大家好,今天我们来聊聊如何利用 XGBoost 和 SHAP 进行模型建模与可解释性分析。我们会逐一解析代码输出的10张图,帮助大家理解每张图的含义、背后的原理,以及如何通过这些图来提升我们的模型理解能力。
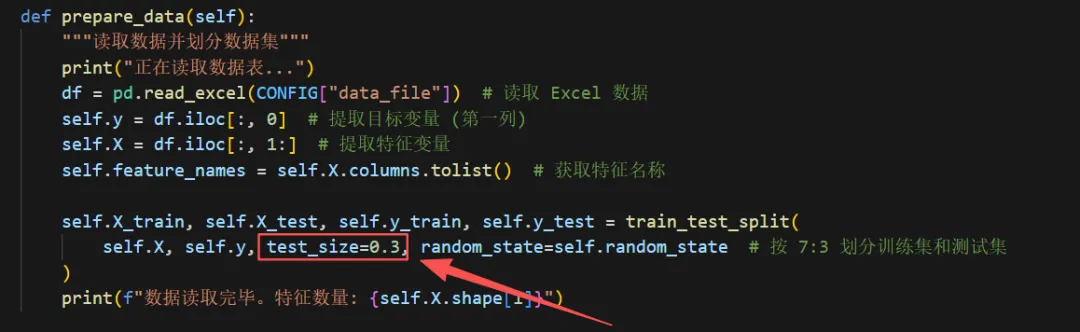
这套代码先读取 Excel 数据,把第一列作为因变量、其余列作为自变量,再按 7:3 划分训练集和测试集;之后用 XGBoost 回归器结合随机搜索做参数优化,并基于训练后的树模型计算 SHAP 值、 SHAP 交互值与二维部分偏依赖PDP;最终按统一风格批量输出 10 大类图形,保存为 PNG 和 PDF 两种格式。这是一套从“预测”走向“解释”的完整科研可视化方案。
这套代码适合解决这样的问题:知道模型能不能预测准、哪些变量最重要、变量是正向还是负向起作用、是否存在阈值效应、两个变量会不会联合作用、不同样本为什么会得到不同预测结果。尤其适合生态环境、医学预测、农业性状分析、材料性能预测、地学建模、经济与社会科学中的多变量回归问题。
代码当前使用的是 XGBRegressor,并用到 R²、RMSE、MAE 等回归指标,所以它对应的是连续型变量的回归研究,而不是分类任务。
完整代码获取:回复“ XGBoost回归 ”即可获得通道
我们先来看看我组合在一起的美图:
●XGBoost 模型概念:
XGBoost是一个高效的梯度提升树实现,它在处理各种回归、分类任务中表现非常出色。梯度提升树的核心思想是通过一系列弱学习器,每棵树都在前一棵树的基础上纠正误差,最终组成一个强学习器。XGBoost 则是在这一基础上做了优化,采用了很多高效的技术,如 并行计算、正则化、剪枝技术等,极大地提升了计算效率和模型性能。
XGBoost 的特点:
高效性:XGBoost 在大数据集上的表现非常高效,能够利用多线程进行并行计算,支持 GPU 加速。
可调节性:XGBoost 提供了多种参数来调节模型,帮助解决过拟合问题,并提高预测精度。
处理缺失值:XGBoost 在训练过程中能够自动处理缺失值,减少了数据预处理的工作量。
集成方法:作为梯度提升树的一种实现,XGBoost 通过集成学习方法结合多棵树的预测结果,提高了整体模型的鲁棒性和准确性。
●SHAP概念:
SHAP 是一种模型可解释性方法,全称是 Shapley Additive Explanations,它通过Shapley 值来解释每个特征对模型输出的贡献。Shapley 值源于博弈论,是用来衡量一个玩家对合作博弈中总回报贡献的重要工具。
Shapley 值:通过考虑所有可能的特征组合,计算每个特征在各自组合中的边际贡献,最终给出特征对模型输出的贡献度。对于每个样本,SHAP 解释了各个特征对模型预测值的影响,告诉我们每个特征在决策中的重要性。
