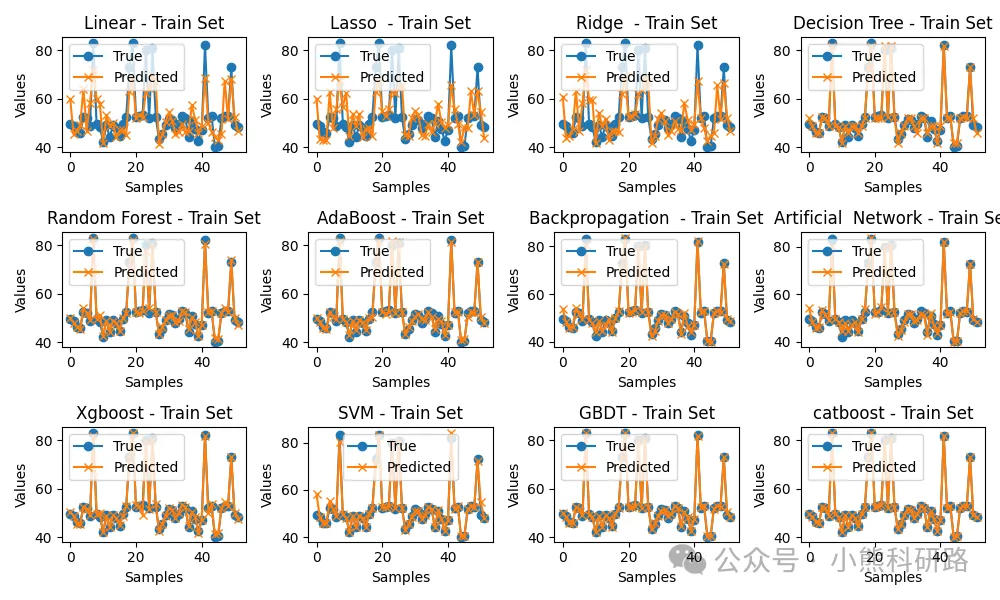
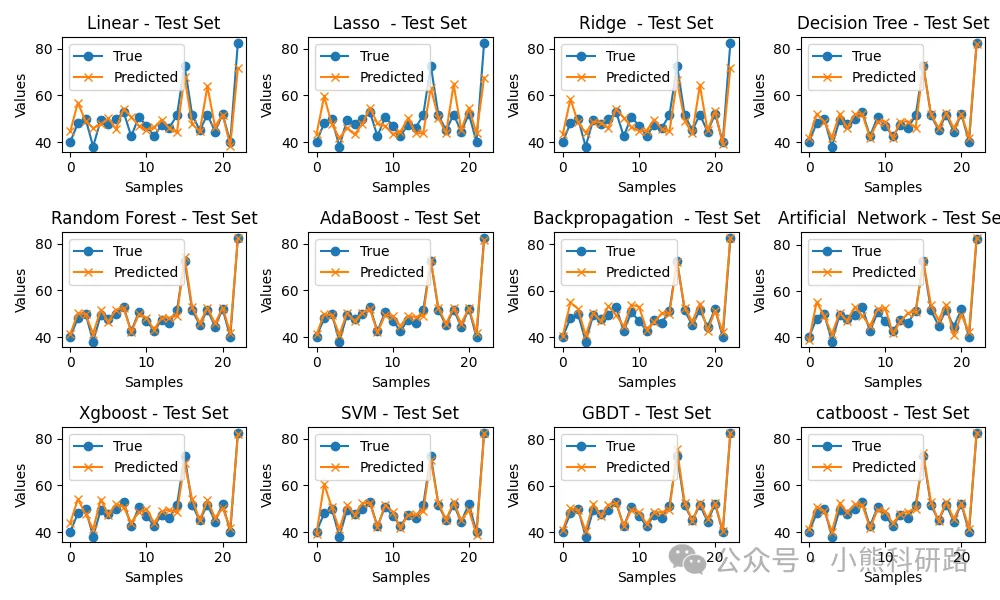
可视化支持:一键绘制预测值与真实值散点图、残差图,直观评估模型表现。
数据预处理集成:内置标准化、缺失值处理等常用步骤,简化数据清洗流程。
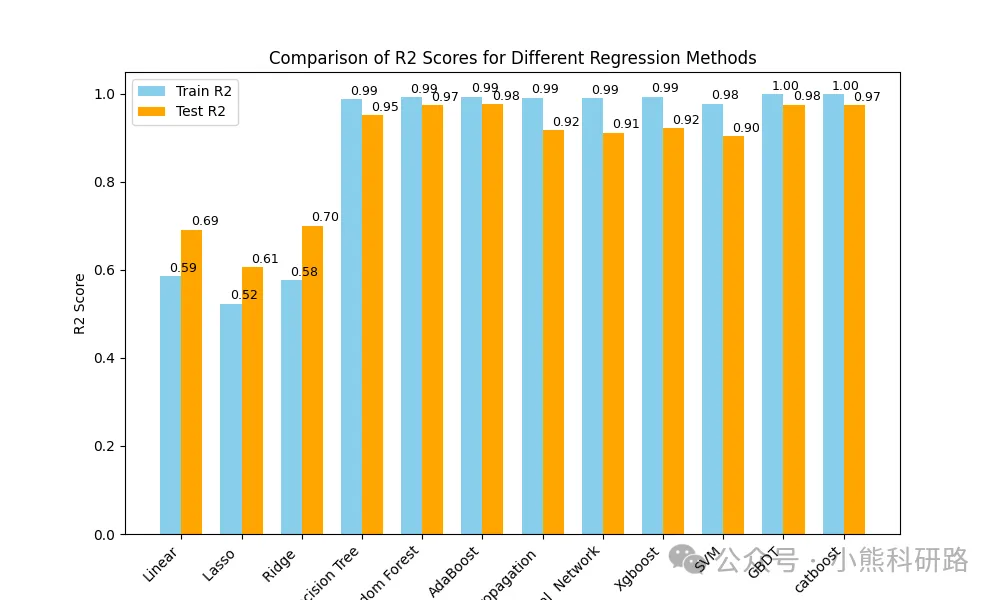
效果展示
从测试结果来看,集成学习模型(如XGBoost、CatBoost、随机森林)在大多数数据集上表现稳健,尤其是在非线性关系较强的场景中,明显优于线性模型。而BP神经网络在大样本下也能取得不错的效果,但需注意参数调优。
模型效果展示如下:
适用场景
总结
回归预测没有“银弹”,多模型对比才是保障效果的关键。这套12合1的回归全家桶,帮你省去重复造轮子的时间,让你更专注于特征工程与业务理解。
代码已开源,欢迎下载体验,一键跑通,开启高效建模之旅!
代码获取方式
本文采用python代码编写,代码注释详细,逻辑清晰易懂,数据采用excel表格形式便于替换数据集,可一键运行。如需上述12种机器学习算法的多输入变量回归预测模型完整代码,可以点击文章下方“阅读原文”链接到代码下载网址。也可可以微信联系小编:panda20219。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
