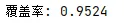在上一节中,我们得到了一个重要结论:
参数估计量在大样本下服从近似正态分布
即:
1问题提出
我们已经可以计算点估计,但一个更关键的问题是:
这个估计有多可靠?误差范围是多少?
👉 这就引出了:
区间估计(Interval Estimation)
2核心思想
我们从一个概率陈述出发:
关键变换(推导核心)
对不等式变形:
👉 得到置信区间:
3直觉解释
很多人误解置信区间:
❌ 错误理解:
参数有 95% 概率在区间内
✅ 正确理解:
区间是随机的,参数是固定的
👉 更准确说法:
如果重复采样 100 次
构造 100 个区间
👉 约有 95 个区间包含真实参数
4Python验证(覆盖率)
# file: ci_coverage.py
import numpy as np
defmain():
np.random.seed(0)
true_mu = 10
sigma = 2
n = 30
count = 0
N_sim = 5000
for _ in range(N_sim):
data = np.random.normal(true_mu, sigma, n)
x_bar = np.mean(data)
lower = x_bar - 1.96 * sigma / np.sqrt(n)
upper = x_bar + 1.96 * sigma / np.sqrt(n)
if lower <= true_mu <= upper:
count += 1
print("覆盖率:", count / N_sim)
if __name__ == "__main__":
main()
结果解释
5σ未知:t分布
现实中:
σ 通常未知
此时使用:
👉 置信区间:
6Python验证(t区间)
# file: ci_t_distribution.py
import numpy as np
from scipy import stats
defmain():
np.random.seed(0)
true_mu = 10
n = 20
N_sim = 5000
count = 0
for _ in range(N_sim):
data = np.random.normal(true_mu, 2, n)
x_bar = np.mean(data)
s = np.std(data, ddof=1)
t_val = stats.t.ppf(0.975, df=n-1)
lower = x_bar - t_val * s / np.sqrt(n)
upper = x_bar + t_val * s / np.sqrt(n)
if lower <= true_mu <= upper:
count += 1
print("覆盖率:", count / N_sim)
if __name__ == "__main__":
main()
执行结果如下: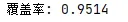
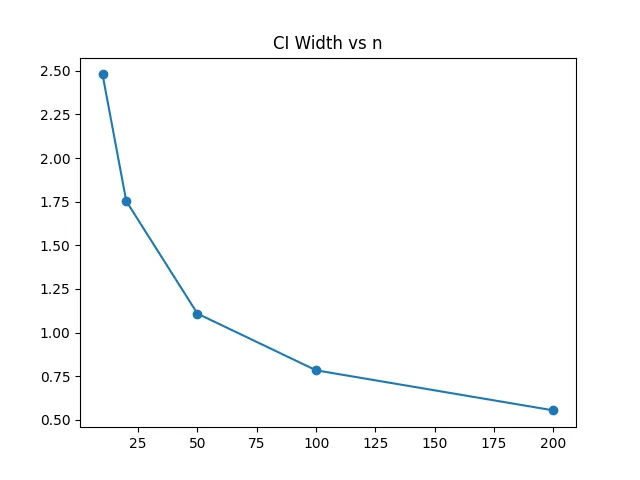
7区间宽度分析(工程重点)
区间长度:
# file: ci_width.py
import numpy as np
import matplotlib.pyplot as plt
defmain():
np.random.seed(0)
sizes = [10, 20, 50, 100, 200]
widths = []
for n in sizes:
width = 2 * 1.96 * 2 / np.sqrt(n)
widths.append(width)
plt.plot(sizes, widths, marker='o')
plt.title("CI Width vs n")
plt.show()
if __name__ == "__main__":
main()
结果解释
8工程意义
置信区间用于:
9本节总结
10下期预告
下一讲进入统计决策核心:
📌 点赞 + 转发,持续更新《统计学入门》