SHAP 将每个样本的预测值分解为各个特征的贡献值,通过这些贡献值,我们可以理解模型为何作出某个预测,哪些特征影响较大,哪些特征影响较小,是否存在特征之间的交互作用等。
SHAP 的优势:
全局与局部解释相结合:SHAP 不仅可以提供单一预测的局部解释,还可以通过平均计算提供特征的重要性排序,进行全局解释。
一致性:SHAP 值具有一致性,即如果某个特征对所有预测的贡献度都增加,那么 SHAP 值会相应增加。
SHAP 方法非常适合用于解释那些复杂的机器学习模型,如树模型(XGBoost、LightGBM)、深度神经网络等。无论是做模型调优、结果解释,还是公平性分析,SHAP 都能提供透明、直观的可解释性。
●PDP概念:
PDP(部分依赖图)是一种用于可视化模型中某个特征与预测结果之间关系的图表。PDP 通过显示特定特征的不同值如何影响预测输出,从而帮助我们理解特征与模型输出之间的关系。
单变量 PDP:通过固定所有其他特征为它们的平均值,绘制一个特征值与模型预测输出之间的关系。这使得我们能够看到特征值变化时,模型预测的趋势。
双变量 PDP:绘制两个特征与预测结果之间的关系图,通过固定其他所有特征,考察这两个特征如何联合影响预测值。
●PDP 的优势:
易于解释:PDP 提供了一种简单、直观的方式来理解特征与预测之间的关系,尤其适用于线性或非线性关系的可视化。
不依赖于特定模型的内核:PDP 可以应用于任何类型的模型(例如线性回归、决策树、随机森林、XGBoost 等),并且通过将其他特征固定,可以聚焦于目标特征对预测的影响。
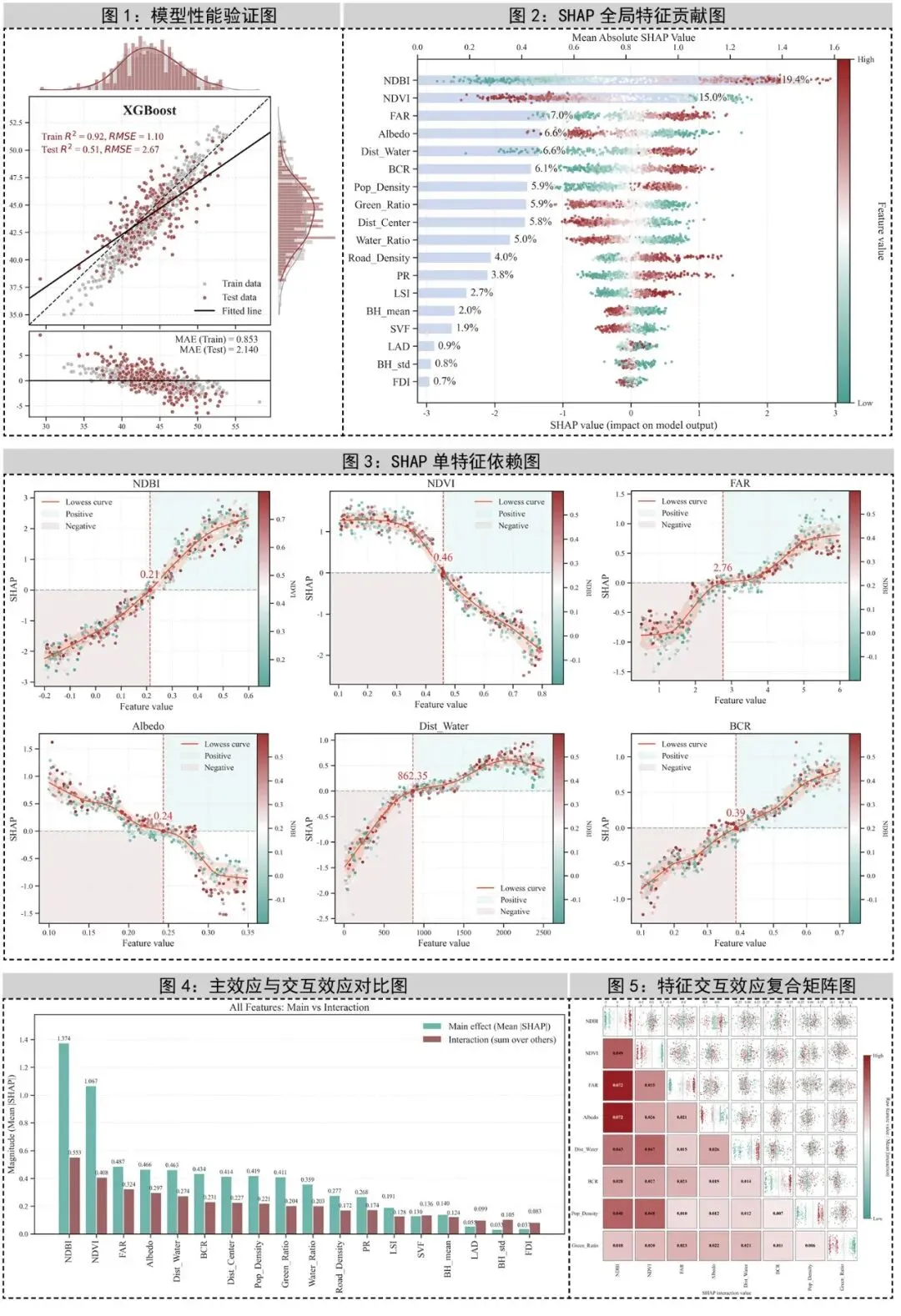
一、图1:模型性能验证图——确认模型是否可靠
首先,我们来看看图1。图1的主要作用是评估模型的预测效果。它由三部分组成:
➤ 真实值 vs 预测值的散点图:这部分是用来直观展示预测的准确性。你会看到散点图中,理想情况下,所有点都应该沿着对角线分布。如果散点图偏离对角线,那就说明模型的预测有偏差。
➤ 残差图:下方的残差图展示了预测误差是否随机分布。如果残差图呈现规律性的模式,那么说明模型的误差存在系统性偏差。
➤ 边缘分布:上方和右侧的分布曲线帮助我们检验训练集和测试集的分布情况,看是否有过拟合的风险。
★这张图重点需要看以下4点内容:
第一,看散点是否贴近对角线;
第二,看训练集与测试集表现差距大不大,差距过大往往提示过拟合;
第三,看残差是否围绕 0 随机分布,若出现弧形、漏斗形,说明可能有非线性未捕捉或异方差问题;
第四,看边缘分布中训练集与测试集是否形态相近,若差异很大,模型外推风险会增加。
这张图适合出现在论文或汇报的“模型构建与性能验证”部分。凡是连续变量预测研究,例如作物产量预测、污染物浓度预测、患者指标预测、材料性能预测,都非常适合先放这张图。
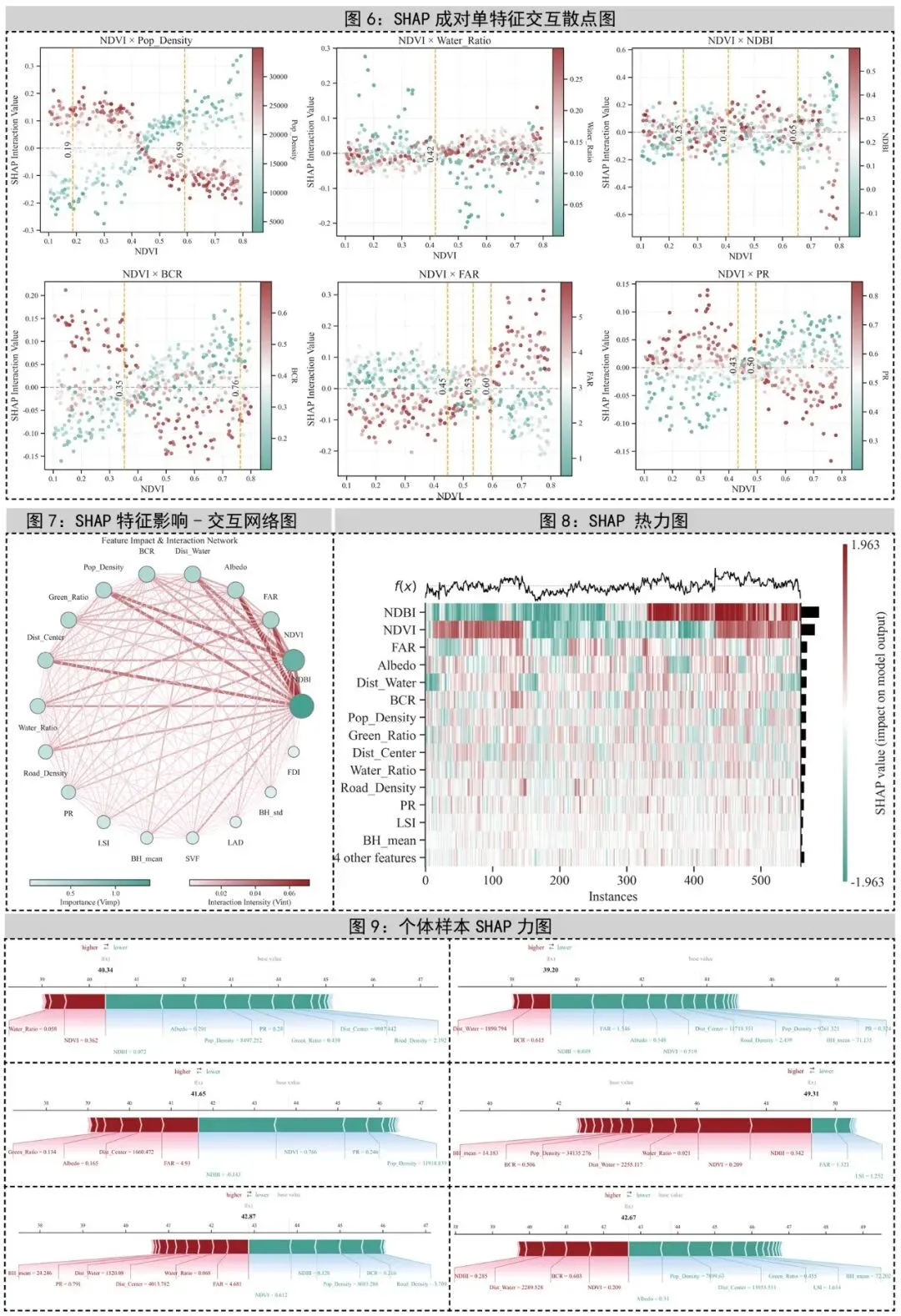
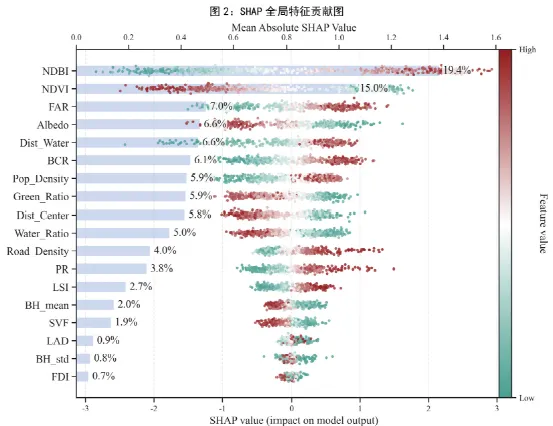
二、图2:SHAP全局特征贡献图——揭示哪些特征最重要
图2是一个把SHAP 条形图和SHAP 蜂群图合并在一起的全局解释图。背景的横向柱子表示每个变量的平均绝对 SHAP 值,也就是平均贡献强度;前景的散点则表示每个样本在该特征上的 SHAP 分布,颜色代表该特征原始取值从低到高。代码还额外标出了每个特征占总 SHAP 的百分比。
这张图的原理的SHAP 可以把模型对某个样本的预测拆成各个特征分别贡献了多少。如果把一个特征在所有样本上的贡献绝对值取平均,就得到这个特征的全局重要性。换句话说,条形图回答重要不重要,蜂群图回答怎么重要。
➤ 条形图:条形图展示了每个特征的重要性,即它对模型预测贡献的绝对值。条形越长,说明该特征的重要性越大。
➤ 蜂群图:蜂群图通过展示不同样本的SHAP值,帮助我们理解特征对模型预测的影响方向。
★这张图重点需要看以下内容:
条形图告诉我们哪些特征在全局范围内对模型影响最大。
蜂群图帮助我们了解特征是如何影响每个样本的。例如,如果一个特征的高值通常会增加预测结果,那么我们可以通过蜂群图看到它的分布是否集中在预测结果的高端。
这张图非常适合用于变量筛选、机制解释、论文主图。在医学、生物学、生态学、土壤学、空气污染研究中,只要您用的是树模型,它都是最常见也最容易被审稿人接受的全局解释图之一。
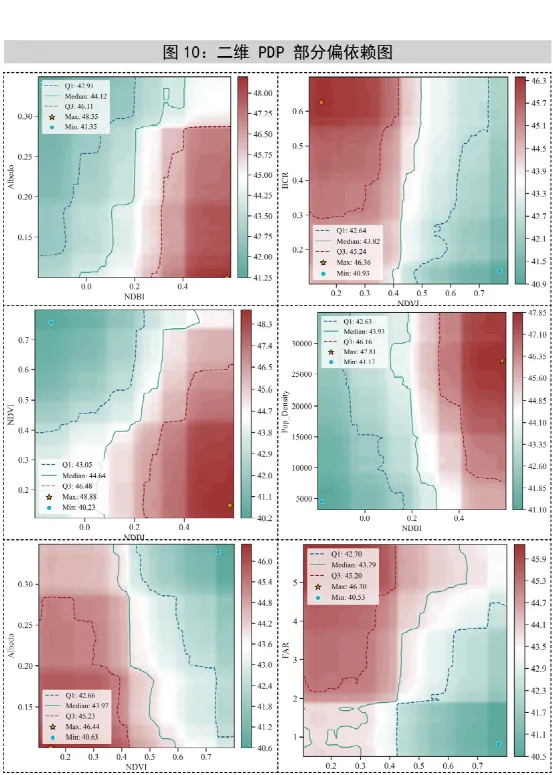
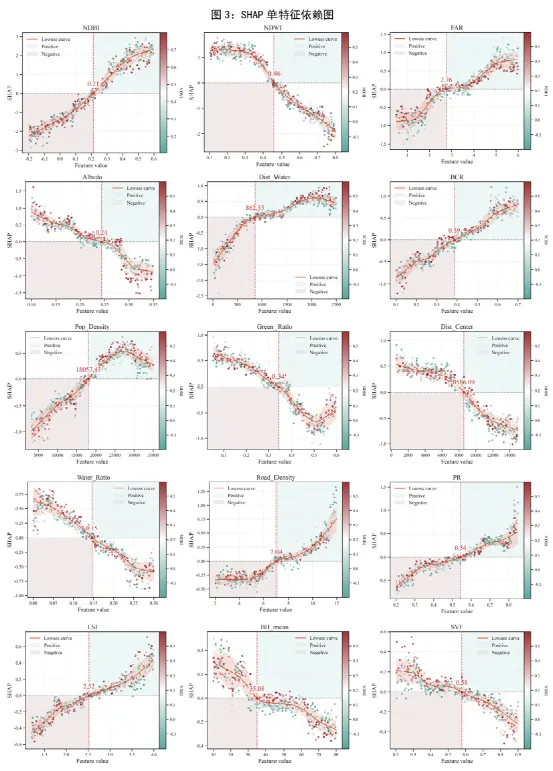
三、图3:SHAP单特征依赖图——观察每个特征如何影响预测
图3是SHAP单特征依赖图,它帮助我们理解每个特征与模型预测之间的关系。图3会按特征逐个输出,横轴是某个特征的取值,纵轴是这个特征对应的 SHAP 值,颜色则由另一个对比特征决定。图中还叠加了 Lowess 平滑曲线、局部波动带、SHAP=0 参考线,并自动寻找平滑曲线和 0 线的交点,把它作为一个阈值点标出来,同时把阈值左右的区域分别着成不同的颜色分区。
横轴:特征的取值。
纵轴:SHAP值,表示该特征对预测结果的贡献大小。
颜色:代表另一个特征的值,用来展示交互效应。
★这张图重点需要看以下内容:
第一,是否存在非线性关系,因为平滑曲线不必是直线;
第二,是否存在阈值效应,因为代码专门找了 SHAP=0 的交叉点;
第三,是否可能存在交互作用,因为同样的横坐标位置,不同颜色的点可能分布不同。
当曲线在0上方,说明这个特征当前区间倾向于提升模型预测;当曲线在 0 下方,说明倾向于降低预测;当曲线跨过0时,可以把交点近似理解为影响方向发生变化的拐点或敏感阈值。如果散点在某些区间特别分散,说明同样的特征值对不同样本的作用不完全一致,这通常提示交互作用存在。
四、图4:SHAP主效应与交互效应对比图——哪个效应更强?回答“变量本身重要,还是联合作用更重要”
图4的作用是对比每个特征的主效应和交互效应。一类是对角线上的主效应,也就是特征自身独立产生的作用;另一类是与其他所有特征的交互效应总和。代码把这两者并列画成柱状图,方便逐特征对比。
主效应展示了特征独立时对模型预测的影响。
交互效应展示了特征与其他特征组合时的影响。
它的理论基础是 SHAP 交互值分解。简单理解,一个特征对结果的影响,可以拆成自己单独起作用的部分和通过与其他变量配合才起作用的部分。如果主效应明显更高,说明该变量是单兵作战型;如果交互效应很高,说明它更像“协同型变量”,必须和别的因素一起看。
解读时可以重点关注两种情况:
如果一个特征主效应高、交互效应低,通常说明它比较稳定、直接、可独立解释;如果交互效应高于主效应,就说明不能只看它本身,必须进一步分析它和哪些变量耦合最强。对于复杂生态系统、生物网络、材料复合机制、临床多指标联合预测,这张图很有意义。

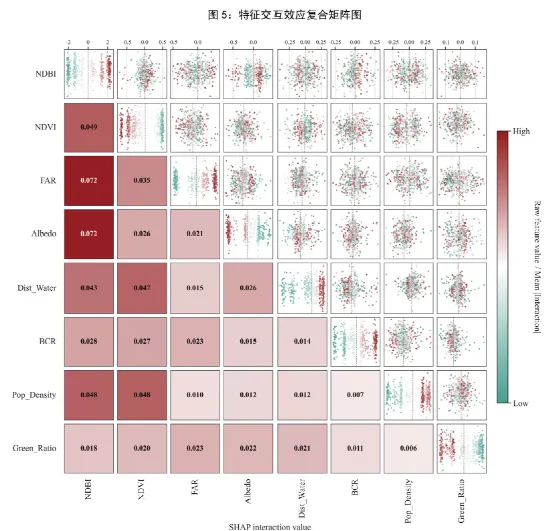
五、图5:SHAP特征交互效应复合矩阵图——特征交互的全局展示
图5是一个特征交互热力图矩阵,它展示了多个特征之间的交互强度。代码选出最重要的一批特征,构成一个方阵。左下三角是交互强度热力格,每个格子直接写出两个特征间平均绝对交互值;右上三角是散点分布图;对角线表示每个特征自身主效应的分布。整个矩阵还共享一个颜色条。
矩阵左下角的热力图表示不同特征间的交互强度。
右上角的散点图展示了这些交互效应在不同样本中的分布情况。
它的设计思想是把数值大小和分布形态放在同一张图里。左下三角解决的是谁和谁作用最强;右上三角解决的是这种作用在样本中如何分布,是集中还是离散,是正向还是负向;对角线则补充单个变量自己的主效应有多强。
我们可以这样解读:
扫左下三角,找颜色最深、数值最大的格子,这些就是重点交互对;再看对应右上格子的散点,如果分布跨越 0 很明显,说明这对变量在不同样本中既可能增强也可能抑制预测;如果点大多聚在某一侧,则作用方向更稳定。这张图适合用于探索性分析和高维变量关系总览。在组学、环境因子耦合、土壤-植被互作、材料配方优化等研究里,特别适合用来发现值得重点展开的变量对。
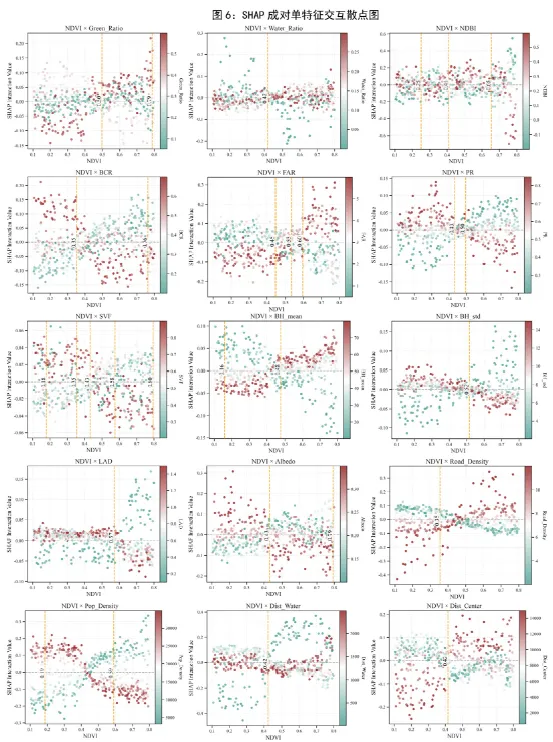
六、图6:SHAP成对单特征交互散点图——深入分析每一对特征的交互关系。回答“两个变量在什么区间开始联合作用”
图6展示了每对特征的交互影响。代码对每一对变量批量作图。横轴是特征 A 的原始值,纵轴是 A 与 B 的 SHAP 交互值,颜色表示特征 B 的取值。图中还画了 SHAP=0 水平线,并对散点做 Lowess 平滑,自动寻找平滑曲线跨过 0 的位置,用竖虚线标出交互作用拐点。
·横轴是特征 A 的原始值,纵轴是特征 A 和特征 B 的 SHAP 交互效应。
·图中通过颜色来表示特征 B 的值,同时利用Lowess 找阈值拐点。
它比图5更深入,因为图5更像总览,而图6是对单个变量对进行展开细看。如果图5告诉我们某两变量交互强,图6就进一步告诉我们:在哪个 A 的取值区间,这种交互开始增强;B 值高和 B 值低时,这个交互是否不同;交互值主要是正向还是负向。解读时,纵轴大于 0 可以理解为两者联合作用把预测推高,纵轴小于 0 则表示联合作用把预测往下拉;颜色分层越明显,说明 B 对 A 的作用调节越强;阈值线则提示交互效应发生变化的关键区间。
这类图特别适合研究协同效应、拮抗效应、共线环境暴露、双因子调控、配方优化、复合处理实验。例如温度与湿度、氮与磷、污染物 A 与污染物 B、临床指标 1 与指标 2 的联动影响,都很适合用这种图来讲。
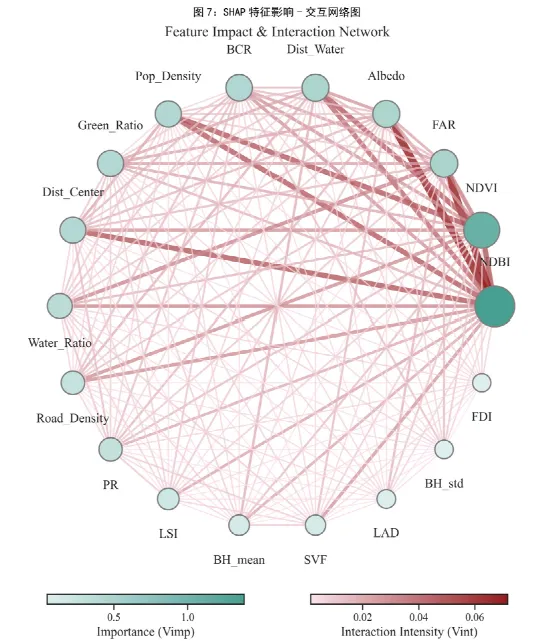
七、图7:SHAP特征影响-交互网络图——展示变量之间的系统性结构,回答“系统结构长什么样”
图7是一个特征交互网络图,它展示了特征之间如何相互连接,交互关系的强度和主效应的强度。图7把前若干个最重要特征画成一个网络。节点代表特征,节点大小和颜色由平均绝对 SHAP 值决定;边代表特征之间的交互,边宽和颜色由平均绝对交互值决定,采用圆形布局。
如果图2是在说“谁重要”,图7就是在说“这些重要变量之间是如何织成一张网的”。节点大的变量往往是系统中的核心驱动因子;连线粗的变量对,往往构成关键耦合关系;一个节点如果既大又和很多节点强连接,就可以称为“枢纽变量”或“网络中心变量”。
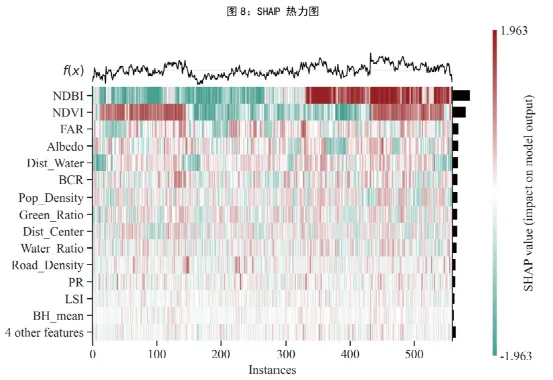
八、图8:SHAP 热力图——不同样本的特征贡献对比,回答“不同样本的解释模式是否一致”
图8是SHAP 汇总热力图。它展示的是多个样本上、多个特征的 SHAP 值分布格局,并对显示数量作了限制,以避免图太拥挤。代码还特意对坐标轴字体和 f(x) 标签做了统一美化。
这类图的核心思想是“把解释结果矩阵化”。如果说图2看的是某个特征在全样本中的总体表现,那么图8看的是:不同样本到底是靠哪些特征被解释出来的,样本之间是否存在分群,某些特征是否只在少数样本中强烈起作用。
★这张图重点需要看以下内容:
第一,某一行如果整行颜色都很强,说明这个特征在多数样本中都重要;
第二,若只在某些列突然出现强色块,说明该特征只对特定样本有强影响;
第三,如果多行在同一批列上同时出现特定模式,说明样本可能存在潜在分群。
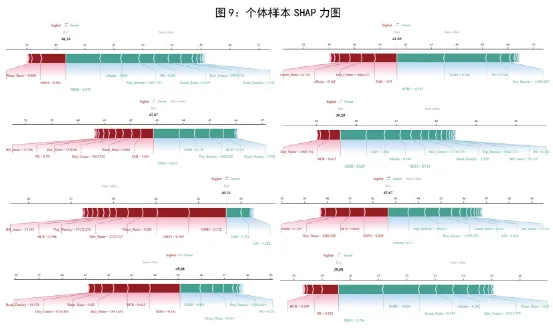
九、图9:个体样本SHAP力图——个体预测的深度解析,回答“某一个样本为什么会得到这个预测值”
图9是SHAP力图,图9会给多个样本分别输出 SHAP force plot。它先取模型的基线值,再把某个样本各个特征的 SHAP 贡献逐步叠加,形成最终预测值。
模型对一个样本的最终判断,不是凭空出现的,而是从一个平均基准出发,被一系列特征“推高”或“拉低”之后形成的。正向贡献和负向贡献分别对应不同颜色,最终落点就是这个样本的预测值。
先看终点 f(x) 离基线 base value 有多远,再看哪些特征把结果往上推、哪些往下压,最后看这些贡献的相对大小。它非常适合回答临床场景中的为什么这个患者风险高、农业场景中的为什么这个样点产量低、材料场景中的为什么这组配方性能最好。
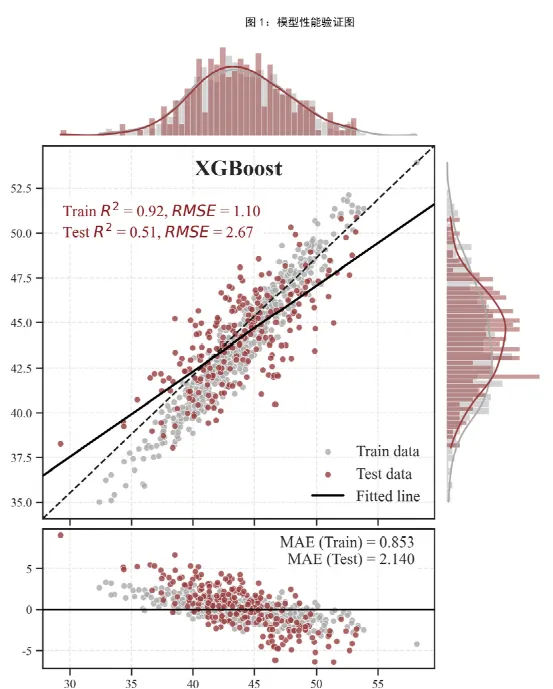
十、图10:二维 PDP 部分偏依赖图——变量联合作用的影响,回答“两个变量一起变化时,预测面怎么变”
图10会按特征重要性顺序,把每个特征和其他特征两两配对,构建二维网格。代码将其他未参与的变量固定为训练集中的中位数,然后在二维网格上调用模型预测,得到一个预测响应面。接着用等高线填色表示预测高低,再画出预测值的 Q1、Median、Q3 等高线,并用特殊符号标出全图的最大值和最小值位置。
与图6的交互散点图相比,图10更像一个二维地形图:颜色深浅代表预测值高低,等高线帮助我们看清梯度变化方向,最大值和最小值点帮助我们快速找到最优组合与最差组合。
我们在解读时需要:看颜色梯度判断高值区和低值区;看等高线疏密判断变化快慢,线越密变化越剧烈;看最大值点和最小值点判断优化方向;若等高线明显弯曲或旋转,往往说明两变量存在较强的非线性耦合。
这类图特别适合用于配方优化、环境阈值组合识别、农业栽培参数优化、材料工艺窗口分析、生态最适区识别等研究。
R代码运行:
第一步:安装 Python
建议您安装 Python3.11或3.12版本。这份代码里用到了 xgboost、shap、scikit-learn、statsmodels、networkx、seaborn、openpyxl 等库,太新的 Python 版本有时会和个别包兼容性不稳定。
第二步:选择一个合适的Python编辑器进行安装。
用 VS Code 或 PyCharm 或者其他Python编辑器运行。
方式一:VS Code 运行
先打开 VS Code,进入您的项目文件夹。
确认左侧能看到:.ipynb和.py格式的两个文件,VS Code一般使用.ipynb格式的文件运行。

方式二:PyCharm 运行
如果用 PyCharm,步骤如下:
新建项目
把.py 格式的代码和示例数据.xlsx 放进项目目录,导入.py文件使用
其他编辑器可去网上查找代码运行教学
第三步:把代码和您的 Excel 放在同一个文件夹里。
数据排列方式可参考我提供的示范数据。第一列放置目标变量(Y),从第二列开始放置特征变量(X)。
如果您的 Excel 第一列不是因变量,而是样本编号、地区名、时间列,那模型就会把这些内容当成预测目标,结果一定错。
第四步:安装Python模型库
您可以在终端一次性安装:输入下面的代码进行安装:
pip install numpy pandas matplotlib seaborn shap xgboost networkx scikit-learn statsmodels openpyxl
如果网络慢,可以用镜像:代码如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy pandas matplotlib seaborn shap xgboost networkx scikit-learn statsmodels openpyxl
第五步:替换您自己的Excel数据,点击运行。
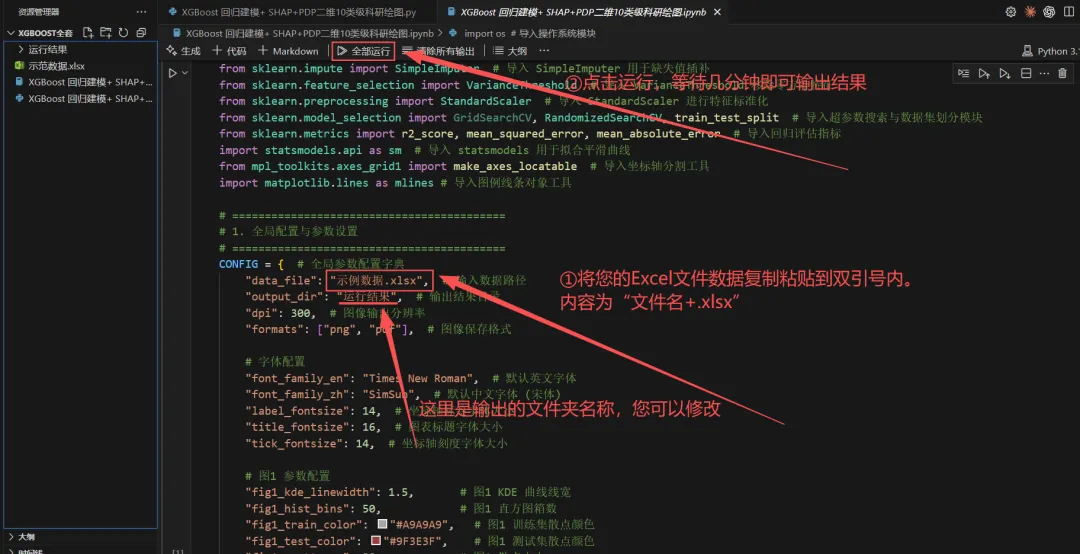
输出文件包含以下内容:
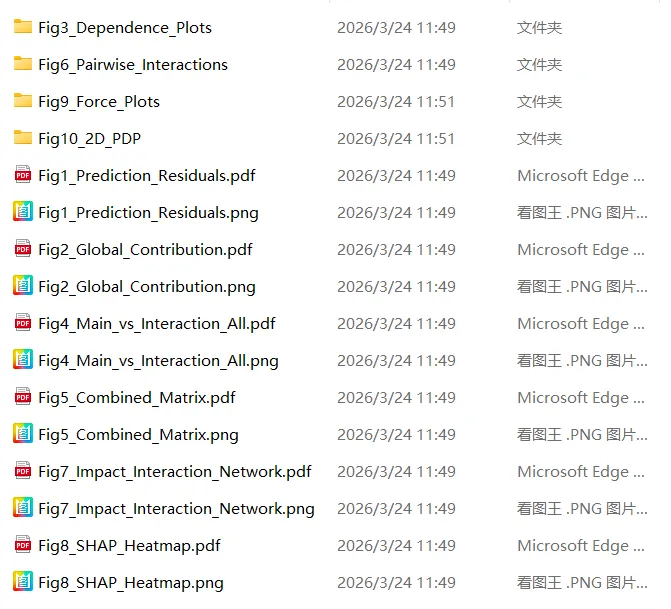
★自定义修改的内容:
⏯修改字体、字体大小的地方,可根据您的需求调整

⏯图1模型性能验证图样式调整区域。复制颜色代码到颜色双引号内
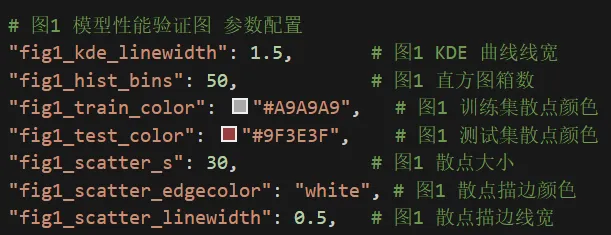
⏯图2 SHAP全局特征贡献图颜色样式调整区域。复制颜色代码到颜色双引号内

⏯图3 SHAP单特征依赖图 参数配置
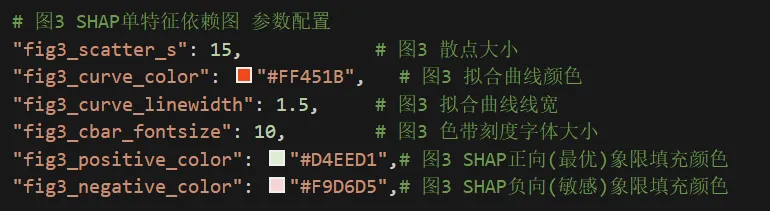
⏯图4 SHAP主效应与交互效应对比图 参数配置

⏯图5、图7、图8中需要展示的特征变量(X)的数量调整。对于特征变量(X)较多的小伙伴们,可以自定义选择和输入想要展示的变量特征。这里按照重要性较高的特征变量(X)顺序来选择的。如果特征太多,可能做出来的图很杂乱,建议减少大量不重要的特征展示。

⏯这里调整图5.的字体大小。

⏯这里调整图7.特征影响-交互网络图的颜色。

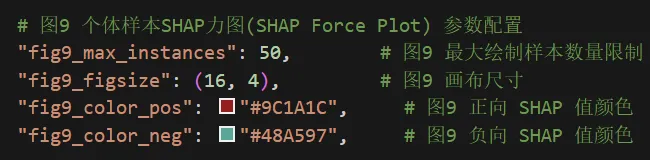
⏯这里调整图9.个体样本SHAP力图的内容。
由于我的示范数据样本量比较多,我这里只设置输出50个样本的SHAP力图。输出图的顺序按照Excel表内每一行的排列顺序进行排列。其他小伙伴可以根据自己的样本量自行设置。样本量输出太多的话,运行时间会很长很长......
⏯这里调整图10. 二维 PDP 部分偏依赖图(2D PDP) 参数配置。

⏯这里调整所有图内整体配色。

⏯这里调整训练集和测试集划分比例。
.......其他内容可参考旁边的中文注释自行调整,小白调整时需要注意,避免调错导致代码运行失败。
★代码运行常见报错问题:
1.出现:FileNotFoundError: [Errno 2] No such file or directory: '示例数据.xlsx'
原因是当前文件夹代码默认去找 示例数据.xlsx。而这个文件和代码不在同一个文件夹内。解决办法:你需要替换为你自己的数据,然后和代码放在一个文件夹内。
2.出现:ModuleNotFoundError: No module named 'shap'
或者:ModuleNotFoundError: No module named 'xgboost'
其他:ModuleNotFoundError: No module named ''
解决办法就是补安装对应模型库:例如:
pip install shap
pip install xgboost
3.出现:警告:系统缺失中文字体 'SimSun',中文可能无法正常显示。
代码里设置了英文字体 Times New Roman,中文字体 SimSun,并且会先检查系统里有没有这些字体;如果缺失,会打印警告。
解决方法:改成您电脑里实际有的中文字体
4.报错:Excel 第一列不是数值型目标变量
如果第一列是文字,比如“样本编号”“地区名称”,XGBoost 回归就会报错,或者训练结果异常。
解决方法:
确保第一列真的是您要预测的连续型数值变量。
5. 运行很慢,像“卡住了一样”
这份代码慢的地方主要有两个:
一是 RandomizedSearchCV 做参数搜索,设置了 cv=5 和 n_iter=28;
二是 SHAP 交互值 shap_interaction_values 计算非常耗时。
所以如果特征很多、样本很多,程序可能要跑很久,这不是死机,是正常现象。
6. 图太多,输出文件夹里内容爆炸
这份代码不只是输出 10 张图,而是有些图会批量输出很多张。
尤其是图3、图6、图10,它们会按特征或特征对循环保存。
所以如果您的特征有 20 个,图6 和图10 可能会生成很多文件。
这也是为什么代码里专门给图3、图6等设置了子文件夹。
出现其他运行问题可添加微信详细咨询:zhouysh001(八宝粥加油)
完整代码获取:回复“ XGBoost回归 ”即可获得通道
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
